
OrzClick: 国庆写个 ClickHouse 客户端
2 / 2 / 创建于 5年前 /
 Oraoto 的个人博客
Oraoto 的个人博客
起因
我看 ClickHouse 有 C++ 客户端(clickhouse-cpp),我又用过 PHP-CPP 写扩展,于是就在国庆写了 OrzClick ,一个 PHP 用的 ClickHouse 客户端。
比较尴尬的是,我写到一半才发现 SeasClick,它也是 clickhouse-cpp 的绑定, 而且是 C 写的,感觉用 PHP-CPP 我就已经输了一半呀,所以我的小目标就是性能超越 SeasClick 。
。
性能测试
Select 结果: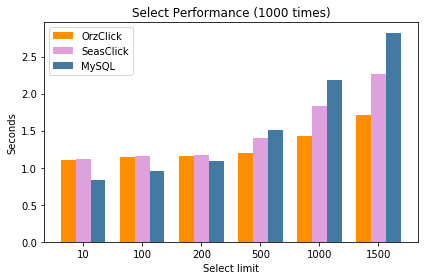
- 使用 PDO 访问 ClickHouse 的 MySQL 接口,查询小量数据性能更好

- 小量数据时,OrzClick 和 SeasClick 性能相近,数据大时 OrzClick > SeasClick > MySQL 接口
Insert 结果: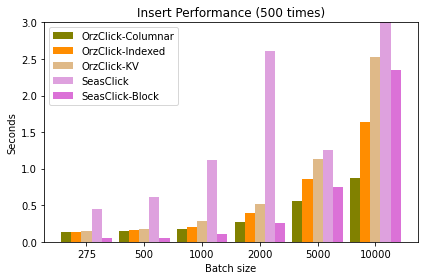
- OrzClick-Indexed 对标的是 SeasClick,API 最相近(可看代码:1 2),算是达到了小目标
- SeasClick 和 OrzClick 都有提高插入性能的 API,SeasClick 的 startWrite-write-endWrite 性能非常好(图上的 SeasClick-Block),OrzClick 的 InsertColumnar 只有数据量大于 5 千时才能超过它(图上的 OrzClick-Columnar)

哪个 clickhouse-cpp ?
在 Github 搜索 clickhouse-cpp, 你会发现有两个相似的库:
看 LICENSE 和开发人员的评论,可以得知 ClickHouse 官方的才是 fork。简单对比了一下代码,两者底层还是一样的,只是功能特性有一点小小区别。
OrzClick 使用的是 ClickHouse/clickhouse-cpp 的 fork,而 SeasClick 是 artpaul/clickhouse-cpp 的 fork,所以大家还是同源的,性能差异就体现在使用方式和补丁了。
SeasClick 的优化
clickhouse-cpp 的数据插入接口非常简单,就一个入口方法:
void Insert(const std::string& table_name, const Block& block);而 SeasClick 把它拆分成:
void InsertQuery(const std::string& query, SelectCallback cb);
void InsertData(const Block& block);
void InsertDataEnd();这个拆分对性能提升、扩展实现有很大帮助:
InsertQuery可以拿到字段的类型信息,可以简化 PHP 接口的使用,不像 OrzClick 一样需要用户指定字段类型InsertQuery+ 多次InsertData+InsertDataEnd可以实现连续插入,性能提升巨大(见图上的 SeasClick-Block)
OrzClick 的优化
数据访问模式
ClickHouse 是个列式存储的数据库,而它的接口也使用了同样的设计,一次 select 会返回多个 Block,Block 里有多个 Column,一个 Column 里的数据是连续存放的,Column 间是相互独立的。
应用层使用数据还是按行为主,所以这里要重新组织一下数据,把列式数据转成行式数据。 SeasClick 是按行处理,而 OrzClick 是按列处理,这是两者的主要区别之一。
SeasClick 遍历模式
Block
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Column A Column B Column C ┃
┃ ┃
┃ ┏━━━━━━━━━┓ ┏━━━━━━━━━┓ ┏━━━━━━━━━┓ ┃
Seas─╮──┃───>┃ 1 ┃──>┃ X ┃──>┃ 1.2 ┃ ┃
│ ┃ ┣━━━━━━━━━┫ ┣━━━━━━━━━┫ ┣━━━━━━━━━┫ ┃
╰──┃───>┃ 2 ┃──>┃ Y ┃──>┃ 2.3 ┃ ┃
┃ ┣━━━━━━━━━┫ ┣━━━━━━━━━┫ ┣━━━━━━━━━┫ ┃
┃ ┃ 3 ┃ ┃ Z ┃ ┃ 3.4 ┃ ┃
┃ ╏ ╏ ╏ ╏ ╏ ╏ ┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
OrzClick 遍历模式
Block
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Column A Column B Column C ┃
╭───────────────────╮─────────────╮ ┃
Orz ─╯──┃─╮ ┏━━━━━━━━━┓ │ ┏━━━━━━━━━┓ │ ┏━━━━━━━━━┓ ┃
┃ │ ┃ 1 ┃ │ ┃ X ┃ │ ┃ 1.2 ┃ ┃
┃ │ ┣━━━━━━━━━┫ │ ┣━━━━━━━━━┫ │ ┣━━━━━━━━━┫ ┃
┃ │ ┃ 2 ┃ │ ┃ Y ┃ │ ┃ 2.3 ┃ ┃
┃ │ ┣━━━━━━━━━┫ │ ┣━━━━━━━━━┫ │ ┣━━━━━━━━━┫ ┃
┃ V ┃ 3 ┃ V ┃ Z ┃ V ┃ 3.4 ┃ ┃
┃ ╏ ╏ ╏ ╏ ╏ ╏ ┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛ SeasClick 的实现类似这样:
for (auto i = 0; i < block.GetRowCount(); i++) { // 外层按行遍历
for (auto j = 0; j < block.GetColumnCount(); j++) { // 行内再按列遍历
switch (block[i]->GetType().GetCode()) { // 每一列类型都不同,要相应处理
case clickhouse::Type::Int8:
add_assoc_long_ex(result, key, len, block[i]->As<clickhouse::ColumnInt8>()->At(j));
break;
case ...// 其他类型类似
}
}
}OrzClick 的实现类似这样:
for (auto i = 0; i < block.GetColumnCount(); i++) { // 外层按列遍历
switch (block[i]->GetType().GetCode()) { // 每一列类型都不同,要相应处理
case clickhouse::Type::Int8:
auto col = block[i]->As<clickhouse::ColumnInt8>();
for (auto j = 0; j < block.GetRowCount(); j++) { // 列内再按行遍历
add_assoc_long_ex(result, key, col->At(j));
}
break;
case ...// 其他类型类似
}
}对比一下可以看到 SeasClick 的内层循环会有大量的 switch 分支跳转,而 OrzClick
在外层判断了类型,内层循环非常紧湊,没有多余的分支。
用 perf stat 分析一下,SeasClick 分支数(branches)、分支预测错误数(branch-misses)都在 OrzClick 的 2 倍以上:
# perf stat php select-orzclick.php 1000 1000
Performance counter stats for 'php select-orzclick.php 1000 1000':
496.85 msec task-clock:u # 0.340 CPUs utilized
0 context-switches:u # 0.000 K/sec
0 cpu-migrations:u # 0.000 K/sec
1,977 page-faults:u # 0.004 M/sec
1,761,248,425 cycles:u # 3.545 GHz
2,601,973,475 instructions:u # 1.48 insn per cycle
487,402,260 branches:u # 980.986 M/sec
2,879,008 branch-misses:u # 0.59% of all branches
# perf stat php select-seasclick.php 1000 1000
Performance counter stats for 'php select-seasclick.php 1000 1000':
896.48 msec task-clock:u # 0.482 CPUs utilized
0 context-switches:u # 0.000 K/sec
0 cpu-migrations:u # 0.000 K/sec
1,962 page-faults:u # 0.002 M/sec
3,316,728,038 cycles:u # 3.700 GHz
6,019,365,862 instructions:u # 1.81 insn per cycle
1,316,036,409 branches:u # 1468.000 M/sec (2.7x)
10,073,424 branch-misses:u # 0.77% of all branches (3.4x)所以在 select 测试中,数据量少的时候 OrzClick 只比 SeasClick 略好,但数据量大了性能差距就拉开了。
当然也有退化到 OrzClick 不利的情况,就是 ClickHouse 返回多个Block,但每个 Block 都只有一行,目前只发现 Memory 引擎有这种情况。
TCP_NODELAY
在测试的时候,发现少量数据反而更慢,就是一字节的区别:
$ time php insert-orzclick.php 8170 100
real 0m3.894s
user 0m0.030s
sys 0m0.061s
$ time php insert-orzclick.php 8171 100
real 0m0.422s
user 0m0.050s
sys 0m0.022s看 ClickHouse 日志,处理少量数据反而时多用了 40ms 左右的时间(大佬们看到 40 ms 就大概猜到了吧)。
对比两者的火焰图,虽然执行的总时间不同,但是各种函数的比例是接近的, 大头都是 _zend_hash_find_known_hash:


难道问题真在 PHP?我移除掉 clickhouse-cpp 的调用,发现两种情况执行时间基本相同,这也就排除掉 PHP 的可能性,问题应该出在 clickhouse-cpp。
再用 strace 跟踪,发现数据少的时候是只有一个 send 系统调用,多的时候会分成两个:
# 8170
sendto(3, "\2\0\1\0\2\377\377\377\377\0\1\352?\2u8"..., 8192, MSG_NOSIGNAL, NULL, 0) = 8192
# 8171
sendto(3, "\2\0\1\0\2\377\377\377\377\0\1\353?\2u8"..., 22, MSG_NOSIGNAL, NULL, 0) = 22
sendto(3, "\1\2\3\4\5\6\7\10\t\n\v\f\r\16\17\20"..., 8171, MSG_NOSIGNAL, NULL, 0) = 81718170 和 8171 这个临界点,发现和 clickhouse-cpp 的缓冲区大小 8192 很接近。于是我试着调整 clickhouse-cpp 缓冲区大小,的确会影响 send 的次数,但只是临界点有点变化,不能解决问题。
至此基本可以确定是内核和协议栈的影响,于是想有那些配置可能影响发送、 接收延迟,然后就想到了 TCP_NODELAY,于是我提了个 PR,给 clickhouse-cpp 加上了 TCP_NODELAY 选项(PR在2020-01-10合并),测试性能终于稳定了。
后来我又尝试用 Off-CPU 火焰图,只能看到在 recv 时有等待,还不能直接看出原因,这种问题没经验真不易处理(虽然搜索 TCP 40ms 就有结果)。

PHP-CPP 损耗
PHP-CPP 封装了 Zend API,开发扩展基本可以不考虑 Zend 引擎低层(zval、HashTable 等等),非常方便,代价就是更多额外操作和性能损耗。
优化方式非常暴力,直接修改 PHP-CPP,暴露出被封装的 zval,然后直接用 Zend API 操作。过程就是先用 PHP-CPP 写,然后用火焰图发现热点,然后替换成 Zend API。
例如在 nestedForeach 方法里,需要获取数组的值,如果用 PHP-CPP 的 Value::get() 最后会复制一次:
Value::Value(struct _zval_struct *val, bool ref)
{
// do we have to force a reference?
if (!ref)
{
// we don't, simply duplicate the value
ZVAL_DUP(_val, val);
}批量插入的时候,就会有不必要的数组复制。所以这里改成 zend_hash_find 拿到 *zval,然后直接遍历:
zval *item;
auto column = zend_hash_find(Z_ARRVAL_P(data._val), key);
auto ht = Z_ARRVAL_P(column);
ZEND_HASH_FOREACH_VAL(ht, item) {
callback(item);
}
ZEND_HASH_FOREACH_END();结束语
国庆假期通过这个项目,每样学到了一点点:
- ClickHouse
- PHP 扩展开发
- C++
- CMake
- 性能优化
也有没做好的:
- 单元测试,本来想用 phpt,但没写,目前在 tests 目录有几个我开发时用的用例子
- CI,准备试试 GitHub Action
最后,从 OrzClick 这名字你就应该知道,这是出于玩和学习的目的写的,生产环境还是建议用 SeasClick。
本作品采用《CC 协议》,转载必须注明作者和本文链接












 关于 LearnKu
关于 LearnKu




推荐文章: