
Go 标准库文档翻译:encoding/xml 包 - 加了点自己的列子
0 / 0 / 创建于 3年前 /
 wangchunbo 的个人博客
wangchunbo 的个人博客
本文是 Go 标准库中 encoding/xml 包文档的翻译, 原文地址为: golang.org/pkg/encoding/xml/
概述
xml 包实现了一个简单的 XML 1.0 语法分析器, 这个分析器能够理解 XML 命名空间。
常量
const (
// 一个普通的 XML 首部,可以用于封装的输出结果。
// 这个首部不会自动被添加到这个包产生的任何输出中,
// 提供这个首部只是为了方便。
Header = `<?xml version="1.0" encoding="UTF-8"?>` + "\n"
)变量
HTMLAutoClose 用于说明 HTML 元素是否会自动关闭标签:
var HTMLAutoClose = htmlAutoClose
HTMLEntity 是一个实体 map , 这个 map 记录了标准 HTML 实体字符与翻译之间的映射:
var HTMLEntity = htmlEntityEscape 函数
func Escape(w io.Writer, s []byte)Escape 的作用跟 EscapeText 类似, 但前者不会返回错误。 这个函数是为了兼容 Go 1.0 而提供的, 高于此版本的平台应该使用 EscapeText 来代替。
EscapeText 函数
func EscapeText(w io.Writer, s []byte) error把与纯文本数据 s 等价的转义后 XML 写入到 w 。
Marshal 函数
func Marshal(v interface{}) ([]byte, error)返回被编码为 XML 的 v 。
Marshal 在遇到一个数组或切片时, 会对其包含的每个元素进行封装; 在遇到指针时, 会对指针的值进行封装, 并忽略那些未 nil 的指针; 在遇到接口时, 会对接口包含的值进行封装, 并忽略那些值为 nil 的接口; 在遇到其他数据时, Marshal 将写入一个或多个包含这些数据的 XML 元素。
在进行封装时, XML 元素的名字由一系列规则决定, 这些规则的优先级从高到低依次为:
如果给定的数据是一个结构, 那么使用 XMLName 字段的标签作为元素名
使用类型为 Name 的 XMLName 字段的值为元素名
将用于获取数据的结构字段的标签用作元素名
将用于获取数据的结构字段的名字用作元素名
将被封装类型的名字用作元素名
结构中的每个已导出字段都会被封装为相应的元素并包含在 XML 里面, 但以下规则中提到的内容除外:
XMLName 字段,因为前面提到的原因,会被忽略
带有 “-” 标签的字段会被忽略
带有 “name,attr” 标签的字段会成为 XML 元素的属性, 其中属性的名字为这里给定的 name
带有 “,attr” 标签的字段会成为 XML 元素的属性, 其中属性的名字为字段的名字
带有 “,chardata” 标签的字段将会被封装为字符数据而不是 XML 元素。
带有 “,cdata” 标签的字段将会被封装为字符数据而不是 XML 元素, 并且这些数据还会被一个或多个 … 标签包围。
带有 “,innerxml” 标签的字段无需进行任何封装, 它会以原样进行输出。
带有 “,comment” 标签的字段无需进行任何封装, 它会直接输出为 XML 注释。 这个字段内部不能包含 “–” 字符串。
如果字段的标签中包含 “omitempty” 选项, 那么在字段的值为空时, 这个字段将被忽略。 空值指的是 false , 0 ,为 nil 的指针、接口值、数组、切片、map ,以及长度为 0 的字符串。
匿名结构字段会被看作是外层结构的其中一部分来处理。
字段可以使用类似 “a>b>c” 这样的标签来说明元素 c 被嵌套在父元素 a 和 b 里面。 如果有多个字段紧挨在一起, 并且它们都拥有相同的父元素, 那么这些字段对应的元素将被包裹在同一个 XML 元素里面。
Marshal 的执行示例请参考 MarshalIndent 的文档。
如果用户尝试让 Marshal 去封装一个频道、函数或者map, 那么 Marshal 将返回一个错误。
MarshalIndent 函数
func MarshalIndent(v interface{}, prefix, indent string) ([]byte, error)MarshalIndent 的作用跟 Marshal 类似, 但每个 XML 元素都会出现在一个新的缩进行里面, 这个缩进行以 prefix 为前缀, 后跟一个或多个 indent 组成的缩进字符串, indent 出现的数量由行的嵌套深度决定。
示例:
package main
import (
"encoding/xml"
"fmt"
"os"
)
func main() {
type Address struct {
City, State string
}
type Person struct {
XMLName xml.Name `xml:"person"`
Id int `xml:"id,attr"`
FirstName string `xml:"name>first"`
LastName string `xml:"name>last"`
Age int `xml:"age"`
Height float32 `xml:"height,omitempty"`
Married bool
Address
Comment string `xml:",comment"`
}
v := &Person{Id: 13, FirstName: "John", LastName: "Doe", Age: 42}
v.Comment = " Need more details. "
v.Address = Address{"Hanga Roa", "Easter Island"}
output, err := xml.MarshalIndent(v, " ", " ")
if err != nil {
fmt.Printf("error: %v\n", err)
}
os.Stdout.Write(output)
}示例执行结果:
<person id="13">
<name>
<first>John</first>
<last>Doe</last>
</name>
<age>42</age>
<Married>false</Married>
<City>Hanga Roa</City>
<State>Easter Island</State>
<!-- Need more details. -->
</person>波波的列子
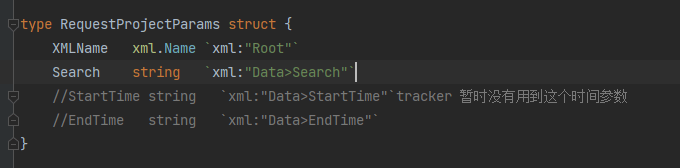
结果如下:
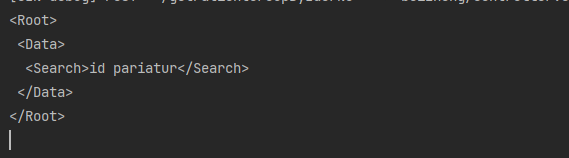
Unmarshal 函数
func Unmarshal(data []byte, v interface{}) errorUnmarshal 会对 XML 编码的数据进行语法分析, 并将结果储存到 v 指向的值里面, 其中 v 必须是一个任意的(arbitrary)结构、切片或者字符串。 格式良好但是无法放入到 v 里面的数据将被抛弃。
因为 Unmarshal 使用了反射包, 所以它只能对已导出的字段、也即是那些大写的字段进行处理。 Unmarshal 使用大小写敏感的比较操作来对比 XML 元素的名字和结构的字段名以及标签值。
Unmarshal 通过以下规则来将 XML 元素映射为结构。 在这些规则里面, “字段的标签”指的是结构字段的标签里面, 与键 ‘xml’ 相关联的值:
如果结构拥有一个 []byte 类型或者 string 类型的字段, 并且这个字段带有 “,innerxml” 标签, 那么 Unmarshal 将把嵌套在元素中的所有 XML 以未经处理的方式记录到字段里面。 后续的其他规则仍然适用(The rest of the rules still apply)。
如果结构拥有一个名字为 XMLName 并且类型为 Name 的字段, 那么 Unmarshal 将把元素的名字记录到字段里面。
如果 XMLName 字段拥有与之相关联的标签, 并且这个标签的格式为 “name” 或者 “namespace-URL name” , 那么 XML 元素必须拥有给定的名字以及可选的命名空间, 否则 Unmarshal 将返回一个错误。
如果 XML 元素拥有一个属性, 它的名字与结构字段的名字相同, 并且与该字段相关联的标签包含了 “,attr” 标签, 又或者结构字段里面出现了格式为 “name,attr” 的显示命名标签, 那么 Unmarshal 将把元素的属性值记录在该字段里面。
如果 XML 元素拥有的属性没有被上一条规则处理, 并且结构的某个字段包含了 “,any,attr” 标签, 那么 Unmarshal 将把属性的值记录到它遇到的第一个拥有该标签的字段里面。
如果 XML 元素包含字符数据, 那么这些数据将被累积到结构中第一个拥有标签 “,chardata” 的字段里面, 该字段的类型可以是 []byte 或者 string 。 如果结构里面没有包含这样的字段, 那么字符数据将被丢弃。
如果 XML 元素包含注释, 那么这些注释将被累积到结构中第一个拥有标签 “,comment” 的字段里面, 该字段的类型可以是 []byte 或者 string 。 如果结构里面没有包含这样的字段, 那么注释将被丢弃。
如果 XML 元素包含一个子元素, 它的名字能够与一个格式为 “a” 或者 “a>b>c” 的标签前缀相匹配, 那么 Unmarshal 将沿着 XML 的结构进行访问, 查找具有给定名字的元素, 并将最深处的元素映射至结构字段。 以 “>” 开始的标签与以字段名开始、后跟 “>” 的标签是相等的。
如果 XML 元素包含一个子元素, 这个子元素的名字与结构字段的 XMLName 标签相匹配, 并且结构字段不包含上面各条规则提到的显式命名标签, 那么 Unmarshal 将把子元素映射至这个结构字段。
如果 XML 元素包含一个子元素, 这个子元素不包含任何模式标签(比如 “,attr” , “,chardata” 等等), 那么 Unmarshal 将把这个子元素映射至与之具有相同名字的结构字段。
如果 XML 元素包含一个子元素, 但是这个子元素与之前列举的所有规则都不匹配, 这时如果结构里面包含一个标签为 “,any” 的字段, 那么 Unmarshal 将把这个子元素映射至那个结构字段。
匿名结构字段会被看作是外层结构的其中一部分来处理。
带有 “-” 标签的结构字段不会被解封。
Unmarshal 通过将元素的字符数据拼接并保存在字符串或者 []byte 里面, 以此来将 XML 元素映射至字符串或 []byte 。 被保存的 []byte 永远不会是 nil 。
Unmarshal 通过将属性的值保存在字符串或者切片里面, 以此来将属性值映射至字符串或 []byte 。
Unmarshal 可以将属性的名字以及值储存在 Attr 里面, 以此来将属性值映射至 Attr 。
Unmarshal 通过扩展切片的长度并将元素或属性映射至新创建的值里面, 以此来将 XML 元素或属性值映射到切片。
Unmarshal 通过将 bool 的值设置为使用字符串表示的布尔值, 以此来将 XML 元素或属性值映射至 bool 类型。
Unmarshal 会对字符串值进行解释, 并将解释所得的数字设置为字段的值, 以此来将 XML 元素或属性值映射至整数或浮点数字段。 这种映射不会进行溢出检查。
Unmarshal 通过记录元素的名字来将一个 XML 元素映射为 Name 。
Unmarshal 通过为指针设置为一个新分配的值, 并把元素映射至该值来将一个 XML 元素映射至指针。
示例
这个示例展示了如何将一个 XML 片段解封至一个具有多个预设字段的值里面。 需要注意的是, Phone 字段并未被修改, 并且 XML 元素也被忽略了。 此外, Groups 字段也是根据标签里面提供的元素路径来进行设置的。
package main
import (
"encoding/xml"
"fmt"
)
func main() {
type Email struct {
Where string `xml:"where,attr"`
Addr string
}
type Address struct {
City, State string
}
type Result struct {
XMLName xml.Name `xml:"Person"`
Name string `xml:"FullName"`
Phone string
Email []Email
Groups []string `xml:"Group>Value"`
Address
}
v := Result{Name: "none", Phone: "none"}
data := `
<Person>
<FullName>Grace R. Emlin</FullName>
<Company>Example Inc.</Company>
<Email where="home">
<Addr>gre@example.com</Addr>
</Email>
<Email where='work'>
<Addr>gre@work.com</Addr>
</Email>
<Group>
<Value>Friends</Value>
<Value>Squash</Value>
</Group>
<City>Hanga Roa</City>
<State>Easter Island</State>
</Person>
`
err := xml.Unmarshal([]byte(data), &v)
if err != nil {
fmt.Printf("error: %v", err)
return
}
fmt.Printf("XMLName: %#v\n", v.XMLName)
fmt.Printf("Name: %q\n", v.Name)
fmt.Printf("Phone: %q\n", v.Phone)
fmt.Printf("Email: %v\n", v.Email)
fmt.Printf("Groups: %v\n", v.Groups)
fmt.Printf("Address: %v\n", v.Address)
}输出:
me: xml.Name{Space:"", Local:"Person"}
Name: "Grace R. Emlin"
Phone: "none"
Email: [{home gre@example.com} {work gre@work.com}]
Groups: [Friends Squash]
Address: {Hanga Roa Easter Island}Attr 类型
Attr 用于表示 XML 元素中以 Name=Value 格式存在的属性:
type Attr struct {
Name Name
Value string
}CharData 类型
CharData 用于表示 XML 字符数据(原始文本), 而 XML 转义序列(sequence)将被 CharData 表示的字符代替。
type CharData []byte(CharData) Copy 方法
func (c CharData) Copy() CharData返回 CharData 的一个副本。
Comment 类型
Comment 用于表示格式为 <!--comment--> 的 XML 注释, 但注释的 <!-- 标记以及 --> 标记不会被包含在字节里面。
type Comment []byte(Comment) Copy 方法
func (c Comment) Copy() Comment返回 Comment 的一个副本。
Decoder 类型
Decoder 用于表示一个读取特定输入流的 XML 语法分析器, 分析器会假定该输入以 UTF-8 进行编码。
type Decoder struct {
// Strict 的默认值为 true ,用于强制执行 XML 规范中的要求。
// 如果值被设置为 false ,那么语法分析器将允许输入包含以下常见错误:
// * 如果一个元素缺少关闭标签,那么语法分析器将在有需要时自动生成结束标签,
// 以便维持 Token 返回的各个值的平衡。
// * 在属性值或是字符数据中,未知或格式不正确的字符实体(以 & 开头的序列)将被保留。
//
// 通过设置:
//
// d.Strict = false;
// d.AutoClose = HTMLAutoClose;
// d.Entity = HTMLEntity
//
// 可以创建一个能够处理典型 HTML 的语法分析器。
//
// 严格模式并不会强制执行 XML 命名空间 TR 的要求。
// 特别地,它将不会拒绝使用未定义前缀的命名空间标签。
// 这些标签将会被记录,而它们包含的未知前缀则会被看作是命名空间 URL 。
Strict bool
// 当 Strict 的值为 false 时,
// AutoClose 将包含一系列无论结束元素是否存在都需要在打开之后立即关闭的元素。
AutoClose []string
// Entity 可以用于将非标准实体名字映射为相应的字符串替代物。
// 无论实际的映射内容是什么,
// 语法分析器都会表现得就像以下这些标准映射出现在了 map 里面一样:
//
// "lt": "<",
// "gt": ">",
// "amp": "&",
// "apos": "'",
// "quot": `"`,
Entity map[string]string
// 字符集读取器,如果非空,那么将定义一个函数,
// 这个函数可以用于生成字符集转换读取器,用于将非 UTF-8 字符集转换为 UTF-8 。
// 如果 CharsetReader 为 nil 或者返回一个错误,那么分析过程将停止并返回一个错误。
// CharsetReader 的其中一个结果值必须为非 nil 。
CharsetReader func(charset string, input io.Reader) (io.Reader, error)
// 当整个 XML 流都被包裹在一个包含属性 xmlns="DefaultSpace" 的元素里面时,
// DefaultSpace 将用于设置未经修饰(unadorned)的标签的默认命名空间。
DefaultSpace string
// contains filtered or unexported fields
}
NewDecoder 函数
func NewDecoder(r io.Reader) *Decoder创建一个新的读取 r 的 XML 语法分析器。 如果 r 没有实现 io.ByteReader , 那么函数将使用它自有的缓冲机制。
(*Decoder) Decode 方法
func (d *Decoder) Decode(v interface{}) error执行与 Unmarshal 一样的解码工作, 唯一的不同在于这个方法会通过读取解码器流来查找起始元素。
(*Decoder) DecodeElement 方法
func (d *Decoder) DecodeElement(v interface{}, start *StartElement) errorDecodeElement 的作用跟 Unmarshal 类似, 但这个方法会接受一个指向起始 XML 元素的指针, 然后将被指向的内容解码至 v 。 当一个客户端想要自行读取某些原始 XML token , 但是却想要使用 Unmarshal 去处理某些元素时, 这个方法就可以派上用场。
(*Decoder) InputOffset 方法
func (d *Decoder) InputOffset() int64返回当前解码器位置在输入流中所处的字节偏移量。 这个偏移量会给出最近被返回的 token 的结尾, 以及下一个 token 的开头。
(*Decoder) Skip 方法
func (d *Decoder) Skip() error跳过被读取的任意多个 token , 直到遇见与已处理的开始元素匹配的结束元素为止。 这个方法在遇见开始元素时会自动进行递归, 所以它可以用于跳过嵌套结构。 当这个方法找到与起始元素相匹配的结束元素时, 它返回 nil ; 否则, 它将返回一个用于描述问题的错误。
(*Decoder) Token 方法
func (d *Decoder) Token() (Token, error)返回输入流的下一个 XML token 。 在到达流的尽头时, Token 将返回 nil 和 io.EOF 。
方法返回的 token 数据中的字节切片指向语法分析器的内部缓冲区, 这些字节切片会在下一个 Token() 方法调用之前一直有效。 通过调用 CopyToken 或者 token 的 Copy 方法可以取得这些字节的拷贝。
Token 会将注入
这样的自关闭元素扩展为单独的开始元素和结束元素, 并在后续的调用中返回它们。
Token 保证它返回的 StartElement token 和 EndElement token 都会正确地嵌套和匹配: 如果 Token 遇到了一个意料之外的结束元素, 又或者在所有预期的结束元素之前遇到了一个 EOF , 那么它将返回一个错误。
Token 实现了 www.w3.org/TR/REC-xml-names/ 中描述的 XML 命名空间。 当 Token 的命名空间已知时, Token 包含的每个 Name 结构的 Space 都会被设置为标志着它的命名空间的 URL 。 如果 Token 遇到了一个未被识别的命名空间前缀, 那么它会使用这个前缀来作为 Space 的值, 而不是报告一个错误。
(*Decoder) RawToken 方法
func (d *Decoder) RawToken() (Token, error)
RawToken 的作用跟 Token 的作用类似, 但 RawToken 不会验证起始元素和结束元素是否匹配, 也不会将命名空间前缀转换为它们对应的 URL 。
Directive 类型
一个 Directive 表示一个 <!text> 格式的 XML 命令, 用于包围命令的 <! 标识和 > 标识不会包含在 Directive 之内:
type Directive []byte(Directive) Copy 方法
func (d Directive) Copy() Directive创建 Directive 的一个副本。
Encoder 类型
Encoder 负责把 XML 数据写入至输出流里面:
type Encoder struct {
// contains filtered or unexported fields
}
示例:
package main
import (
"encoding/xml"
"fmt"
"os"
)
func main() {
type Address struct {
City, State string
}
type Person struct {
XMLName xml.Name `xml:"person"`
Id int `xml:"id,attr"`
FirstName string `xml:"name>first"`
LastName string `xml:"name>last"`
Age int `xml:"age"`
Height float32 `xml:"height,omitempty"`
Married bool
Address
Comment string `xml:",comment"`
}
v := &Person{Id: 13, FirstName: "John", LastName: "Doe", Age: 42}
v.Comment = " Need more details. "
v.Address = Address{"Hanga Roa", "Easter Island"}
enc := xml.NewEncoder(os.Stdout)
enc.Indent(" ", " ")
if err := enc.Encode(v); err != nil {
fmt.Printf("error: %v\n", err)
}
}示例执行结果:
<person id="13">
<name>
<first>John</first>
<last>Doe</last>
</name>
<age>42</age>
<Married>false</Married>
<City>Hanga Roa</City>
<State>Easter Island</State>
<!-- Need more details. -->
</person>NewEncoder 函数
func NewEncoder(w io.Writer) *Encoder返回一个能够对 w 进行写入的编码器。
(*Encoder) Encode 方法
func (enc *Encoder) Encode(v interface{}) error将 XML 编码的 v 写入到流里面。
请查阅 Marshal 的文档来了解 Go 是如何将 Go 值转换为 XML 的。
Encode 在返回之前会先调用 Flush 。
(*Encoder) EncodeElement 方法
func (enc *Encoder) EncodeElement(v interface{}, start StartElement) error将 XML 编码的 v 写入到流里面, 并使用 start 作为被编码数据的最外围标签。
请查阅 Marshal 的文档来了解 Go 是如何将 Go 值转换为 XML 的。
EncodeElement 在返回之前会先调用 Flush 。
(*Encoder) EncodeToken 方法
func (enc *Encoder) EncodeToken(t Token) error将给定的 XML token 写入到流里面。 这个方法在 StartElement token 和 EncodeToken token 不匹配时回返回一个错误。
因为 EncodeToken 通常会在更大的 Encode 操作或者 EncodeElement 操作中出现, 又或者在自定义 Marshal 的 MarshalXML 中调用, 而这些操作通常会在完成时调用 Flush , 所以 EncodeToken 不会调用 Flush 。 如果一个调用者创建了一个 Encoder , 并在之后直接调用 EncodeToken , 但是却没有使用 Encode 或者 EncodeElement , 那么这个调用者就需要在操作完成时调用 Flush , 以便确保 XML 被写入到底层的写入器里面。
只有在第一个 token 存在于流里面时, EncodeToken 才会允许对一个 Target 设置为 “xml” 的 Proclnst 进行写入。
(*Encoder) Flush 方法
func (enc *Encoder) Flush() error将所有被缓冲的 XML 冲刷到底层的写入器里面。 请查看 EncodeToken 的文档以便了解更多细节。
(*Encoder) Indent 方法
func (enc *Encoder) Indent(prefix, indent string)对生成 XML 的编码器进行设置, 使得编码器产生的每个元素都会以一个 prefix 开头的新缩进行为开始, 而跟在 prefix 后面的则是一个或多个 indent 的副本, indent 的具体数量由元素的嵌套深度决定。
EndElement 类型
一个 EndElement 表示一个 XML 结束元素。
type EndElement struct {
Name Name
}Marshaler 类型
Marshaler 接口由那些需要将自己封装成合法的 XML 元素的对象实现。
MarshalXML 会将它的接收者编码成一个或多个 XML 元素。 在通常情况下, 数组或切片会被编码成一个由多个元素组成的序列, 序列中的每个元素与数组/切片中的一个值对应。
使用 start 作为元素标签并不是必须的, 但这样做可以让 Unmarshal 将 XML 元素匹配至正确的结构字段。
一种常用的实现策略是根据自己想要生成的 XML 构建一个带有布局的独立值, 然后使用 e.EncodeElement 去编码它。 另一种常用的策略是以每次一个 token 的方式, 通过重复调用 e.EncodeToken 来生成 XML 输出。 被编码的 token 序列必须由零个或任意多个合法的 XML 元素组成。
type Marshaler interface {
MarshalXML(e *Encoder, start StartElement) error
}MarshalerAttr 类型
MarshalerAttr 接口由那些需要将自己封装成合法的 XML 属性的对象实现。
MarshalXMLAttr 会返回一个 XML 属性, 并且这个属性将会带有接收者被编码之后的值。
如果 MarshalXMLAttr 返回空白的属性 Attr{} , 那么这个属性将不产生任何输出。 MarshalXMLAttr 只能用于字段标签中带有 “attr” 选项的结构字段。
type MarshalerAttr interface {
MarshalXMLAttr(name Name) (Attr, error)
}Name 类型
一个 Name 可以表示一个使用命名空间标识符(Space)进行注解的 XML 名字(Local)。 在 Decoder.Token 返回的 token 但中, Space 标识符将不会使用被分析文档中的简短前缀, 而是以标准 URL 的方式给出。
type Name struct {
Space, Local string
}ProcInst 类型
一个 ProcInst 可以表示一个格式为 <?目标指令?> 的 XML 处理指令。
type ProcInst struct {
Target string
Inst []byte
}(ProcInst) Copy 方法
func (p ProcInst) Copy() ProcInstStartElement 类型
一个 StartElement 可以表示一个 XML 起始元素。
type StartElement struct {
Name Name
Attr []Attr
}(StartElement) Copy 方法
func (e StartElement) Copy() StartElement
(StartElement) End 方法
func (e StartElement) End() EndElement
返回相应的 XML 结束元素。
SyntaxError 类型
一个 SyntaxError 表示一个在 XML 输入流中发现的语法错误。
type SyntaxError struct {
Msg string
Line int
}(*SyntaxError) Error 方法
func (e *SyntaxError) Error() stringTagPathError 类型
一个 TagPathError 用于表示一个在解封过程中因为字段标签使用了冲突的路径而引起的错误。
type TagPathError struct {
Struct reflect.Type
Field1, Tag1 string
Field2, Tag2 string
}(*TagPathError) Error 方法
func (e *TagPathError) Error() stringToken 类型
一个 Token 是一个持有以下任一 token 类型的接口: StartElement , EndElement , CharData , Comment , ProcInst , Directive 。
type Token interface{}CopyToken 函数
func CopyToken(t Token) Token返回 Token 的一个副本。
UnmarshalError 类型
一个 UnmarshalError 表示一个在解封过程中出现的错误。
type UnmarshalError string(UnmarshalError) Error 方法
func (e UnmarshalError) Error() stringUnmarshaler 类型
实现了 Unmarshaler 接口的对象可以对记录了自身描述的 XML 元素进行解封。
UnmarshalXML 可以对一个带有给定起始元素的 XML 元素进行解码。 如果 UnmarshalXML 返回一个错误, 那么针对 Unmarshal 的外部调用将停止并返回该错误。 UnmarshalXML 必须只处理一个 XML 元素。
一种常用的实现策略是使用 d.DecodeElement , 解封出一个带有与预想中的 XML 相匹配布局的独立值, 然后将这个值的数据复制到接收者里面。 另一种常用的实现策略是以每次一个 token 的方式, 使用 d.Token 去处理 XML 对象。 UnmarshalXML 有可能无法使用 d.RawToken 。
type Unmarshaler interface {
UnmarshalXML(d *Decoder, start StartElement) error
}UnmarshalerAttr 类型
实现了 UnmarshalerAttr 接口的对象可以对记录了自身描述的 XML 属性进行解封。
UnmarshalXMLAttr 可以对一个 XML 属性进行解码。 如果 UnmarshalXMLAttr 返回一个错误, 那么针对 UnmarshalXMLAttr 的外部调用将停止并返回该错误。 UnmarshalXMLAttr 只能用于字段标签中带有 “attr” 选项的结构字段。
type UnmarshalerAttr interface {
UnmarshalXMLAttr(attr Attr) error
}UnsupportedTypeError 类型
当 Marshal 遇到一种它无法转换为 XML 的类型时, 就会返回一个 MarshalXMLError 。
type UnsupportedTypeError struct {
Type reflect.Type
}(*UnsupportedTypeError) Error 方法
func (e *UnsupportedTypeError) Error() stringLicense¶
Portions of this page are reproduced from work created and shared by Google and used according to terms described in the Creative Commons 3.0 Attribution License .
本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu



