
为什么把 dig 迁移到 wire
17 / 0 / 创建于 4年前
 Remember 的个人博客
Remember 的个人博客
开篇
dig 和 wire 都是 Go 依赖注入的工具,那么,本质上功能相似的框架,为什么要从 dig 切换成 wire?
场景
我们从场景出发。
假设我们的项目分层是:router->controller->service->dao。
大概就长这样:

现在我们需要对外暴露一个订单服务的接口。
首页看 main.go 文件。
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"github.com/wuqinqiang/digvswire/dig"
"github.com/wuqinqiang/digvswire/router"
)
func main() {
serverStart()
}
func serverStart() {
defer func() {
if err := recover(); err != nil {
fmt.Printf("init app err:%v\n", err)
}
}()
e := gin.Default()
di := dig.ContainerByDig()
err := router.RegisterRouter(e, di)
if err != nil {
fmt.Printf("register router err:%v", err)
}
_ = e.Run(":8090")
}
这里使用了 gin 启动项目。 然后我们查看 dig.ContainerByDig(),
dig
package dig
import (
"github.com/wuqinqiang/digvswire/controller"
"github.com/wuqinqiang/digvswire/dao"
"github.com/wuqinqiang/digvswire/server"
"go.uber.org/dig"
)
func ContainerByDig() *dig.Container {
d := dig.New()
_ = d.Provide(dao.NewOrderDao)
_ = d.Provide(server.NewOrderServer)
_ = d.Provide(controller.NewOrderHandler)
return d
}
首先通过 dig.New() 创建一个 di 容器。 Provide 函数用于添加服务提供者, Provide 函数第一个参数本质上是一个函数。一个告诉容器 “我能提供什么,为了提供它,我需要什么?” 的函数。
比如我们看第二个 server.NewOrderServer,
package server
import (
"github.com/wuqinqiang/digvswire/dao"
)
var _ OrderServerInterface = &OrderServer{}
type OrderServerInterface interface {
GetUserOrderList(userId string) ([]dao.Order, error)
}
type OrderServer struct {
orderDao dao.OrderDao
}
func NewOrderServer(order dao.OrderDao) OrderServerInterface {
return &OrderServer{orderDao: order}
}
func (o *OrderServer) GetUserOrderList(userId string) (orderList []dao.Order, err error) {
return o.orderDao.GetOrderListById(userId)
}
这里的 NewOrderServer(xxx) 在 Provide 中的语意就是 “我能提供一个 OrderServerInterface 服务,但是我需要依赖一个 dao.OrderDao“。
刚才的代码中,
_ = d.Provide(dao.NewOrderDao)
_ = d.Provide(server.NewOrderServer)
_ = d.Provide(controller.NewOrderHandler)
因为我们的调用链是 controller->server->dao,那么本质上他们的依赖是 controller<-server<-dao,只是依赖的不是具体的实现,而是抽象的接口。
所以你看到 Provide 是按照依赖关系顺序写的。
其实完全没有必要,因为这一步 dig 只会对这些函数进行分析,提取函数的形参以及返回值。然后根据返回的参数来组织容器结构。 并不会在这一步执行传入的函数,所以在 Provide 阶段前后顺序并不重要,只要确保不遗漏依赖项即可。
万事俱备,我们开始注册一个能获取订单的路由,
err := router.RegisterRouter(e, d)
// router.go
func RegisterRouter(e *gin.Engine, dig *dig.Container) error {
return dig.Invoke(func(handle *controller.OrderHandler) {
e.GET("/user/orders", handle.GetUserOrderList)
})
}
此时,调用 invoke, 才是真正需要获取 *controller.OrderHandler 对象。
调用 invoke 方法,会对传入的参数做分析,参数中存在 handle *controller.OrderHandler, 就会去容器中寻找哪个 Provide 进来的函数返回类型是 handle *controller.OrderHandler,
就能对应找到,
_ = d.Provide(controller.NewOrderHandler)
// 对应
func NewOrderHandler(server server.OrderServerInterface) *OrderHandler {
return &OrderHandler{
server: server,
}
}
发现这个函数有形参 server.OrderServerInterface,那就去找对应返回此类型的函数,
_ = d.Provide(server.NewOrderServer)
//对应
func NewOrderServer(order dao.OrderDao) OrderServerInterface {
return &OrderServer{orderDao: order}
}
又发现形参 (order dao.OrderDao),
_ = d.Provide(dao.NewOrderDao)
//对应
func NewOrderDao() OrderDao {
return new(OrderDaoImpl)
}
最后发现 NewOrderDao 没有依赖,不需要再查询依赖。开始执行函数的调用 NewOrderDao(),把返回的 OrderDao 传入到上层的 NewOrderServer(order dao.OrderDao) 进行函数调用, NewOrderServer(order dao.OrderDao) 返回的 OrderServerInterface 继续返回到上层 NewOrderHandler(server server.OrderServerInterface) 执行调用,最后再把函数调用返回的 *OrderHandler 传递给 dig.Invoke(func(handle *controller.OrderHandler) {},
整个链路就通了。用一个简陋的图来描述这个过程 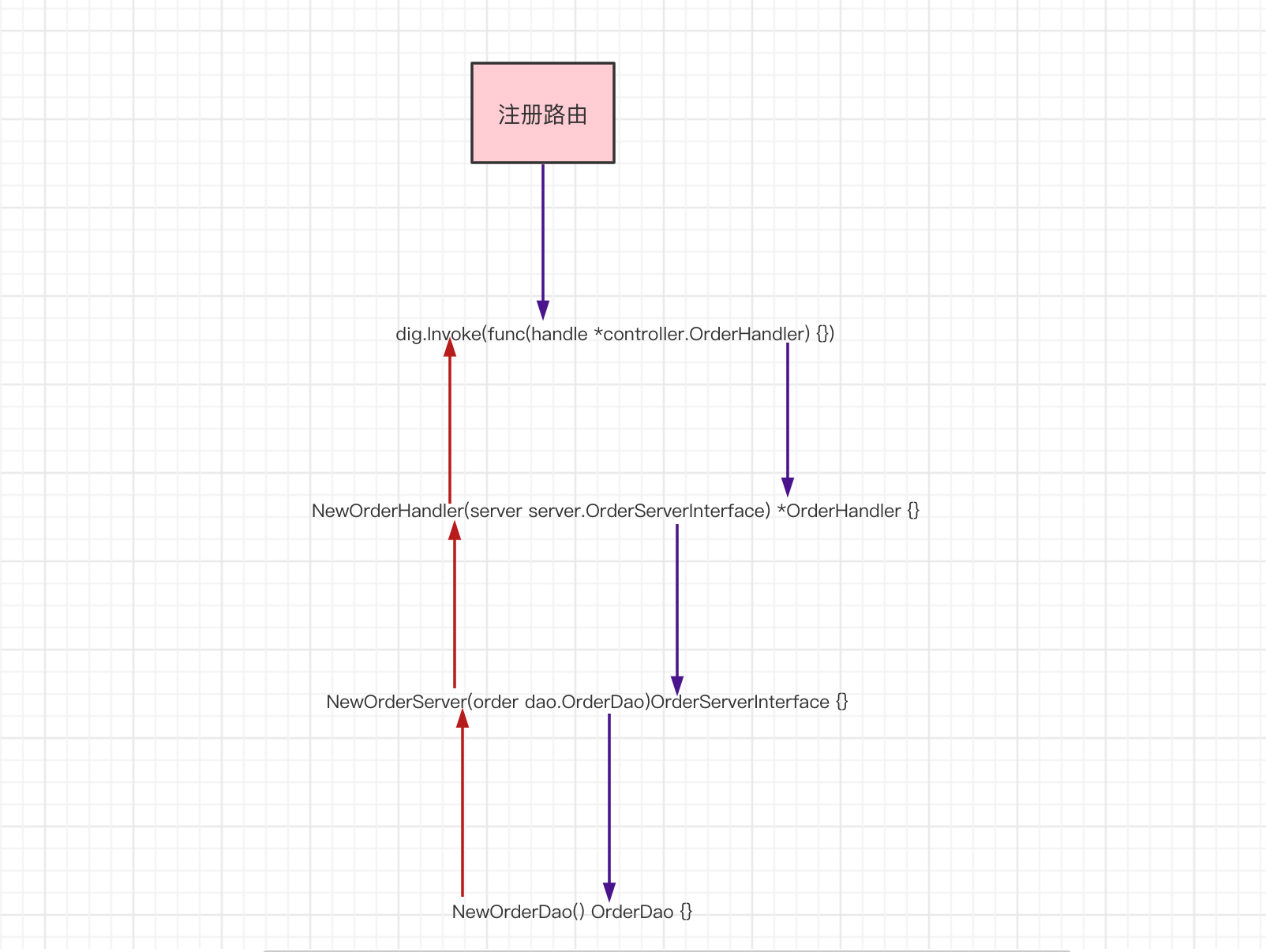
dig 的整个流程采用的是反射机制,在运行时计算依赖关系,构造依赖对象。
这样会存在什么问题?
假设我现在注释掉 Provide 的一行代码,比如,
func ContainerByDig() *dig.Container {
d := dig.New()
//_ = d.Provide(dao.NewOrderDao)
_ = d.Provide(server.NewOrderServer)
_ = d.Provide(controller.NewOrderHandler)
return d
}
我们在编译项目的时候并不会报任何错误,只会在运行时才发现缺少了依赖项。 
wire
还是上面的代码,我们使用 wire 作为我们的 DI 容器。
wire 也有两个核心概念: Provider 和 Injector。
其中 Provider 的概念和 dig 的概念是一样的:”我能提供什么?我需要什么依赖”。
比如下面 wire.go 中的代码,
//+build wireinject
package wire
import (
"github.com/google/wire"
"github.com/wuqinqiang/digvswire/controller"
"github.com/wuqinqiang/digvswire/dao"
"github.com/wuqinqiang/digvswire/server"
)
var orderSet = wire.NewSet(
dao.NewOrderDao,
server.NewOrderServer,
controller.NewOrderHandler)
func ContainerByWire() *controller.OrderHandler {
wire.Build(orderSet)
return &controller.OrderHandler{}
}
其中,dao.NewOrderDao 、server.NewOrderServer 以及 controller.NewOrderHandler 就是 Provider。
你会发现这里还调用 wire.NewSet 把他们整合在一起,赋值给了一个变量 orderSet。
其实是用到 ProviderSet 的概念。原理就是把一组相关的 Provider 进行打包。
这样的好处是:
- 结构依赖清晰,便于阅读。
- 以组的形式,减少
injector里的Build。
至于 injector,本质上就是按照依赖关系调用 Provider 的函数,然后最终生成我们想要的对象(服务)。
比如上面的 ContainerByWire() 就是一个 injector。
那么 wire.go 文件整体的思路就是:定义好 injector,然后实现所需的 Provider。
最后在当前 wire.go 文件夹下执行 wire 命令后,
此时如果你的依赖项存在问题,那么就会报错提示。比如我现在隐藏上面的 dao.NewOrderDao,那么会出现 
如果依赖不存在问题,最终会生成一个 wire_gen.go 文件。
// Code generated by Wire. DO NOT EDIT.
//go:generate go run github.com/google/wire/cmd/wire
//+build !wireinject
package wire
import (
"github.com/google/wire"
"github.com/wuqinqiang/digvswire/controller"
"github.com/wuqinqiang/digvswire/dao"
"github.com/wuqinqiang/digvswire/server"
)
// Injectors from wire.go:
func ContainerByWire() *controller.OrderHandler {
orderDao := dao.NewOrderDao()
orderServerInterface := server.NewOrderServer(orderDao)
orderHandler := controller.NewOrderHandler(orderServerInterface)
return orderHandler
}
// wire.go:
var orderSet = wire.NewSet(dao.NewOrderDao, server.NewOrderServer, controller.NewOrderHandler)
需要注意上面两个文件。我们看到 wire.go 中第一行 //+build wireinject ,这个 build tag 确保在常规编译时忽略 wire.go 文件。 而与之相对的 wire_gen.go 中的 //+build !wireinject。 两个对立的 build tag 是为了确保在任意情况下,两个文件只有一个文件生效, 避免出现 “ContainerByWire() 方法被重新定义” 的编译错误。
现在我们可以真正使用 injector 了,我们在入口文件中替换成 dig。
func serverStart() {
defer func() {
if err := recover(); err != nil {
fmt.Printf("init app err:%v\n", err)
}
}()
e := gin.Default()
err := router.RegisterRouterByWire(e, wire.ContainerByWire())
if err != nil {
panic(err)
}
_ = e.Run(":8090")
}
func RegisterRouterByWire(e *gin.Engine, handler *controller.OrderHandler) error {
e.GET("/v2/user/orders", handler.GetUserOrderList)
return nil
}
一切正常。
当然 wire 有一个点需要注意,在 wire.go 文件中开头几行:
//+build wireinject
package wire
build tag 和 package 他们之间是有空行的,如果没有空行,build tag 识别不了,那么编译的时候就会报重复声明的错误: 
还有很多高级的操作可以自行了解。
总结
以上大体介绍了 go 中 dig 和 wire 两个 DI 工具。其中 dig 是通过运行时反射实现的依赖注入。 而 wire 是根据自定义的代码,通过命令,生成相应的依赖注入代码,在编译期就完成依赖注入,无需反射机制。 这样的好处是:
- 方便排查,如果存在依赖错误,编译时就能发现。而
dig只能在运行时才能发现依赖错误。 - 避免依赖膨胀,
wire生成的代码只包含被依赖的,而dig可能会存在好多无用依赖。 - 依赖关系静态存在源码,便于工具分析。
Reference
[3] medium.com/@dche423/master-wire-cn...
[4] www.cnblogs.com/li-peng/p/14708132...
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: