
MYSQL索引为什么这么快?了解索引的神奇之处
1 / 4 / 创建于 4年前
 CodeUndefined 的个人博客
CodeUndefined 的个人博客
前言
公司最近组织开展一系列的技术分享会,我借着这次机会把自己以前学的一些知识点重新归纳一下记录起来。首先是对自己技术的积累有好处,其次也是想让自己学习的知识能够更深入的理解,有不足或者错误的地方欢迎指出,共同进步。
探究一下MYSQL索引为什么这么快?索引究竟是什么?
1.什么是索引?
- MYSQL官方文档介绍索引是一种方便快速查询数据的数据结构。用我们生活中的例子来讲,索引就好比书的目录,如果没有目录,每次你想要查找某些内容,你必须从头开始查找,这样的效率极其低下。
- 索引一般比较大,所以大部分情况下索引是存在磁盘的索引文件上,也有可能是存在数据文件上。
- 索引的种类有很多:主键索引(这是最常见的一种索引,主键不能为空且必须唯一)、唯一索引(相对于主键索引,它的值可以为空)、全文索引(在char、varchar、text类型可以使用)、普通索引、前缀索引。按照列数来区分:单一索引、组合索引(多字段组成)
2.MYSQL索引的数据结构
在讲解MYSQL索引的数据结构之前,我们先看看了解一下其他的数据结构,看看他们的优缺点进行对比。
2.1 二叉树
二叉树简单来说就是左节点大于右节点,在理想的情况下,他的查找速度就接近与二分法的性能O(log2n)。因为在内存排序的时间是非常快的,可以忽略不计,所以总的消耗时间就取决于IO的操作次数。二叉树查找速度取决树高,每次查询接口都是一次IO操作,也是性能的瓶颈所在。
但是也会有这种一种情况,同样也是二叉树,但是他的树非常高,导致查询一次需要多次IO操作,效率及其低下
2.2 平衡二叉树
平衡二叉树可以解决二叉树不稳定导致查询效率低下的缺点。平衡二叉树的特点:树的左右节点层级最高相差一层。在插入或者删除的情况下,通过左旋转或右旋转使得整个二叉树平衡,不会出现层级相差很多的情况。平衡二叉树的性能接近二分法查找O(log2n)。
平衡二叉树查找id为8的记录,只需要IO操作2次即可。但是仔细想一下,如果数据量很多呢?假设数据表有100W的数据,根据O(log2n)计算,大约需要20次IO操作。磁盘寻道大概需要10ms,总的查询时间为20 * 10 = 0.2,效率也比较低下。
还有就是平衡二叉树不支持范围查询,范围查询每次都需要从根节点遍历,效率及其低下。
2.3 B-树(改造二叉树成多叉树)
之前的几种树形结构适合与小数据量的内存查找,也叫做内查找。在1970年,R.Bayer和E.Mccreight提出了一种适合于外查找的平衡多叉树B-树。MYSQL数据文件是存在磁盘的,每次都是按照一页大小(一般而16K)读取内存。像二叉树、平衡二叉树,每次读取节点都要进行一次IO操作,所以树越高IO操作次数越多。想要提高查询效率,首先要解决的就是降低树高的问题。
设想一下,每一次IO操作读取一个节点,读取16K大小的内存数据,但是每次节点的数据实际上远远小于16K。假设节点数据大小为16B,为了让一次IO操作能够读取更多节点,我们可以在每个节点尽可能地存储索引数据。我们在每个节点存储1000个索引数据(1000*16B = 16K),将二叉树改造成多叉树,从树高变成树“胖”,解决了树高的问题,从而降低IO操作次数,提高查询效率。
B-树的特点:1.每个节点存储多个元素 2.节点的元素包含键值以及数据 3.所有叶子节点存放同一层,具有相同深度,叶子节点之间没有指针连接。这种数据结构解决了树高IO次数多的问题,但是在每个节点存储数据,假设数据一旦很大,每个节点储存的索引数也随之减少,最后还是会导致树很高,查询效率低。其次,B-树不能范围查询。设想一下如果我们要查询15-25范围内的数据,查到15之后就又要重新回到根节点继续查找,这样循环遍历的效率有待提高。
2.4 B+树(改造B-树)
结合了B-树的缺点进行改造,就诞生了B+树。B+树跟B-树的差异并不是很大,判断的依据很简单:节点是否存放数据。B+树存放数据的节点只有叶子节点,而且叶子结点双向指针连接,形成了双向有序链表。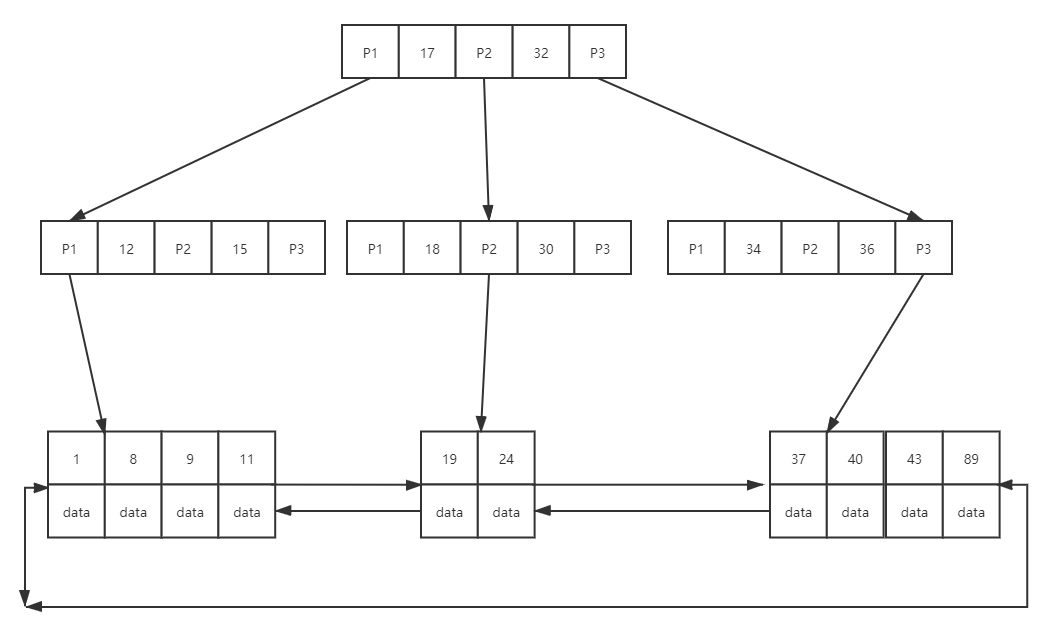
这样一来,除了叶子节点其他存放的都是索引键值,可以很大程度增加节点存放索引树,从理论上树是要比B-树“矮”的。同时B+树支持范围查询,因为底层叶子节点是双向有序链表,而且主键具有唯一性(对于辅助索引后面会讲到),假设范围为15到19,我们只需要查到15记录之后继续往后查询,直到大于19即可,无需从根节点再次遍历,效率较高。
3.MYSQL索引B+树实践
MYISAM引擎 (主键索引)
MYISAM引擎是非聚簇索引,也就是说B+树的叶子节点的键值存放索引列的值,数据存在数据在磁盘的地址。MYISAM的索引文件跟数据文件是分开存储的。CREATE TABLEstudent(idint(11) NOT NULL AUTO_INCREMENT,namevarchar(20) DEFAULT NULL,ageint(11) DEFAULT NULL, PRIMARY KEY (id) USING BTREE, KEYidx_age(age) USING BTREE ) ENGINE = MyISAM AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
创建了一个表student,id为主键索引,age为普通索引。假设表中有以下数据,现在执行以下语句SELECT * FROM stduent WHERE id = 16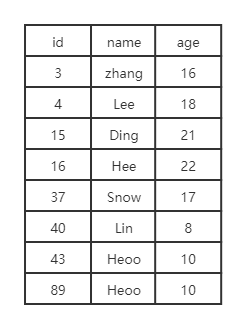
具体链路:(实际上逻辑上相邻实际磁盘并不一定相邻,这里只是方便展示)
(1)先从磁盘1加载数据到内存,因为18>16走左路(一次IO操作) (2)读取磁盘2加载数据到内存,又因为16>14向下继续读取(一次IO操作) (3)检索叶子节点,判断到等于16则停止(一次IO操作)
MYISAM引擎 (辅助索引)
在MYISAM引擎中,主键索引跟辅助索引的差别并不很大,叶子节点存放的都是磁盘地址,只是辅助索引并并不是唯一值,所以在等值查询检索叶子节点的时候,也要按照范围一样,进行检索数据。
Innodb引擎 (聚簇索引、主键索引)
Innodb引擎使用的是聚簇索引。每一个数据表都有一个聚簇索引,采用B+树的数据结构,叶子节点键值对应存放的是整行数据记录。在Innodb中,非聚簇索引就是辅助索引,叶子节点存储的数据是主键值。如果一个表没有主键,innodb引擎会自动构建一个隐藏的rowid在构成聚簇索引。依旧是按照我们刚刚讲解MYISAM引擎的数据表例子:SELECT * FROM stduent WHERE age = 37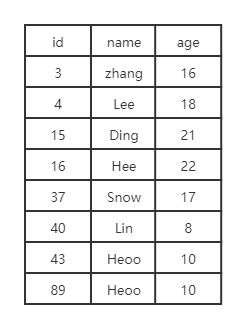
具体链路:(实际上逻辑上相邻实际磁盘并不一定相邻,这里只是方便展示)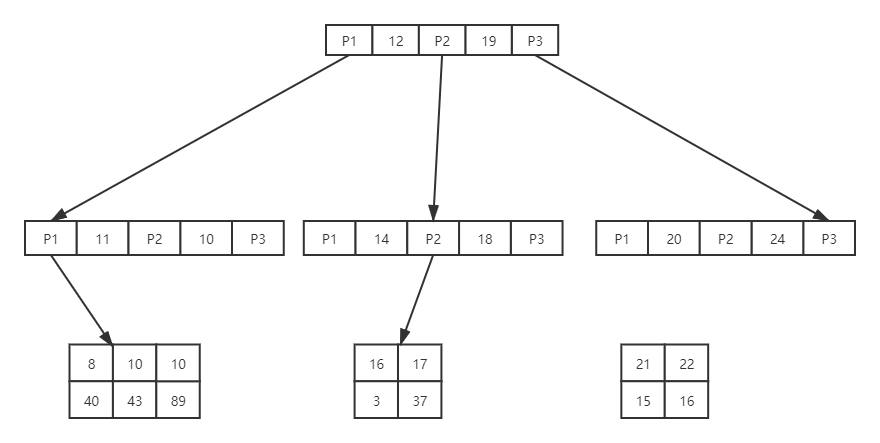
(1)先从磁盘1加载数据到内存,因为18<37走左路(一次IO操作) (2)读取磁盘2加载数据到内存,又因为37>24向下继续读取(一次IO操作) (3)检索叶子节点,判断到等于37则停止(一次IO操作) (4)这时候查到的数据就是age字段为37的记录主键值。按照聚簇索引的方式再查找数据就得到了数据结构集(这个过程叫做回表)相同索引字段情况下,按主键字段排序。因为要多加上三次回表操作,效率回相对低一点点。这里有个概念叫做覆盖索引,如果查询所需要的字段刚好就是索引字段就不需要回表查询,从而提高了查询效率。
总结
索引的原理远远不止于这么一点点,组合索引以及一些其他的原理我暂时理解还不是到位,等到后面学习更加理解之后再写一篇文章进行记录总结吧。“学而不思则惘,思而不学则殆”,以前没办法理解这句话的涵义,直到后来才知道总结、思考才是学习最有效率的方式。多总结、多思考,也是作为一名程序员进步的最快方式。
本作品采用《CC 协议》,转载必须注明作者和本文链接
















 关于 LearnKu
关于 LearnKu




推荐文章: