
用 docker 学习 redis 主从复制3 redis-sentinel「哨兵模式」
0 / 0 / 创建于 4年前 /
 php_yt 的个人博客
php_yt 的个人博客
为什么需要 redis-sentinel
redis 复制有一个问题,当主机(Master)宕机时,怎么办?
我们需要迅速的将某个从节点切换为主节点,然后把其他从节点复制该节点,最后通知客户端连接新的主节点。
如果这一切需要手动去做,那么主从复制并没有做到高可用。
如何解决呢?如果我们有一个监控程序能够监控各个机器的状态及时作出调整,将手动的操作变成自动的。
Sentinel 的出现就是为了解决这个问题。
Redis Sentinel ⌈翻译:哨兵⌉ 本身又是一个分布式架构,每个 Sentinel 节点不仅对 Redis 服务器进行监控,而且还监控其余的 Sentinel 节点,避免单节点故障。
redis-sentinel 不是三方软件,它也是 redis 的一部分。redis-server用于存储;redis-cli是客户端;redis-sentinel是用于监控。
故障转移的流程
主节点出现故障,此时两个从节点与主节点失去连接,主从复制失败。

每个 Sentinel 节点通过定期监控发现主节点出现了故障
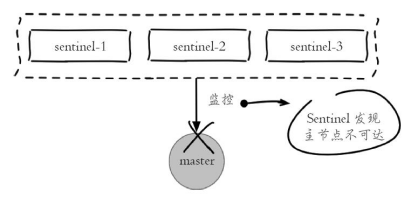
多个 Sentinel 节点对主节点的故障达成一致会选举出其中一个节点作为领导者负责故障转移。
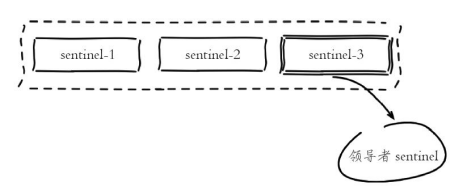
Sentinel 领导者节点执行了故障转移,整个过程基本是跟我们手动调整一致的,只不过是自动化完成的。
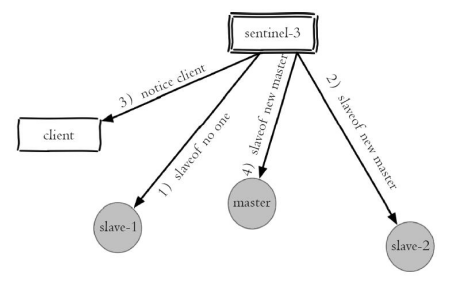
故障转移后整个 Redis Sentinel 的结构,重新选举了新的主节点。并且将故障转移的结果通知给应用方。
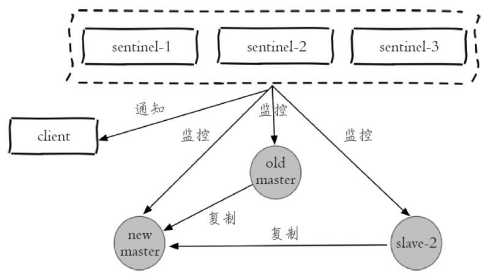
演示
这里准备一主二从 ⌈ip段 2 - 5,将配置 5 为主节点⌉
docker run -itd --name master --net mynetwork --ip 172.10.0.5 -p 6385:6379 redis:n1
docker run -itd --name slave0 --net mynetwork --ip 172.10.0.2 -p 6382:6379 redis:n1
docker run -itd --name slave1 --net mynetwork --ip 172.10.0.4 -p 6384:6379 redis:n1以及三台redis-sentinel ⌈ip段 11-13⌉
docker run -itd --name sentinel1 --net mynetwork --ip 172.10.0.11 -p 22531:26379 redis:n1
docker run -itd --name sentinel2 --net mynetwork --ip 172.10.0.12 -p 22532:26379 redis:n1
docker run -itd --name sentinel3 --net mynetwork --ip 172.10.0.13 -p 22533:26379 redis:n1
1、配置主从复制 master slave0 slave1
docker exec -it master bash
docker exec -it slave0 bash
docker exec -it slave1 bash
vi /etc/redis.conf
#
bind 0.0.0.0
# 不设置密码,把保护模式关闭
protected-mode no
三个容器启动
[root@794f7a0dfc70 /]# redis-server /etc/redis.conf &
然后在slave0 slave1 中执行
[root@794f7a0dfc70 /]# redis-cli
127.0.0.1:6379> slaveof 172.10.0.5 6379
OK Already connected to specified master主节点检查
[root@4f1cb20cc2b3 /]# redis-cli
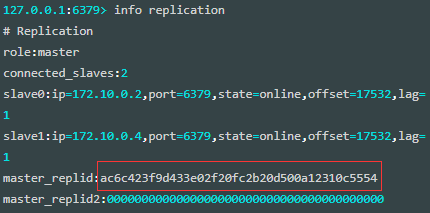
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.10.0.2,port=6379,state=online,offset=17532,lag=1
slave1:ip=172.10.0.4,port=6379,state=online,offset=17532,lag=1
master_replid:ac6c423f9d433e02f20fc2b20d500a12310c5554
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:17532
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:175322、配置 sentinel
docker exec -it sentinel2 bash
vi /etc/redis-sentinel.conf# bind 127.0.0.1 192.168.1.1
bind 0.0.0.0
# 这里不设置密码,所以把保护模式关闭
# protected-mode no
protected-mode no
#监控主节点 主节点名称 ip port
#最后一个2的意思是有几台sentinel节点发现有问题,就会发生故障转移。
#例如配置为2,代表至少2个sentinel节点认为主节点不可达,那么这个不可达的判定才是客观的。
#值越小,对于下线的条件越宽松,反之越严格。一般设置为sentinel节点总数的一半+1
#172.10.0.5是主节点,mymaster是随便起的名称,因哨兵可监视多个master,为了区分
sentinel monitor mymaster 172.10.0.5 6379 2
#主节点的密码,没有设置不用更改
# sentinel auth-pass <master-name> <password>三个 sentinel 容器全部如上配置,然后启动
redis-sentinel /etc/redis-sentinel.conf &查看 sentinel 的日志
[root@c562749c1042 redis]# cat /var/log/redis/sentinel.log
# oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
# Redis version=5.0.3, bits=64, commit=00000000, modified=0, pid=83, just started
# Configuration loaded
* Running mode=sentinel, port=26379.
# WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
# Sentinel ID is 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad
# +monitor master mymaster 172.10.0.5 6379 quorum 2
* +slave slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379
* +slave slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379
* +sentinel sentinel 0a794e05a58aa0b90a7badd3a79acbc17f878c02 172.10.0.12 26379 @ mymaster 172.10.0.5 6379
* +sentinel sentinel f88c2429ad02985495c4c7fd5929275e96e07b61 172.10.0.11 26379 @ mymaster 172.10.0.5 6379重点是下面几行,因为三个 sentinel 节点都监控 master 节点,所以 slave 从节点信息、以及其他 sentinel 节点信息可以通过 master 节点信息共享。
测试
我们将 master 挂掉模拟主节点宕机,看看哨兵是如何运作的
[root@4f1cb20cc2b3 /]# ps -ef | grep redis
root 105 78 0 14:25 pts/2 00:00:01 redis-server 0.0.0.0:6379
root 115 78 0 14:41 pts/2 00:00:00 grep --color=auto redis
[root@4f1cb20cc2b3 /]# kill 105分别看各个 sentinel 的日志
sentinel1 节点
# +sdown master mymaster 172.10.0.5 6379
主观下线
# +new-epoch 1
# +vote-for-leader 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad 1
投票给sentiel3做为领导者
# +config-update-from sentinel 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad 172.10.0.13 26379 @ mymaster 172.10.0.5 6379
从领导者sentiel3那里配置更新
# +switch-master mymaster 172.10.0.5 6379 172.10.0.4 6379
切换主节点信息到slave1
* +slave slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.4 6379
其他从节点信息
* +slave slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.4 6379
# +sdown slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.4 6379发现主节点不可达,进行主观下线(sdown subjective主观的);投票给 sentinel3 节点(172.10.0.13)作为领导者;剩下的是故障转移后从领导者那里接收的信息,其实从这里也可以看出,master 节点进行了切换 172.0.0.5(原master) -> 172.0.0.4 (原slave1节点)
sentinel2 节点
//当前哨兵认为master已经主观宕机,也就是sdown
# +sdown master mymaster 172.10.0.5 6379
//由于哨兵集群内有超过两个哨兵都认为master宕机了,因此转化成客观宕机,也就是odown
# +odown m#quorum 2/2
、、递增集群状态版本号,这个版本号将被接下来选举出的新的master采用。
# +new-epoch 1
//开始对名为"mymaster"的Redis集群进行故障转移。
# +try-failover master mymaster 172.10.0.5 6379
//当前哨兵投票给自己为领导者
# +vote-for-leader 0a794e05a58aa0b90a7badd3a79acbc17f878c02 1
//sentinel3节点选举了sentinel3
# 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad voted for 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad 1
//sentinel1选举了sentinel3(因此sentinel3获得了两票,成为了领导者)
# f88c2429ad02985495c4c7fd5929275e96e07b61 voted for 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad 1
//从sentinel3领导者得到更新配置
# +config-update-from sentinel 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad 172.10.0.13 26379 @ mymaster 172.10.0.5 6379
//开始监控新的master
# +switch-master mymaster 172.10.0.5 6379 172.10.0.4 6379
+slave slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.4 6379
同步其他从节点信息
* +slave slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.4 6379
# +sdown slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.4 6379和 sentinel1 节点的日志差不都,先是主观下线,就是我认为它下线了,发现还有其他节点也认为它下线了,于是客观上认为它下线了。
sentinel3 节点 ⌈选举为领导者⌉
//开始对名为"mymaster"的Redis集群进行故障转移。
# +try-failover master mymaster 172.10.0.5 6379
//自己投票给了自己
# +vote-for-leader 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad 1
//sentinel2节点投票给了sentinel2
# 0a794e05a58aa0b90a7badd3a79acbc17f878c02 voted for 0a794e05a58aa0b90a7badd3a79acbc17f878c02 1
//sentinel1投票给了自己
# f88c2429ad02985495c4c7fd5929275e96e07b61 voted for 4c7ec628d2a2e1778dab9ba36d7e5109dd2601ad 1
//自己当选为领导人,负责故障转移的工作
# +elected-leader master mymaster 172.10.0.5 6379
//开始在集群中寻找合适的slave
# +failover-state-select-slave master mymaster 172.10.0.5 6379
//选择了172.10.0.4作为主节点
# +selected-slave slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379
////向172.10.0.4发送 slaveof no one 命令成为主节点
* +failover-state-send-slaveof-noone slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379
//等待晋升为主节点(等待其它的sentinel确认slave)
* +failover-state-wait-promotion slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379
//晋升成功(意味着其它的sentinel全部确认成功)
# +promoted-slave slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379
//更新主节点的所有slaves的配置信息
# +failover-state-reconf-slaves master mymaster 172.10.0.5 6379
//向指定的slave 172.10.0.2发送"slaveof"指令,令其跟随新的master
* +slave-reconf-sent slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379
# -odown master mymaster 172.10.0.5 6379
//目标slave正在执行slaveof操作
* +slave-reconf-inprog slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379
//目标slave配置信息更新完毕
* +slave-reconf-done slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379
//本次故障转移完毕。
# +failover-end master mymaster 172.10.0.5 6379
//各个sentinel开始监控新的master
# +switch-master mymaster 172.10.0.5 6379 172.10.0.4 6379
切换主节点172.10.0.5->172.10.0.4
* +slave slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.4 6379
将slave0作为主节点的从节点
* +slave slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.4 6379
将原master作为主节点的从节点
# +sdown slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.4 6379
原master节点不可达sentinel3 节点被选举为领导者,完成故障转移的工作,将172.10.0.4 (slave1)切换为主节点。
新的主节点 slave1
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=172.10.0.2,port=6379,state=online,offset=758977,lag=0
master_replid:ed72006b113f2ffe639f6e5f807acea6af3e15cc
master_replid2:ac6c423f9d433e02f20fc2b20d500a12310c5554
master_repl_offset:759113
second_repl_offset:115575
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:296
repl_backlog_histlen:758818上方只有一个从节点 slave0 是因为刚刚我们把原主节点下线了
可以看到它的日志
* MASTER <-> REPLICA sync started
# Error condition on socket for SYNC: Connection refused
* Connecting to MASTER 172.10.0.5:6379
* MASTER <-> REPLICA sync started
# Error condition on socket for SYNC: Connection refused
主节点已经宕机,复制中断
# Setting secondary replication ID to ac6c423f9d433e02f20fc2b20d500a12310c5554, valid up to offset: 115575. New replication ID is ed72006b113f2ffe639f6e5f807acea6af3e15cc
将辅助复制ID设置为xx,有效数据至偏移量:115575。新的复制ID是xx. 你可以对照下文章前面的故障转移之前的replication ID
* Discarding previously cached master state.
丢弃以前缓存的主节点状态
* MASTER MODE enabled (user request from 'id=10 addr=172.10.0.13:37944 fd=13 name=sentinel-4c7ec628-cmd age=353 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=154 qbuf-free=32614 obl=36 oll=0 omem=0 events=r cmd=exec')
主模式已启用(来自sentinel3哨兵的请求)
# CONFIG REWRITE executed with success.
成功地执行了配置重写
* Replica 172.10.0.2:6379 asks for synchronization
slave0节点请求复制
* Partial resynchronization request from 172.10.0.2:6379 accepted. Sending 159 bytes of backlog starting from offset 115575
172.10.0.2:6379的部分重新同步请求已接受。从偏移量115575开始发送159字节的积压工作日志中的第二句,将辅助复制ID设置为ac6c423f9d433e02f20fc2b20d500a12310c5554,有效数据至偏移量:115575。New replication ID is ..
、将原master节点的 master_replid 作为了自己的 master_replid2 (辅助复制ID),也就是故障转移的过程,保留了原 master 的一些原始信息。
原 master 节点的信息
一个很重要的原因,就是避免切换主节点后发生全量复制,上方日志中最后一行: 172.10.0.2:6379的部分重新同步请求已接受。从偏移量115575开始发送159字节的积压工作 证明是部分复制。另外可以从另一个从节点(slave0)的日志来看:
* Connecting to MASTER 172.10.0.5:6379
* MASTER <-> REPLICA sync started
# Error condition on socket for SYNC: Connection refused
主节点断开复制
* REPLICAOF 172.10.0.4:6379 enabled (user request from 'id=10 addr=172.10.0.13:48156 fd=13 name=sentinel-4c7ec628-cmd age=353 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=286 qbuf-free=32482 obl=36 oll=0 omem=0 events=r cmd=exec')
执行了 replicaof 172.10.0.4 6379 (来自sentinel3的请求)
# CONFIG REWRITE executed with success.
配置更新成功
* Connecting to MASTER 172.10.0.4:6379
连接新的主节点
* MASTER <-> REPLICA sync started
开始复制
* Non blocking connect for SYNC fired the event.
* Master replied to PING, replication can continue...
* Trying a partial resynchronization (request ac6c423f9d433e02f20fc2b20d500a12310c5554:115575).
* Successful partial resynchronization with master.
请求与主节点部分复制。注意:切换主节点后并不是全量复制,而是部分复制
# Master replication ID changed to ed72006b113f2ffe639f6e5f807acea6af3e15cc
主节点的 replication ID更换
* MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization
主节点接收部分复制请求slave0 从 slave1(现在是新的主节点)进行部分复制(Partial Resynchronization),而不是全量复制。
重新启动原 master 节点
之前将原 master 节点 172.10.0.5 主动挂掉,之后 sentinel 进行了故障转移,将 172.10.0.4 即 slave1 作为主节点,现在将原 master 节点重新启动,会发生什么呢?
通过在目前主节点 slave1 上查看
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.10.0.2,port=6379,state=online,offset=1229694,lag=0
slave1:ip=172.10.0.5,port=6379,state=online,offset=1229694,lag=1
...可以发现原来的主节点重新启动后,自动变成了从节点。这个过程是怎样的呢?
其中一个哨兵发现原主节点上线后,于是向它发送了转换为从节点的命令
+convert-to-slave slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.4 6379 而原主节点收到后
REPLICAOF 172.10.0.4:6379 enabled (user request from 'id=3 addr=172.10.0.12:47798 fd=7 name=sentinel-0a794e05-cmd age=10 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=150 qbuf-free=32618 obl=36 oll=0 omem=0 events=r cmd=exec')
这是sentinel2节点发来的请求,执行了 REPLICAOF 172.10.0.4 6379 命令 变成从节点
117:S 06 Jan 2022 16:10:20.154 # CONFIG REWRITE executed with success.
更新配置
117:S 06 Jan 2022 16:10:21.007 * Connecting to MASTER 172.10.0.4:6379
开始发起复制
117:S 06 Jan 2022 16:10:21.007 * MASTER <-> REPLICA sync started
...故障转移后应用方的连接
sentinel 提供了一些命令提供给应用方查询主节点及从节点的信息,应用方可随机连接任何一台 sentinel 节点,然后通过命令查询。
查询 mymaster 的主节点
[root@VM-0-8-centos ~]# redis-cli -p 22531
127.0.0.1:22531> sentinel get-master-addr-by-name mymaster
1) "172.10.0.4"
2) "6379"查询 mymaster 的所有从节点
127.0.0.1:22531> SENTINEL slaves mymaster
1) 1) "name"
2) "172.10.0.2:6379"
3) "ip"
4) "172.10.0.2"
5) "port"
6) "6379"
...
2) 1) "name"
2) "172.10.0.5:6379"
...应用方可以定时更新最新的信息,保存在自身的内存或磁盘中。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: