
php 面试题-精简版-适用于1年以上经验
0 / 0 / 创建于 3年前 /
 wangchunbo 的个人博客
wangchunbo 的个人博客
php 面试题 - 精简版#
以前的面试题太多了。几百道。现在整理几个精华吧。
laravel 不在这里哦。
资料均来源于互联网。
表单提交中的 Get 和 Post 的异同点#
get 请求一般用于向服务端获取数据,post 一般向服务端提交数据
get 传输的参数在 url 中,传递参数大小有限制,post 没有大小限制,
get 不安全,post 安全性比 get 高
get 请求在服务端用 Request.queryString 接受,post 请求在服务端用 Requset.form 接受
浅谈 HTTP 中 Get、Post、Put 与 Delete 的区别#
1、GET 请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的 select 操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
2、与 GET 不同的是,PUT 请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的 update 操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次 PUT 操作,其结果并没有不同。
3、POST 请求同 PUT 请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的 insert 操作一样,会创建新的内容。几乎目前所有的提交操作都是用 POST 请求的。
4、DELETE 请求顾名思义,就是用来删除某一个资源的,该请求就像数据库的 delete 操作。
就像前面所讲的一样,既然 PUT 和 POST 操作都是向服务器端发送数据的,那么两者有什么区别呢。。。POST 主要作用在一个集合资源之上的(url),而 PUT 主要作用在一个具体资源之上的(url/xxx),通俗一下讲就是,如 URL 可以在客户端确定,那么可使用 PUT,否则用 POST。
综上所述,我们可理解为以下:
1、POST /url 创建
2、DELETE /url/xxx 删除
3、PUT /url/xxx 更新
4、GET /url/xxx 查看
echo print () print_r () var_dump () 的区别#
常见的输出语句
echo()
可以一次输出多个值,多个值之间用逗号分隔。echo 是语言结构 (language construct),而并不是真正的函数,因此不能作为表达式的一部分使用。
print()
函数 print () 打印一个值(它的参数),如果字符串成功显示则返回 true,否则返回 false。
print_r()
可以把字符串和数字简单地打印出来,而数组则以括起来的键和值得列表形式显示,并以 Array 开头。但 print_r () 输出布尔值和 NULL 的结果没有意义,因为都是打印”\n”。因此用 var_dump () 函数更适合调试。
var_dump()
判断一个变量的类型与长度,并输出变量的数值,如果变量有值输的是变量的值并回返数据类型。此函数显示关于一个或多个表达式的结构信息,包括表达式的类型与值。数组将递归展开值,通过缩进显示其结构。
编写一段用最小代价实现将字符串完全反序。将 “1234567890” 转换成 “0987654321”. (用前述你最熟悉的语言编写并标注简单注释,不要使用函数)#
public function ceshi(){
$a = '1234567890';
$i = 0;
$b = '';
while (isset($a[$i]) && $a[$i] != null){
$b = $a[$i++].$b;
}
echo $b;
}补充,函数: PHP strrev () 函数
请用递归实现一个阶乘求值算法 F (n): n=5;F (n)=5!=54321=120#
function F($n) {
if($n==0) {
return 1;
}else{
return $n* F($n-1);
}
}
var_dump(F(5));
将字符长 pai-huang-pian 转化为驼峰法的形式:PaiHuangPian#
方法一
function Fun($str){
if(isset($str) && !empty($str)){
$newStr='';
if(strpos($str,'-')>0){
$strArray=explode('-',$str);
$len=count($strArray);
for ($i=0;$i<$len;$i++){
$newStr.=ucfirst($strArray[$i]);
}
}
return $newStr;
}
}
方法二
function Fun($str){
$arr1=explode('_',$str);
$str = implode(' ',$arr1);
return ucwords($str);
}
var_dump(Fun("fang-zhi-gang")); //FangZhiGang
数组内置的排序方法有哪些?#
sort($array); //数组升序排序
rsort($array); //数组降序排序
asort($array); //根据值,以升序对关联数组进行排序
ksort($array); //根据建,以升序对关联数组进行排序
arsort($array); //根据值,以降序对关联数组进行排序
krsort($array); // 根据键,以降序对关联数组进行排序
可参考:www.runoob.com/php/php-arrays-sort...
语句 include 和 require 的区别是什么?为避免多次包含同一文件,可用什么语句代替它们?#
【这题,老兄弟连人都知道哈哈哈】
答 1:
1、加载失败的处理方式不同
include 在引入不存在的文件时,产生一个警告且脚本还会继续执行,
require 则会导致一个致命性错误且脚本停止执行。
2、include () 是有条件包含函数,而 require () 则是无条件包含函数。
if(FALSE){
include 'file.php'; //file.php不会被引入
}
if(FALSE){
require 'file.php'; //file.php将会被引入
}3、文件引用方式
include 有返回值,而 require 没有
$retVal = include(’somefile.php’);
if(!empty($retVal)){
echo "文件包含成功";
}else{
echo "文件包含失败";
}答 2: 可以用 include_once,require_once 代替,表示文件只引入一次,引入之后则不在引入,作为优化点
PHP 不使用第三个变量实现交换两个变量的值 ***#
这题,我经常遇到,也不知道为啥。标记一下,三个星号
方法一 str_replace
<?php
/**
* 双方变量为字符串时,可用交换方法二
* 使用str_replace()方法达到交换变量值得目的
* 此方法较第一种,逻辑上稍微简单点
*/
$a = "This is A"; // a变量原始值
$b = "This is B"; // b变量原始值
echo '交换之前 $a 的值:'.$a.', $b 的值:'.$b,'<br>'; // 输出原始值
$a .= $b; // 将$b的值追加到$a中
$b = str_replace($b, "", $a); // 在$a(原始$a+$b)中,将$b替换为空,则余下的返回值为$a
$a = str_replace($b, "", $a); // 此时,$b为原始$a值,则在$a(原始$a+$b)中将$b(原始$a)替换为空,则余下的返回值则为原始$b,交换成功
echo '交换之后 $a 的值:'.$a.', $b 的值:'.$b,'<br>'; // 输出结果值方法二 list 函数
list($b,$a)=array($a,$b);
var_dump($a,$b);一个文件的路径为 /wwwroot/include/page.class.php,写出获得该文件扩展名的方法#
$arr = pathinfo(“/wwwroot/include/page.class.php”);
$str = substr($arr[‘basename’],strrpos($arr[‘basename’],’.’));
简述 php 的垃圾收集机制。#
php 中的变量存储在变量容器 zval 中,zval 中除了存储变量类型和值外,还有 is_ref 和 refcount 字段。refcount 表示指向变量的元素个数,is_ref 表示变量是否有别名。如果 refcount 为 0 时,就回收该变量容器。如果一个 zval 的 refcount 减 1 之后大于 0,它就会进入垃圾缓冲区。当缓冲区达到最大值后,回收算法会循环遍历 zval,判断其是否为垃圾,并进行释放处理。
PHP 如何接口调用?#
使用 curl 调用 http 接口:
get
<?php
//初始化
$curl = curl_init ( ) ;
//设置抓取的url
curl_setopt ( $curl , CURLOPT_URL , 'http://www.baidu.com' ) ;
//设置头文件的信息作为数据流输出
curl_setopt ( $curl , CURLOPT_HEADER , 1 ) ;
//设置获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt ( $curl , CURLOPT_RETURNTRANSFER , 1 ) ;
//执行命令
$data = curl_exec ( $curl ) ;
//关闭URL请求
curl_close ( $curl ) ;
//显示获得的数据
print_r ( $data ) ;
?>
post
<?php
//初始化
$curl = curl_init ( ) ;
//设置抓取的url
curl_setopt ( $curl , CURLOPT_URL , 'http://www.baidu.com' ) ;
//设置头文件的信息作为数据流输出
curl_setopt ( $curl , CURLOPT_HEADER , 1 ) ;
//设置获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt ( $curl , CURLOPT_RETURNTRANSFER , 1 ) ;
//设置post方式提交
curl_setopt ( $curl , CURLOPT_POST , 1 ) ;
//设置post数据
$post_data = array (
"username" => "coder" ,
"password" => "12345"
) ;
curl_setopt ( $curl , CURLOPT_POSTFIELDS , $post_data ) ;
//执行命令
$data = curl_exec ( $curl ) ;
//关闭URL请求
curl_close ( $curl ) ;
//显示获得的数据
print_r ( $data ) ;
?>php 命名空间是如何定义的?##
命名空间通过关键字namespace 来声明。如果一个文件中包含命名空间,它必须在其它所有代码之前声明命名空间,除了一个以外:declare关键字。
命名空间一个最明确的目的就是解决重名问题,PHP中不允许两个函数或者类出现相同的名字,否则会产生一个致命的错误。这种情况下只要避免命名重复就可以解决,最常见的一种做法是约定一个前缀。
基础
命名空间将代码划分出不同的空间(区域),每个空间的常量、函数、类(为了偷懒,我下边都将它们称为元素)的名字互不影响, 这个有点类似我们常常提到的‘封装'的概念
php 接口是如何实现的?#
如果一个抽象类里面的所有方法都是抽象方法,且没有声明变量,而且接口里面所有的成员都是 public 权限的,那么这种特殊的抽象类就叫接口
接口是什么?
使用接口(interface),可以指定某个类必须实现哪些方法,但不需要定义这些方法的具体内容。
接口是通过 interface 关键字来定义的,就像定义一个标准的类一样,但其中定义所有的方法都是空的。
接口中定义的所有方法都必须是公有,这是接口的特性。
接口使用规范
接口不能实例化
接口的属性必须是常量
接口的方法必须是 public【默认 public】,且不能有函数体
类必须实现接口的所有方法
一个类可以同时实现多个接口,用逗号隔开
接口可以继承接口【用的少】
什么是 Composer, 工作原理是什么?#
Composer 是 PHP 的一个依赖管理工具。工作原理就是将已开发好的扩展包从 packagist.org composer 仓库下载到我们的应用程序中,并声明依赖关系和版本控制。
composer 团队协作怎么保证版本统一?#
安装组件使用 composer install 而不是 composer update,
.lock 文件加入版本控制当中。
OOP 思想,特征和其意义#
抽象、封装、继承和多态是面向对象的基础。
抽象:提取现实世界中某事物的关键特性,为该事物构建模型的过程。对同一事物在不同的需求下,需要提取的特性可能不一样。得到的抽象模型中一般包含:属性(数据)和操作(行为)。这个抽象模型我们称之为类。对类进行实例化得到对象。
封装:封装可以使类具有独立性和隔离性;保证类的高内聚。只暴露给类外部或者子类必须的属性和操作。类封装的实现依赖类的修饰符(public、protected 和 private 等)
继承:对现有类的一种复用机制。一个类如果继承现有的类,则这个类将拥有被继承类的所有非私有特性(属性和操作)。这里指的继承包含:类的继承和接口的实现。
多态:多态是在继承的基础上实现的。多态的三个要素:继承、重写和父类引用指向子类对象。父类引用指向不同的子类对象时,调用相同的方法,呈现出不同的行为;就是类多态特性。多态可以分成编译时多态和运行时多态。
帮助理解: www.cnblogs.com/waj6511988/p/69742...
设计模式之 SOLID 原则#
php 设计模式不多说了,但是记住,要能讲出来.
SRP 单一责任原则
OCP 开放封闭原则
LSP 里氏替换原则
ISP 接口隔离原则
DIP 依赖倒置原则
- 开闭原则:对扩展开放,对修改关闭
- 里氏替换原则:继承 必须保证 父类中的性质在子类中仍然成立
- 依赖倒置原则:面向接口编程,而不面向实现类
- 单一职责原则:控制 类的 粒度的大小 ,增强内聚性,减少耦合
- 接口隔离原则:要为各个类提供所需的专用接口
- 迪米特法则:迪米特法则(Law of Demeter)又叫作最少知识原则(The Least Knowledge Principle),一个类对于其他类知道的越少越好,就是说一个对象应当对其他对象有尽可能少的了解,只和朋友通信,不和陌生人说话。英文简写为: LOD。
- 合成复用原则:尽可能使用组合或者聚合等关系来关联类,其次才考虑使用继承。
mvc 框架的生命周期说一下#
model:存放向数据库请求来的数据
view:存放组件、图片、页面模板 html 文件
controller:获取或改变 model 里的数据返回给页面渲染数据
用户请求进来,先加载配置文件,框架初始化,然后匹配路由地址,寻找到对应的 controller 的文件地址,引入加载文件,实例化 controller,根据路由匹配得到的方法和参数,调用并传参到方法,此处可能需要读取 db,model 层则负责数据库存取,提供封装好的方法给到 controller 层调用,controller 层得到数据后,通过引入 view 层文件,传递数据到 view 层,渲染 html 模板后输出。
可以参考:www.jb51.net/article/49498.htm
session 与 cookie 的区别是什么?#
1、保持状态:
cookie 和 session 都是用来跟踪浏览器用户身份的会话方式。
2、使用方式:
(1)cookie 机制:如果不在浏览器中设置过期时间,cookie 被保存在内存中,生命周期随浏览器的关闭而结束,这种 cookie 简称会话 cookie。如果在浏览器中设置了 cookie 的过期时间,cookie 被保存在硬盘中,关闭浏览器后,cookie 数据仍然存在,直到过期时间结束才消失。
Cookie 是服务器发给客户端的特殊信息,cookie 是以文本的方式保存在客户端,每次请求时都带上它
(2)session 机制:当服务器收到请求需要创建 session 对象时,首先会检查客户端请求中是否包含 sessionid。如果有 sessionid,服务器将根据该 id 返回对应 session 对象。如果客户端请求中没有 sessionid,服务器会创建新的 session 对象,并把 sessionid 在本次响应中返回给客户端。通常使用 cookie 方式存储 sessionid 到客户端,在交互中浏览器按照规则将 sessionid 发送给服务器。如果用户禁用 cookie,则要使用 URL 重写,可以通过 response.encodeURL (url) 进行实现;API 对 encodeURL 的结束为,当浏览器支持 Cookie 时,url 不做任何处理;当浏览器不支持 Cookie 的时候,将会重写 URL 将 SessionID 拼接到访问地址后。
3、存储内容:
cookie 只能保存字符串类型,以文本的方式;session 通过类似与 Hashtable 的数据结构来保存,能支持任何类型的对象 (session 中可含有多个对象)
4、存储的大小:
cookie:单个 cookie 保存的数据不能超过 4kb;
session 大小没有限制。
5、安全性:
cookie:针对 cookie 所存在的攻击:Cookie 欺骗,Cookie 截获;
session 的安全性大于 cookie。
为什么 session 的安全性大于 cookie?#
sessionID 存储在 cookie 中,若要攻破 session 首先要攻破 cookie;
sessionID 是要有人登录,或者启动 session_start 才会有,所以攻破 cookie 也不一定能得到 sessionID;
第二次启动 session_start 后,前一次的 sessionID 就是失效了,session 过期后,sessionID 也随之失效。
sessionID 是加密的
综上所述,攻击者必须在短时间内攻破加密的 sessionID,这很难。
session 与 cookie 的应用场景有哪些?#
cookie:
(1)判断用户是否登陆过网站,以便下次登录时能够实现自动登录(或者记住密码)。如果我们删除 cookie,则每次登录必须从新填写登录的相关信息。
(2)保存上次登录的时间等信息。
(3)保存上次查看的页面。
(4)浏览计数。
session:
Session 用于保存每个用户的专用信息,变量的值保存在服务器端,通过 SessionID 来区分不同的客户。
(1)网上商城中的购物车。
(2)保存用户登录信息。
(3)将某些数据放入 session 中,供同一用户的不同页面使用。
(4)防止用户非法登录。
存放 session 的三种方法#
1、如果你能修改到服务器配置文件,那就打开打开 php.ini
修改下面两项:
session.save_handler = memcache
session.save_path = "tcp://127.0.0.1:11211"2、修改网站根目录下的.htaccess 文件
php_value session.save_handler "memcache"
php_value session.save_path "tcp://127.0.0.1:11211"3、在程序代码中修改
ini_set("session.save_handler", "memcache");
ini_set("session.save_path", "tcp://127.0.0.1:11211");IoC 容器是什么?#
IoC(Inversion of Control)译为 「控制反转」,也被叫做「依赖注入」(DI)。什么是「控制反转」?对象 A 功能依赖于对象 B,但是控制权由对象 A 来控制,控制权被颠倒,所以叫做「控制反转」,而「依赖注入」是实现 IoC 的方法,就是由 IoC 容器在运行期间,动态地将某种依赖关系注入到对象之中。
其作用简单来讲就是利用依赖关系注入的方式,把复杂的应用程序分解为互相合作的对象,从而降低解决问题的复杂度,实现应用程序代码的低耦合、高扩展。
Laravel 中的服务容器是用于管理类的依赖和执行依赖注入的工具。
Facades 是什么?#
Facades(一种设计模式,通常翻译为外观模式)提供了一个”static”(静态)接口去访问注册到 IoC 容器中的类。提供了简单、易记的语法,而无需记住必须手动注入或配置的长长的类名。此外,由于对 PHP 动态方法的独特用法,也使测试起来非常容易。
Contract 是什么?#
Contract(契约)是 laravel 定义框架提供的核心服务的接口。Contract 和 Facades 并没有本质意义上的区别,其作用就是使接口低耦合、更简单。
依赖注入的原理?#
依赖注入 (DI) 和控制反转 (IOC) 是从不同的角度的描述的同一件事情,就是指通过引入 IOC 容器,利用依赖关系注入的方式,实现对象之间的解耦。
我们把依赖注入应用到软件系统中,再来描述一下这个过程:
对象 A 依赖于对象 B, 当对象 A 需要用到对象 B 的时候,IOC 容器就会立即创建一个对象 B 送给对象 A。IOC 容器就是一个对象制造工厂,你需要什么,它会给你送去,你直接使用就行了,而再也不用去关心你所用的东西是如何制成的,也不用关心最后是怎么被销毁的,这一切全部由 IOC 容器包办。
在传统的实现中,由程序内部代码来控制组件之间的关系。我们经常使用 new 关键字来实现两个组件之间关系的组合,这种实现方式会造成组件之间耦合。IOC 很好地解决了该问题,它将实现组件间关系从程序内部提到外部容器,也就是说由容器在运行期将组件间的某种依赖关系动态注入组件中。
PHP7 和 PHP5 的区别,具体多了哪些新特性?#
性能提升了两倍
结合比较运算符 (<=>)
标量类型声明
返回类型声明
try…catch 增加多条件判断,更多 Error 错误可以进行异常处理
匿名类,现在支持通过 new class 来实例化一个匿名类,这可以用来替代一些 “用后即焚” 的完整类定义
…… 了解更多查看文章链接 PHP7 新特性
为什么 PHP7 比 PHP5 性能提升了?#
变量存储字节减小,减少内存占用,提升变量操作速度
改善数组结构,数组元素和 hash 映射表被分配在同一块内存里,降低了内存占用、提升了 cpu 缓存命中率
改进了函数的调用机制,通过优化参数传递的环节,减少了一些指令,提高执行效率
php7 新特性#
标量类型声明
返回值类型声明
语法糖:null 合并运算符,太空船操作符
define 允许定义常量数组,
匿名类,
新增了一些函数 intdiv (),随机函数,
1、php7.0 相比于 php5.6 的新特性
参考:php.net/manual/zh/migration70.new-f...
2、php7.1 相对于 php7.0 的新特性
参考:php.net/manual/zh/migration71.new-f...
3、php7.2 相对于 php7.1 的新特性
参考:php.net/manual/zh/migration72.new-f...
php8 新特性#
新增联合类型(Union Types);
添加了 WeakMap;
添加了 ValueError 类;
新增的特性大多是语法糖,主要是 JIT。
JIT 是一种编译器策略,它将代码表述为一种中间状态,在运行时将其转换为依赖于体系结构的机器码,并即时执行,在 PHP8 中,Zend VM 不需要解释某些操作码,并且这些指令将直接作为 CPU 级指令执行。
IT 和 opcache 区别
要说明 opcode cache 与 JIT 的区别,得先明白,字节码,又叫中间码与机器码的区别。
简答的说,提升 php 执行效率,更快了。
相关链接 www.laruence.com/2020/06/27/5963.h...
简述 php 的垃圾收集机制。#
关键词:使用了引用计数器
简述:
1. PHP可以自动进行内存管理,清除不需要的对象,主要使用了引用计数。
2. php中的变量存储在变量容器zval中,zval中除了存储变量类型和值外,还有is_ref和refcount字段。
refcount表示指向变量的元素个数,is_ref表示变量是否有别名。
如果refcount为0时,就回收该变量容器。
3. 为了解决循环引用内存泄露问题 , 使用同步周期回收算法。
如果一个zval的refcount减1之后大于0,它就会进入垃圾缓冲区。
当缓冲区达到最大值后,回收算法会循环遍历zval,判断其是否为垃圾,并进行释放处理。www.php.net/manual/zh/features.gc....
php-fpm 是什么?#
PHP5.3.3 开始集成了 php-fpm 模块,不再是第三方的包了。PHP-FPM 提供了更好的 PHP 进程管理方式,可以有效控制内存和进程、可以平滑重载 PHP 配置。
重点:
php-fpm 是 fastcgi 的实现。
PHP-FPM(FastCGI Process Manager:FastCGI进程管理器)是一个PHPFastCGI管理器,对于PHP 5.3.3之前的php来说,是一个补丁包 [1] ,旨在将FastCGI进程管理整合进PHP包中。如果你使用的是PHP5.3.3之前的PHP的话,就必须将它patch到你的PHP源代码中,在编译安装PHP后才可以使用。
相对Spawn-FCGI,PHP-FPM在CPU和内存方面的控制都更胜一筹,而且前者很容易崩溃,必须用crontab进行监控,而PHP-FPM则没有这种烦恼。
php-fpm是 FastCGI 的实现,并提供了进程管理的功能。
进程包含 master 进程和 worker 进程两种进程。
master 进程只有一个,负责监听端口,接收来自 Web Server 的请求,而 worker 进程则一般有多个(具体数量根据实际需要配置),每个进程内部都嵌入了一个 PHP 解释器,是 PHP 代码真正执行的地方。
使用PHP-FPM来控制PHP-CGI的FastCGI进程
/usr/local/php/sbin/php-fpm{start|stop|quit|restart|reload|logrotate}
--start 启动php的fastcgi进程
--stop 强制终止php的fastcgi进程
--quit 平滑终止php的fastcgi进程
--restart 重启php的fastcgi进程
--reload 重新平滑加载php的php.ini
--logrotate 重新启用log文件php-fpm 的运行模型?#
多进程同步阻塞模式
php-fpm 是一种 master(主)/worker(子)多进程架构模型。
当 PHP-FPM 启动时,会读取配置文件,然后创建一个 Master 进程和若干个 Worker 进程(具体是几个 Worker 进程是由 php-fpm.conf 中配置的个数决定)。Worker 进程是由 Master 进程 fork 出来的。
master 进程主要负责 CGI 及 PHP 环境初始化、事件监听、Worker 进程状态等等,worker 进程负责处理 php 请求。
master 进程负责创建和管理 woker 进程,同时负责监听 listen 连接,master 进程是多路复用的;woker 进程负责 accept 请求连接,同时处理请求,一个 woker 进程可以处理多个请求(复用,不需要每次都创建销毁 woker 进程,而是达到处理一定请求数后销毁重新 fork 创建 worker 进程),但一个 woker 进程一次只能处理一个请求。
cgi,php-cgi,php-fpm,fastcgi 的区别?#
cgi
cgi 是一个 web server 与 cgi 程序(这里可以理解为是 php 解释器)之间进行数据传输的协议,保证了传递的是标准数据。
php-cgi
php-cgi 是 php 解释器。他自己本身只能解析请求,返回结果,不会管理进程。php-fpm 是调度管理 php-cgi 进程的程序。
Fastcgi
Fastcgi 是用来提高 cgi 程序(php-cgi)性能的方案 / 协议。
cgi 程序的性能问题在哪呢?”PHP 解析器会解析 php.ini 文件,初始化执行环境”,就是这里了。标准的 CGI 对每个请求都会执行这些步骤,所以处理的时间会比较长。
Fastcgi 会先启一个 master,解析配置文件,初始化执行环境,然后再启动多个 worker。当请求过来时,master 会传递给一个 worker,然后立即可以接受下一个请求。这样就避免了重复劳动,效率自然提高。而且当 worker 不够用时,master 可以根据配置预先启动几个 worker 等着;当然空闲 worker 太多时,也会停掉一些,这样就提高了性能,也节约了资源。这就是 Fastcgi 的对进程的管理。
php-fpm
fastcgi 是一个方案或者协议,php-fpm 就是 FastCGI 的后端实现,也就是说,进程分配和管理是 FPM 来做的。官方对 FPM 的解释:【Fastcgi Process Manager】【Fastcgi 进程管理器】。
php-fpm 的管理对象是 php-cgi,他负责管理一个进程池,来处理来自 Web 服务器的请求。
对于 php.ini 文件的修改,php-cgi 进程是没办法平滑重启的,有了 php-fpm 后,就把平滑重启成为了一种可能,php-fpm 对此的处理机制是新的 worker 用新的配置,已经存在的 worker 处理完手上的活就可以歇着了,通过这种机制来平滑过度的。
php-fpm 如何完成平滑重启?#
修改 php.ini 之后,php-cgi 进程的确是没办法平滑重启的。php-fpm 对此的处理机制是新的 worker 用新的配置,已经存在的 worker 处理完手上的活就可以歇着了,通过这种机制来平滑过度。
php-fpm 和 nginx 的通信机制是怎么样的?#
看下 nginx 的配置文件:
Nginx 中 fastcgi_pass 的配置:
location ~ .php$ {
root /home/wwwroot;
fastcgi\_pass 127.0.0.1:9000;
#fastcgi_pass unix:/var/run/php-fpm/php-fpm.sock;
#fastcgi_pass unix:/tmp/php-cgi.sock;
try_files $uri /index.php =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}因为 nginx 不能直接执行 php,所以需要借用 fastcgi 模块,和 php-fpm 进行通信。有两种方式;
TCP
UNIX Domain Socket
TCP 是 IP 加端口,可以跨服务器;
而 UNIX Domain Socket 不经过网络,只能用于 Nginx 跟 PHP-FPM 都在同一服务器的场景。具体配置:
方式 1:
php-fpm.conf: listen = 127.0.0.1:9000
nginx.conf: fastcgi_pass 127.0.0.1:9000;方式 2:
php-fpm.conf: listen = /tmp/php-fpm.sock
nginx.conf: fastcgi_pass unix:/tmp/php-fpm.sock;值得一提的是,MySQ 命令行客户端连接 mysqld 服务也类似有这两种方式:
使用 Unix Socket 连接 (默认):
mysql -uroot -p --protocol=socket --socket=/tmp/mysql.sock使用 TCP 连接:
mysql -uroot -p --protocol=tcp --host=127.0.0.1 --port=3306怎么选定用 tcp 还是套接字的方式和 nginx 通信?
tcp 方式是面向链接的协议,更稳定。
套接字效率更高,但是限制 nginx 和 php-fpm 都在一台服务器。
php-fpm 在请求链路的体现,画出来?
www.example.com
|
|
\!/
Nginx
|
|
\!/
路由到www.example.com/index.php
|
|
\!/
加载nginx的fast-cgi模块
|
|
\!/
fast-cgi监听127.0.0.1:9000地址
|
|
\!/
www.example.com/index.php请求到达127.0.0.1:9000
|
|
\!/
php-fpm 监听127.0.0.1:9000
|
|
\!/
php-fpm 接收到请求,启用worker进程处理请求
|
|
\!/
php-fpm 处理完请求,返回给nginx
|
|
\!/
nginx将结果通过http返回给浏览器php-fpm 有几种工作模式?#
PHP-FPM 进程管理方式有动态(Dynamic)、静态(Static)、按需分配(Ondemand)三种。
动态
会初始化创建一部分 worker,在运行过程中,动态调整 worker 数量,最大 worker 数受 pm.max_children 和 process.max
listen = 127.0.0.1:9001
pm = dynamic
pm.max_children = 10
pm.start_servers = 2
pm.min_spare_servers = 1
pm.max_spare_servers = 6当空闲进程数小于 min_spare_servers 时,创建新的子进程,总子进程数小于等于 pm.max_children,小于等于 process.max
当空闲进程数大于 max_spare_servers,会杀死启动时间最长的子进程
如果子进程(idle 状态)数大于 max_children, 会打印 warning 日志,结束处理
process 小于 max_children ,计算一个 num,启动 num 个 worker
优点:动态扩容,不浪费系统资源
缺点:所有 worker 都在工作,新的请求到来需要等待创建 worker 进程,最长等待 1s(内部存在一个 1s 的定时器,去查看,创建进程),频繁启停进程消耗 cpu,请求数稳定,不需要频繁销毁
静态
启动固定大小数量的 worker,也有 1s 的定时器,用于统计进程的一些状态信息,例如空闲 worker 个数,活动 worker 个数
pm.max_children = 10 #必须配置这个参数,而且只有这个参数有效
优点:不用动态判断负载,提升性能
缺点:如果配置成 static,只需要考虑 max_children 数量,数量取决于 cpu 的个数和应用的响应时间,一次启动固定大小进程浪费系统资源
按需分配
php-fpm 启动的时候不会启动 worker 进程,按需启动 worker,有链接进来后,才会启动
listen = 127.0.0.1:9001
pm = ondemand
pm.process_idle_timeout = 60
pm.max_children = 10连接到来时(只有链接,不没有数据也会创建,telnet 也会创建),创建新 worker 进程,worker 进程数的创建收 max_children 设置限制,也受限于全局的 process.max 设置(三种模式都受限此,下文中有全局配置项讲解),如果空闲时间超过了 process_idle_timeout 的设置就会销毁 worker 进程
优点:按流量需求创建,不浪费系统资源,
缺点:因为 php-fpm 是短连接的,如果每次请求都先建立连接,大流量场景下会使得 master 进程变得繁忙,浪费 cpu,不适合大流量模式
不推荐使用此模式
| 工作模式 | 特点 |
|---|---|
| 动态 | 均衡优先,适合小内存服务器,2g 左右 |
| 静态 | 性能优先, 适合大内存机器 |
| 按需分配 | 内存优先,适合微小的内存,2g 以下 |
怎么选定 php-fpm 的 worker 进程数?#
动态建立进程个数
- N+20% 到 M/m 之间
- N 是 cpu 核数,M 是内存,m 是每个 php 进程内存数
静态进程个数
- M/(m*1.2)
- pm.max_requests, 设置最大请求数,达到这个数量以后,会自动长期 worker 进程,繁殖内存意外增长
注意:PHP 程序在执行完成后,或多或少会有内存泄露的问题。这也是为什么开始的时候一个 php-fpm 进程只占用 3M 左右内存,运行一段时间后就会上升到 20-30M。所以需要每个 worker 进程处理完一定的请求后,销毁重新创建。
cpu 密集型的 pm.max_children 不能超过 cpu 内核数,但是 web 服务属于 IO 密集型的,可以将 pm.max_children 的值设置大于 cpu 核数。
php-fpm 如何优化?#
(1)避免程序跑死(hang)
在负载较高的服务器上定时重载 php-fpm,reload 可以平滑重启而不影响生产系统的 php 脚本运行,每 15 分钟 reload 一次,定时任务如下:
0-59/15 * * * * /usr/local/php/sbin/php-fpm reload
(2)合理增加单个 worker 进程最大处理请求数,减少内存消耗
最大处理请求数是指一个 php-fpm 的 worker 进程在处理多少个请求后就终止掉,master 进程会重新 respawn 新的。该配置可以避免 php 解释器自身或程序引起的 memory leaks。默认值是 500,可以修改为如下配置:
pm.max_requests = 1024
(3)开启静态模式,指定数量的 php-fpm 进程,减少内存消耗
说下你最常用的 php 框架(laravel 框架)的生命周期?#
自己在站内搜。
生命周期概览#
第一件事
Laravel 应用的所有请求入口都是 public/index.php 文件,所有请求都会被 web 服务器(Apache/Nginx)导向这个文件。 index.php 文件包含的代码并不多,但是,这里是加载框架其它部分的起点。
index.php 文件载入 Composer 生成的自动加载设置,然后从 bootstrap/app.php 脚本获取 Laravel 应用实例,Laravel 的第一个动作就是创建服务容器实例。
HTTP/Console 内核
接下来,请求被发送到 HTTP 内核或 Console 内核(分别用于处理 Web 请求和 Artisan 命令),这取决于进入应用的请求类型。这两个内核是所有请求都要经过的中央处理器,现在,就让我们聚焦在位于 app/Http/Kernel.php 的 HTTP 内核。
HTTP 内核继承自 Illuminate\Foundation\Http\Kernel 类,该类定义了一个 bootstrappers 数组,这个数组中的类在请求被执行前运行,这些 bootstrappers 配置了错误处理、日志、检测应用环境以及其它在请求被处理前需要执行的任务。
HTTP 内核还定义了一系列所有请求在处理前需要经过的 HTTP 中间件,这些中间件处理 HTTP 会话的读写、判断应用是否处于维护模式、验证 CSRF 令牌等等。
HTTP 内核的 handle 方法签名相当简单:获取一个 Request,返回一个 Response,可以把该内核想象作一个代表整个应用的大黑盒子,输入 HTTP 请求,返回 HTTP 响应。
服务提供者
内核启动过程中最重要的动作之一就是为应用载入服务提供者,应用的所有服务提供者都被配置在 config/app.php 配置文件的 providers 数组中。首先,所有提供者的 register 方法被调用,然后,所有提供者被注册之后,boot 方法被调用。
服务提供者负责启动框架的所有各种各样的组件,比如数据库、队列、验证器,以及路由组件等,正是因为他们启动并配置了框架提供的所有特性,所以服务提供者是整个 Laravel 启动过程中最重要的部分。
分发请求
一旦应用被启动并且所有的服务提供者被注册,Request 将会被交给路由器进行分发,路由器将会分发请求到路由或控制器,同时运行所有路由指定的中间件。
聚焦服务提供者#
服务提供者是启动 Laravel 应用中最关键的部分,应用实例被创建后,服务提供者被注册,请求被交给启动后的应用进行处理,整个过程就是这么简单!
对 Laravel 应用如何通过服务提供者构建和启动有一个牢固的掌握非常有价值,当然,应用默认的服务提供者存放在 app/Providers 目录下。
默认情况下,AppServiceProvider 是空的,这里是添加自定义启动和服务容器绑定的最佳位置,当然,对大型应用,你可能希望创建多个服务提供者,每一个都有着更加细粒度的启动。
laravel 请求生命周期流程图,如下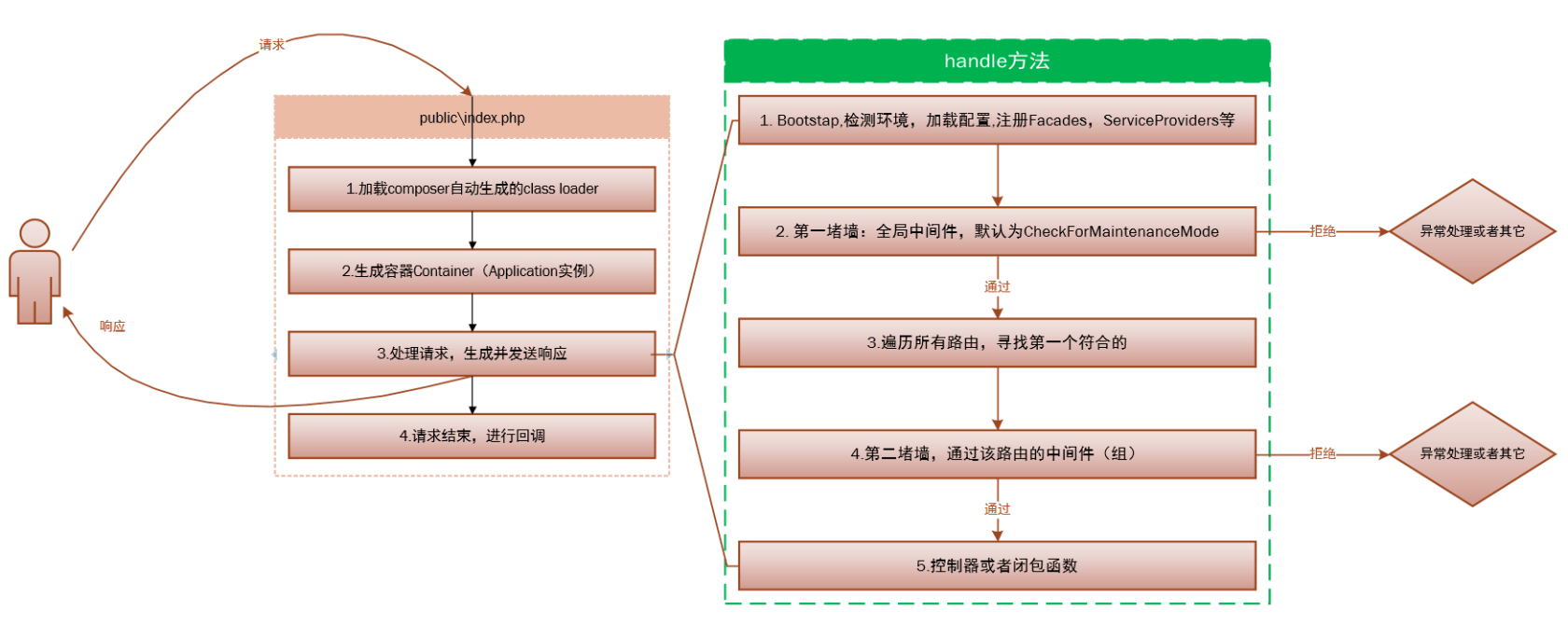
什么是依赖注入,解决了那些问题#
1.什么是依赖注入
依赖注入是控制反转的一种实现,实现代码解耦,便于单元测试。因为它并不需要了解自身所依赖的类,而只需要知道所依赖的类实现了自身所需要的方法就可以了。
2.解决那些问题
依赖之间的解耦
单元测试,方便Mock什么是控制反转#
控制反转 是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。其中最常见的方式叫做依赖注入(Dependency Injection, DI), 还有一种叫"依赖查找"(Dependency Lookup)。通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体,将其所依赖的对象的引用传递给它。也可以说,依赖被注入到对象中。怎么理解 依赖注入 (DI) 与控制反转 (Ioc)?#
这让我想起了怎么理解 nginx 正向代理和反向代理…
IOC(inversion of control)控制反转模式;控制反转是将组件间的依赖关系从程序内部提到外部来管理;
DI(dependency injection)依赖注入模式;依赖注入是指将组件的依赖通过外部以参数或其他形式注入;
依赖注入和控制反转说的实际上是同一个东西,它们是一种设计模式,这种设计模式用来减少程序间的耦合。依赖注入和控制反转是对同一件事情的不同描述,从某个方面讲,就是它们描述的角度不同。
1、依赖注入是从应用程序的角度在描述,可以把依赖注入,即:应用程序依赖容器创建并注入它所需要的外部资源;
2、而控制反转是从容器的角度在描述,即:容器控制应用程序,由容器反向的向应用程序注入应用程序所需要的外部资源。
laravel 的控制反转
是通过反射和递归实现的容器,容器作为全局注册表,使用容器的依赖注入做为一种桥梁来解决依赖,使类之间耦合度更低。
php 的弱类型是怎么实现的?#
php 是通过 c 语言进行实现,但是 c 语言为强类型,那 php 的弱语言类型是通过 PHP 底层设计了一个 zval (“Zend value” 的缩写) 的数据结构,可以用来表示任意类型的 PHP 值。通过共同体实现弱类型变量声明。
简单说下对 php 底层变量(zval)数据结构的理解#
1. 变量存储结构
变量的值存储到以下所示 zval 结构体中。 zval 结构体定义在 Zend/zend.h 文件,其结构如下:
typedef struct _zval_struct zval;
...
struct _zval_struct {
/* Variable information */
zvalue_value value; /* value */
zend_uint refcount__gc;
zend_uchar type; /* active type */
zend_uchar is_ref__gc;
};
PHP 使用这个结构来存储变量的所有数据。和其他编译性静态语言不同, PHP 在存储变量时将 PHP 用户空间的变量类型也保存在同一个结构体中。这样我们就能通过这些信息获取到变量的类型。
zval 结构体中有四个字段,其含义分别为:
| 属性名 | 含义 | 默认值 |
|---|---|---|
| refcount__gc | 表示引用计数 | 1 |
| is_ref__gc | 表示是否为引用 | 0 |
| value | 存储变量的值 | |
| type | 变量具体的类型 |
2. 变量类型:
zval 结构体的 type 字段就是实现弱类型最关键的字段了,type 的值可以为: IS_NULL、IS_BOOL、IS_LONG、IS_DOUBLE、IS_STRING、IS_ARRAY、IS_OBJECT 和 IS_RESOURCE 之一。 从字面上就很好理解,他们只是类型的唯一标示,根据类型的不同将不同的值存储到 value 字段。 除此之外,和他们定义在一起的类型还有 IS_CONSTANT 和 IS_CONSTANT_ARRAY。
这和我们设计数据库时的做法类似,为了避免重复设计类似的表,使用一个标示字段来记录不同类型的数据。
常见的设计模式有哪些?#
简单说下单例模式,注册树模式,适配模式,策略模式,观察者模式。
记住三私一公,最容易考察现场撸码的题。
请看本人文档
《汪春波 - php 技术博客 - 设计模式》
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



推荐文章: