
开源项目 | 一款开源的MySQL分析加速器,让MySQL的分析速度提升最高达50-100倍
1 / 1 / 创建于 3年前 /
 DataXY 的个人博客
DataXY 的个人博客
大家好,首先声明一下,这不是广告贴,我来推荐给所有MySQL的小伙伴们一个开源软件,号称下一代MySQL分析加速器,让MySQL的分析速度加快,最高可达100倍。
开源地址:github.com/stoneatom/stonedb
StoneDB 是国内首款基于 MySQL 的开源 HTAP 数据库,是一款同时支持在线事务处理与在线分析处理的融合型数据库产品,可实现与 MySQL 数据库的无缝切换。StoneDB 具备超高性能、金融级高可用、实时分析、兼容 MySQL 5.6、MySQL 5.7 协议和 MySQL 生态等重要特性。
StoneDB 旨在通过插件化的方式解决 MySQL 数据库本身分析能力欠缺的问题,为用户提供一站式 HTAP 解决方案。StoneDB 从一开始就设计了向后兼容性,无需任何代码修改,用户即可将业务和数据从 MySQL 迁移至 StoneDB,所有的现有 OLTP 和 OLAP 工作负载都可以继续使用 MySQL 数据库体系运行。
核心优势
完全兼容 MySQL 及 MySQL 生态
StoneDB 完全兼容 MySQL 协议及 MySQL 生态,支持 MySQL 客户端工具和周边生态工具,同时适配各类主流 BI 工具。StoneDB 完整地支持标准 SQL 语法,提供 MySQL 常用功能,包括聚合、关联、排序、分组、子查询、触发器、视图、存储过程等。应用无需进行任何业务代码修改即可从 MySQL 切换至 StoneDB,实现业务和数据的无缝迁移。
最小化硬件开销
StoneDB 对部署的服务器的数量和配置没有要求,可支持单节点最小配置运行,实现了数据库硬件开销最小化,显著降低了 HTAP 系统的部署门槛,也节约了运维成本。而行业内常见的 HTAP 数据库对服务器硬件的数量与配置均有最低要求,相比之下,StoneDB 在使用成本上具有显著优势。
事务 + 分析型混合工作负载
StoneDB 为处理事务型/分析型混合工作负载提供了一种全新的一体化解决方案,实现了事务型负载与分析型负载的有效隔离,解决了事务型工作负载和分析型工作负载资源之间的资源竞争问题。事务数据通过 Binlog 方式实时同步到分析引擎,无需复杂且耗时的 ETL 步骤,不仅满足了事务的 ACID 属性,还解决了业务对数据分析实时性的需求。与传统 TP + AP 架构相比,StoneDB 的系统架构更加简单,提高了数据实时性,并且保证了数据一致性。
实时分析
基于原生 MySQL 复制协议,StoneDB 可将事务数据实时同步至分析引擎,数据更新零延迟,分析引擎可直接分析最新数据,提供最实时的决策支持,实现数据即写即用。StoneDB 大幅简化了实时数据服务的架构复杂度,减少了运维成本,提高了业务敏捷性,让实时分析业务能更快成型落地,加速业务推进速度。
完全开源
StoneDB 的核心代码与相关工具完全开源,严格遵守 GPL 2.0 开源协议。
StoneDB 已建立开源社区,拥有丰富的社区人才,帮助产品快速迭代演进。相关技术文档与课程也已开放,赋能开源社区,使开源社区能对社区用户进行帮助与服务,对用户问题反馈进行及时响应。
活跃的社区生态
StoneDB 构建了一个由用户、开发者、贡献者、StoneDB 爱好者以及众多上下游合作伙伴共同建设的开源社区。社区本着“开源开放、共建共享”的基本原则,围绕“3C(Code、Consumer、Community)”为核心发展战略,为 StoneDB 社区参与者提供丰富的学习内容、专业的技术支持和开发指导、开放的交流和分享平台,与广大数据库相关行业人员共同建设高质量的开源社区。
开源地址:github.com/stoneatom/stonedb
全面国产化
StoneDB 是一个由国内团队设计开发、自主可控、并拥有完整知识产权的国产开源数据库产品。为了助力信创产业,StoneDB 一直坚持进行国产化适配,已经或即将完成鲲鹏、海光、飞腾、龙芯、兆芯等国产处理器适配,以及麒麟、统信等国产化操作系统的适配。未来,StoneDB 还会继续与行业伙伴深度合作,共同发展与完善国产基础软件的产业生态,全面助推国产化建设进程和信创产业应用生态发展,为基础软件国产化的创新发展贡献力量。
列式存储
Tianmu 表在磁盘上按列存储。由于关系型数据库中每一列的数据类型都相同,这种连续的空间存储与行式存储相比,能够实现更高的数据压缩比。在读取数据方面,如果查询只需要读取一个字段,在行式存储中,引擎层向服务层返回的包含该字段的所有行,需要消耗更多的网络带宽和 I/O。而处理同一查询,列式存储只需要返回该字段,极大减少了网络带宽和 I/O 的消耗。此外,列式存储无需再为列创建索引和维护索引。
高性能加载
StoneDB 提供独立的数据导入模块,支持不同的数据源和多语言架构。数据在导入前,StoneDB 会对数据进行预处理,包括数据压缩和知识节点(Knowledge Node)的构建。经过预处理的数据在进入存储引擎后,无需再次执行解析、数据验证以及事务处理等操作。
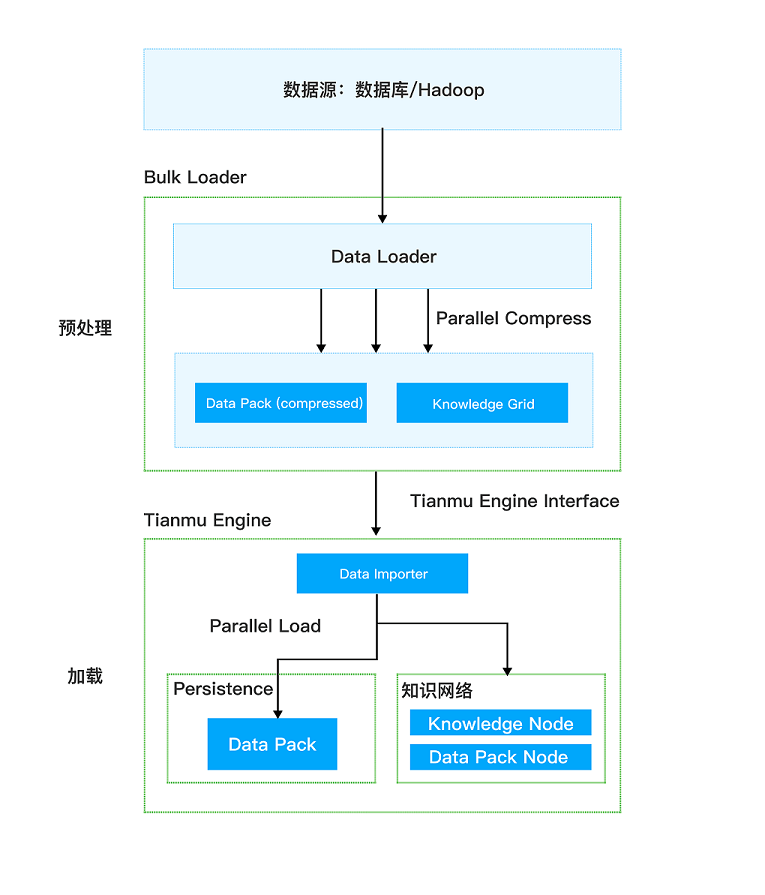
知识网格优化技术
在 StoneDB 中,数据包根据粗糙集概念划分为不相关数据包、可疑数据包、相关数据包:
- 不相关数据包:表示不满足查询条件的数据包,这类数据包直接被忽略。
- 相关数据包:表示满足查询条件的数据包,如果要查询相关的数据包里面的具体数据,需要对数据包进行解压缩,如果根据数据包的元数据节点就能得到数据,那么就不需要解压缩数据包。
- 可疑数据包:表示数据包中的数据部分满足查询条件,需要进一步解压缩数据包才能得到满足条件的数据。
StoneDB 根据知识网格技术过滤掉不相关数据包,对可疑数据包需要进一步解压缩才能得到满足条件的数据。如果能从相关数据包的元数据节点得到结果,则无需对数据包进行解压缩。这样就消除了解压缩数据包的过程和降低 I/O 消耗,提高了查询响应时间和网络利用率。
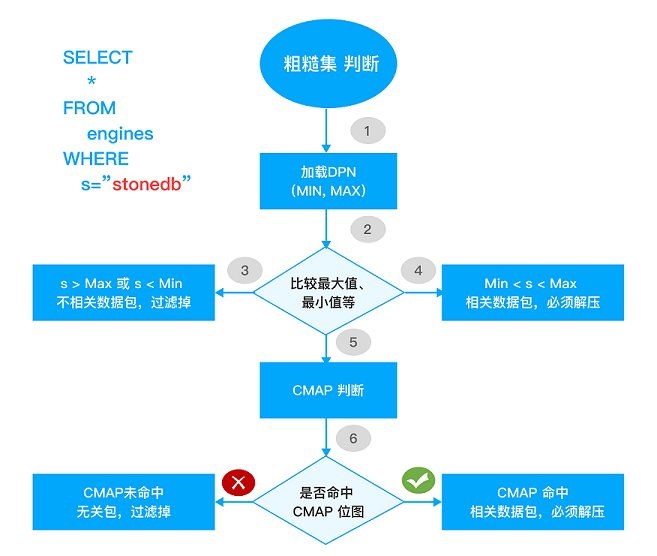
例如,执行如下 SQL 语句:
SELECT count(*) FROM students where score < 550
查询结果如下图所示:
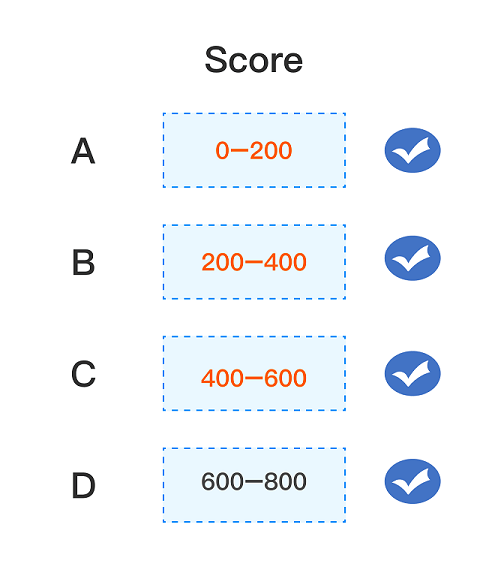
通过知识网格可以确定 2 个关联数据包 A 和 B,和 1 个可疑数据包 C。由于此查询包含聚合函数(count),执行逻辑如下:
- 数据包 A 和 B:StoneDB 只需要从其对应的数据包节点中读取 count 值即可,不会消耗 I/O 资源。
- 数据包 C:StoneDB 读取并解压数据包 C,执行函数计算后,返回结果集。
高效的数据压缩比
在 StoneDB 中,数据是按照列模式进行组织的,列中所有记录的类型一致,可以根据数据类型选择对应的高效压缩算法。列中重复值越多,压缩效果则越明显。数据包大小固定,可以最大化压缩性能和效率;针对同一份数据,StoneDB 会使用不同的压缩算法进行多次压缩,从而实现更高的压缩比,一份 1TB 的原始数据,可压缩至 100GB,外加 1GB 的元数据进行存储,可节约 90% 左右的存储空间。
StoneDB 会根据数据的特性及分布状况,自动选择对应的压缩算法:
- 行程长度编码(Run-Length Encoding,RLE):数据被编码成一系列表示为 (value, start position, runLength) 的三元组。例如,一列中的前 42 个元素都是字母 M,那么在列存储中,这前 42 个元素便可压缩为 (‘M’, 1, 42)。而在行存储的场景中,RLE 只能用于压缩包含大量空白和重复子字符串的大字符串。但是在列存储系统中,RLE 能够得到更广泛的应用,列值单独存储,且经过排序,会存在大量的重复数据。
- 部分匹配预测算法(Prediction by Partial Matching,PPM):PPM 是一种概率压缩算法,使用 trie 记录原始字符串的所有子字符串和出现次数。之后依次为每个数据包生成概率表。匹配时先按 N 阶上下文匹配,如果发现概率为 0,则用 N-1 阶重试,如重试至 N-N,概率仍为 0,则表示该子字符串为新子字符串,输出转义码。
- 增量编码(Delta Coding):增量编码找一个参照值,将所有值减去参照值,从而缩小范围。参照值可以选择数据本身,或者数据所在的位置。
- 基于数据的增量编码:适用于重复率低,但彼此差值较小的数据列。
- 基于位置的增量编码:适用于重复率高,但分布比较随机的数据列。
除此之外,还会针对一些特定业务场景开发高效压缩算法,例如 Email 地址、IP 地址、URL 等。
欢迎大家在Github上点点关注,可以大胆的、毫不吝啬的、甚至简单粗暴地测试一下,给我们提提意见~
开源地址:github.com/stoneatom/stonedb
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: