
一: 2023 go岗位-跳槽-学习规划(求补充)
166 / 16 / 创建于 3年前 /
 wangchunbo 的个人博客
wangchunbo 的个人博客
进度
2023-05-04 完成基础,base项,文章整理,链接整理。话术整理。
2023-05-05 完成kafka roccketMQ,以及 知识库es的知识点整理与面试话术总结。
未完成 docker,k8s
未完成,微服务,领域驱动
未完成 云原生
2023-05-06 完成 项目疑难问题如何解决。
2023-05-06 增加三次握手 四次挥手 理解,增加b*树,b+树区别
基础面试题
请先完成此文章的题目。再看下面的题。这个题是现在很基础的,很常问的题。
这个人写的很正经,不是打广告,我反正就记录一下。各位也可以找到其他的相关题。然后可以评论,求补充。
www.kancloud.cn/martist/phper-will...
0. laravel 为phper 转go的准备下
laravel 基础面试题 我感觉可以不看,不就那点东西。用了两三年laravel 自然都会。
翻译:91 个常见的 Laravel 面试题和答案
laravel生命周期 一图搞定(讲清楚这个就行)
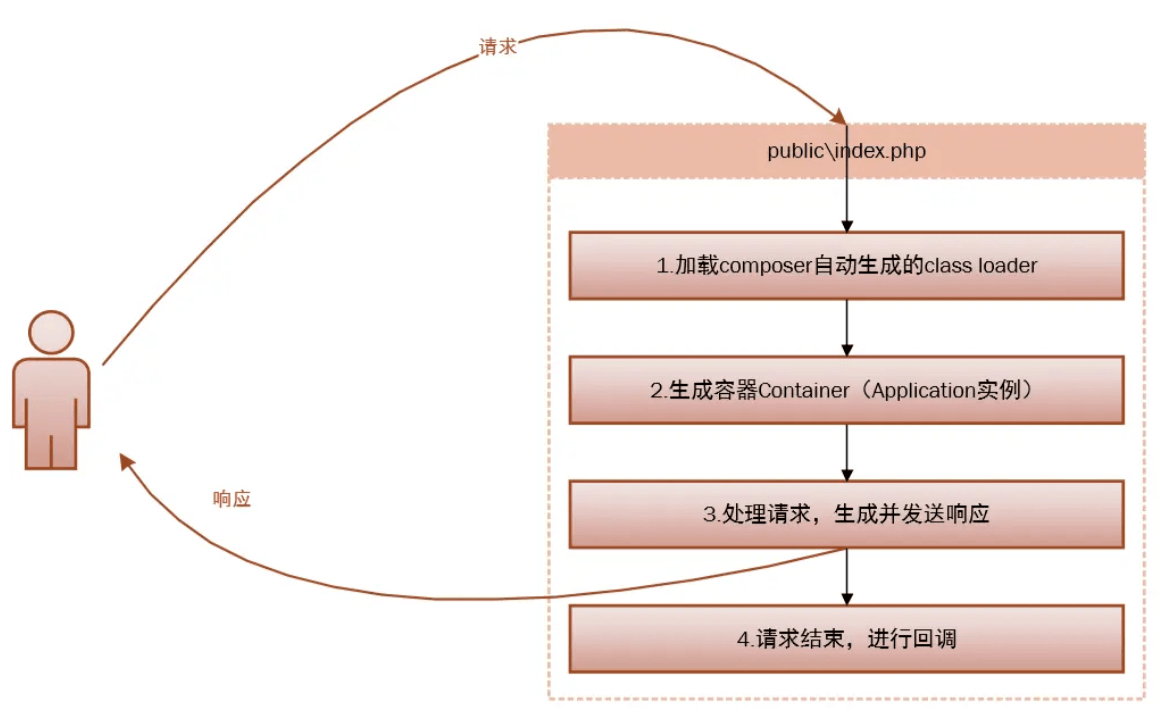
laravel 服务容器:注册基础服务;管理所需创建的类及其依赖。
依赖 依赖注入,控制反转浅显解释:博客:依赖、依赖注入与控制反转 笔记
1. 面试题
topgo讲的细。
www.topgoer.cn/docs/gomianshiti/go...
面试技术点详解拆分
redis部分
包含了redis,但是redis 我认为有更细节的部分(更加易于背诵),请看下文。
博客:[面试题]跳槽面试必背-自己最近5年的整理,欢迎大家补充。
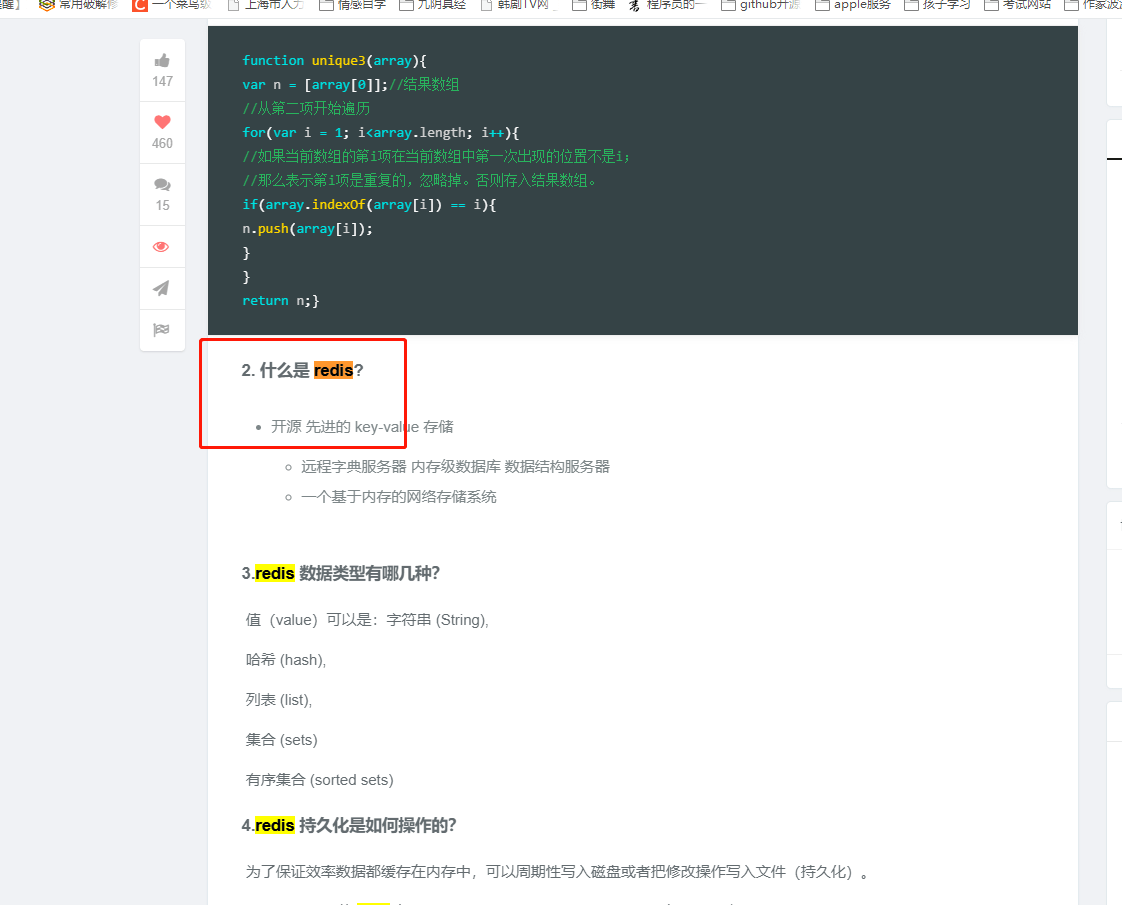
mysql优化,从该文章的 16开始,如下图
博客:[面试题]跳槽面试必背-自己最近5年的整理,欢迎大家补充。
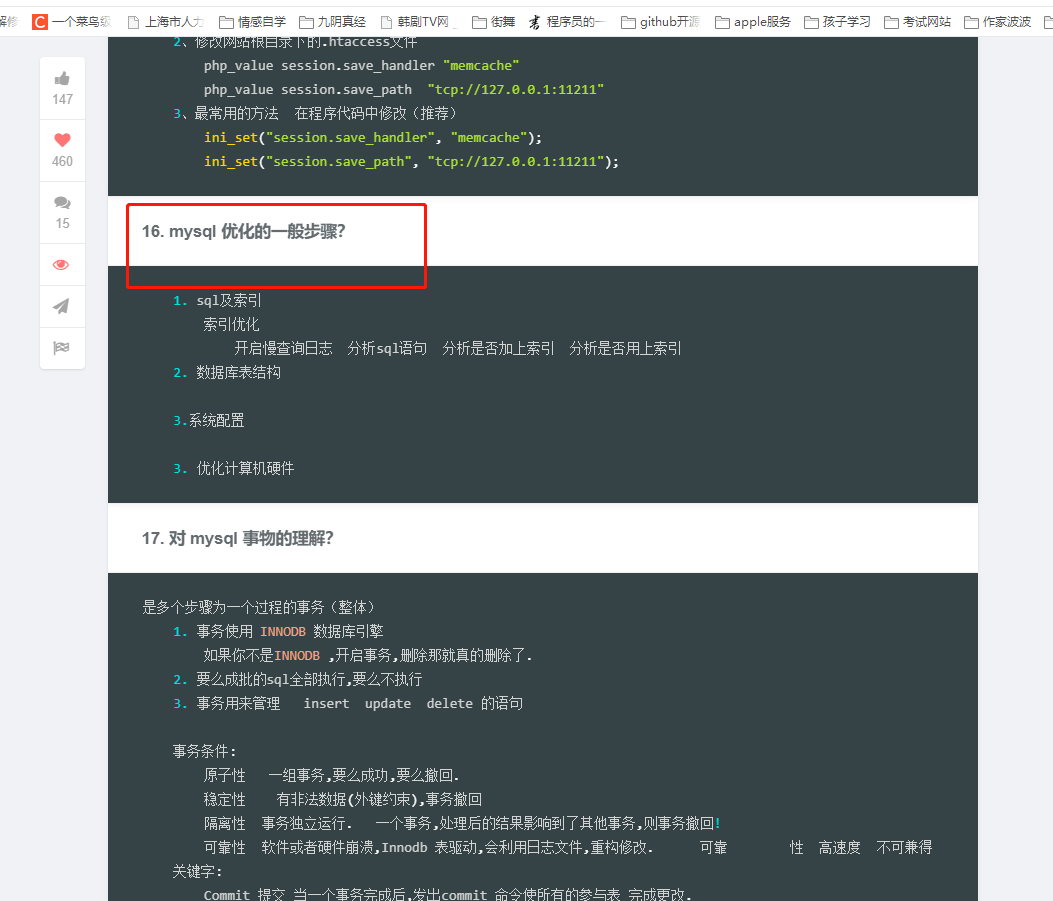
2. go 底层
看幼麟实验室
www.bilibili.com/video/BV1hv411x7w...
3. gin框架(求补充)与设计模式
实际上,我觉得没啥好问的。一般也不至于问你gin咋用吧。工作用用行了。
4. Docker(求补充)
5. GRPC(求补充)
6. 微服务(求补充)
7. k8s(求补充)
8. 云原生 kafka rocketMQ(求补充)
面试题(很多很精要):来自于某知识星球。我就挂个链接。
wx.zsxq.com/dweb2/index/columns/51...
kafuka 面试汇总
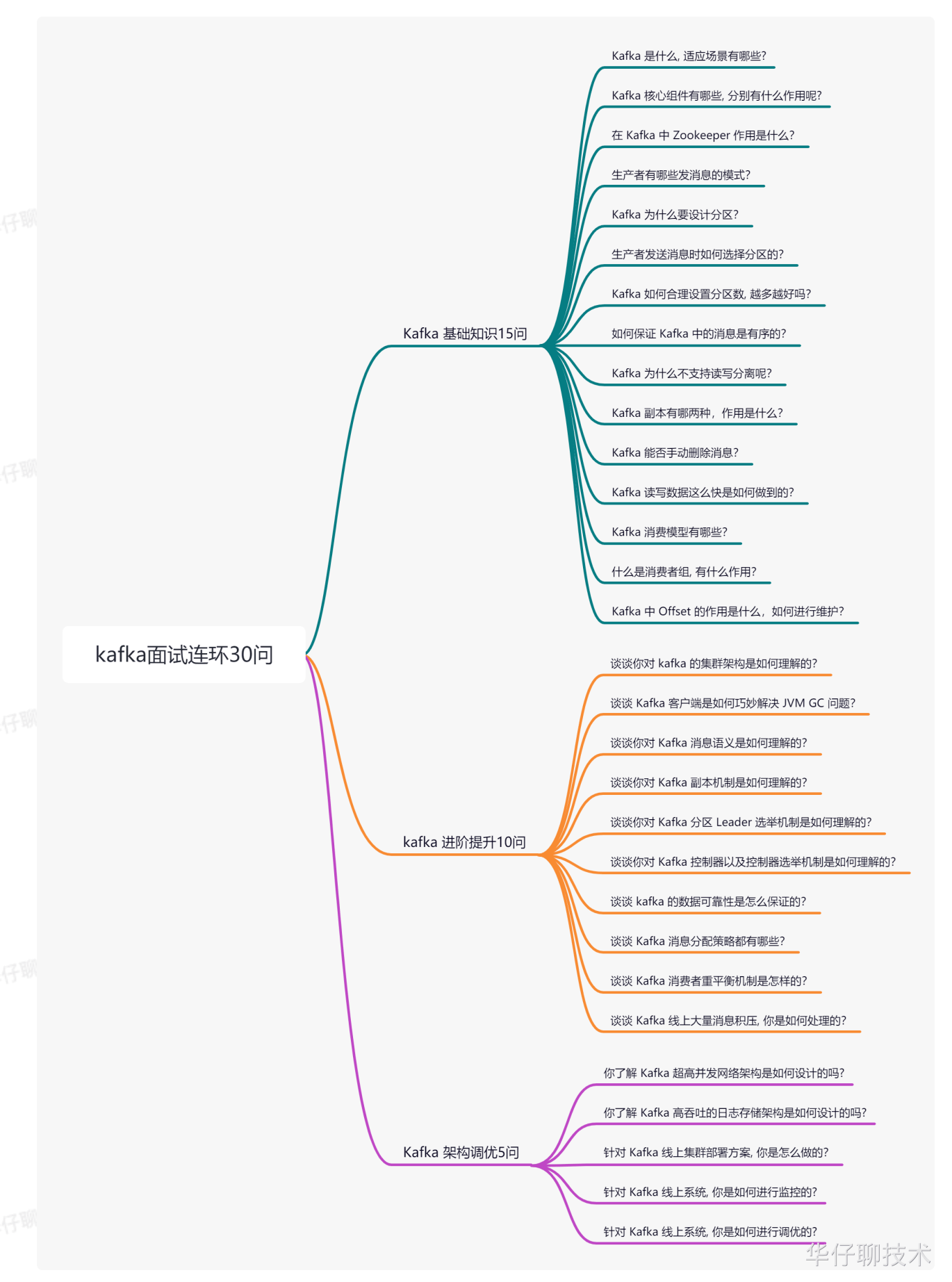
8.1 kafka 使用场景
1)⽇志收集⽅向:可以⽤ Kafka 来收集各种服务的 log,然后统⼀输出,⽐如⽇志系统 elk,⽤ Kafka 进⾏数据中转。(kafka 用于价格变动记录,比如电商爬虫得到的数据)
2)消息系统⽅向:Kafka 具备系统解耦、副本冗余、流量削峰、消息缓冲、可伸缩性、容错性等功能,同时还提供了消息顺序性保障以及消息回溯功能 等。
3)⼤数据实时计算⽅向:Kafka 提供了⼀套完整的流式处理框架, 被⼴泛应⽤到⼤数据处理,如与 flink、spark、storm 等整合 。
来自于华哥的口头解释:
现在都是微服务,服务之间通信都可以用啊,比如你要做一套中间件服务或者开放平台,肯定需要做监控/服务质量相关,就可以通过kafka来接收而不影响业务使用,后面起消费者可以做不同的定制化操作(比如发送到Prometheus做监控、报警等等)。
还有就是针对高并发业务场景,可以直接脱离数据库直接用kafka或者rocketmq来抗并发,消峰,然后后台服务慢慢消费做其他处理
不过大数据用kafka比较多,业务用rocketmq多,我们之前公司基本都是kafka,基础架构部搭建了kafka消息管理平台,做个回调配置地址就可以了,剩下的就是自己写生产者和消费者业务代码,相对比较简单。
8.2 kafka 基础命令
articles.zsxq.com/id_qfjnjwafdxsv....
8.3 rocketMQ 使用场景
跟kafka 差不多。
8.4 rocketMQ 基础命令
articles.zsxq.com/id_o92x7jv3p0tu....
8.5 kafka rocketMQ 等区别 优缺点
rocketMQ 最后一页。
优势:
1 java源码,2支持高级特性多(普通消息」、「顺序消息」、「事务消息」、「消息过滤」、「定时/延时消息」、「消息重试」),3阿里已经在用。
articles.zsxq.com/id_6xttsqfhw9v5....

9. 爬虫
爬虫base面试题1(简单版): blog.csdn.net/AudiA6LV6/article/de...
爬虫base面试题2(专业版):blog.csdn.net/wanlitengfei/article...
10. websocket
11. JWT 与 OAuth2.0
请看博文。这个也要自己整理一段话术。或者全背下来
blog.csdn.net/sssssooo/article/det...
12. Elasticsearch面试题 与 应用场景
基础面试题
blog.csdn.net/QLCZ0809/article/det...
应用场景-知识库 全文检索 todo
13. MogoDB 常用操作 与 应用场景
13.1 应用场景,网站用户来源日志
1. 存日志

先提取出各个字段的值,然后存入,就是一个包含很多个字段的文档。
也支持批量写 db.events.insert([doc1, doc2, ...])
2. 日志分析
可以find 模糊搜索
可以按照time 时间段搜索
3. 日志过大怎么处理。
第一: 设定TTL 索引,过期自动删除
之前网站设置的是3个月过期,同时查询数据存入mysql
MongoDB的TTL索引可以支持文档在一定时间之后自动过期删除。例如上述日志time字段代表了请求产生的时间,针对该字段建立一个TTL索引,则文档会在30小时后自动被删除。db.events.createIndex( { time: 1 }, { expireAfterSeconds: 108000 } )
第二:
定期按集合或DB归档,按照月份 对集合命名。 缺点就是,跨月份查询需要联合查询
详情如下:
比如每到月底就将events集合进行重命名,名字里带上当前的月份,然后创建新的events集合用于写入。比如2016年的日志最终会被存储在如下12个集合里:
events-201601events-201602events-201603events-201604....events-201612
当需要清理历史数据时,直接将对应的集合删除掉:
db["events-201601"].drop()db["events-201602"].drop()
不足之处,在于到时候,如果要查询多个月份的数据,查询的语句会稍微复杂些,需要从多个集合里查询结果来合并。
13.2 基础命令
1. MongoDB 创建数据库的语法格式如下:
use DATABASE_NAME
MongoDB 删除数据库的语法格式如下:
db.dropDatabase()
2.集合操作
MongoDB 中使用 createCollection() 方法来创建集合
查看已有集合,可以使用 show collections 或 show tables 命令:
如何将数据插入到 MongoDB 的集合中。
文档的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
3. 文档
文档的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document) 或 db.COLLECTION_NAME.save(document)update() 更新
remove 删除
find 查询
排序 sort
索引 createIndex
14. rbac 原理与 casbin 以及应用场景
rbac原理
- 五个表,完成权限控制

升级版本增加角色组表. 用户组和角色组进行管理.
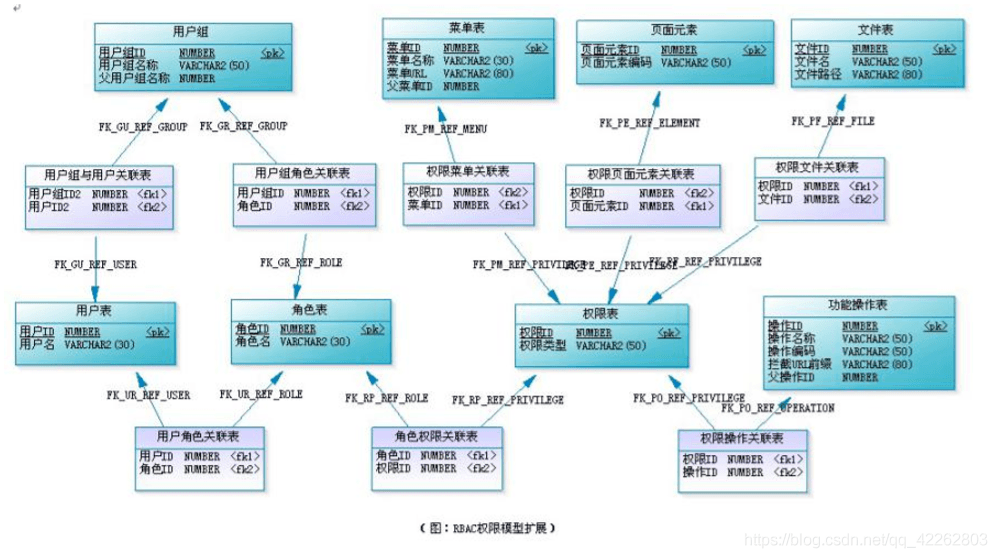
用户组的优点 应用场景。
除了减少工作量,还有更便于理解。
比如按部门建立用户组的例子。一位用户从A部门异动到了B部门,这是实际发生的情况。如果没有用户组,那么我们要拿掉A部门的所有角色,换上B部门的所有角色。
加上用户组之后,只需要操作用户离开A组而加入B组就行了。这与实际情况很贴近。
用户组的理解:
用户组对标的是用户而不是角色,用户组的作用是对用户做一个归类,可以更加方便地授权而已。
譬如你要对多个角色授权,并且这些角色成员存在交集。那么先把这些共同的用户添加到一个用户组,再在角色成员里面添加用户组,总的添加操作次数是x+y,而直接添加用户则是x*y次。这就是用户组的作用。
casbin 应用场景
casbin 支持acl rbac RESTful等。 我们系统中用的是 rbac 与restful(RESTful: ⽀持路径, 如 /res/*, /res/:id 和 HTTP ⽅法, 如 GET, POST, PUT, DELETE)
目前的系统里,构建了一个 rbac服务。
采用互斥角色。
用户-单角色,单角色对对权限节点。
权限节点分为了,菜单,按钮,api。
二开了权限节点,新增了api分类与api表。增加了公共api分类。
把菜单或者按钮与多个api进行关联。一对多。
因为可能某个按钮,有多个api。
在中间件中增加相关的权限判断。
15. 项目中的问题,你是如何解决的
15.1 事务问题例子:
突然的网站访问慢。但是cpu 内存 磁盘资源正常。
这时候经过排查,发现是有两种情况。一是数据库事务占用,二是数据库连接耗尽。
原因大致是: 代码问题,没有回滚,就return。 二是事务执行时间过长,造成数据库链接无法释放。
解决方案是:
- review 减少代码bug。 有err return,则所有地方都加回滚。
- 事务执行过长。要么逻辑移出事务,要么优化这块代码。
- 合理配置超时时间。比如,实在是一次处理几千条数据。那就超时给1分钟。
后面考虑做的,是 kafka 日志,监控。但是还没做。
15.2 安全问题
短信盗刷。
通过验证,发送短信 url,来源标志。判断用户是否合法。
如:url来源、渠道。如百度 360 手机端 pc 端等等。
结合同ip发送短信频率,来进行判断。恶意并发请求。
有的竞争对手,会去网吧。疯狂并发请求网站。消耗资源。
写了个py脚本。如果查看到同ip发起大量请求,则直接禁止访问。
- 数据库漏洞
场景1:之前遇到一个把我们mysql5.6 数据库给干死的。
恢复数据,数据库升级到8.0,改端口,限制ip访问
系统打补丁。
这个是真没太多办法。
场景2:数据丢失,数据误删。
取自动备份前一天的数据,+binlog 恢复。
15.3 爬虫问题
爬虫还是禁不了。
因为你总要有页面输出吧。哪怕代码不能爬,火车头也能爬,谷歌浏览器插件Data Scraper也能爬。
人工也能爬。。。只要别让人家把网站爬的资源不够最好。
后来
开放 api,api数据全是缓存过的。让外人去爬。
16 三次握手 四次挥手
16.1 简单话术
三次握手
我对你 嗨
你对我 嗨
我发出握手邀请。
你收到了,跟我握手。
我,看握住了,我加点力。
你也看,握住了,也加点力
四次挥手
职员问主管,我要下班了。
主管,说,还有事。你得做。或者没事,你收拾东西走吧。
职员,收拾一下或者接着做事。
主管 看职员收拾好走了,主管也准备走了。
16.2 专业术语
简述 TCP 三次握手?
- 服务器进程先创建传输控制块 TCB,并处于监听状态,等待客户端的连接请求
- 客户端创建传输控制块 TCB,并向服务器发出连接请求报文段
- 服务器收到连接请求报文段后,如同意建立连接,则发送确认报文段
- 客户端进程收到服务器的确认报文段后,立即回复确认报文段,并进入已建立连接状态
- 服务器收到确认报文段之后,也进入已建立连接状态
简述TCP 四次挥手?
- 客户端应用进程发出连接释放报文段,并停止再发送数据,进入 FIN-WAIT-1(终止等待1)状态,等待服务器确认
- 服务器收到连接释放报文段后即发出确认,进入 CLOSE-WAIT(关闭等待)状态,服务器若发送数据,客户端扔要接收
- 客户端收到来自服务器的确认后,进入 FIN-WAIT-2(终止等待2)状态,等待服务器发出连接释放报文段
- 服务器没有要发送的数据,发出连接释放报文段,进入 LAST-ACK(最后确认)状态,等待客户端确认
- 客户端收到连接释放报文段后,发出确认,进入 TIME-WAIT(时间等待)状态,经过时间等待计时器设置的时间 2MSL 后,进入 CLOSED(关闭) 状态
- 服务器收到客户端报文段后,进入 CLOSED 状态
17. mysql b*树 与 b+树,为什么选择b+树索引呢?
17.1 B*树又在B+树的基础上产生了一系列的变化,如下:
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3,代替B+树的1/2;B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以B*树相对于B+树,空间利用率上有所提高,查询速率也有所提高。
17.2 为什么MySQL选择B+树做索引
首先 Mysql索引主要有两种结构:B+Tree索引和Hash索引
(a) Inodb存储引擎 默认是 B+Tree索引
(b) MyISAM 存储引擎 默认是Fulltext索引(全文索引);
(c)Memory 存储引擎 默认 Hash索引;
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
4、B+树更适合基于范围的查询:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
本作品采用《CC 协议》,转载必须注明作者和本文链接






























 关于 LearnKu
关于 LearnKu




推荐文章: