
Go高性能编程-了解内存对齐以及Go中的类型如何对齐保证
8 / 0 / 创建于 3年前
 lin钟一 的个人博客
lin钟一 的个人博客
前言
本文将介绍Go中的各种字段类型的字节数和对齐保证。
详细可见个人博客:linzyblog.netlify.app/
一、内存对齐
1、什么是内存对齐?
元素是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。从结构体存储的首地址开始,每个元素放置到内存中时,它都会认为内存是按照自己的大小(通常它为4字节(32位)或8字节(64位))来划分的,因此元素放置的位置一定会在自己宽度的整数倍上开始,这就是所谓的内存对齐。
2、为什么需要内存对齐?
CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如 32 位的 CPU ,字长为 4 字节,那么 CPU 访问内存的单位也是 4 字节。64位 CPU 访问内存的单位是8个字节。
这么设计的目的,是减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。比如同样读取 8 个字节的数据,一次读取 4 个字节那么只需要读取 2 次。CPU 始终以字长访问内存。
提出设想如果我们不进行内存对齐,而是按照类型字节长度紧密对齐呢?
变量 a、b 各占据 3 字节的空间,我们使用32位 CPU 访问内存读取变量,例如:
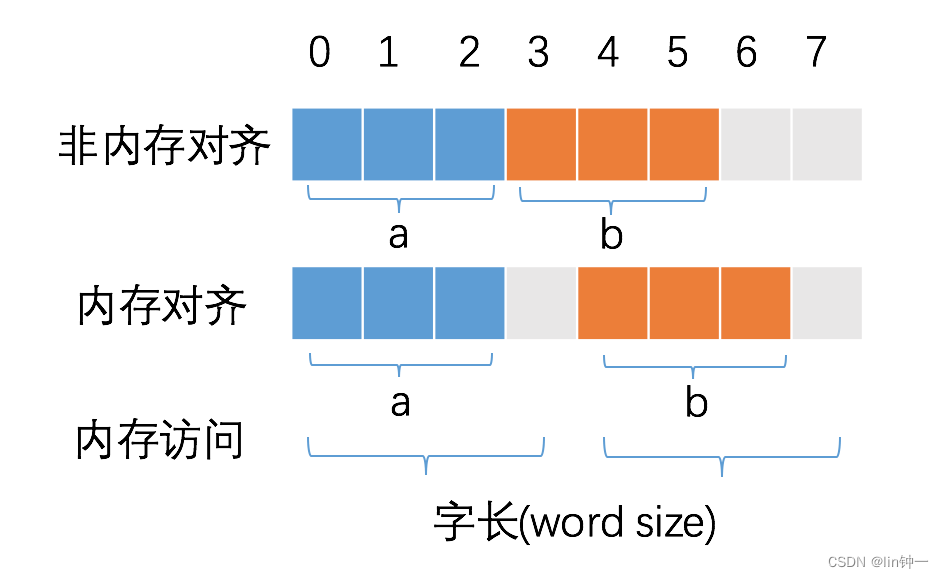
- 内存对齐后,a、b 占据 4 字节空间,CPU 读取 b 变量的值只需要进行一次内存访问。
- 不进行内存对齐,CPU 读取 b 变量的值需要进行 2 次内存访问。第一次访问得到 b 变量的第 1 个字节,第二次访问得到 b 变量的后两个字节,最后在寄存器中将剩余的数据合并得到我们想要变量 b 的数据。
从这个例子中也可以看到,内存对齐对实现变量的原子性操作也是有好处的,每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的,这个特性在并发场景下至关重要。
简言之:合理的内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性。
内存对齐是为了减少访问内存的次数,提高CPU读取内存数据的效率,如果内存不对齐,访问相同的数据需要更多的访问内存次数。
二、Go中的类型对齐保证
为了充分利用CPU指令来达到最佳程序性能,为一个特定类型的值开辟的内存块的起始地址必须为某个整数N的倍数,N被称为此类型的值地址对齐保证,或者简单地称为此类型的对齐保证。 我们也可以说此类型的值的地址保证为N字节对齐的。
1、数据类型的大小和对齐保证
对于当前的标准 Go 编译器(版本 1.19),字段对齐保证和类型的一般对齐保证是相等的。
对于不同的类型,对应的对齐保证大小和占用的内存大小:
| 类型 | 对齐保证(字节数) | 占用的内存大小(字节数) |
|---|---|---|
| byte, uint8, int8 | 1 | 1 |
| uint16, int16 | 2 | 2 |
| uint32, int32, float32 | 4 | 4 |
| uint64, int64, float64, complex64 | 8 | 8 |
| complex128 | 16 | 16 |
| string | 8 | 16 |
| array | 取决于元素类型 | |
| struct | 取决于各个字段类型 | |
| uint, int | 取决于编译器实现。通常在32位架构上为4字节,在64位架构上为8字节。 | |
| uintptr | 取决于编译器实现。但必须能够存下任一个内存地址。 |
Go白皮书仅列出了一些类型对齐保证要求,一个合格的Go编译器必须保证:
- 对于任何类型的变量x,
unsafe.Alignof(x)的结果最小为1。 - 对于一个结构体类型的变量x,
unsafe.Alignof(x)的结果为x的所有字段的对齐保证unsafe.Alignof(x.f)中的最大值(但是最小为1)。 - 对于一个数组类型的变量x,
unsafe.Alignof(x)的结果和此数组的元素类型的一个变量的对齐保证相等。
如果结构或数组类型不包含内存大小大于零的字段(或元素),则其大小为零。两个不同的零大小变量在内存中可能具有相同的地址。
2、Go实现内存对齐
Go的unsafe包中有三个函数:
func Sizeof(x ArbitraryType) uintptr
func Offsetof(x ArbitraryType) uintptr
func Alignof(x ArbitraryType) uintptrunsafe.Sizeof 返回变量x的占用字节数,但不包含它所指向内容的大小,对于一个string类型的变量它的大小是16字节,一个指针类型的变量大小是8字节unsafe.Alignof 返回变量x需要的对齐保证,它可以被x地址整除。(一般取结构体数据类型对齐保证的最大值)unsafe.Offsetof 返回结构体成员地址相对于结构体首地址相差的字节数,称为偏移量
在 Go 语言中,我们可以使用 unsafe.Sizeof 计算出一个数据类型实例需要占用的字节数。
type T1 struct {
a int8 //1字节
b int64 //8字节
c int16 //2字节
}
type T2 struct {
a int8
c int16
b int64
}
type T3 struct {
a int8 //1字节
b int32 //4字节
c int16 //2字节
}
func main() {
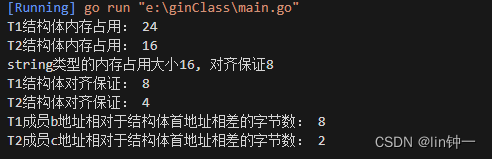
fmt.Println("T1结构体内存占用:", unsafe.Sizeof(T1{}))
fmt.Println("T2结构体内存占用:", unsafe.Sizeof(T2{}))
var s string
fmt.Printf("string类型的内存占用大小%v, 对齐保证%v\n", unsafe.Sizeof(s), unsafe.Alignof(s))
fmt.Println("T1结构体对齐保证:", unsafe.Alignof(T2{}))
fmt.Println("T2结构体对齐保证:", unsafe.Alignof(T3{}))
var t1 T1
var t2 T2
fmt.Println("T1成员b地址相对于结构体首地址相差的字节数:", unsafe.Offsetof(t1.b))
fmt.Println("T2成员c地址相对于结构体首地址相差的字节数:", unsafe.Offsetof(t2.c))
}
1)内存对齐规则
内存对齐的规则,这里只介绍结构体的内存对齐:
- 规则一:结构体第一个字段偏移量为0,后面的字段的偏移量等于成员数据类型大小和字段对齐保证两者取最小值的最小整数倍,如果不满足规则,编译器会在前面填充值为0的字节空间
- 规则二:结构体本身也需要内存对齐,其大小等于各字段类型占用内存最大的和编译器默认对齐保证两者取最小值的最小整数倍
2)计算结构体内存占用大小
为什么这里明明结构体内字段类型和数量都是一样,但是内存大小却不一样?
a、T1为什么是24字节?
- a是int8类型占1字节,对齐保证是1字节。
- 因为是第一个成员,偏移量为0,所有不需要填充,直接排在内存空间的第一位。
- b是int64类型占8字节,对齐保证是8字节。
- 当前偏移量为2,根据规则一,其偏移量为两者中最小值,所以调整后的偏移量为8。
- 在64位架构上,为了让字段b的地址为8字节对齐,需在这里填充7个字节,从第9位开始占用8个字节空间。
- 在32位架构上,为了让字段b的地址为4字节对齐,需在这里填充3个字节,从第5位开始占用8个字节空间。
- c是int16类型占2字节,对齐保证2字节。
- 当前偏移量为16,根据规则一,其偏移量为两者中最小值,所以调整后的偏移量为2。
- 在64位架构上需在这里填充6个字节,从第17位开始占用2个字节空间。
- 在32位架构上需在这里填充2个字节,从第13位开始占用2个字节空间。
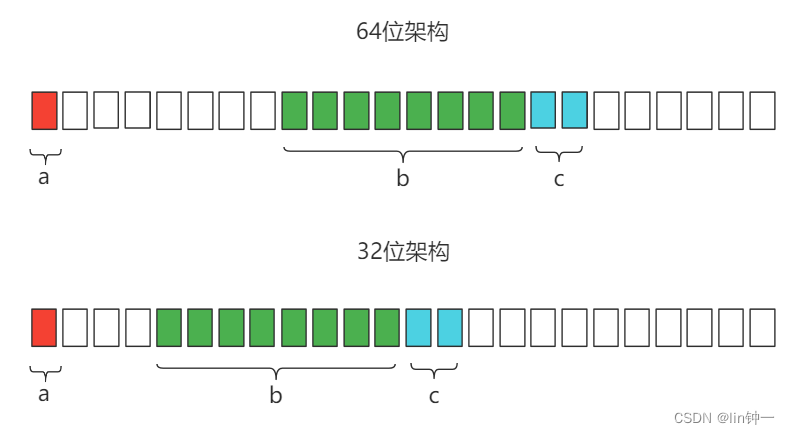
第一条规则算下来结构体T1在64位架构上占用大小为 1+7+8+2=18,在32位架构上占用大小为 1+3+8+2=14
我们再来根据第二条规则计算:
结构体最大字段内存大小为8字节,
- 结构体T1的内存大小在64位架构上,取两者最小值8的最小整数倍,因本身结构体当前大小为18,所以最后结构体大小=3*8=24,为24个字节。
- 结构体T1的内存大小在32位架构上,取两者最小值4的最小整数倍,因本身结构体当前大小为14,所以最后结构体大小=4*4=16,为16个字节。
b、T2为什么是16字节?
- a是int8类型占1字节,对齐保证是1字节。
- 因为是第一个成员,偏移量为0,所有不需要填充,直接排在内存空间的第一位。
- c是int16类型占2个字节,对齐保证2字节。
- 当前偏移量为2,根据规则一,其偏移量为两者中最小值,所以调整后的偏移量为2。
- 为了让字段c的地址为2字节对齐,需在这里填充1个字节,从第3位开始占用2个字节空间。
- b是int64类型占8个字节,对齐保证是8字节。
- 当前偏移量为4,根据规则一,其偏移量为两者中最小值,所以调整后的偏移量为8。
- 在64位架构上,为了让字段b的地址为8字节对齐,需在这里填充4个字节,从第9位开始占用8个字节空间。
- 在32位架构上,为了让字段b的地址为4字节对齐,不需要填充,从第5位开始占用8个字节空间。
- 字节可以保证字段b的地址为4字节对齐的。
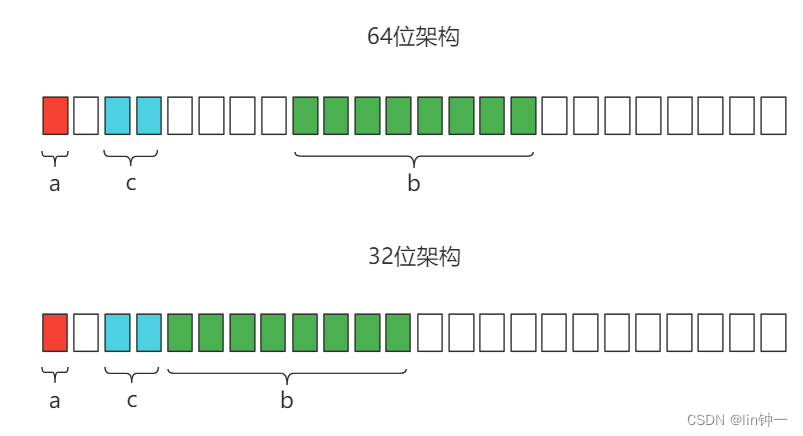
第一条规则算下来
结构体T1在64位架构上占用大小为 1+1+2+4+8=16
结构体T1在32位架构上占用大小为 1+1+2+8=12
我们再来根据第二条规则计算:
结构体最大字段内存大小为8字节,
- 结构体T1的内存大小在64位架构上,取两者最小值8的最小整数倍,因本身结构体当前大小为16,所以最后结构体大小=2*8=16,为16个字节。
- 结构体T1的内存大小在32位架构上,取两者最小值4的最小整数倍,因本身结构体当前大小为12,所以最后结构体大小=3*4=12,为12个字节。
3)struct 内存对齐的技巧
我们通过上面两个结构体,因为字段数据类型顺序不一样,导致内存占用也不同。
每个字段按照自身的对齐倍数来确定在内存中的偏移量,字段排列顺序不同,上一个字段因偏移而浪费的大小也不同。
因此,在对内存特别敏感的结构体的设计上,我们可以通过调整字段的顺序,减少内存的占用。
4)空 struct{} 的作用
空 struct{} 大小为 0,作为其他 struct 的字段时,一般不需要内存对齐。但是有一种情况除外:即当 struct{} 作为结构体最后一个字段时,需要内存对齐。
因为如果有指针指向该字段, 返回的地址将在结构体之外,如果此指针一直存活不释放对应的内存,就会有内存泄露的问题(该内存不因结构体释放而释放)。
因此,当 struct{} 作为其他 struct 最后一个字段时,需要填充额外的内存保证安全。我们做个试验,验证下这种情况。
type demo1 struct {
c int32
a struct{}
}
type demo2 struct {
a struct{}
c int32
}
func main() {
fmt.Println(unsafe.Sizeof(demo1{})) // 8
fmt.Println(unsafe.Sizeof(demo2{})) // 4
}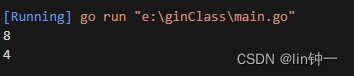
可以看到,demo2{} 的大小为 4 字节,与字段 c 占据空间一致,而 demo1{} 的大小为 8 字节,即额外填充了 4 字节的空间。
3、64位字原子操作的地址对齐保证要求
一个64位字的原子操作要求此64位字的地址必须是8字节对齐的。 这对于标准编译器目前支持的64位架构来说并不是一个问题,因为标准编译器保证任何一个64位字的地址在64位架构上都是8字节对齐的。
然而,在32位架构上,标准编译器为64位字做出的地址对齐保证仅为4个字节。 对一个不是8字节对齐的64位字进行64位原子操作将在运行时刻产生一个恐慌,需要分别读取两次合并。 更糟的是,一些非常老旧的架构并不支持64位原子操作需要的基本指令。
On 386, the 64-bit functions use instructions unavailable before the Pentium MMX.
On non-Linux ARM, the 64-bit functions use instructions unavailable before the ARMv6k core.
On ARM, 386, and 32-bit MIPS, it is the caller's responsibility to arrange for 64-bit alignment of 64-bit words
accessed atomically via the primitive atomic functions (types Int64 and Uint64 are automatically aligned). The
first word in an allocated struct, array, or slice; in a global variable; or in a local variable
(because the subject of all atomic operations will escape to the heap) can be relied upon to be 64-bit aligned.所以大致意思意思:
- 这些非常老旧的架构在今日已经相当的不主流了。 如果一个程序需要在这些架构上对64位字进行原子操作,还有很多其它同步技术可用。
- 对其它不是很老旧的32位架构,有一些方法可以保证在这些架构上对一些64位字的原子操作是安全的。
这里的方法是已分配结构、数组或切片中的第一个(64位)字(元素)可以被认为是8字节对齐的。
这里的已分配解读为一个声明的变量、内置函数make的调用返回值,或者内置函数new的调用返回值所引用的值。如果一个切片是从一个已分配数组派生出来的并且此切片和此数组共享第一个元素,则我们也可以将此切片看作是一个已分配的值。
这里对哪些64位字可以在32位架构上被安全地原子访问的描述是有些保守的。 有很多描述并未包括的64位字在32位架构上也是可以被安全地原子访问的。
比如,如果一个元素类型为64位字的数组或者切片的第一个元素可以被安全地进行64位原子访问,则此数组或切片中的所有元素都可以被安全地进行64位原子访问。 只是因为很难用三言两语将所有在32位架构上可以被安全地原子访问的64位字都罗列出来,所以官方文档采取了一种保守的描述。
下面是一个展示了哪些64位字在32位架构上可以和哪些不可以被安全地原子访问的例子。
type (
T1 struct {
v uint64
}
T2 struct {
_ int16
x T1
y *T1
}
T3 struct {
_ int16
x [6]int64
y *[6]int64
}
)
var a int64 // a可以安全地被原子访问
var b T1 // b.v可以安全地被原子访问
var c [6]int64 // c[0]可以安全地被原子访问
var d T2 // d.x.v不能被安全地被原子访问
var e T3 // e.x[0]不能被安全地被原子访问
func f() {
var f int64 // f可以安全地被原子访问
var g = []int64{5: 0} // g[0]可以安全地被原子访问
var h = e.x[:] // h[0]可以安全地被原子访问
// 这里,d.y.v和e.y[0]都可以安全地被原子访问,
// 因为*d.y和*e.y都是开辟出来的。
d.y = new(T1)
e.y = &[6]int64{}
_, _, _ = f, g, h
}
// 事实上,c、g和e.y.v的所有以元素都可以被安全地原子访问。
// 只不过官方文档没有明确地做出保证。如果一个结构体类型的某个64位字的字段(通常为第一个字段)在代码中需要被原子访问,为了保证此字段值在各种架构上都可以被原子访问,我们应该总是使用此结构体的开辟值。 当此结构体类型被用做另一个结构体类型的一个字段的类型时,此字段应该(尽量)被安排为另一个结构体类型的第一个字段,并且总是使用另一个结构体类型的开辟值。
如果一个结构体含有需要一个被原子访问的字段,并且我们希望此结构体可以自由地用做其它结构体的任何字段(可能非第一个字段)的类型,则我们可以用一个[15]byte值来模拟此64位值,并在运行时刻动态地决定此64位值的地址。 比如:
type Counter struct {
x [15]byte // 模拟:x uint64
}
func (c *Counter) xAddr() *uint64 {
// 此返回结果总是8字节对齐的。
return (*uint64)(unsafe.Pointer(
(uintptr(unsafe.Pointer(&c.x)) + 7)/8*8))
}
func (c *Counter) Add(delta uint64) {
p := c.xAddr()
atomic.AddUint64(p, delta)
}
func (c *Counter) Value() uint64 {
return atomic.LoadUint64(c.xAddr())
}通过采用此方法,Counter类型可以自由地用做其它结构体的任何字段的类型,而无需担心此类型中维护的64位字段值可能不是8字节对齐的。 此方法的缺点是,对于每个Counter类型的值,都有7个字节浪费了。而且此方法使用了非类型安全指针。
Go 1.19引入了一种更为优雅的方法来保证一些值的地址对齐保证为8字节。 Go 1.19在sync/atomic标准库包中加入了几个原子类型。 这些类型包括atomic.Int64和atomic.Uint64。 这两个类型的值在内存中总是8字节对齐的,即使在32位架构上也是如此。 我们可以利用这个事实来确保一些64位字在32位架构上总是8字节对齐的。 比如,无论在32位架构还是64位架构上,下面的代码所示的T类型的x字段在任何情形下总是8字节对齐的。
type T struct {
_ [0]atomic.Int64
x int64
}三、小结
这里主要是验证内存对齐规则对实际存储空间的影响,并验证了内存对齐的规则.平时工作中不需要关心值地址的对齐保证,编译器已经自动完成了相关的工作.除非打算优化下内存消耗.特别是定义结构体时,可以参照下上面的结论.
参考文章:点击跳转
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: