
用 docker 学习 redis 主从复制3.3 redis-sentinel「哨兵模式」 数据丢失的情况
0 / 0 / 创建于 4年前 /
 php_yt 的个人博客
php_yt 的个人博客
哨兵模式虽然能够在 master 下线时自动故障转移,但还是不能保证数据百分百不丢失,本篇介绍下什么情况下会发生。
1、异步复制导致数据丢失
由于 master-->slave 的复制是异步,所以可能有部分数据还没来得及复制到 slave 就宕机了,这部分数据就丢失了。
2、集群脑裂导致数据丢失
如果 master 因为网络原因导致哨兵 ping 超时,因而判断为客观下线,但其实master 并没有真实下线。哨兵开始故障转移,而在此过程中,客户端在向 master 写入数据。
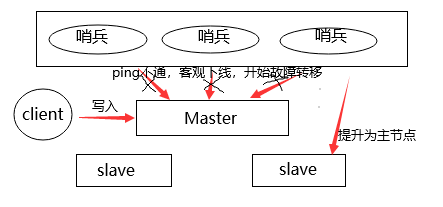
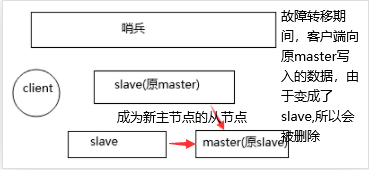
在选举过程中,新的 master 已经产生,哨兵也开始向其他 redis机器 发送命令让它们成为新 master 的从节点。而原 master 在没有成为新 master 的从节点之前,实际上同时有两个 master,称之为「集群脑裂」。
因为原 master 最终会成为新 master 的从节点,因此客户端写入的数据会在主从同步完成后删掉,造成故障转移期间写入的数据丢失。
主节点的两个配置选项可以减少上述情况的数据丢失
发生以下两种情况,主节点拒绝执行写命令。
#从节点的数量少于1个
min-slaves-to-write 2
#或者有2个从节点的延迟(lag)值都大于或等于10秒时
min-slaves-max-lag 10异步复制导致的数据丢失
min-slaves-max-lag 10
主从服务器可以通过发送和接收REPLCONF ACK命令来检查两者之间的网络连接是否正常,如果主服务器超过一秒钟没有收到从服务器发来的REPLCONF ACK命令,那么主服务器就知道主从服务器之间的连接出现问题了,在一般情况下,lag 的值应该在 0 秒或者 1 秒之间跳动。
如果min-slaves-to-write个从节点的 lag 值都大于 10 秒,则拒绝新的写入。也就是说,客户端能正常连接进行写入,但是和从节点的连接出问题了,起不到主备的作用了,那就不要再新写入数据了。脑裂导致的数据丢失
min-slaves-to-write 2
在故障转移过程中,晋升一个节点为主节点后,其他机器会陆续变为新主节点的从节点。这意味着,原主节点的从节点在减少,直到自己也变成从节点。
如果主节点的从节点少于了 2 台甚至都没有从节点了,那么就拒绝写入命令。拒绝写入后的客户端连接问题
如果主节点连接失败或者拒绝写入,就需要发起重试,请求哨兵拿到新的主节点信息。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: