
MySQL调优之查询优化
3 / 2 / 创建于 4年前 /
 PHPer技术栈 的个人博客
PHPer技术栈 的个人博客
一、查询慢的原因
1、网络
(1)网络丢包,重传
这个比较容易理解。当SQL 从客户端发送到数据库,执行完毕,数据库将结果返回给客户端,这个将数据返回给客户端的过程本质是网络包传输。因为链路的不稳定性,如果在传输过程中发送丢包会导致数据包重传,进而增加数据传输时间。从客户端来看,就会觉得SQL 执行慢。
(2)网卡满 比如大字段
如果公司业务体量很大,比如平时每天300w订单的电商平台,平台大促(双十一,618)的时候极有可能出现网卡被打满。网卡带宽被占满类似各种节假日高速公路收费站(网卡)拥堵导致车流(数据包传输的速度)行动缓慢。
(3)网络链路变长
该场景会影响应用纬度的一个事务比如交易下单整体耗时。
我们知道每个节点之间的数据传输是需要时间的,比如同城跨机房(15KM)之间的访问一般网络耗时1.5ms左右。
链路1 [client1]–调用–[client2]—[proxy]—[db] 相比 链路2[client1] – [proxy] –[db]
执行一条sql请求会增加 [client1]–[client2]之间的网络传输耗时大约3ms。如果一个业务事件包含30个sql ,那么链路1要比链路2 多花至少90ms的时间成本。导致业务整体变慢。
2、CPU
(1)cpu 电源策略
cpu 电源策略是控制cpu运行在哪种模式下的耗电策略的,对于数据库服务器推荐最大性能模式 以下内容摘自 《Red Hat Enterprise Linux7 电源管理指南》
ASPM(Active-State Power Management,活动状态电源管理)能节省 PCI Express(PCIe,Peripheral Component Interconnect Express)子系统的电量,其原理为当 PCIe 连接没有处于使用状态时将其设定为低功率状态。ASPM 可以同时控制连接两端的电源状态,并且在连接终端的设备处于满电状态的情况下,仍然可以节电。
启用 ASPM 时,在不同电源状态间转换连接时需要时间,因此会增加设备延迟。ASPM 有三种决定电源状态的策略:
默认(default)
根据系统固件(例如:BIOS)指定的默认设置设定 PCIe 连接的电源状态。这是 ASPM 的默认状态。
节电(powersave)
将 ASPM 设定为尽可能节电,不考虑性能损失。
性能(performance)
禁用 ASPM 使 PCIe 链接以最佳性能操作。
使用 pcie_aspm kernel 参数可以启用或者禁用 ASPM,其中 pcie_aspm=off 会禁用 ASPM,而 pcie_aspm=force 会启用 ASPM,即使在不支持 ASPM 的设备中也可以。
ASPM 策略在 /sys/module/pcie_aspm/parameters/policy 中设置,但还可以使用 pcie_aspm.policy kernel 参数在启动时指定,其中 pcie_aspm.policy=performance 将设定 ASPM 性能策略。
(2)CPU被消耗
CPU的消耗如图:
用户
用户空间CPU消耗,各种逻辑运算
正在进行大量tps
函数/排序/类型转化/逻辑IO访问…
用户空间消耗大量cpu,产生的系统调用是什么?那些函数使用了cpu周期?
IO等待
等待IO请求的完成
此时CPU实际上空闲
如vmstat中的wa 很高。但IO等待增加,wa也不一定会上升(请求I/O后等待响应,但进程从核上移开了)
3、IO
(1)磁盘IO被其他任务占用
有些备份策略为了减少备份空间的使用,基于xtrabckup备份的时候 使用了compress选项将备份集压缩。当我们需要在数据库服务器上恢复一个比较大的实例,而解压缩的过程需要耗费cpu和占用大量io导致数据库实例所在的磁盘io使用率100%,会影响MySQL 从磁盘获取数据的速度,导致大量慢查询。
(2)raid卡 充放电,raid 卡重置
RAID卡都有写cache(Battery Backed Write Cache),写cache对IO性能的提升非常明显,因为掉电会丢失数据,所以必须由电池提供支持。电池会定期充放电,一般为90天左右,当发现电量低于某个阀值时,会将写cache策略从writeback置为writethrough,相当于写cache会失效,这时如果系统有大量的IO操作,可能会明显感觉到IO响应速度变慢,cpu 队列堆积系统load飙高。
(3)IO调度算法
noop(电梯式调度策略):
NOOP实现了一个FIFO队列,它像电梯的工作方式一样对I/O请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一个介质。NOOP倾向于饿死读而利于写,因此NOOP对于闪存设备,RAM以及嵌入式是最好的选择。
deadline(介质时间调度策略):
Deadline确保了在一个截至时间内服务请求,这个截至时间是可调整的,而默认读期限短于写期限。这样就防止了写操作因为不能被读取而饿死的现象。Deadline对数据库类应用是最好的选择。
anticipatory(预料I/O调度策略):
本质上与Deadline一样,但在最后一次读操作后,要等待6ms,才能继续进行对其他I/O请求进行调度。它会在每个6ms中插入新的I/O操作,而会将一些小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量。AS适合于写入较多的环境,比如文件服务器,AS对数据库环境表现很差。
4、上下文切换
(1)什么叫上下文切换?
假设有三个CPU,每个CPU核心数是4,那么物理核心数:3*4 = 12(个)
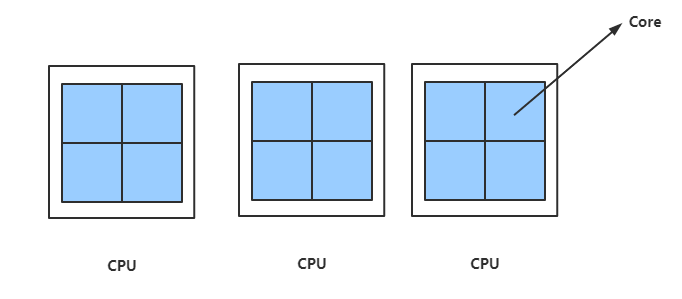
这个核是指CPU里面的Core,可以理解为是将四个CPU封装在一起,但是有的CPU具有超线程的技术,一个核可以模拟出两个两个虚拟核,上面的12个物理核可以让操作系统认为有24个核,同是并行执行24个任务,注意:实际上一个核(Core)只能同时执行一个任务,多个任务同时执行的话,会在Core上高速切换。
为什么要超线程?
超线程这个概念是Intel提出的,简单来说是在一个CPU上真正的并发两个线程,听起来似乎不太可能,因为CPU都是分时的啊,其实这里也是分时,因为前面也提到一个CPU除了处理器核心还有其他设备,一段代码执行过程也不光是只有处理器核心工作,如果两个线程A和B,A正在使用处理器核心,B正在使用缓存或者其他设备,那AB两个线程就可以并发执行,但是如果AB都在访问同一个设备,那就只能等前一个线程执行完后一个线程才能执行。实现这种并发的原理是 在CPU里加了一个协调辅助核心,根据Intel提供的数据,这样一个设备会使得设备面积增大5%,但是性能提高15%~30%。
线程切换,涉及到一个问题,如果CPU在ABA这样切换的话,第二次执行到A,如何确定从哪儿开始执行呢?
在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做CPU 上下文。
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
(2)寄存器为什么会影响CPU 性能?
CPU 上下文切换无非就是更新了 CPU 寄存器的值,但这些寄存器,本身就是为了快速运行任务而设计的,为什么会影响系统的 CPU 性能呢?
我们都知道线程上下文切换,这儿的线程是指任务,任务包括哪些呢?线程以及进程,还有其他的吗?硬件通过触发信号,会导致中断处理程序的调用,也是一种常见的任务。
所以根据任务的不同,CPU 的上下文切换就可以分为进程上下文切换、线程上下文切换以及中断上下文切换。
(3)进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
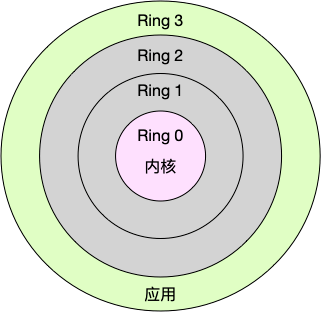
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。从用户态到内核态的转变,需要通过系统调用来完成。内核空间态资源包括内核的堆栈、寄存器等;用户空间态资源包括虚拟内存、栈、变量、正文、数据等。
(4)线程上下文切换
在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
进程是操作系统的管理单位,而线程则是进程的管理单位;一个进程至少包含一个执行线程。不管是在单线程还是多线程中,每个线程都有一个程序计数器(记录要执行的下一条指令),一组寄存器(保存当前线程的工作变量),堆栈(记录执行历史,其中每一帧保存了一个已经调用但未返回的过程)。虽然线程寄生在进程中,但与他的进程是不同的概念,并且可以分别处理:进程是系统分配资源的基本单位,线程是调度CPU的基本单位。
一个线程指的是进程中一个单一顺序的控制流,一个进程中可以并行多个线程,每条线程并行执行不同的任务。每个线程共享堆空间,拥有自己独立的栈空间。
- 线程划分尺度小于进程,线程隶属于某个进程;
- 进程是CPU、内存等资源占用的基本单位,线程是不能独立占有这些资源的;
- 进程之间相互独立,通信比较困难,而线程之间共享一块内存区域,通信方便;
- 进程在执行过程中,包含:固定的入口、执行顺序和出口,而进程的这些过程会被应用程序控制;

(5)中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。
中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
5、系统调用
(1)系统调用是什么?
定义:用户在编程时,可以调用的操作系统功能。全称:操作系统功能调用。从用户态进入内核态。
具体来说:当你的代码需要做IO操作(open、read、write)、或者是进行内存操作(mmpa、sbrk)、甚至是说要获取一个系统时间(gettimeofday),就需要通过系统调用来和内核进行交互。只要程序是建立在Linux内核之上的,就绕不开系统调用。
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境来使应用程序具有更好的兼容性。
为了达到这个目的,内核提供一系列具备预定功能的多内核函数,通过一组称为系统调用(system call)的接口呈现给用户。系统调用把应用程序的请求传给内核,调用相应的的内核函数完成所需的处理,将处理结果返回给应用程序。
现代的操作系统通常都具有多任务处理的功能,通常靠进程来实现。由于操作系统快速的在每个进程间切换执行,所以一切看起来就会像是同时的。同时这也带来了很多安全问题。因此操作系统必须保证每一个进程都能安全的执行。这一问题的解决方法是在处理器中加入基址寄存器和界限寄存器。这两个寄存器中的内容用硬件限制了对储存器的存取指令所访问的储存器的地址。这样就可以在系统切换进程时写入这两个寄存器的内容到该进程被分配的地址范围,从而避免恶意软件。
为了防止用户程序修改基址寄存器和界限寄存器中的内容来达到访问其他内存空间的目的,这两个寄存器必须通过一些特殊的指令来访问。
通常,处理器设有两种模式:“用户模式”与“内核模式”,通过一个标签位来鉴别当前正处于什么模式。一些诸如修改基址寄存器内容的指令只有在内核模式中可以执行,而处于用户模式的时候硬件会直接跳过这个指令并继续执行下一个。
同样,为了安全问题,一些I/O操作的指令都被限制在只有内核模式可以执行,因此操作系统有必要提供接口来为应用程序提供诸如读取磁盘某位置的数据的接口,这些接口就被称为系统调用。
### (2)为什么系统调用会影响性能
当操作系统接收到系统调用请求后,会让处理器进入内核模式,从而执行诸如I/O操作,修改基址寄存器内容等指令,而当处理完系统调用内容后,操作系统会让处理器返回用户模式,来执行用户代码。
系统调用必须通过软中断机制(异常处理机制)首先进入系统核心,然后才能转向相应的命令处理程序。
在采用抢先式调度的系统中,当系统调用返回时,要重新进行调度分析――是否有更高优先级的任务就绪。
系统调用的调用过程和被调用过程运行在不同的状态。
系统调用花在内核态用户态的切换上的时间是差不多的,但区别在于不同的系统调用当进入到内核态之后要处理的工作不同,呆在内核态里的时候相差较大。
6、生成统计信息
(1)统计信息概念
MySQL统计信息是指数据库通过采样、统计出来的表、索引的相关信息,例如,表的记录数、聚集索引page个数、字段的Cardinality….。MySQL在生成执行计划时,需要根据索引的统计信息进行估算,计算出最低代价(或者说是最小开销)的执行计划.MySQL支持有限的索引统计信息,因存储引擎不同而统计信息收集的方式也不同. MySQL官方关于统计信息的概念介绍几乎等同于无,不过对于已经接触过其它类型数据库的同学而言,理解这个概念应该不在话下。相对于其它数据库而言,MySQL统计信息无法手工删除。MySQL 8.0之前的版本,MySQL是没有直方图的。
详细介绍参考:MySQL的统计信息学习总结
7、锁等待时间
数据被其他访问锁住了,等待锁释放
二、优化数据访问
查询性能低下的主要原因是访问的数据太多,某些查询不可避免的需要筛选大量的数据,我们可以通过减少访问数据量的方式进行优化
主要就是看是否向数据库请求了不需要的数据
1、减少请求的数据量
1.只返回必要的列:最好不要使用 SELECT * 语句。
2.只返回必要的行:使用 LIMIT 语句来限制返回的数据。
3.缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2、减少服务器端扫描的行数
例如使用索引来覆盖查询。
3、切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
`DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);`
`rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0` 4、分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
1.让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
2.分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
3.减少锁竞争;
4.在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
5.查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);`三、执行过程的优化
1、查询缓存
在解析一个查询语句之前,如果查询缓存是打开的,那么mysql会优先检查这个查询是否命中查询缓存中的数据,如果查询恰好命中了查询缓存,那么会在返回结果之前会检查用户权限,如果权限没有问题,那么mysql会跳过所有的阶段,就直接从缓存中拿到结果并返回给客户端
2、查询优化处理
mysql查询完缓存之后会经过以下几个步骤:解析SQL、预处理、优化SQL执行计划,这几个步骤出现任何的错误,都可能会终止查询
(1)、语法解析器和预处理
mysql通过关键字将SQL语句进行解析,并生成一颗解析树,mysql解析器将使用mysql语法规则验证和解析查询,例如验证使用使用了错误的关键字或者顺序是否正确等等,预处理器会进一步检查解析树是否合法,例如表名和列名是否存在,是否有歧义,还会验证权限等等
(2)、查询优化器
当语法树没有问题之后,相应的要由优化器将其转成执行计划,一条查询语句可以使用非常多的执行方式,最后都可以得到对应的结果,但是不同的执行方式带来的效率是不同的,优化器的最主要目的就是要选择最有效的执行计划。
mysql使用的是基于成本的优化器(还有一个基于规则的优化器),在优化的时候会尝试预测一个查询使用某种查询计划时候的成本,并选择其中成本最小的一个。
3、查询优化器
select count(*) from film_actor;
show status like ‘last_query_cost’;
可以看到这条查询语句大概需要做1104个数据页才能找到对应的数据,这是经过一系列的统计信息计算来的
这些信息包括:
- 每个表或者索引的页面个数
- 索引的基数
- 索引和数据行的长度
- 索引的分布情况
索引基数(cardinality):索引中不重复的索引值的数量; 例如,某个数据列包含值1、3、7、4、7、3,那么它的基数就是4。
(1)优化器的优化策略
静态优化
直接对解析树进行分析,并完成优化
动态优化
动态优化与查询的上下文有关,也可能跟取值、索引对应的行数有关
注意
mysql对查询的静态优化只需要一次,但对动态优化在每次执行时都需要重新评估
(2)优化器的优化类型
重新定义关联表的顺序
数据表的关联并不总是按照在查询中指定的顺序进行,决定关联顺序时优化器很重要的功能
将外连接转化成内连接,内连接的效率要高于外连接
使用等价变换规则,mysql可以使用一些等价变化来简化并规划表达式
优化count(),min(),max()
索引和列是否可以为空通常可以帮助mysql优化这类表达式:例如,要找到某一列的最小值,只需要查询索引的最左端的记录即可,不需要全文扫描比较
预估并转化为常数表达式,当mysql检测到一个表达式可以转化为常数的时候,就会一直把该表达式作为常数进行处理
explain select film.film_id,film_actor.actor_id from film inner join film_actor using(film_id) where film.film_id = 1索引覆盖扫描,当索引中的列包含所有查询中需要使用的列的时候,可以使用覆盖索引
子查询优化
mysql在某些情况下可以将子查询转换一种效率更高的形式,从而减少多个查询多次对数据进行访问,例如将经常查询的数据放入到缓存中
等值传播
如果两个列的值通过等式关联,那么mysql能够把其中一个列的where条件传递到另一个上:
`explain select film.film_id from film inner join film_actor using(film_id
) where film.film_id > 500;`
这里使用film_id字段进行等值关联,film_id这个列不仅适用于film表而且适用于film_actor表
`explain select film.film_id from film inner join film_actor using(film_id
) where film.film_id > 500 and film_actor.film_id > 500;`
(3)关联查询
mysql的关联查询很重要,但其实关联查询执行的策略比较简单:mysql对任何关联都执行嵌套循环关联操作,即mysql先在一张表中循环取出单条数据,然后再嵌套到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。mysql会尝试再最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行之后,mysql返回到上一层次关联表,看是否能够找到更多的匹配记录,以此类推迭代执行。整体的思路如此,但是要注意实际的执行过程中有多个变种形式
join的实现方式原理
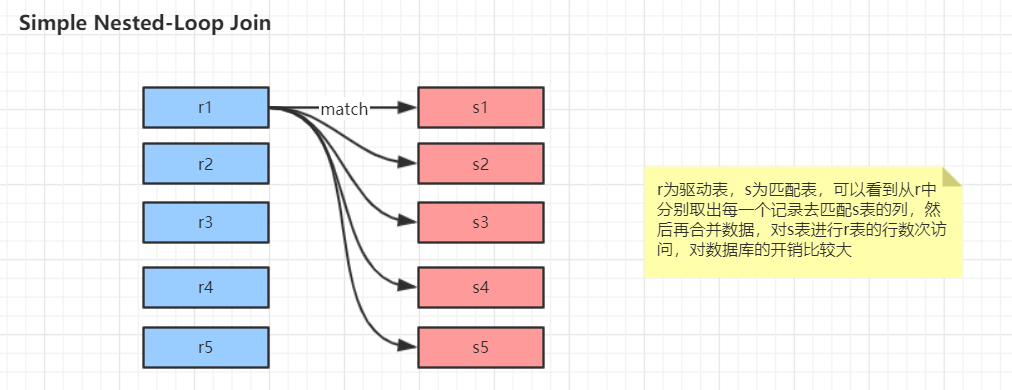
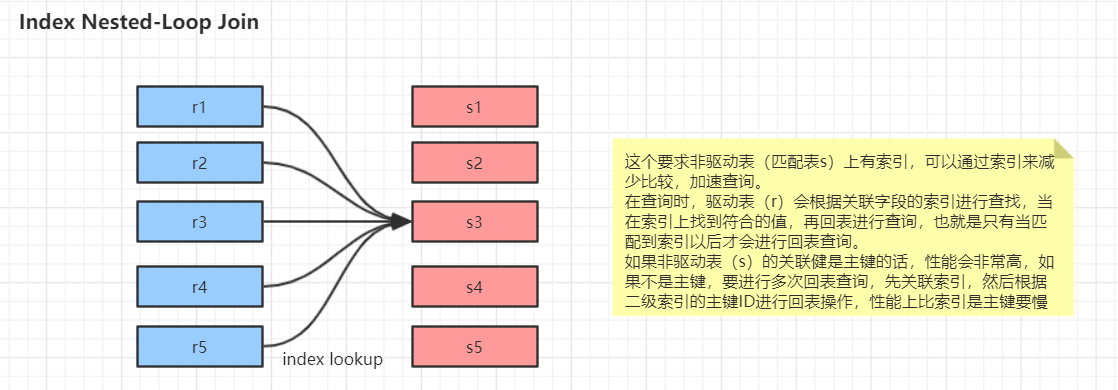

案例演示
查看不同的顺序执行方式对查询性能的影响:
explain select film.film_id,film.title,film.release_year,actor.actor_id,actor.first_name,actor.last_name from film inner join film_actor using(film_id) inner join actor using(actor_id);查看执行的成本:
show status like 'last_query_cost';按照自己预想的规定顺序执行:
explain select straight_join film.film_id,film.title,film.release_year,actor.actor_id,actor.first_name,actor.last_name from film inner join film_actor using(film_id) inner join actor using(actor_id);查看执行的成本:
show status like 'last_query_cost';(4)排序优化
无论如何排序都是一个成本很高的操作,所以从性能的角度出发,应该尽可能避免排序或者尽可能避免对大量数据进行排序。
推荐使用利用索引进行排序,但是当不能使用索引的时候,mysql就需要自己进行排序,如果数据量小则再内存中进行,如果数据量大就需要使用磁盘,mysql中称之为filesort。
如果需要排序的数据量小于排序缓冲区(show variables like ‘%sort_buffer_size%’😉,mysql使用内存进行快速排序操作,如果内存不够排序,那么mysql就会先将树分块,对每个独立的块使用快速排序进行排序,并将各个块的排序结果存放再磁盘上,然后将各个排好序的块进行合并,最后返回排序结果
两次传输排序
第一次数据读取是将需要排序的字段读取出来,然后进行排序,第二次是将排好序的结果按照需要去读取数据行。
这种方式效率比较低,原因是第二次读取数据的时候因为已经排好序,需要去读取所有记录而此时更多的是随机IO,读取数据成本会比较高
两次传输的优势,在排序的时候存储尽可能少的数据,让排序缓冲区可以尽可能多的容纳行数来进行排序操作
单次传输排序
先读取查询所需要的所有列,然后再根据给定列进行排序,最后直接返回排序结果,此方式只需要一次顺序IO读取所有的数据,而无须任何的随机IO,问题在于查询的列特别多的时候,会占用大量的存储空间,无法存储大量的数据
注意
当需要排序的列的总大小超过max_length_for_sort_data定义的字节,mysql会选择双次排序,反之使用单次排序,当然,用户可以设置此参数的值来选择排序的方式
四、优化特定类型的查询
1、优化count()查询
count()是特殊的函数,有两种不同的作用,一种是某个列值的数量,也可以统计行数
(1).使用近似值
在某些应用场景中,不需要完全精确的值,可以参考使用近似值来代替,比如可以使用explain来获取近似的值
其实在很多OLAP的应用中,需要计算某一个列值的基数,有一个计算近似值的算法叫hyperloglog。
(2).更复杂的优化
一般情况下,count()需要扫描大量的行才能获取精确的数据,其实很难优化,在实际操作的时候可以考虑使用索引覆盖扫描,或者增加汇总表,或者增加外部缓存系统。
注意:
总有人认为myisam的count函数比较快,这是有前提条件的,只有没有任何where条件的count(*)才是比较快的
2、优化关联查询
确保on或者using子句中的列上有索引,在创建索引的时候就要考虑到关联的顺序
当表A和表B使用列C关联的时候,如果优化器的关联顺序是B、A,那么就不需要再B表的对应列上建上索引,没有用到的索引只会带来额外的负担,一般情况下来说,只需要在关联顺序中的第二个表的相应列上创建索引
确保任何的groupby和order by中的表达式只涉及到一个表中的列,这样mysql才有可能使用索引来优化这个过程
3、优化子查询
子查询的优化最重要的优化建议是尽可能使用关联查询代替
4、优化limit分页
- 在很多应用场景中我们需要将数据进行分页,一般会使用limit加上偏移量的方法实现,同时加上合适的orderby 的子句,如果这种方式有索引的帮助,效率通常不错,否则的化需要进行大量的文件排序操作,还有一种情况,当偏移量非常大的时候,前面的大部分数据都会被抛弃,这样的代价太高。
- 要优化这种查询的话,要么是在页面中限制分页的数量,要么优化大偏移量的性能
- 优化此类查询的最简单的办法就是尽可能地使用覆盖索引,而不是查询所有的列(查看执行计划查看扫描的行数)
select film_id,description from film order by title limit 50,5 explain select film.film_id,film.description from film inner join (select film_id from film order by title limit 50,5) as lim using(film_id);
5、优化union查询
mysql总是通过创建并填充临时表的方式来执行union查询,因此很多优化策略在union查询中都没法很好的使用。经常需要手工的将where、limit、order by等子句下推到各个子查询中,以便优化器可以充分利用这些条件进行优化
除非确实需要服务器消除重复的行,否则一定要使用union all,因此没有all关键字,mysql会在查询的时候给临时表加上distinct的关键字,这个操作的代价很高
6、推荐使用用户自定义变量
用户自定义变量是一个容易被遗忘的mysql特性,但是如果能够用好,在某些场景下可以写出非常高效的查询语句,在查询中混合使用过程化和关系话逻辑的时候,自定义变量会非常有用。
用户自定义变量是一个用来存储内容的临时容器,在连接mysql的整个过程中都存在。
自定义变量的使用
set @one :=1
set @min_actor :=(select min(actor_id) from actor)
set @last_week :=current_date-interval 1 week;
自定义变量的限制
1、无法使用查询缓存
2、不能在使用常量或者标识符的地方使用自定义变量,例如表名、列名或者limit子句
3、用户自定义变量的生命周期是在一个连接中有效,所以不能用它们来做连接间的通信
4、不能显式地声明自定义变量地类型
5、mysql优化器在某些场景下可能会将这些变量优化掉,这可能导致代码不按预想地方式运行
6、赋值符号:=的优先级非常低,所以在使用赋值表达式的时候应该明确的使用括号
7、使用未定义变量不会产生任何语法错误
自定义变量的使用案例
优化排名语句
1、在给一个变量赋值的同时使用这个变量
2、查询获取演过最多电影的前10名演员,然后根据出演电影次数做一个排名
避免重新查询刚刚更新的数据
当需要高效的更新一条记录的时间戳,同时希望查询当前记录中存放的时间戳是什么
update t1 set lastUpdated=now() where id =1;
select lastUpdated from t1 where id =1;update t1 set lastupdated = now() where id = 1 and @now:=now();
select @now;确定取值的顺序
在赋值和读取变量的时候可能是在查询的不同阶段
set @rownum:=0;
select actor_id,@rownum:=@rownum+1 as cnt from actor where @rownum<=1;因为where和select在查询的不同阶段执行,所以看到查询到两条记录,这不符合预期
set @rownum:=0;
select actor_id,@rownum:=@rownum+1 as cnt from actor where @rownum<=1 order by first_name当引入了orde;r by之后,发现打印出了全部结果,这是因为order by引入了文件排序,而where条件是在文件排序操作之前取值的
解决这个问题的关键在于让变量的赋值和取值发生在执行查询的同一阶段:
set @rownum:=0;
select actor_id,@rownum as cnt from actor where (@rownum:=@rownum+1)<=1;来源:www.cnblogs.com/Courage129/p/14199...
本作品采用《CC 协议》,转载必须注明作者和本文链接










 关于 LearnKu
关于 LearnKu




推荐文章: