
巧用Python的camelot库批量提取PDF发票信息
5 / 1 / 创建于 4年前
 Gandedong 的个人博客
Gandedong 的个人博客
巧用Python的camelot库批量提取PDF发票信息
PDF是一种文档格式,因为这种格式不受操作系统的限制,而且方便保存和传输,所以相关的pdf软件非常受欢迎。目前市场上有很多pdf软件,大部分是阅读类,也有支持对pdf的编辑、转换成Word等功能,但这部分工具不少是收费的。
例如我就很喜欢某个PDF转换软件,买了个终身VIP会员,目的就是将电子发票转换成Excel格式,并提取相关数据。
现在很多增值税普通发票都是电子发票,其格式都是以PDF格式进行保存的,而且相信未来的增值税电子专票也会以PFD格式保存。那么财务能不能将PFD格式的发票信息批量读取到Excel中呢?特别是不花钱的情况下。
例如我从京东中收到几十份电子发票,能不能通过什么办法将其金额、税额一次性的录入到某个Excel文件中呢?
可以的,但问题是python可以操作PDF文件的库有好几个,如PyPDF2、pyPDF4、pikepdf、ReportLab、pdfplumber、PyMuPDF等,那么我们应该选择哪一个库为我们工作呢?
因为不是所有PDF库都能读取所有版本的电子发票,有些库只能读取2018年之前的版本,有些库对2019年的发票不能读取中文等等。
例如用pdfplumber库,我们读取中石化的电子发票时,只能读取数字。
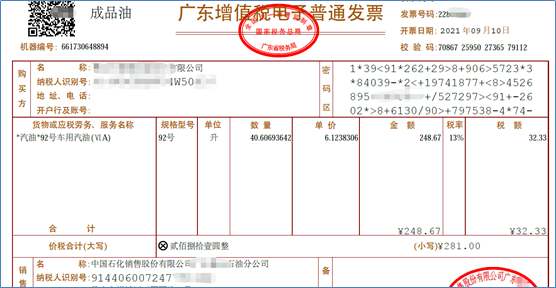
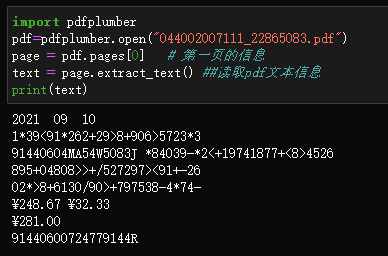
用pdfplumber库的话,虽然可以读取中文,但不能解析表格:
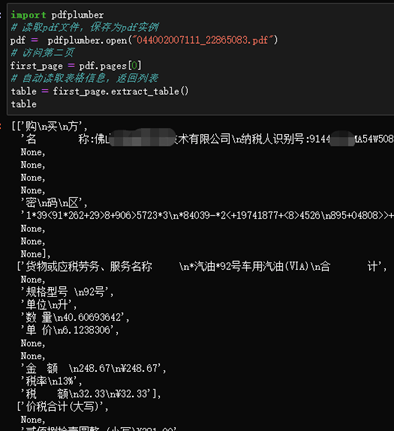
我们的电子发票上面,除了有文本、表格、图片,我们需要读取以上的这些信息,还还需要有解析表格的功能。当然,其他的Python库也可以读取,但为了减少读取时出现错误,我建议选择用camelot库来读取发票。
Camelot译文为卡美洛,是阿瑟王传说中的城堡,但在python库中,这是一个PDF表格读取库,而且比较冷门,不过非常适合用来提取发票。它能将每个PDF表格提取到Pandas DataFrame 中,对数据分析非常方便,更让人满意的是能比较准确的识别中文。
设计camelot库是一位叫做维纳亚克·梅塔的印度电脑工程师,是一位印度90后。从事数据分析的工作。如果对这个库有什么疑问的,可以在Github留言给它。老实说,这个库的安装比较麻烦,我也走了不少弯路,以下是我的安装总结:
千万不要用pip install camelot来安装,因为即使安装成功了也会报错,正确的方法是在Anaconda中用conda install -c conda-forge camelot-py命令。
不要用PIP安装,不然的话会非常麻烦,安装成功之后,你就等于安装了一套python库,包括PyPDF2库、 camelot库、ghostscript库、opencv库、 pdfminer.six-库、 pdftopng库、以及tabulate库。
另外安装后,需要到www.ghostscript.com/download/gsdnl...官网安装Ghostscript软件,不然的话会报错,由于我是Win10的,选择用64bit。安装成功后记得重启电脑。
这个时候我们再用camelot去读取发票,就会发现已经转变成表格格式。
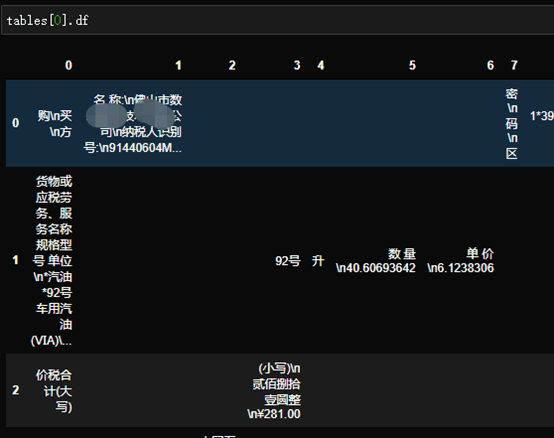
现在,我先介绍一下这个库的基本操作。
import camelot #导入库
tables = camelot.read_pdf('发票名称.pdf')
tables[0].df ##用提取表格显示其中tables[0]表示第一张表格,如果是tables[1]表示第二张表格,.df表示用pandas方式显示表格。
默认情况下,Camelot库只会对PDF 的第一页来提取表格。如果要指定多个页面,您可以使用pages关键字参数:
camelot.read_pdf(‘发票名称.pdf’, pages=’1,2,3’)##提取1,2,3页的表格,或者用
camelot.read_pdf(‘发票名称.pdf’, pages=’1-3’)或者pages=’1-end’都可以。
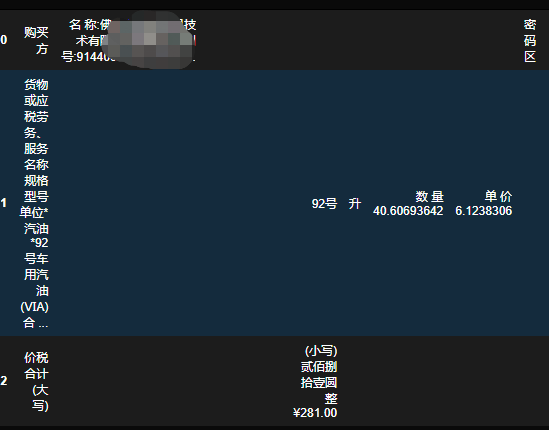
导入之后,如果我们发现有一些不需要的字符,如空格、点和换行符之类的,我们可以用strip_text参数去除。
tables = camelot.read_pdf(‘发票名称.pdf’, strip_text=’ \n’)
tables[0].df
运行如下:
但是我发现这种单元格不好看,好像有些单元格没有拆分一样,这时我们可以加上shift_text=[‘’]这个参数,让各行列分组更紧密。
tables = camelot.read_pdf(‘044002007111_22865083.pdf’,shift_text=[‘’],strip_text=’\n’)
tables[0].df
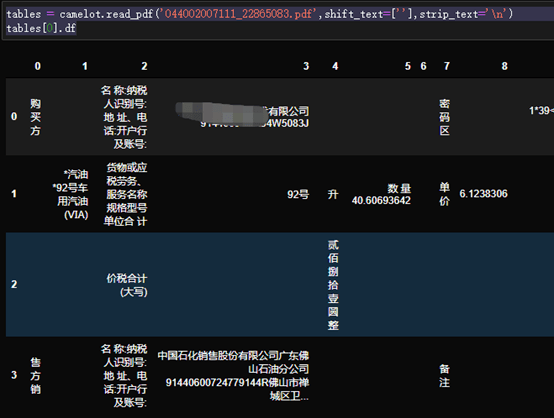
这个时候,基本上发票的数据可以出来了。
我们可以用tables[0].to_csv(‘发票.csv’)来保存,或用to_excel()为Excel格式。

如果是非常多的发票呢?这是一个非常有现实意义的问题,相信不少的出纳会希望有一款软件能批量读取发票,然后将其转化成Excel文件。以下是我分享的代码,希望可以帮到大家。
##批量读取发票,然后汇总成一个CSV文件
import camelot
import pandas as pd
import os
##定义文件夹位置
directoryPath = r'E:\py读取pdf发票汇总'##如果改为=os.getcwd()表示当前文件夹
os.chdir(directoryPath)
print(os.listdir())##列取该文件夹下所有文件名称
folderList = os.listdir(directoryPath)
for folders, sub_folders, file in os.walk(directoryPath): ##所有文件的路径
for name in file: ##定义所需文件名
if name.endswith(".pdf"): ##如果文件名是以.pdf结束的话
filename = os.path.join(folders,name) ##定义这条路径
print(filename)##输出文件路径
print(name)##输出文件名
tables = camelot.read_pdf(filename,shift_text=[''],strip_text='\n')##读取pdf文件,
df01= tables[0].df##转换为DF表格
#df01.to_excel('{name}.xlsx',sheet_name=name)
df01.to_csv('foo2.csv',mode="a",encoding="utf_8_sig")##保存为CSV格式,以直接使参数mode='a’实现每个表追加数据。
除了能读取发票之外,也可以读取申报表。在电子税务局,我们可以查询以及下载已经申报的申报表,包括增值税申报表、所得税申报表以及综合申报表等。这些报表不是Excel格式的,全部都是PDF格式的。如果只做一家公司的账当然是没有问题的,但如果是好几家公司的账,要核对每个月的申报表以及每家子公司的申报表时,这就麻烦了。
旧的方法是一张一张的打印下来,然后逐张分析。好一点的用商业化PDF转化软件,批量将PDF转化成Excel文件,然后再分类汇总,数据透视等等。不过如果安装了Camelot之后,你就可以用这个库直接在PDF文件夹抓取数据,直接用Pandas库进行分析。而且更方便的是,可以设定好脚本程序,解决重复分析的问题。
我用一个例子来说明一下:
import pandas as pd
import camelot
import os
directoryPath =os.getcwd()
folderList = os.listdir(directoryPath)
for name in folderList:
if '增值税'and".pdf" in name:
filename = os.path.join(directoryPath,name)
print(filename)##输出文件路径
print(name)##输出文件名
tables = camelot.read_pdf(name,pages='1')##读取pdf文件,
tables[0].df
df01=tables[0].df
df02=df01.iloc[[4,5,9]]
df02
运行后:

特别要注意的是,你要保证你浏览器内的pdf版本为最新版,我见到有的同事用其他浏览器下载的申报表文件,因为版本原因不能被Camelot读取,而相同的申报表,我却可以读取。这显然是保存PDF文件时出现问题。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: