
rust-algorithms:17-BWT
0 / 0 / 创建于 3年前
 godme 的个人博客
godme 的个人博客
算法梗概
详细可以看一下大佬的文章,这里主要说一下LF的对应关系。
F和L
作为First和Last,两者的区分十分明显。
就算我们不知道两者之间的数据,但是单看F和L,我们一定知道边界情况。内容
因为全部会循环一遍,因此在F(L)中出现过的数据,一定遍历了全部元素。F的固有顺序
因为F本身就是排序后的产物,因此只要有乱序后的数据,随时能够得到F。
因此,最后保留L,其实是可以间接算出F的。位置信息的保留
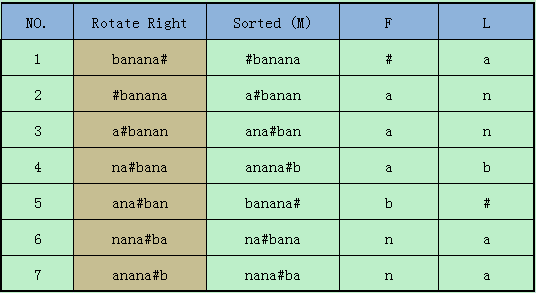
因为插入的#或者$是完全小于任意字符的字符序的。
因此,循环字符的排序,即使是相同的字符,排序过后也隐含的保留了字符出现的顺序。字符串的恢复
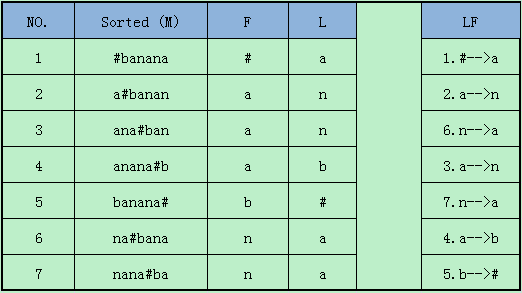
我们固然已经不知道中间内容,但是通过下面的几点,可以毫无歧义的进行恢复- 通过
L准确恢复F,并且L第一个字符肯定是最后一个 - 通过
F和L的对应关系,能够明确映射出首尾关系 - 通过
F隐含的字符序,恢复原先的字符排列顺序
整体就是:
- 将整体的字符序隐藏在
F中 - 将
F隐藏在L中,切L自带字符信息 - 通过
L恢复F - 通过
F的字符序,L的字符信息、L和F的对照关系进行恢复
- 通过
变体
不管是使用#还是$,还是其他的办法,都存在一个问题
我们使用什么字符来保证最小字符序
这将引起两个问题
- 我们需要先遍历一遍
- 字符串中包含最小字符序的字符
换句话说,我们为什么需要最小字符序的字符?
是因为缺少了这个最小字符序的字符就无法构建出如此条件的情况?
事实是,选取最小字符序字符,可以保证F排序;
进而保证L开端就可以作为解析的开始入门符号。
这里不可避免的涉及上面两个问题,能否有更好的办法完成这个工作呢?
有!那就是将作为解析的开端作为编码结果的一部分进行记录。
这里引申出一个有意思的问题:是否只能够存在一个解析开端。
诚然,历经一个循环遍历周期,循环串必定至少一次的和原串重合
我们将第n个周期的初始顺序记录,都必定能够一个无误的开端。
但是在一次循环遍历周期中,如果变体串和原串相等,也就是出现了回环串
是否可以作为解析开端呢?
答案是必然可以的,因为
- 我们只是需要一个开端,无误的开端
- 我们需要的不是原来的字符串,而是和原字符串相等的字符串
正如我们恢复的数据不是原来的数据,而是相同的数据
载体的不等,并不妨碍数据的相同
编码
pub fn encode(input: String) -> (String, usize) {
let len = input.len();
let mut table = Vec::<String>::with_capacity(len);
// 字符移位循环
for i in 0..len {
table.push(input[i..].to_owned() + &input[..i]);
}
// 排序M
table.sort_by_key(|a| a.to_lowercase());
let mut encoded = String::new();
let mut index: usize = 0;
for (i, item) in table.iter().enumerate().take(len) {
// 构造L
encoded.push(item.chars().last().unwrap());
// 解析开端,可以只赋值一次,回环子串也没问题
if item.eq(&input) {
index = i;
}
}
(encoded, index)
}解码
pub fn decode(input: (String, usize)) -> String {
let len = input.0.len();
let mut table = Vec::<(usize, char)>::with_capacity(len);
// L序号标记,后续映射表可查
// 不仅是字符,还有顺序要求,不能直接使用Map
// table是L和F二合一,目的是确定L的解析顺序,和F字符无关,确定映射关系即可
for i in 0..len {
table.push((i, input.0.chars().nth(i).unwrap()));
}
// 恢复F,带序号
table.sort_by(|a, b| a.1.cmp(&b.1));
let mut decoded = String::new();
let mut idx = input.1;
for _ in 0..len {
// 根据L填充数据
decoded.push(table[idx].1);
// 反查F确定顺序
idx = table[idx].0;
}
decoded
}用途
测序什么的我完全不懂,但是经过BWT算法计算之后的最大特征就是:相同字符紧密排列。
因为F是排序的,循环遍历的首尾呼应,L中的数据也是紧密字符序。
对于重复字符而言,更利于压缩,这也造就了它通用压缩的使用范围。```actionscript
pub fn decode(input: (String, usize)) -> String {
let len = input.0.len();
let mut table = Vec::<(usize, char)>::with_capacity(len);
// L序号标记,后续映射表可查
// 不仅是字符,还有顺序要求,不能直接使用Map
// table是L和F二合一,目的是确定L的解析顺序,和F字符无关,确定映射关系即可
for i in 0..len {
table.push((i, input.0.chars().nth(i).unwrap()));
}
// 恢复F,带序号
table.sort_by(|a, b| a.1.cmp(&b.1));
let mut decoded = String::new();
let mut idx = input.1;
for _ in 0..len {
// 根据L填充数据
decoded.push(table[idx].1);
// 反查F确定顺序
idx = table[idx].0;
}
decoded
}
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: