
C语言的角落——这些C语言不常用的特性你知道吗?
0 / 0 / 创建于 5年前 /
 linux-xiaofeng 的个人博客
linux-xiaofeng 的个人博客
变长参数列表
<stdarg.h> 头文件定义了一些宏,当函数参数未知时去获取函数的参数
变量:typedef va_list
宏:
va_start()
va_arg()
va_end()
va_list类型通过stdarg宏定义来访问一个函数的参数表,参数列表的末尾会用省略号省略
(va_list用来保存va_start,va_end所需信息的一种类型。为了访问变长参数列表中的参数,必须声明va_list类型的一个对象 )
我们通过初始化(va_start)类型为va_list的参数表指针,并通过va_arg来获取下一个参数。
【例子:】
求任意个整数的最大值:

可变长数组
历史上,C语言只支持在编译时就能确定大小的数组。程序员需要变长数组时,不得不用malloc或calloc这样的函数为这些数组分配存储空间,且涉及到多维数组时,不得不显示地编码,用行优先索引将多维数组映射到一维的数组。
ISOC99引入了一种能力,允许数组的维度是表达式,在数组被分配的时候才计算出来。

注意:如果你需要有着变长大小的临时存储,并且其生命周期在变量内部时,可考虑VLA(Variable Length Array,变长数组)。但这有个限制:每个函数的空间不能超过数百字节。因为C99指出边长数组能自动存储,它们像其他自动变量一样受限于同一作用域。即便标准未明确规定,VLA的实现都是把内存数据放到栈中。VLA的最大长度为SIZE_MAX字节。考虑到目标平台的栈大小,我们必须更加谨慎小心,以保证程序不会面临栈溢出、下个内存段的数据损坏的尴尬局面。
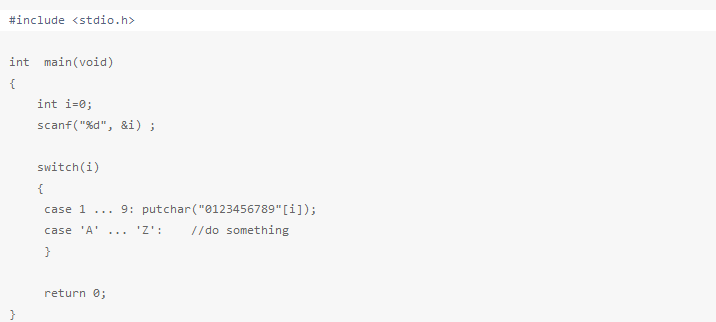
case支持范围取值(gcc扩展特性) MinGW编译通过
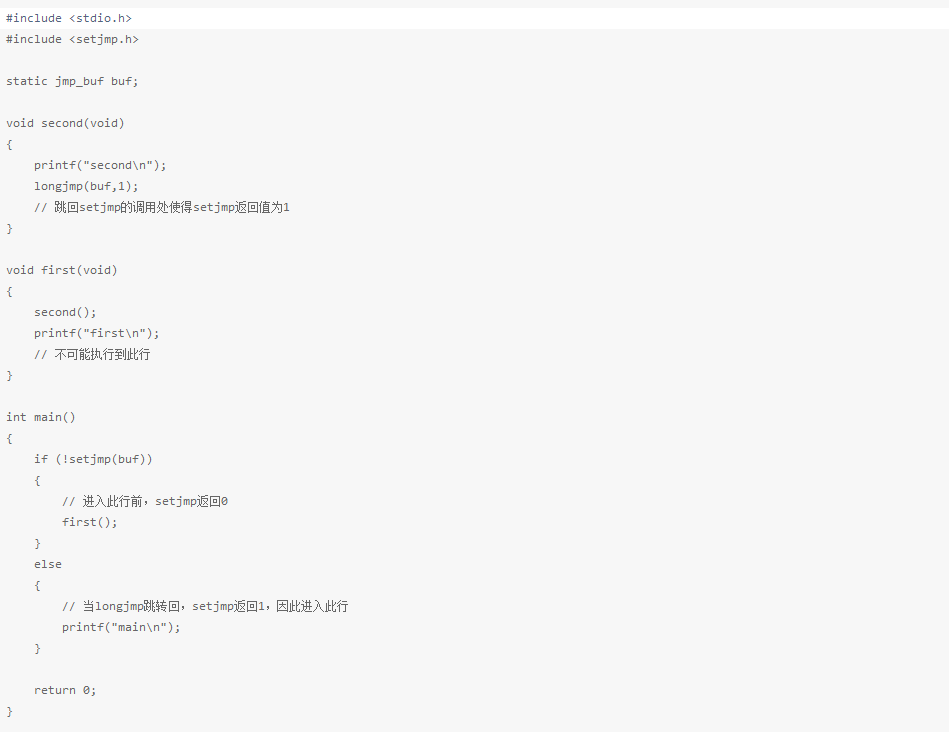
非局部跳转setjmp和longjmp
在C中,goto语句是不能跨越函数的,而执行这类跳转功能的是setjmp和longjmp宏。这两个宏对于处理发生在深层嵌套函数调用中的出错情况是非常有用的。
此即为:非局部跳转。非局部指的是,这不是由普通C语言goto语句在一个函数内实施的跳转,而是在栈上跳过若干调用帧,返回到当前函数调用路径的某个函数中。
#include <setjmp.h>
int setjmp(jmp_buf env) ; /设置调转点/
void longjmp(jmp_bufenv, int val) ; /跳转/
setjmp参数env的类型是一个特殊类型jmp_buf。这一数据类型是某种形式的数组,其中存放 在调用longjmp时能用来恢复栈状态的所有信息。因为需在另一个函数中引用env变量,所以应该将env变量定义为全局变量。
longjmp参数val,它将成为从setjmp处返回的值。(很神奇吧。setjmp根据返回值可知道是哪个longjmp返回来的)
推荐自己的linuxC/C++交流群:812855908!整理了一些个人 觉得比较好的学习书籍、视频资料以及大厂面经视频共享在群文件里面,有需要的 可以自行添加哦!~
volatile属性
如果你有一个自动变量,而又不想它被编译器优化进寄存器,则可定义其为有volatile属性。这样,就明确地把这个值放在存储器中,而不会被优化进寄存器。
setjmp会保存当前栈状态信息,也会保存此时寄存器中的值。(longjmp会回滚寄存器中的值)
【如果要编写一个使用非局部跳转的可移植程序,则必须使用volatile属性】
· IO缓冲问题
缓冲输出和内存分配
当一个程序产生输出时,能够立即看到它有多重要?这取决于程序。
例如,终端上显示输出并要求人们坐在终端前面回答一个问题,人们能够看到输出以知道该输入什么就显得至关重要了。另一方面,如果输出到一个文件中,并最终被发送到一个行式打印机,只有所有的输出最终能够到达那里是重要的。
立即安排输出的显示通常比将其暂时保存在一大块一起输出要昂贵得多。因此,C实现通常允许程序员控制产生多少输出后在实际地写出它们。
这个控制通常约定为一个称为setbuf()的库函数。如果buf是一个具有适当大小的字符数组,则
setbuf(stdout, buf);
将告诉I/O库写入到stdout中的输出要以buf作为一个输出缓冲,并且等到buf满了或程序员直接调用fflush()再实际写出。缓冲区的合适的大小在中定义为BUFSIZ。
因此,下面的程序解释了通过使用setbuf()来讲标准输入复制到标准输出:

不幸的是,这个程序是错误的,因为一个细微的原因。
要知道毛病出在哪,我们需要知道缓冲区最后一次刷新是在什么时候。答案:主程序完成之后,库将控制交回到操作系统之前所执行的清理的一部分。在这一时刻,缓冲区已经被释放了! (即main函数栈清空之后)
有两种方法可以避免这一问题。
首先,使用静态缓冲区,或者将其显式地声明为静态:
static char buf[BUFSIZ];
或者将整个声明移到主函数之外。
另一种可能的方法是动态地分配缓冲区并且从不释放它:
char *malloc();
setbuf(stdout, malloc(BUFSIZ));
注意在后一种情况中,不必检查malloc()的返回值,因为如果它失败了,会返回一个空指针。而setbuf()可以接受一个空指针作为其第二个参数,这将使得stdout变成非缓冲的。这会运行得很慢,但它是可以运行的。
预编译和宏定义
C/C++中几个罕见却有用的预编译和宏定义
1:# error
语法格式如下:
#error token-sequence
其主要的作用是在编译的时候输出编译错误信息token-sequence,从方便程序员检查程序中出现的错误。例如下面的程序

在编译的时候输出如编译信息
fatal error C1189: #error : No definedConstant Symbol CONST_NAME1
2:#pragma
其语法格式如下:
pragma token-sequence
此指令的作用是触发所定义的动作。如果token-sequence存在,则触发相应的动作,否则忽略。此指令一般为编译系统所使用。例如在Visual C++.Net 中利用# pragma once 防止同一代码被包含多次。
3:#line
此命令主要是为强制编译器按指定的行号,开始对源程序的代码重新编号,在调试的时候,可以按此规定输出错误代码的准确位置。
形式1
语法格式如下:
line constant “filename”
其作用是使得其后的源代码从指定的行号constant重新开始编号,并将当前文件的名命名为filename。例如下面的程序如下:

提示如下的编译信息:
Hello.c(15) : error C2065: ‘CONST_NAME1’ :undeclared identifier
表示当前文件的名称被认为是Hello.c, #line 10 “Hello.c”所在的行被认为是第10行,因此提示第15行出错。
形式2
语法格式如下:
line constant
其作用在于编译的时候,准确输出出错代码所在的位置(行号),而在源程序中并不出现行号,从而方便程序员准确定位。
4:运算符#和##
在ANSI C中为预编译指令定义了两个运算符——#和##。
的作用是实现文本替换(字符串化),例如
#define HI(x)printf(“Hi,”#x”\n”);
void main()
{
HI(John);
}
程序的运行结果
Hi,John
在预编译处理的时候, #x的作用是将x替换为所代表的字符序列。(即把x宏变量字符串化)在本程序中x为John,所以构建新串“Hi,John”。
##的作用是串连接。
例如
#define CONNECT(x,y) x##y
void main()
{
int a1,a2,a3;
CONNECT(a,1)=0;
CONNECT(a,2)=12;
a3=4;
printf(“a1=%d\ta2=%d\ta3=%d”,a1,a2,a3);
}
程序的运行结果为
a1=0 a2=12 a3=4
在编译之前, CONNECT(a,1)被翻译为a1, CONNECT(a,2)被翻译为a2。
数据类型对应字节数
程序运行平台
不同的平台上对不同数据类型分配的字节数是不同的。
个人对平台的理解是CPU+OS+Compiler,是因为:
1、64位机器也可以装32位系统(x64装XP);
2、32位机器上可以有16/32位的编译器(XP上有tc是16位的,其他常见的是32位的);
3、即使是32位的编译器也可以弄出64位的integer来(int64)。
以上这些是基于常见的wintel平台,加上我们可能很少机会接触的其它平台(其它的CPU和OS),所以个人认为所谓平台的概念是三者的组合。
虽然三者的长度可以不一样,但显然相互配合(即长度相等,32位的CPU+32位的OS+32位的Compiler)发挥的能量最大。
理论上来讲 我觉得数据类型的字节数应该是由CPU决定的,但是实际上主要由编译器决定(占多少位由编译器在编译期间说了算)。
常用数据类型对应字节数可用如sizeof(char),sizeof(char*)等得出
32位编译器:
char :1个字节
char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
64位编译器:
char :1个字节
char*(即指针变量): 8个字节
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 8个字节
long long: 8个字节
unsigned long: 8个字节
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: