
Laravel 实用小技巧——日志告警功能应该怎么做?
82 / 4 / 创建于 2年前 /
 快乐的皮拉夫 的个人博客
快乐的皮拉夫 的个人博客
简介
作为开发同学,我们都知道,如果线上环境出了问题的话,肯定要第一时间进行通知告警。告警的方式有很多,常见的告警方式包括:钉钉,企业微信,邮件或者短信等。
通常情况下,告警方式和问题的紧急程度息息相关。紧急程度越高的问题,往往选择触达效果更明显的方式:比如短信,而一些紧急程度不高的问题,我们可以选择其他一些普通的告警方式:比如钉钉或者企业微信。
这样选择是在成本和触达效果之间权衡的结果。
那么应该如何设计一个相对合理的日志告警功能呢?本篇文章我们就来一起探讨一下这个话题。
实现方案
这里我们以 Laravel 为例展开讨论,告警方式我们选择短信和钉钉两种。
小试牛刀
我们先来看一个最简单的方案。
首先,我们来定义一个通知服务类,代码如下:
class NotifyService
{
/**
* 短信通知
*
* @param string $message 消息
*/
public static function smsNotify(string $message)
{
//短信通知逻辑
}
/**
* 钉钉通知
*
* @param string $message 消息
*/
public static function dingTalkNotify(string $message)
{
//钉钉通知逻辑
}
}当我们需要使用特定的告警逻辑时,我们就可以调用相应的告警方法了,如下:
..
$message = '这是一条错误告警信息';
Log::error($message);
NotifyService::smsNotify($message); //短信通知
NotifyService::dingTalkNotify($message); //钉钉通知
...问题是,每次我们需要使用特定的告警逻辑时,都需要主动调用通知的逻辑,比较繁琐。能不能用更「优雅」的方式调用呢?
优雅一点
我们可以考虑把 Log 写日志方法包装一层,在方法内部,通过不同的日志等级关联对应的告警方法。代码如下:
首先我们在 common.php (自定义配置)文件中增加告警相关的配置,如下:
config/common.php
...
//告警配置
'alert' => [
//短信告警配置
'sms' => [
'is_open' => env('SMS_ALERT_IS_OPEN', true), //开关
'log_level' => ['emergency', 'alert', 'critical'] //日志级别
],
//钉钉告警配置
'ding_talk' => [
'is_open' => env('DING_TALK_ALERT_IS_OPEN', true), //开关
'log_level' => ['emergency', 'alert', 'critical', 'error', 'warning'] //日志级别
]
],
...然后我们在 NotifyService.php 中封装一个公共的日志方法,逻辑如下:
app/Services/Common/NotifyService.php
...
/**
* 自定义日志方法
*
* @param string $message 消息
* @param string $level 日志等级
* @param array $context 上下文
*/
public static function logger(string $message, string $level = 'debug', array $context = [])
{
Log::log($level, $message, $context);
//短信通知逻辑
if(Config::get('common.alert.sms.is_open') == true && in_array($level, (array)Config::get('common.alert.sms.log_level'))){
self::smsNotify($message);
}
//钉钉通知逻辑
if(Config::get('common.alert.ding_talk.is_open') == true && in_array($level, (array)Config::get('common.alert.ding_talk.log_level'))){
self::dingTalkNotify($message);
}
}
...这样,当我们按照正确的日志等级调用自定义的 logger 方法时,如果配置了相关的通知逻辑,就会自动触发通知:
NotifyService::logger('这是一条错误告警信息', 'emergency');根据配置信息,这条错误会同时触发「钉钉」和「短信」两种告警逻辑。而如果传递的错误级别是 error 的话,则只会进行「钉钉」通知。
这样设计,即控制了通知的成本,又能保证触达的效果,看上去是一种不错的实现方案。
但是我们觉得这样实现还是不够「优雅」,因为每次我们每次还要主动调用一下 logger 方法,而且还要按照固定的顺序传参,感觉还是不够「灵活」。并且,日志方法和告警逻辑放在一个方法里,总显得有些「不伦不类」。
那还有没有改进的空间呢?
再优雅一点
实际上,我们可以换个思路。上述方案我们都是通过 Log 方式来记录日志,告警逻辑也是伴随着 Log 进行判断处理。其实这里我们可以从 Log 的圈子里跳出来,通过 异常 逻辑来处理。
比如,我们可以设计两个异常类:运行异常类 RuntimeException 和致命异常类 FatalException。代码结构如下:
app/Exceptions/RuntimeException.php
class RuntimeException extends Exception
{
}app/Exceptions/FatalException.php
class FatalException extends Exception
{
}针对告警方式,我们可以定义两个接口:短信告警接口 ShouldSmsNotify 和 ShouldDingTalkNotify,代码结构如下:
app/Exceptions/ShouldSmsNotify.php
interface ShouldSmsNotify
{
}app/Exceptions/ShouldDingTalkNotify.php
interface ShouldDingTalkNotify
{
}在接口中,我们可以定义需要实现的方法标准。
当我们需要对异常处理进行相应的告警通知时,我们可以让异常类实现对应的通知接口,如下:
class FatalException extends Exception implements ShouldDingTalkNotify, ShouldSmsNotify
{
}接下来,我们就可以在异常处理类 app/Exceptions/Handler.php 中的 register 或者 render 方法中进行统一的异常处理了,如下:
app/Exceptions/Handler.php
...
public function register()
{
$this->reportable(function (Throwable $e) {
//短信告警
if($e instanceof ShouldSmsNotify){
//短信告警逻辑
echo '短信告警:' . $e->getMessage() . PHP_EOL;
}
//钉钉告警
if($e instanceof ShouldDingTalkNotify){
//钉钉告警逻辑
echo '钉钉告警:' . $e->getMessage() . PHP_EOL;
}
});
}
...当然,我们还可以重写异常报告的方式,直接将异常输出到日志中,而不是直接在标准输出中返回:
public function report(Throwable $e)
{
//记录错误日志
Log::error('系统开小差了~', [
'code' => $e->getCode(),
'message' => $e->getMessage(),
'file' => $e->getFile(),
'line' => $e->getLine()
]);
}这样,当我们需要告警时,只需要在代码中进行抛出异常就可以了:
throw new FatalException('这是一条致命的错误信息');这样,会根据异常类是否实现了相应的告警接口而选择是否进行告警处理,是不是看上去比之前更优雅了一些呢?
其实,讲到这里,我们一直在考虑怎么让程序更「优雅」,却并没有关心「性能」的问题。我们都知道,无论是短信通知还是钉钉通知,一般都是通过调用第三方的 Http 服务实现的。
既然是 Http 服务,必然会涉及到「请求」和「响应」的问题。一般情况下,我们这样设计不会有什么问题,但是假设现在我们的队列中处理的任务出现了异常,或者是高并发的情况下触发了大量需要短信或者钉钉告警的异常,这时候会出现什么情况呢?
这会造成短时间内有大量的 Http 请求,网络请求带宽也会瞬间飙升。随之而来的就是服务器负载飙升,程序响应速度极速下降。
我们需要清楚的是,告警本是一项「锦上添花」的工作,但我们不应该为了追求「添花」而使正常业务受到影响,特别是造成服务不可用这种致命的影响。
那我们应该怎么办呢?
性能提一提
我们来分析一下,造成主业务受影响主要有两方面的原因:一是外部告警逻辑和业务逻辑耦合在一起,二是告警服务和主业务共用服务器资源。当告警业务请求量激增或者响应时间过长时,都会直接或者间接影响到主业务。
为了使告警服务和主业务实现解耦,有的小伙伴可能会考虑使用队列的方案。
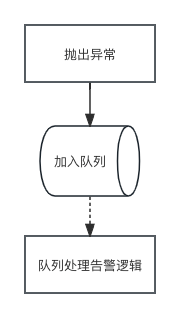
这样确实会实现告警业务和主业务的解耦,但是笔者并不建议这么去做,理由有以下几点:
- 虽然两条业务线逻辑上实现了解耦,但是在抛出异常的时候还会有加入队列的操作。一旦队列服务出现问题或者出现阻塞情况,也会造成主业务进程的阻塞
- 入队操作也是网络请求,当数据量大的时候对程序的性能也有一定的影响
归根结底还是那句话,告警虽然「酷炫」,但不能影响到主业务。
那应该怎么优化呢?
UDP,不错的选择
其实使用 UDP 服务作为错误日志告警的「上报分发器」也是一个不错的选择。
具体思路如下:
- 创建一个 UDP 日志上报的服务
- 收集错误日志并分发到错误日志处理队列
- 队列进程进行异步告警处理
为什么说这里使用 UDP 服务效果更佳呢?因为相比于基于 TCP 协议的队列服务,UDP 协议不需要建立连接,且不需要关注数据的确认和重传,传输效率更高。
需要清楚的是,UDP 协议传输的高效性是靠牺牲了一定的可靠性换来的。所以像日志告警这种对实效性要求较高,但是可靠性可以适当折扣的服务来说,UDP 服务还是比较合适的。
尽管 UDP 协议更快,但是它的主要作用还是进行数据传输。在接收到数据以后,我们最好还是将消息分发到对应的队列进行处理,这样可以最大程度地保证消息传输的流畅性。
可能有的小伙伴会有疑问,既然使用 UDP 接收到消息以后还是会做入队处理,那不相当于还是没有解决掉入队操作的解耦问题么?这样做会不会多此一举呢?
其实,像 Swoole,Workerman 这种提供了 UDP 服务的框架来说,已经支持到非阻塞的 UDP 消息发送了。所以,这个问题并不算是个问题。
讲到这里,实际上我们可以换个思路考虑「错误上报」的问题了。
之前我们的思路都是在抛出异常的同时进行告警逻辑的处理。其实在 Laravel 框架中,日志底层用的是 Monolog 日志服务。Monolog 本身是支持「通道 channel」的概念的,即我们的日志输出到哪里。
通常情况下,我们使用最多的一般都是 single 或者 daily 这些通道。这些通道都是以文本日志的形式进行输出。实际上,我们可以自定义通道,比如我们可以将通道指向 UDP 上报服务,这样,当我们配置了 UDP 上报通道的时候,错误日志就会同时发送到我们的 UDP 服务了,是不是更方便了呢?
示例代码如下:
config/logging.php
'channels' => [
...
'stack' => [
'driver' => 'stack',
//配置多通道
'channels' => ['single', 'udp-report'],
'ignore_exceptions' => false,
],
'single' => [
'driver' => 'single',
'path' => storage_path('logs/laravel.log'),
'level' => env('LOG_LEVEL', 'debug'),
],
//自定义 UDP 上报通道
'udp-report' => [
//使用内置的 monolog 驱动
'driver' => 'monolog',
//仅上报 error 级别及以上的错误
'level' => 'error',
//使用 Monolog 内置的 UDP 上报处理器
'handler' => Monolog\Handler\SyslogUdpHandler::class,
//指定 UDP 服务地址
'with' => [
'host' => '127.0.0.1',
'port' => '9292',
],
],
...
]而 UDP 服务我们可以通过 Swoole 或者 Workerman 等框架进行实现。以 Workerman 为例实现代码如下:
...
$udp_worker = new Worker('udp://0.0.0.0:9292');
$udp_worker->onMessage = function($connection, $data){
//推送消息至队列
};
Worker::runAll();
...这样,我们就可以在通道中配置需要特殊告警的日志级别,然后在 UDP 服务和队列服务中处理告警的逻辑了,是不是更「优雅」了呢?
可能有的小伙伴对 UDP 服务还是心存芥蒂:尽管 UDP 更快,但是如果 UDP 服务也挂了呢?是不是也会抛出致命错误或者造成服务阻塞呢?
的确如此。
如果 UDP 服务真的挂了的话,确实有可能会抛出致命错误。但是我们可以通过异常捕获的方式来进行处理,这样 UDP 服务异常的时候仅影响错误告警功能,而并不影响正常业务的运行。
除此之外,还有其他好的方案吗?
Logstash 日志收集处理
我们上面介绍的方案都是基于「主动上报」机制的。只要是主动上报,就免不了会有一个上报的时间点,换言之,这种方式无法做到完全解耦。
其实除了「主动上报」,「被动采集」也是一种不错的选择,而且这种方式实现了完全解耦。
如果你接触过 ELK 的话,相信你对我说的就不会感到陌生了。没错,ELK 里的 L 就是做这个工作的,也就是 Logstash。
简单介绍一下,Logstash 是由 Elastic 公司推出的一款开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送指定的存储库中。
说白了,其核心功能就是:采集数据 + 加工处理 + 输出数据。
尽管 Logstash 本身也支持从日志采集数据,但是我们一般选择 Filebeat 作为日志采集的 Agent 。因为 Filebeat 更加小巧轻便,占资源少,且没有太多的依赖,更适合作为分布式部署的 Agent 。什么又是 Filebeat 呢?
Filebeat 是 Elastic 公司为解决 Logstash「太重」的问题推出的一款轻量级日志采集器,在处理数量众多的服务器、虚拟机和容器生成的日志时可使用 Logstash + Filebeat 的日志采集方式。
常见的 ELK 日志分析系统架构如下:
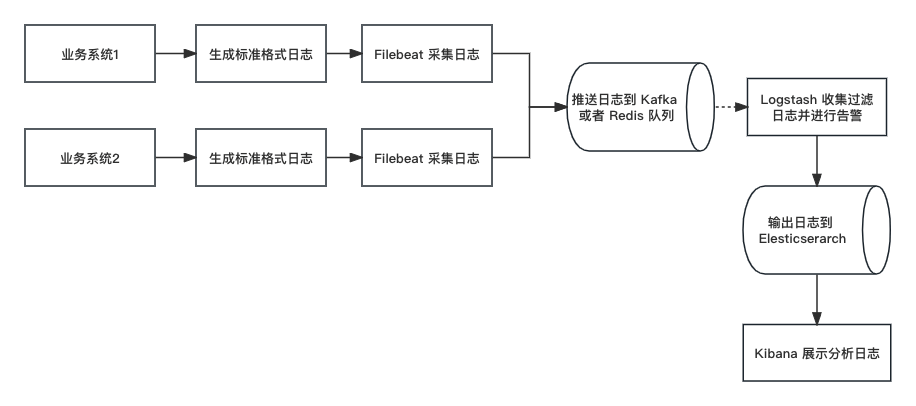
我们在 Filebeat 和 Logstash 之间一般会增加一层队列处理,一方面是作为数据的暂存缓冲,另一方面,像 Kafka 队列还可以开启多个 channel 进行消费,可以提高消息的重复利用率。
我们这里提到的日志告警功能实际上通过 Filebeat + Kafka或者Redis队列 + Logstash 实现就可以了。其思路就是:
- Filebeat 负责收集日志,并推送至队列
- Logstash 负责从队列中取数据,并进行加工处理,根据条件推送至相应的告警服务
限于篇幅,这里我们就不对该方案具体的实现细节进行讨论了。后续我们会专门通过一篇文章来介绍这个方案的实现细节,大家记得持续关注下哦~
总结
本篇文章,我们讨论了一个日常开发中常见的一个错误日志告警的问题。
通过几种不同的实现方案,我们了解到了不同方案实现的优缺点。当然这里介绍的仅仅是笔者接触到的一些方案,至于其他更好的实现方案,也欢迎小伙伴们在评论区留言讨论。
总之,归根结底,做此类的功能,不管使用哪种方案实现,我们都必须清楚一点:「分清主次,分清主次,分清主次。保证主线业务稳定才是最重要的。」
最后,再次感谢大家的持续关注~
本作品采用《CC 协议》,转载必须注明作者和本文链接

























 关于 LearnKu
关于 LearnKu




推荐文章: