
Laravel 实用小技巧 —— 如何快速更新 20 万条 MySQL 数据?
122 / 26 / 创建于 3年前 /
 快乐的皮拉夫 的个人博客
快乐的皮拉夫 的个人博客
背景
在我们日常开发中,「洗数据」这个词儿可能听的比较多(至少在我们公司是这样的)。作为一个互联网公司呆上几年的老兵,都不好意思说自己没洗过数据。那么哪些情况下需要洗数据呢?
程序写的有问题,导致出现「脏数据」了,要洗洗吧?
因为某种原因,造成了「数据丢失」,要洗洗吧?
数据表新增了几个字段,需要根据条件「初始化」数据,还要洗洗吧?
今天,我们就来探讨下最后这个场景:关于「初始化」字段洗数据的问题。
故事场景一般是这样的:
假设我们给用户表
users新增了一个积分字段score,我们有一个额外的存储score的csv文本文件,文件有大约 20 万行左右的数据,文件行格式如下:手机号,积分。已知users表中存在手机号字段phone,且定义了唯一索引,表中有 100 万左右的数据。对于文件中的手机号,如果users表中找不到记录的话,需要新增一条记录。
现在就让我们一起来看看这种问题该怎么处理吧~
处理思路
方案一
其实,这类问题对于一般的开发人员来说难度都不大。基本流程如下图所示:
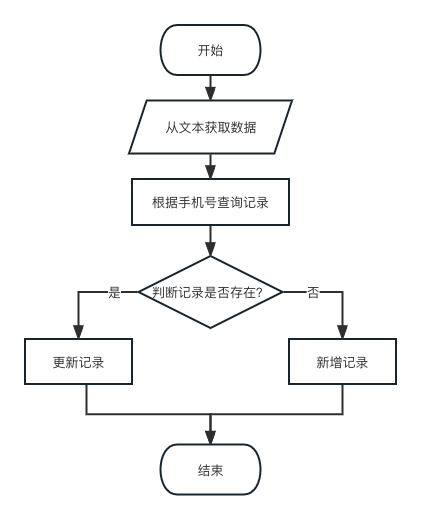
用代码实现大致是以下的逻辑(以 Laravel 为例):
...
//========== 使用SplFileObject类处理文件 ==========
$originFile = storage_path('tmp/scores.csv');
$splFileObj = new \SplFileObject($originFile, 'r+');
while (!$splFileObj->eof()) {
//========== 读取行并移动文件指针 ==========
$lineString = trim($splFileObj->current());
$splFileObj->next();
//========== 文件行格式判断 ==========
if (!$lineString) {
continue;
}
//========== 解析文件行 ==========
$line = explode(',', $lineString);
if (count($line) != 2) {
Log::error("Invalid line format for original score file.//{$splFileObj->key()}//{$lineString}");
continue;
}
//========== 初始化行内参数 ==========
list($phone, $score) = $line;
//========== 新增或更新数据 ==========
$user = User::wherePhone($phone)->first();
if(!$user){
$user = new User();
$user->phone = $phone;
}
$user->score = $score;
$user->save();
}
...代码看上去没什么问题。如果我们的数据量不大的话,这样操作是无可厚非的。
But…我们的文件有 20 万行。。。
如果你真的运行过这样的代码的话,你会发现:这样的更新会「转圈圈」很久很久。
是什么原因造成的呢?让我们来浅分析一下:
- 首先,我们只有文件的读操作,没有写操作,所以「按行读取」的影响并不会很大
- 读取完行记录以后,我们会对数据库记录进行查询,这一步也不可少。但是这里每一次都要查询一行记录,网络开销会比较大,这里我们可以改成批量查询的逻辑
- 对于新增操作,我们可以作批量新增,这样可以减少数据库的 IO 操作
- 对于更新操作,我们不好做批量更新,但是可以通过主键进行更新(实际 Laravel 在执行模型更新的时候正是按主键进行更新的,这里不需要作调整)
于是,我们针对以上的问题优化成方案二。
方案二
在此方案中,我们针对方案一中发现的问题进行了调整,改进后代码逻辑如下:
...
//========== 使用SplFileObject类处理文件 ==========
$originFile = storage_path('tmp/scores.csv');
$splFileObj = new \SplFileObject($originFile, 'r+');
//========== 定义一个迭代数组 ==========
$iterators = [];
while (!$splFileObj->eof()) {
//========== 读取行并移动文件指针 ==========
$lineString = trim($splFileObj->current());
$splFileObj->next();
//========== 文件行格式判断 ==========
if (!$lineString) {
continue;
}
//========== 解析文件行 ==========
$line = explode(',', $lineString);
if (count($line) != 2) {
Log::error("Invalid line format for original score file.//{$splFileObj->key()}//{$lineString}");
continue;
}
//========== 初始化行内参数 ==========
list($phone, $score) = $line;
$iterators[$phone] = $score;
if(count($iterators) != 100){
continue;
}
//========== 批量查询数据 ==========
$users = User::whereIn('phone', array_keys($iterators))->get();
//========== 更新操作 ==========
foreach ($users as $user) {
$user->score = $iterators[$user->phone];
$user->save();
unset($iterators[$user->phone]);
}
//========== 批量新增操作 ==========
foreach ($iterators as $phone => $score) {
$batchInsertData[] = [
'phone' => $phone,
'score' => $score,
];
}
if(!empty($batchInsertData)){
User::insert($batchInsertData);
}
//========== 重置迭代数组和批量新增数组 ==========
$iterators = $batchInsertData = [];
}
...这里我们引入了批量查询和批量新增的逻辑。通过批处理逻辑,我们有效地控制了数据库的 IO 操作次数,从而降低了代码的整体执行时间。
But…这样就算是「最优方案」了吗?
其实,在条件允许的情况下,我们还可以稍稍改进一下(其实笔者大多数处理这种数量级的更新时都是这么做的)。
一起来看看方案三又做出了哪些改进吧~
方案三
其实,在方案二中,我们该做的优化都已经尽量做了。可能有的同学会建议将批处理的上限再进行提高,其实不然,当我们把批处理数量调高以后,虽然网络请求的次数减少了,但是每次网络请求传输的数据量却变大了,甚至会超出最大网络请求包体的限制。所以,批处理的数量并非越大越好。
其实,在我们这个案例中,大部分的时间消耗在了 MySQL 的网络开销上。如果想缩减这一部分时间的话,一方面需要减少网络请求的次数,另一方面需要提高单次请求的响应时间。
而我们在程序中进行处理的话,除了真实的数据库层面的请求和响应时间,程序本身对请求和响应的处理也会占用一些时间。单次请求中可能还不明显,但是当处理的数据量越来越大时,这种操作的时间也需要引起我们的重视。
说到这里了,其实意图已经很明显了:那干脆直接交给 MySQL 客户端去执行不就 OK 了么?
这个阔以有。
我们直接在方案二的基础上作如下调整:
...
//========== 批量查询数据 ==========
$users = User::whereIn('phone', array_keys($iterators))->get();
//========== 更新操作 ==========
foreach ($users as $user) {
// 生成更新 SQL
...
unset($iterators[$user->phone]);
}
//========== 批量新增操作 ==========
foreach ($iterators as $phone => $score) {
$batchInsertData[] = [
'phone' => $phone,
'score' => $score,
];
}
if(!empty($batchInsertData)){
// 生成批量插入 SQL
...
}
...这样,通过程序生成一个完整的 SQL 文件:update.sql,然后我们通过 MySQL 客户端工具执行 从文件运行 SQL 的操作即可。
实际上,这里还有一个小问题,那就是当我们 SQL 的文件过大时,一些可视化的 MySQL 客户端可能会触发
超出文件大小的限制,这时候需要我们对文件进行分割。实际上,笔者更倾向于在命令行下执行 SQL 的操作,这样的操作基于文件流读取数据,不会出现超时或者文件大小的限制。操作命令如下:
mysql -h {host} -u {user} -p < update.sql总结
在我们今天的小案例中,我们讨论了一种失传已久的关于「洗数据」的小妙招。
虽然没有用到什么高深的技术,但是整个思考的过程还是挺有意思的。相信对于那些经常需要在各种数据大坑中洗洗洗的小伙伴有所帮助(其实这也是我在处理这些繁琐工作时总结出来的小经验)。
感谢大家的持续关注~
本作品采用《CC 协议》,转载必须注明作者和本文链接


































 关于 LearnKu
关于 LearnKu




推荐文章: