
记一次nginx拦截爬虫
3 / 10 / 创建于 3年前 /
 EdwinYang 的个人博客
EdwinYang 的个人博客
- 前言:
最近发现服务器在某个时间段,内存疯狂飙升,开始还以为是正常的业务造成的,升级服务器内存,发现还是没有解决问题;(这里自己偷懒了,一开始没有找到问题,默认为就是业务量上来了)
马上查看nginx日志,发现了一些不同寻常的请求: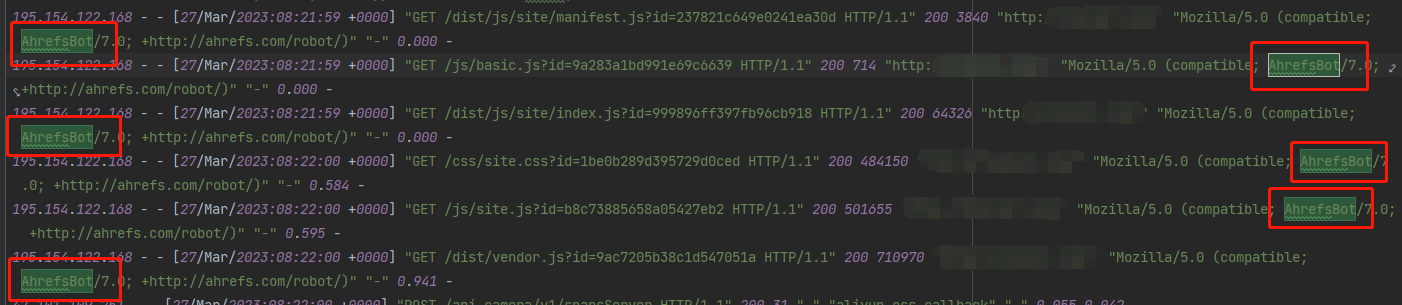
这是什么玩意,怀揣着好奇心马上去搜索了一下,结果: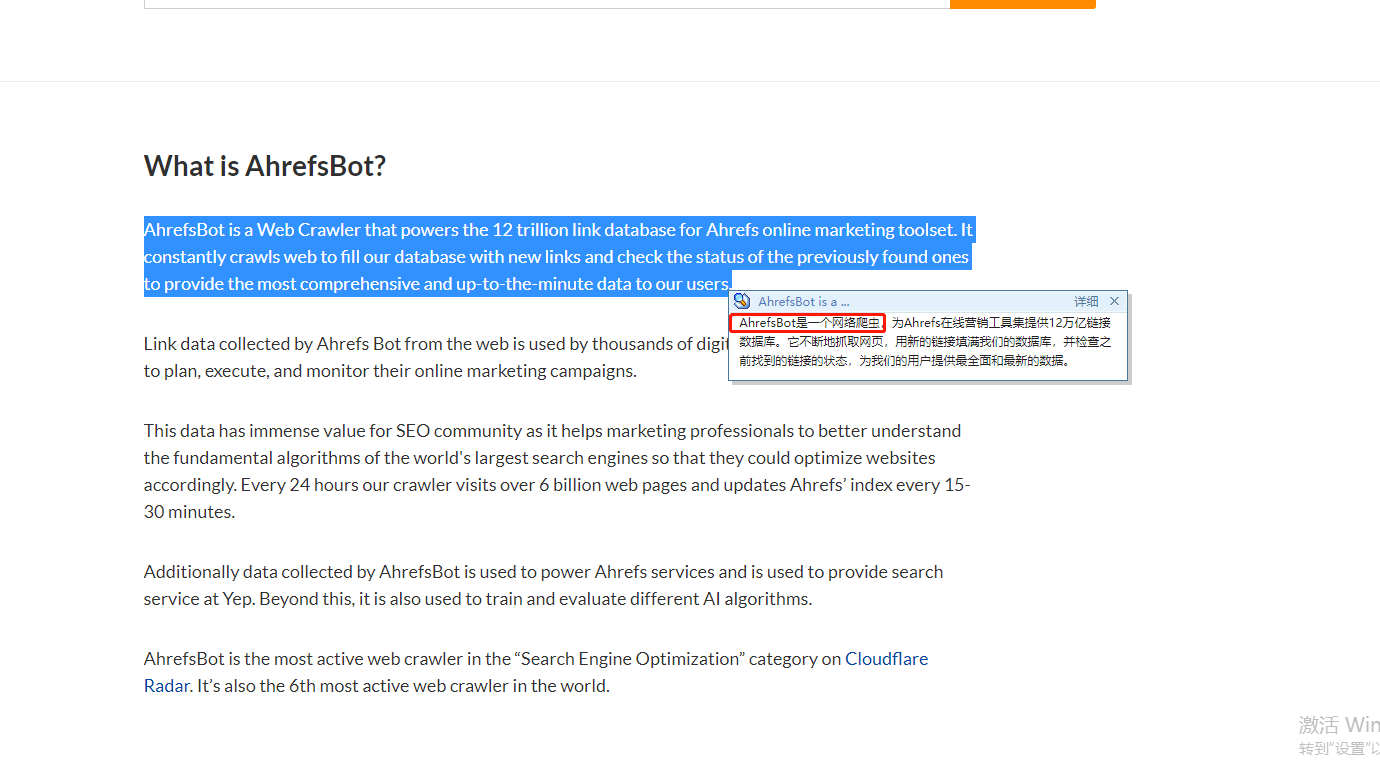
好家伙,差点没把我服务器送回家;
赶紧解决:nginx层面解决
发现虽然是爬虫,但是并没有伪装,每个请求里边都带了user-agent,而且都是一样的,那就好解决了,直接上代码:(我这里适用的是docker)
- docker-compose
version: '3'
services:
d_nginx:
container_name: c_nginx
env_file:
- ./env_files/nginx-web.env
image: nginx:1.20.1-alpine
ports:
- '80:80'
- '81:81'
- '443:443'
links:
- d_php
volumes:
- ./nginx/conf:/etc/nginx/conf.d
- ./nginx/nginx.conf:/etc/nginx/nginx.conf
- ./nginx/deny-agent.conf:/etc/nginx/agent-deny.conf
- ./nginx/certs:/etc/nginx/certs
- ./nginx/logs:/var/log/nginx/
- ./www:/var/www/html- 目录结构
nginx
-----nginx.conf
-----agent-deny.conf
-----conf
----------xxxx01_server.conf
----------xxxx02_server.conf- agent-deny.conf
if ($http_user_agent ~* (Scrapy|AhrefsBot)) {
return 404;
}
if ($http_user_agent ~ "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)|^$" ) {
return 403;
}- 然后在每个service里边
include这个agent-deny.conf
server {
include /etc/nginx/agent-deny.conf;
listen 80;
server_name localhost;
client_max_body_size 100M;
root /var/www/html/xxxxx/public;
index index.php;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#客户端允许上传文件大小
client_max_body_size 300M;
#客户端缓冲区大小,设置过小,nginx就不会在内存里边处理,将生成临时文件,增加IO
#默认情况下,该指令,32位系统设置一个8k缓冲区,64位系统设置一个16k缓冲区
#client_body_buffer_size 5M;
#发现设置改参数后,服务器内存跳动的幅度比较大,因为你不能控制客户端上传,决定不设置改参数
#此指令禁用NGINX缓冲区并将请求体存储在临时文件中。 文件包含纯文本数据。 该指令在NGINX配置的http,server和location区块使用
#可选值有:
#off:该值将禁用文件写入
#clean:请求body将被写入文件。 该文件将在处理请求后删除
#on: 请求正文将被写入文件。 处理请求后,将不会删除该文件
client_body_in_file_only clean;
#客户端请求超时时间
client_body_timeout 600s;
location /locales {
break;
}
location / {
#禁止get请求下载.htaccess文件
if ($request_uri = '/.htaccess') {
return 404;
}
#禁止get请求下载.gitignore文件
if ($request_uri = '/storage/.gitignore') {
return 404;
}
#禁止get下载web.config文件
if ($request_uri = '/web.config') {
return 404;
}
try_files $uri $uri/ /index.php?$query_string;
}
location /oauth/token {
#禁止get请求访问 /oauth/token
if ($request_method = 'GET') {
return 404;
}
try_files $uri $uri/ /index.php?$query_string;
}
location /other/de {
proxy_pass http://127.0.0.1/oauth/;
rewrite ^/other/de(.*)$ https://www.baidu.com permanent;
}
location ~ \.php$ {
try_files $uri /index.php =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass d_php:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_connect_timeout 300s;
fastcgi_send_timeout 300s;
fastcgi_read_timeout 300s;
include fastcgi_params;
#add_header 'Access-Control-Allow-Origin' '*';
#add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE';
#add_header 'Access-Control-Allow-Headers' 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization,token';
}
}这样每个请求里边都会拦截这个AhrefsBot了。
阿里云安全组拦截
分析日志还发现,其实请求的IP就那么几个段,那么为了多重保证(阿里云这个是见效最快,效果最好的,付费的就是不一样)
ip段:
54.36.0.0
51.222.0.0
195.154.0.0直接外网入方向: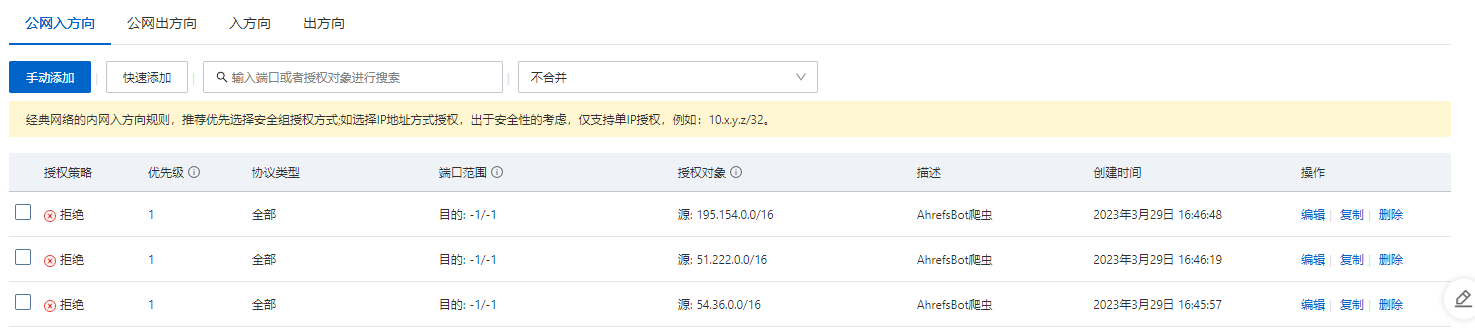
本作品采用《CC 协议》,转载必须注明作者和本文链接















 关于 LearnKu
关于 LearnKu




推荐文章: