
为何股票量化交易要用到pandas库?
2 / 0 / 创建于 4年前 /
 Gandedong 的个人博客
Gandedong 的个人博客
欢迎使用社区 Markdown 编辑器写文章!
在学习pandas的时候有时候我会觉得非常奇怪,为什么美国的投资公司这么重视Pandas,甚至在招聘要求上注明量化投资分析师要掌握pandas呢?例如我见到Gelber Group的交易员岗位中,注明了这样的一句话:“经济学、金融、统计学或相关领域的学士学位,且具有以下的编程经验 - Python(NumPy、pandas 和相关库)。”
后来我也去登录一下美股的股票库,觉得是以下几个原因:
首先,美股上市公司的股票量大,全美国大概有2万支上市公司股票,可能有人觉得不是很多,但中国上证加深证加起来也不过5千几只股票,即使再加上香港4千多,也不过是美股一半的体量左右。而要在这一定时间内查找2万只股票中有那些可以在近期进行投资,可以说是一顿非常花时间的操作,而如果能靠计算机分析,这会是一个很有效率的工具。
其次,现金账户交易规则不同。A股主要是当天买的股票最早第二个交易日才能卖(T+1),美股没有此方面的限制, 当日可卖(T+0),这就决定了你必须在最短的时间内决定是否购入和出售手中的股票。而且更厉害的是高频交易的投资公司,平均每次持仓时间极短,用量变来达到质变,甚至还要求交易员自己写计算机程序。所以割起韭菜来,已经不是用人力了,而是自动化收割了。
不过,在中国,现时是没有高频交易这样的事的,因为单日开仓交易量超过10手的,会被纳入“日内开仓交易量异常”等的导常交易行为。
再次,美国股票下跌过程中也有进行对冲的工具,即可以买跌获利,如浑水之类的公司,这个时候,如果想稳健一点,用计算机每天计算出好几个能互冲的投资组合,理论上可以抵挡不少的市场风险,达到持续收益的目的。
所以在美国金融市场,可以见到很多投资公司有一个专门的量化投资部门或量化投资公司,而交易员和分析员大多数是数学出身,或是计算机程序员,他们除了会研究股票,还会研究那类型的CPU能提高交易速度,也会修改代码,努力减少每个bug。因为他们清楚,这些虽然不会让他们赚到多少钱,但往往会减少他们会亏的钱。这就是我们审计中常说的——风险控制比盈利重要。
注意:我是审计师,不是程序员。
国内涉及证券的两个库分别为tushare、baostock,由于tushare需要积分,我只好介绍baostock库,它对个人用户除了能免费使用外,还不需要注册,对初学者比较友好。而且它能提供大量上市公司历年财务数据,行情数据。
如果是Anaconda运行环境,即通过Anaconda prompt进入命令行。
一般我们用Jupyter Notebook的话,就一定要在Anaconda prompt输入pip install baostock才能成功安装。
安装成功后,我们就可以通过baostock接口查询到股票数据,具体使用方法可以到官网查找:http://baostock.com/baostock/index.php/Python_API文档
不过官网的代码只有最基本的功能,且没有中文,一般来说我都会作一些修改,如我的日K线代码:
##历史K线指标
import baostock as bs ##调用baostock库
import pandas as pd ##调用pandas库
# 登陆系统
lg = bs.login()
# 周月线指标:date,code,open,high,low,close,volume,amount,adjustflag,turn,pctChg
#code:股票代码,sh或sz.+6位数字代码
rs = bs.query_history_k_data_plus("sh.000001",
"date,code,open,high,low,close,preclose,volume,amount,pctChg",##以半角逗号分隔。此参数不可为空;
start_date='2017-01-01', end_date='2021-06-30', frequency="d")##查询的起始日
##frequency:数据类型,默认为d,日k线;d=日k线、w=周、m=月、5=5分钟、15=15分钟、30=30分钟、60=60分钟k线数据
# 设定一个空集
data_list = []
while (rs.error_code == '0') & rs.next():##rs.error_code:当为“0”时表示连接成功,当为非0时表示失败;next()返回下一个项目
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())#当以上的条件成立时,将数据放到空集中
result = pd.DataFrame(data_list, columns=rs.fields)##导入pandas中
result.rename(columns={'date':'日期'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'code':'证券号'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'open':'开盘价'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'high':'最高价'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'low':'最低价'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'close':'收盘价'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'preclose':'昨日收盘价'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'volume':'成交数量(股)'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'amount':'成交金额(元)'},inplace=True) #将表头的名称改成统一的名称
result.rename(columns={'pctChg':'涨跌幅'},inplace=True) #将表头的名称改成统一的名称
result["成交金额(元)"].astype(float)
# 输出到excel文件
with pd.ExcelWriter("d:\历史K线指标.xlsx", mode='a',engine='openpyxl') as writer:
result.to_excel(writer,index=False)
print(result)
# 登出系统
bs.logout()结果如下:
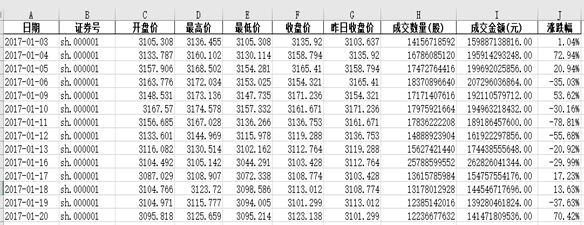
由于我查的是2017年度至2021年6月30日的数据,数据量不多,我直接用EXCEL的图表进行分析。
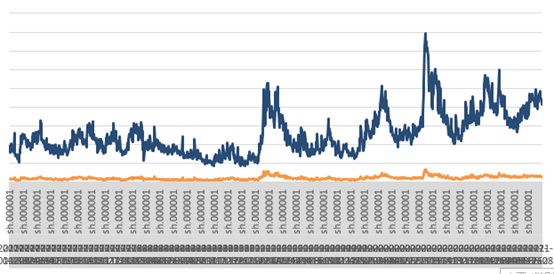
可见,最近几个月上证的成交金额渐渐升高。
代码说明:
1、 lg = bs.login()是必须要用到的代码,没有这一行的话,就不能连接到库,当然没有网络的话也是连接不到的。
2、 bs.query_history_k_data_plus是一个专门用来查询K线指标的函数,在baostock库还有很多不同的函数,主要的函数如下:
| 函数名称 | 作用 |
|---|---|
| query_history_k_data_plus() | 获取沪深A股估值指标(日频)数据(指数未提供估值数据) |
| query_dividend_data() | 获取除权除息信息数据(预披露、预案、正式都已通过) |
| query_adjust_factor() | 获取复权因子信息数据 |
| query_profit_data() | 获取季频盈利能力信息 |
| query_operation_data() | 获取季频营运能力信息 |
| query_growth_data() | 获取季频成长能力信息 |
| query_balance_data() | 获取季频偿债能力信息 |
| query_cash_flow_data() | 获取季频现金流量信息 |
| query_dupont_data() | 获取季频杜邦指数信息 |
| query_performance_express_report() | 获取季频公司业绩快报信息 |
| query_stock_basic() | 获取证券基本资料 |
| query_stock_industry() | 获取行业分类信息 |
| query_sz50_stocks() | 获取上证50成分股信息,更新频率:每周一更新。 |
| query_hs300_stocks() | 获取沪深300成分股信息,更新频率:每周一更新。 |
| query_zz500_stocks() | 获取中证500成分股信息,更新频率:每周一更新。 |
| query_deposit_rate_data() | 获取存款利率 |
| query_loan_rate_data() | 获取贷款利率 |
| query_required_reserve_ratio_data() | 获取存款准备金率 |
| query_money_supply_data_month() | 获取货币供应量 |
| query_shibor_data() | 获取银行间同业拆放利率 |
基本上代码不用改,只改函数命令就可以得出不同的结果。
3、 while (rs.error_code == ‘0’) & rs.next():是一个条件语句,如果不等于0,就表示连接不成功,所以当=0时,和还有下一个数据时,我们可以进行合并。
4、 合并用了append()函数,目的用于在列表末尾添加新的对象,rs.get_row_data()就是这些新的对象了。
5、 result.rename(columns={‘date’:’日期’},inplace=True)是一个将列名替换的语句,意思就是将原来用英文表示的date替换成中文‘日期’。
从这段代码我们可以将baostock库理解成一个固定了格式的爬虫库,使用的目的其实就是为了获得一个数据接口,然后将数据转化成pandas格式,以便我们进行数据分析。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: