
leetcode刷题844-比较含退格的字符串(带代码解析,带知识点回顾)
0 / 0 / 创建于 5年前 /
 wangchunbo 的个人博客
wangchunbo 的个人博客
844. 比较含退格的字符串
难度:简单
第一: 简单浏览一下题目
给定 S 和 T 两个字符串,当它们分别被输入到空白的文本编辑器后,判断二者是否相等,并返回结果。 # 代表退格字符。
注意:如果对空文本输入退格字符,文本继续为空。
示例 1:
输入:S = “ab#c”, T = “ad#c”
输出:true
解释:S 和 T 都会变成 “ac”。
示例 2:
输入:S = “ab##”, T = “c#d#”
输出:true
解释:S 和 T 都会变成 “”。
示例 3:
输入:S = “a##c”, T = “#a#c”
输出:true
解释:S 和 T 都会变成 “c”。
示例 4:
输入:S = “a#c”, T = “b”
输出:false
解释:S 会变成 “c”,但 T 仍然是 “b”。
提示:
- <= S.length <= 200
- <= T.length <= 200
- S 和 T 只含有小写字母以及字符 ‘#’。
进阶:
你可以用 O(N) 的时间复杂度和 O(1) 的空间复杂度解决该问题吗?
来源:力扣(LeetCode)
链接:leetcode-cn.com/problems/backspace...
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
简单进行一下分析
也就是说, 如果符号有一个 #,我们就要删除一个字符.
两个就删除两个.
那我们只能 遍历字符.
这就是方法一,最简单的.
第二: 官方解析
2.1:方法一: 重构字符串
思路以及算法
最容易想到的方法是将给定的字符串中的退格符和应当被删除的字符都去除,还原给定字符串的一般形式。然后直接比较两字符串是否相等即可。
具体地,我们用栈处理遍历过程,每次我们遍历到一个字符:
- 如果它是退格符,那么我们将栈顶弹出;
- 如果它是普通字符,那么我们将其压入栈中。
func build(str string) string {
// 分配存储 数组的内存空间,s结构体的array指针指向这个数组
s := []byte{} // 知识点1,看下文
for i := range str {
// 遍历判断 如果不存在 #
if str[i] != '#' {
// 把当前的字符 压入s 数组中
fmt.Println("来了没有有#")
s = append(s, str[i])
fmt.Println(s)
} else if len(s) > 0 {
// 如果我的s 有字符 (隐藏条件,这里没有特殊写出,并且 没有 # ) 则 直接 让我的 s 长度减去1
fmt.Println("来了有#")
fmt.Println(s)
s = s[:len(s)-1] // 截取 到最后一位. 最后一位不要了. 因为我们这里是有# 所以需要删除最后一位呀
fmt.Println("去掉最后进去的")
fmt.Println(s)
}
}
return string(s)
}
// 这个方法是leetcode 给出的测试用例,逻辑先走这里
func backspaceCompare(s, t string) bool {
return build(s) == build(t)
}方法一的复杂度分析
时间复杂度:O(N+M)O(N+M),其中 NN 和 MM 分别为字符串 SS 和 TT 的长度。我们需要遍历两字符串各一次。
空间复杂度:O(N+M)O(N+M),其中 NN 和 MM 分别为字符串 SS 和 TT 的长度。主要为还原出的字符串的开销。
2.2:方法二:双指针
思路及算法
一个字符是否会被删掉,只取决于该字符后面的退格符,而与该字符前面的退格符无关。因此当我们逆序地遍历字符串,就可以立即确定当前字符是否会被删掉。
具体地,我们定义 skip 表示当前待删除的字符的数量。每次我们遍历到一个字符:
若该字符为退格符,则我们需要多删除一个普通字符,我们让
skip加 1;若该字符为普通字符:
- 若
skip为 0,则说明当前字符不需要删去; - 若
skip不为 0,则说明当前字符需要删去,我们让skip减 1。
- 若
这样,我们定义两个指针,分别指向两字符串的末尾。每次我们让两指针逆序地遍历两字符串,直到两字符串能够各自确定一个字符,然后将这两个字符进行比较。重复这一过程直到找到的两个字符不相等,或遍历完字符串为止。
#
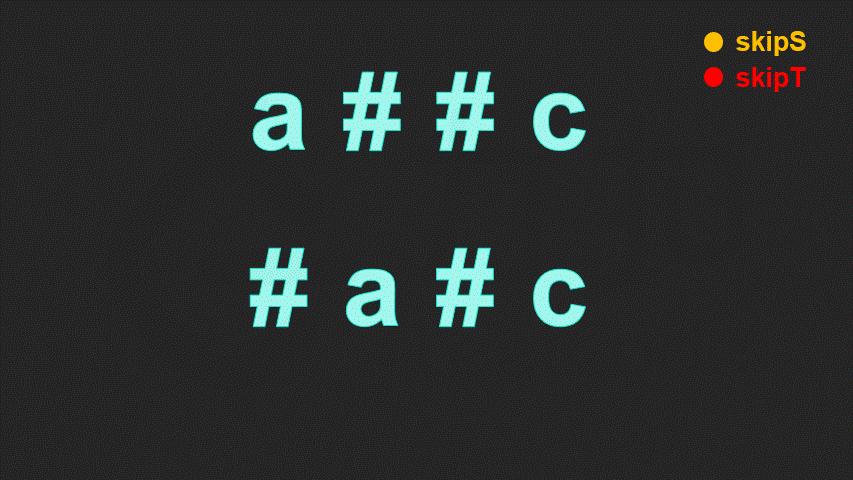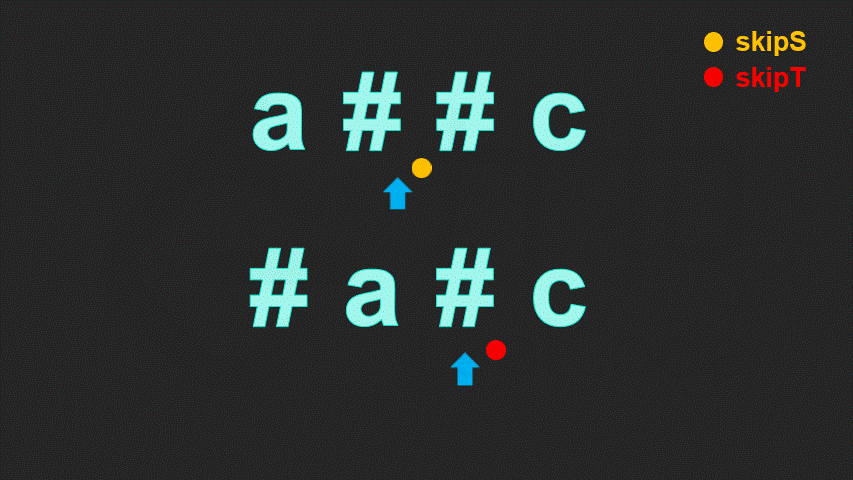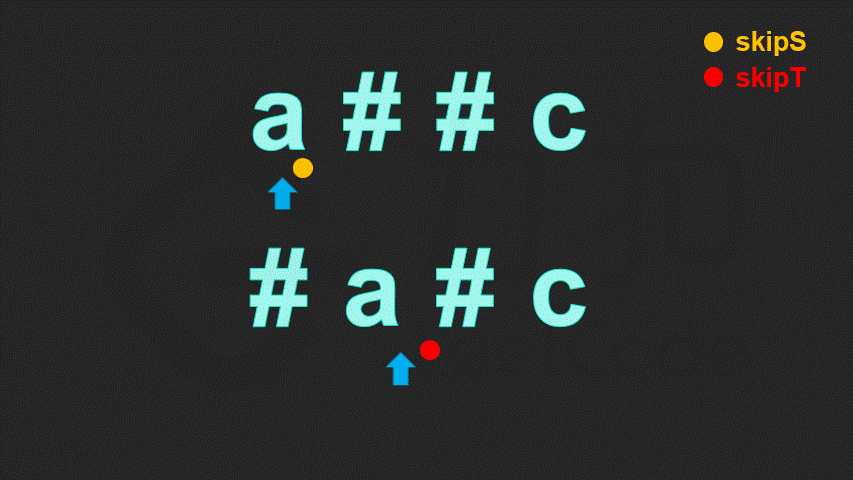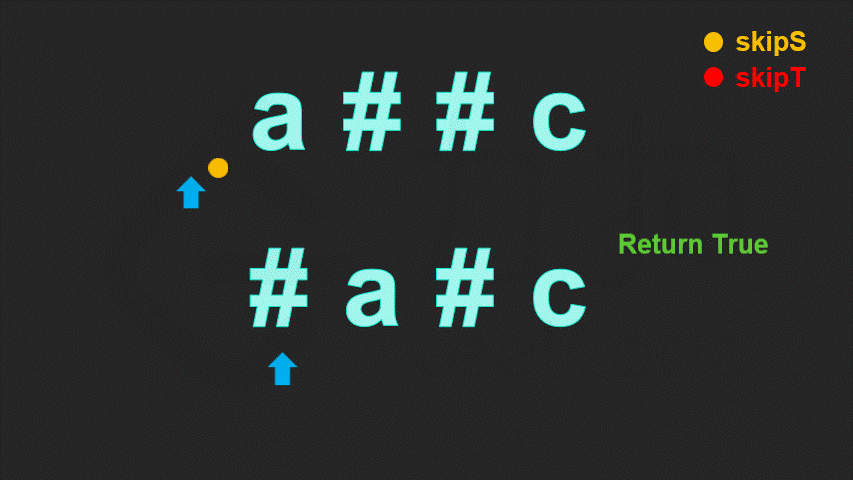
// 函数名字为 leetcode 提前创建好的测试用例
func backspaceCompare(s, t string) bool {
// 创建两个空指针
skipS, skipT := 0, 0
// 从传入的s t末尾开始,长度限制为 当前长度 减去1
i, j := len(s)-1, len(t)-1
// 必须有一个是有 字节的 才进入循环
for i >= 0 || j >= 0 {
for i >= 0 {
// 遍历 s 如果 s 中有 # 让 skip指针 +1
if s[i] == '#' {
skipS++
i--
// 如果 我的指针 大于0 (隐藏条件,这里没有特殊写出,并且 没有 # )
} else if skipS > 0 {
// 就指针后退一个
skipS--
// 循环i 正常减去1
i--
// 其他情况, 就跳出循环
} else {
break
}
}
// 此处原理与上相同
for j >= 0 {
if t[j] == '#' {
skipT++
j--
} else if skipT > 0 {
skipT--
j--
} else {
break
}
}
// 如果 i 或者j 还有字节.
if i >= 0 && j >= 0 {
// 对比 如果 s 与 t 中当前循环 指针 对不上,说明以后也对不上,直接返回false
if s[i] != t[j] {
return false
}
// 如果 有一个还有字节,另外一个没字节了. 这里写法也可以反过来写一样的
// 说明后面也对不上,后面哪怕是 # 或者 任意字符,都不一样了.
// 直接返回false
} else if i >= 0 || j >= 0 {
return false
}
// 什么都没有,说明触发到0 了. 也执行 减1 让他接下来结束最后一次循环
i--
j--
}
return true
}
方法二的 复杂度分析
时间复杂度:O(N+M)O(N+M),其中 NN 和 MM 分别为字符串 SS 和 TT 的长度。我们需要遍历两字符串各一次。
空间复杂度:O(1)O(1)。对于每个字符串,我们只需要定义一个指针和一个计数器即可。
第三: 题外知识
1.0 str与byte如何取舍?
s := []byte{}
既然string就是一系列字节,而[]byte也可以表达一系列字节,那么实际运用中应当如何取舍?
- string可以直接比较,而[]byte不可以,所以[]byte不可以当map的key值。
- 因为无法修改string中的某个字符,需要粒度小到操作一个字符时,用[]byte。
- string值不可为nil,所以如果你想要通过返回nil表达额外的含义,就用[]byte。
- []byte切片这么灵活,想要用切片的特性就用[]byte。
- 需要大量字符串处理的时候用[]byte,性能好很多。
在本文代码我们需要操作一个字符,所以我们用 []byte
2.0 golang的 := 声明变量
:=这个符号直接取代了var和type,这种形式叫做简短声明。\不过它有一个限制,那就是它只能用在函数内部;在函数外部使用则会无法编译通过,所以一般用var方式来定义全局变量**。
换句话说,“:=”只能在声明“局部变量”的时候使用,而“var”没有这个限制。我们来看看下面三种方式定义变量,很明显 第三行是最简单的. 但是要注意局部变量的问题哈!
var number1, number2, number3 int = 1, 2, 3
var number1, number2, number3 = 1, 2, 3
number1, number2, number3 := 1, 2, 3本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu




推荐文章: