
for & range 性能对比
1 / 2 / 创建于 5年前
 attitude 的个人博客
attitude 的个人博客
起源
最近在使用 Go 二刷 LeetCode
第一题,两数之和。解题时使用遍历求解,偶然发现使用 for 和 range的 beats不一致,本着深入研究(啥也不懂)的精神,就想对比下两者的性能如何。
本文参考极客兔兔大佬的原创
探索
既然要对比,那就使用数据说话。
GO test 命令不但可以做单元测试,还支持 bench 进行性能对比。具体操作自行研究,本文就不做深究了。
基本命令:
go test -bench .首先验证下 int类型的遍历
func genIntSlice(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, n)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
func BenchmarkForIntSlice(b *testing.B) {
nums := genIntSlice(1024 * 1024)
for i := 0; i < b.N; i++ {
length := len(nums)
var tmp int
for k := 0; k < length; k++ {
tmp = nums[k]
}
_ = tmp
}
}
func BenchmarkRangeIntSlice(b *testing.B) {
nums := genIntSlice(1024 * 1024)
for i := 0; i < b.N; i++ {
var tmp int
for _, num := range nums {
tmp = num
}
_ = tmp
}
}结果如下:
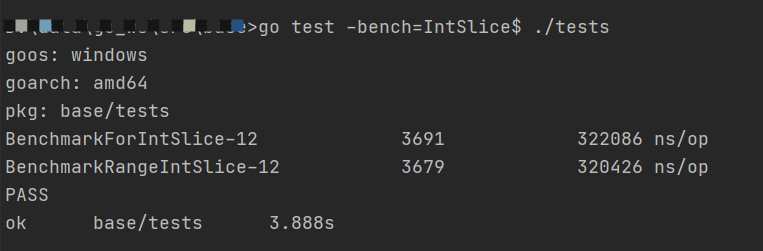
竟然没有差别。难道结论就是两者没有任何区别吗?我们再来验证下复杂点的类型
深入
我们看下对 struct 的遍历有什么区别
type Item struct {
id int
val [4096]byte
}
func BenchmarkForStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
length := len(items)
var tmp int
for k := 0; k < length; k++ {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangeIndexStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
var tmp int
for k := range items {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangeStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
var tmp int
for _, item := range items {
tmp = item.id
}
_ = tmp
}
}结果如下:
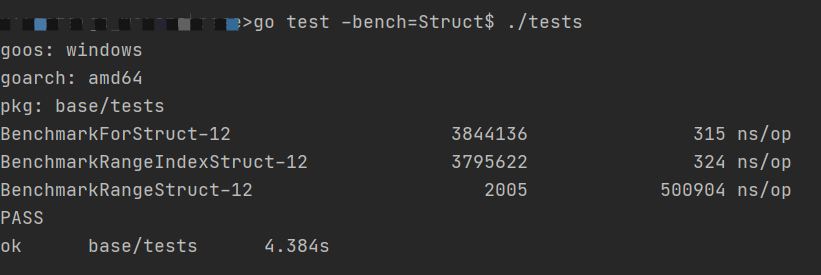
很明显的区别对不对!
- 仅遍历下标的情况下,for 和 range 的性能几乎是一样的。
items的每一个元素的类型是一个结构体类型Item,Item由两个字段构成,一个类型是 int,一个是类型是[4096]byte,也就是说每个Item实例需要申请约 4KB 的内存。- 在这个例子中,for 的性能大约是 range (同时遍历下标和值) 的 2000 倍。
继续深入一下,我们如果遍历指针类型呢?
func generateItems(n int) []*Item {
items := make([]*Item, 0, n)
for i := 0; i < n; i++ {
items = append(items, &Item{id: i})
}
return items
}
func BenchmarkForPointer(b *testing.B) {
items := generateItems(1024)
for i := 0; i < b.N; i++ {
length := len(items)
var tmp int
for k := 0; k < length; k++ {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangePointer(b *testing.B) {
items := generateItems(1024)
for i := 0; i < b.N; i++ {
var tmp int
for _, item := range items {
tmp = item.id
}
_ = tmp
}
}结果如下:
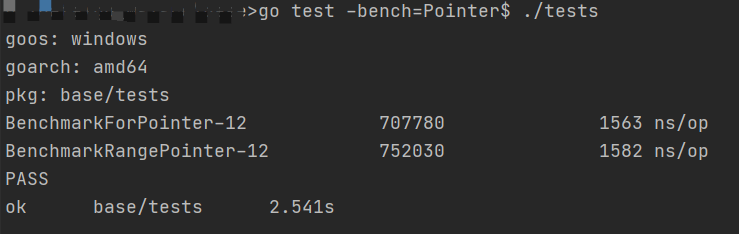
可以看到,几乎没有差别
其实 range在迭代过程中返回的是迭代值的拷贝,这个也可以简单验证下:
persons := []struct{ no int }{{no: 1}, {no: 2}, {no: 3}}
for _, s := range persons {
s.no += 10
}
for i := 0; i < len(persons); i++ {
persons[i].no += 100
}
fmt.Println(persons) // [{101} {102} {103}]最终
range 在迭代过程中返回的是迭代值的拷贝,如果每次迭代的元素的内存占用很低,那么 for 和 range 的性能几乎是一样,例如 []int。但是如果迭代的元素内存占用较高,例如一个包含很多属性的 struct 结构体,那么 for 的性能将显著地高于 range,有时候甚至会有上千倍的性能差异。对于这种场景,建议使用 for,如果使用 range,建议只迭代下标,通过下标访问迭代值,这种使用方式和 for 就没有区别了。如果想使用 range 同时迭代下标和值,则需要将切片/数组的元素改为指针,才能不影响性能。
本作品采用《CC 协议》,转载必须注明作者和本文链接
本帖由系统于 5年前 自动加精













 关于 LearnKu
关于 LearnKu




推荐文章: