
前、后端通用的可视化逻辑编排
6 / 3 / 创建于 3年前 /
 idlewater 的个人博客
idlewater 的个人博客
前一段时间写过一篇文章《实战,一个高扩展、可视化低代码前端,详实、完整》,得到了很多朋友的关注。
其中的逻辑编排部分过于简略,不少朋友希望能写一些关于逻辑编排的内容,本文就详细讲述一下逻辑编排的实现原理。
逻辑编排的目的,是用最少甚至不用代码来实现软件的业务逻辑,包括前端业务逻辑跟后端业务逻辑。本文前端代码基于typescript、react技术栈,后端基于golang。
涵盖内容:数据流驱动的逻辑编排原理,业务编排编辑器的实现,页面控件联动,前端业务逻辑与UI层的分离,子编排的复用、自定义循环等嵌入式子编排的处理、事务处理等
运行快照: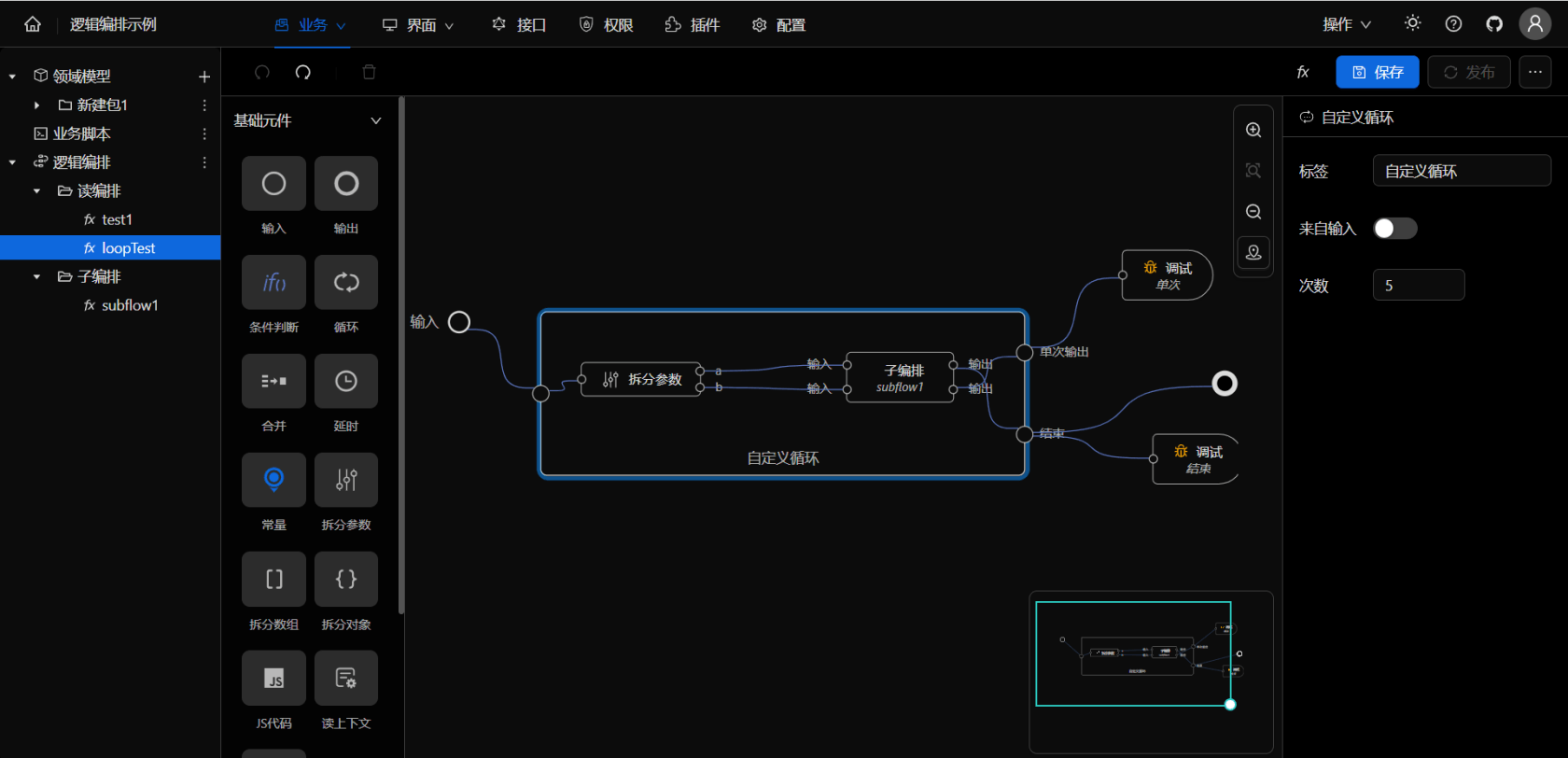
前端项目地址:github.com/codebdy/rxdrag
前端演示地址:rxdrag.vercel.app/
后端演示尚未提供,代码地址:github.com/codebdy/minions-go
注:为了便于理解,本文使用的代码做了简化处理,会跟实际代码有些细节上的出入。
整体架构
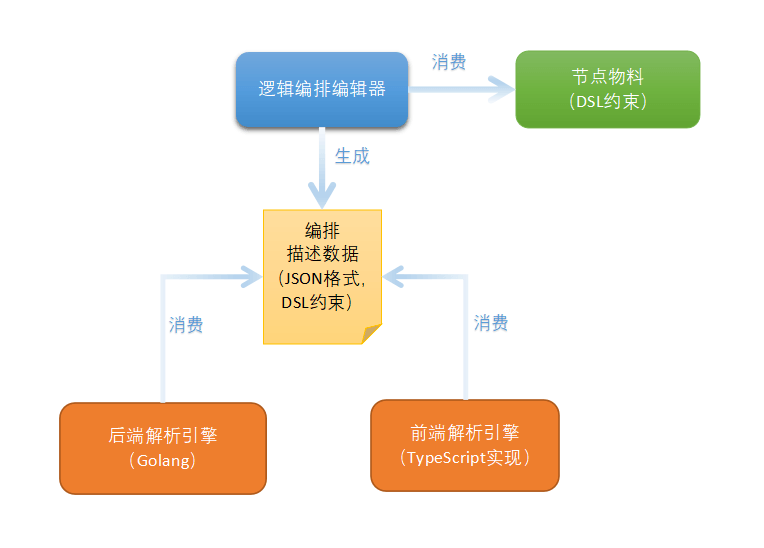
整个逻辑编排,由以下几部分组成:
节点物料,用于定义编辑器中的元件,包含在工具箱中的图标,端口以及属性面板中的组件schema。
逻辑编排编辑器,顾名思义,可视化编辑器,根据物料提供的元件信息,编辑生成JSON格式的“编排描述数据”。
编排描述数据,用户操作编辑器的生成物,供解析引擎消费
前端解析引擎,Typescript 实现的解析引擎,直接解析“编排描述数据”并执行,从而实现的软件的业务逻辑。
后端解析引擎,Golang 实现的解析引擎,直接解析“编排描述数据”并执行,从而实现的软件的业务逻辑。
逻辑编排实现方式的选择
逻辑编排,实现方式很多,争议也很多。
一直以来,小编的思路也很局限。从流程图层面,以线性的思维去思考,认为逻辑编排的意义并不大。因为,经过这么多年发展,事实证明代码才是表达逻辑的最佳方式,没有之一。用流程图去表达代码,最终只能是老板、客户的丰满理想与程序员骨感现实的对决。
直到看到Mybricks项目交互部分的实现方式,才打开了思路。类似unreal蓝图数据流驱动的实现方式,其实大有可为。
这种方式的意义是,跳出循环、if等这些底层的代码细节,以数据流转的方式思考业务逻辑,从而把业务逻辑抽象为可复用的组件,每个组件对数据进行相应处理或者根据数据执行相应动作,从而达到复用业务逻辑的目的。并且,节点的粒度可大可小,非常灵活。
具体实现方式是,把每个逻辑组件看成一个黑盒,通过入端口流入数据,出端口流出变换后的数据:
举个例子,一个节点用来从数据库查询客户列表,会是这样的形式: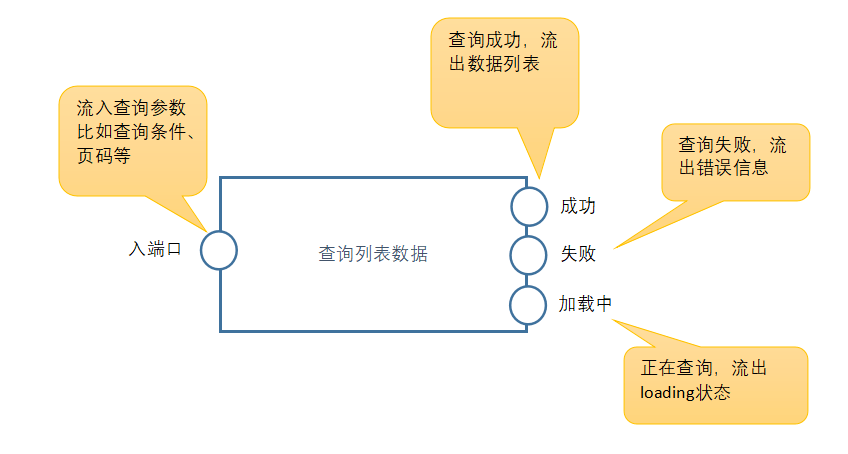
用户不需要关注这个元件节点的实现细节,只需要知道每个端口的功能就可以使用。这个元件节点的功能可以做的很简单,比如一个fetch,只有几十行代码。也可以做到很强大,比如类似useSwr,自带缓存跟状态管理,可以有几百甚至几千行代码。
我们希望这些元件节点是可以自行定义,方便插入的,并且我们做到了。
出端口跟入端口之间,可以用线连接,表示元件节点之间的调用关系,或者说是数据的流入关系。假如,数据读取成功,需要显示在列表中;失败,提示错误消息;查询时,显示等待的Spinning,那么就可以再加三个元件节点,变成: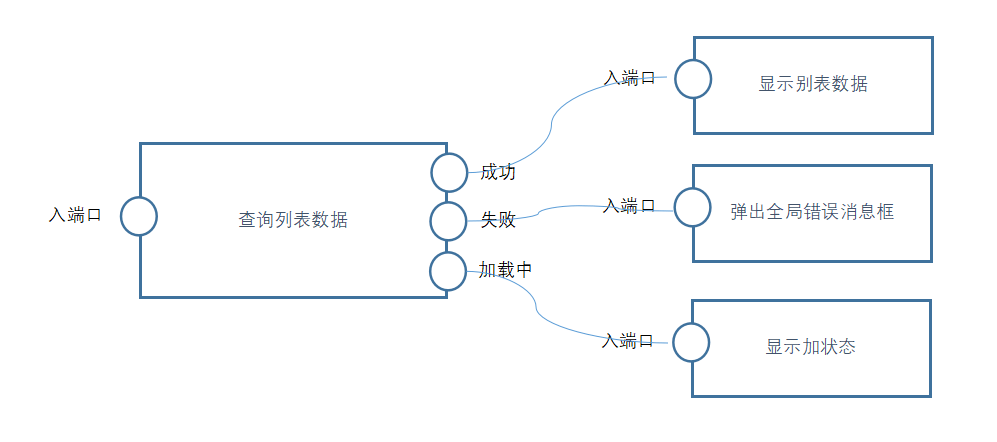
如果用流程图,上面这个编排,会被显示成如下样子: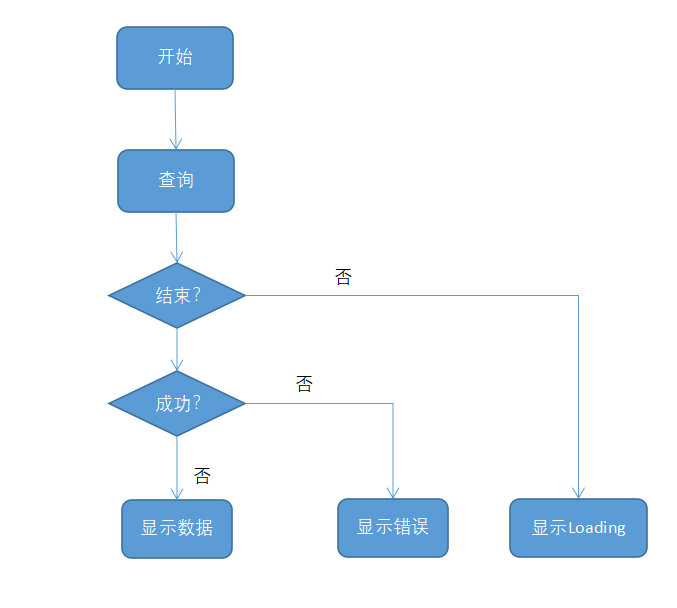
两个比较,就会发现,流程图的思考方式,会把人引入条件细节,其实就是试图用不擅长代码的图形来描述代码。是纯线性的,没有回调,也就无法实现类似js promise的异步。
而数据流驱动的逻辑编排,可以把人从细节中解放出来,用模块化的思考方式去设计业务逻辑,更方便把业务逻辑拆成一个个可复用的单元。
如果以程序员的角度来比喻,流程图相当于一段代码脚本,是面向过程的;数据流驱动的逻辑编排像是几个类交互完成一个功能,更有点面向对象的感觉。
朋友,如果是让你选,你喜欢哪种方式?欢迎留言讨论。
另外还有一种类似stratch的实现方式: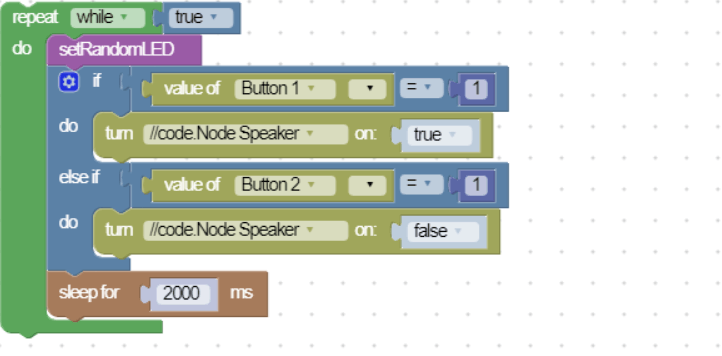
感觉这种纯粹为了可视化而可视化,只适合小孩子做玩具。会写代码的人不愿意用,太低效了。不会写代码的人,需要理解代码才会用。适合场景是用直观的方式介绍什么是代码逻辑,就是说只适合相对比较低智力水平的编程教学,比如幼儿园、小学等。商业应用,就免了。数据流驱动的逻辑编排
一个简单的例子
从现在开始,放下流程图,忘记strach,我们从业务角度去思考也逻辑,然后设计元件节点去实现相应的逻辑。
选一个简单又典型的例子:学生成绩单。一个成绩单包含如下数据: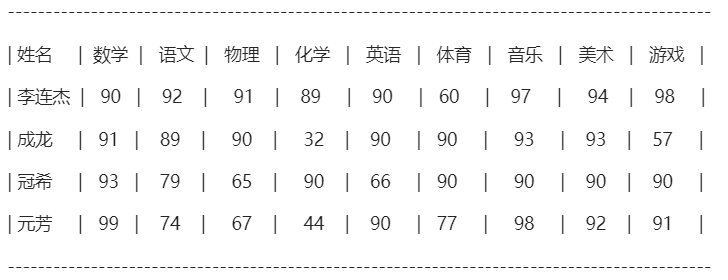
假如数据已经从数据库取出来了,第一步处理,统计每个学生的总分数。设计这么几个元件节点来配合完成: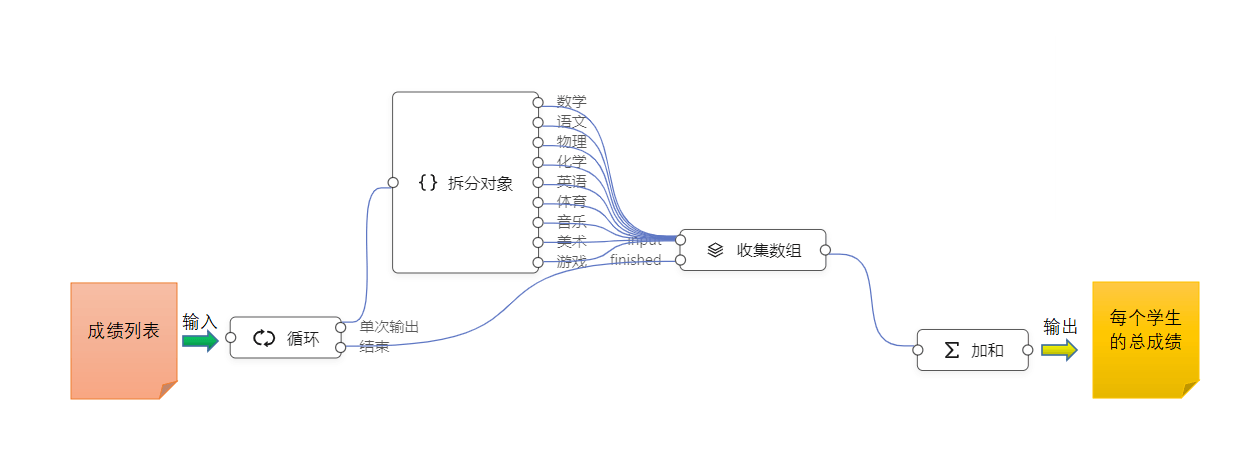
这个编排,输入成绩列表,循环输出每个学生的总成绩。为了完成这个编排,设计了四个元件节点:循环,入端口接收一个列表,遍历列表并循环输出,每一次遍历往“单次输出”端口发送一条数据,可以理解为一个学生对象(尽量从对象的角度思考,而不是数据记录),遍历结束后往“结束端口”发送循环的总数。如果按照上面的列表,“单次输出端口”会被调用4次,每次输出一个学生对象{姓名:xxx,语文:xxx,数学:xxx…},“结束”端口只被调用一次,输出结果是 4.
拆分对象,这个元件节点的出端口是可以动态配置的,它的功能是把一个对象按照属性值按照名字分发到指定的出端口。本例中,就是把各科成绩拆分开来。
收集数组,这个节点也可以叫收集到数组,作用是把串行接收到的数据组合到一个数组里。他有两个入端口:input端口,用来接收串行输入,并缓存到数组;finished端口,表示输入完成,把缓存到的数据组发送给输出端口。
加和,把输入端口传来的数组进行加和计算,输出总数。
这是一种跟代码完全不同的思考方式,每一个元件节点,就是一小段业务逻辑,也就是所谓的业务逻辑组件化。我们的项目中,只提供给了有限的预定义元件节点,想要更多的节点,可以自行自定义并注入系统,具体设计什么样的节点,完全取决于用户的业务需求跟喜好。作者更希望设计元件的过程是一个创作的过程,或许具备一定的艺术性。
刚刚的例子,审视之。有人可能会换一个方式来实现,比如拆分对象跟收集数据这两个节点,合并成一个节点:对象转数组,可能更方便,适应能力也更强:
对象转换数组节点,对象属性与数组索引的对应关系,可以通过属性面板的配置来完成。
这两种实现方式,说不清哪种更好,选择自己喜欢的,或者两种都提供。
输入节点、输出节点
一段图形化的逻辑编排,通过解析引擎,会被转换成一段可执行的业务逻辑。这段业务逻辑需要跟外部对接,为了明确对接语义,再添加两个特殊的节点元件:输入节点(开始节点),输出节点(结束节点)。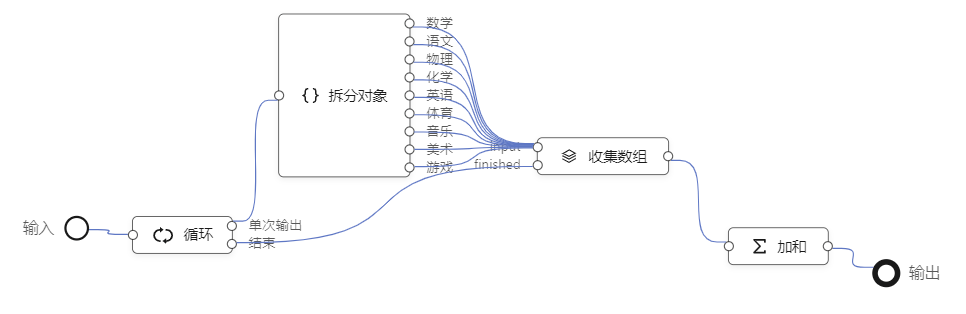
输入节点用于标识逻辑编排的入口,输入节点可以有一个或者多个,输入节点用细线圆圈表示。
输出节点用于标识逻辑编排的出口,输出节点可以有一个或者多个,输出节点用粗线圆圈表示。
在后面的引擎部分,会详细描述输入跟输出节点如何跟外部的对接。
编排的复用:子编排
一般低代码中,提升效率的方式是复用,尽可能复用已有的东西,比如组件、业务逻辑,从而达到降本、增效的目的。
设计元件节点是一种创作,那么使用元件节点进行业务编排,更是一种基于领域的创作。辛辛苦苦创作的编排,如果能被复用,应该算是对创作本身的尊重吧。
如果编排能够像元件节点一样,被其它逻辑编排所引用,那么这样的复用方式无疑是最融洽的。也是最方便的实现方式。
把能够被其它编排引用的编排称为子编排,上面计算学生总成绩的编排,转换成子编排,被引入时的形态应该是这样的:
子编排元件的输入端口对应逻辑编排实现的输入节点,输出端口对应编排实现的输出节点。
嵌入式编排节点
前文设计的循环组件非常简单,循环直接执行到底,不能被中断。但是,有的时候,在处理数据的时候,要根据每次遍历到的数据做判断,来决定继续循环还是终止循环。
就是说,需要一个循环节点,能够自定义它的处理流程。依据这个需求,设计了自定义循环元件,这是一种能够嵌入编排的节点,形式如下: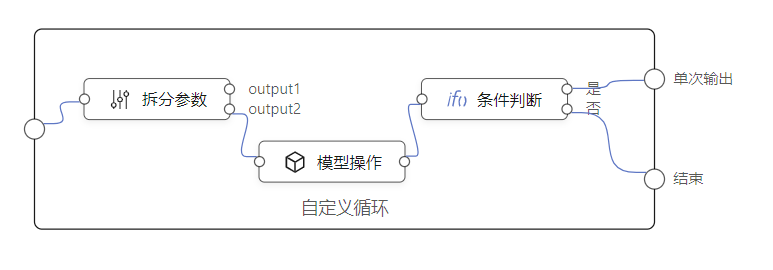
这种嵌入式编排节点,跟其它元件节点一样,事先定义好输入节点跟输出节点。只是它不完全是黑盒,其中一部分通过逻辑编排这种白盒方式来实现。
这种场景并不多见,除了循环,后端应用中,还有事务元件也需要类似实现方式: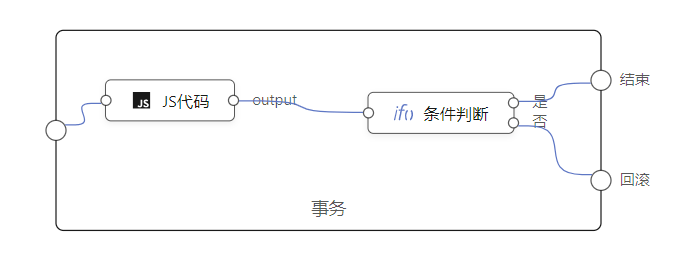
嵌入式元件跟其它元件节点一样,可以被其它元件连接,嵌入式节点在整个编排中的表现形式: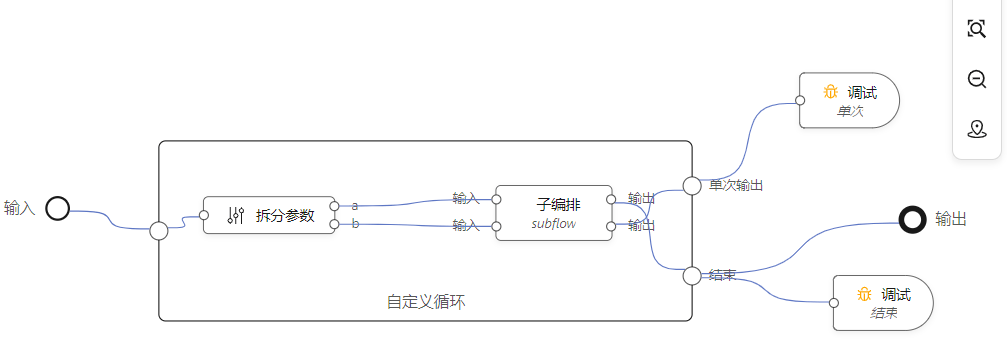
基本概念
为了进一步深入逻辑编排引擎跟编辑器的实现原理,先梳理一些基本的名词、概念。
逻辑编排,本文特指数据流驱动的逻辑编排,是由图形表示的一段业务逻辑,由元件节点跟连线组成。
元件节点,简称元件、节点、编排元件、编排单元。逻辑编排中具体的业务逻辑处理单元,带副作用的,可以实现数据转换、页面组件操作、数据库数据存取等功能。一个节点包含零个或多个输入端口,包含零个或多个输出端口。在设计其中,以圆角方形表示:
端口,分为输入端口跟输出端口两种。是元件节点流入或流出数据的通道(或者接口)。在逻辑单元中,用小圆圈表示。
输入端口,简称入端口、入口。输入端口位于元件节点的左侧。
输出端口,简称出端口、出口。输出端口位于元件节点的右侧。
单入口元件,只有一个入端口的元件节点。
多入口元件,有多个入端口的元件节点。
单出口元件,只有一个出端口的元件节点。
多出口元件,有多个出端口的元件节点。
输入节点,一种特殊的元件节点,用于描述逻辑编排的起点(开始点)。转换成子编排后,会对应子编排相应的入端口。
输出节点,一种特殊的元件节点,用于描述逻辑编排的终点(结束点)。转换成子编排后,会对应子编排相应的出端口。
嵌入式编排,特殊的元件节点,内部实现由逻辑编排完成。示例: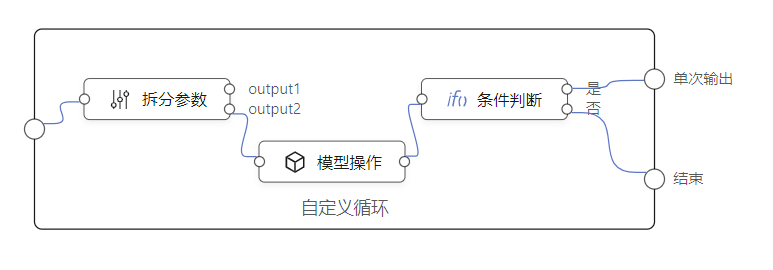
子编排,特殊的逻辑编排,该编排可以转换成元件节点,供其它逻辑编排使用。
连接线,简称连线、线。用来连接各个元件节点,表示数据的流动关系。
定义DSL
逻辑编排编辑器生成一份JSON,解析引擎解析这份JSON,把图形化的业务逻辑转化成可执行的逻辑,并执行。
编辑器跟解析引擎之间要有份约束协议,用来约定JSON的定义,这个协议就是这里定义的DSL。在typescript中,用interface、enum等元素来表示。
这些DSL仅仅是用来描述页面上的图形元素,通过activityName属性跟具体的实现代码逻辑关联起来。比如一个循环节点,它的actvityName是Loop,解析引擎会根据Loop这个名字找到该节点对应的实现类,并实例化为一个可执行对象。后面的解析引擎会详细展开描述这部分。
节点类型
元件节点类型叫NodeType,用来区分不同类型的节点,在TypeScript中是一个枚举类型。
export enum NodeType {
//开始节点
Start = 'Start',
//结束节点
End = 'End',
//普通节点
Activity = 'Activity',
//子编排,对其它编排的引用
LogicFlowActivity = "LogicFlowActivity",
//嵌入式节点,比如自定义逻辑编排
EmbeddedFlow = "EmbeddedFlow"
}端口
export interface IPortDefine {
//唯一标识
id: string;
//端口名词
name: string;
//显示文本
label?: string;
}元件节点
//一段逻辑编排数据
export interface ILogicFlowMetas {
//所有节点
nodes: INodeDefine<unknown>[];
//所有连线
lines: ILineDefine[];
}
export interface INodeDefine<ConfigMeta = unknown> {
//唯一标识
id: string;
//节点名称,一般用于开始结束、节点,转换后对应子编排的端口
name?: string;
//节点类型
type: NodeType;
//活动名称,解析引擎用,通过该名称,查找构造节点的具体运行实现
activityName: string;
//显示文本
label?: string;
//节点配置
config?: ConfigMeta;
//输入端口
inPorts?: IPortDefine[];
//输出端口
outPorts?: IPortDefine[];
//父节点,嵌入子编排用
parentId?: string;
// 子节点,嵌入编排用
children?: ILogicFlowMetas
}连接线
//连线接头
export interface IPortRefDefine {
//节点Id
nodeId: string;
//端口Id
portId?: string;
}
//连线定义
export interface ILineDefine {
//唯一标识
id: string;
//起点
source: IPortRefDefine;
//终点
target: IPortRefDefine;
}
逻辑编排
//这个代码上面出现过,为了使extends更直观,再出现一次
//一段逻辑编排数据
export interface ILogicFlowMetas {
//所有节点
nodes: INodeDefine<unknown>[];
//所有连线
lines: ILineDefine[];
}
//逻辑编排
export interface ILogicFlowDefine extends ILogicFlowMetas {
//唯一标识
id: string;
//名称
name?: string;
//显示文本
label?: string;
}解析引擎的实现
解析引擎有两份实现:Typescript实现跟Golang实现。这里介绍基于原理,以Typescript实现为准,后面单独章节介绍Golang的实现方式。也有朋友根据这个dsl实现了C#版自用,欢迎朋友们实现不同的语言版本并开源。
DSL只是描述了节点跟节点之间的连接关系,业务逻辑的实现,一点都没有涉及。需要为每个元件节点制作一个单独的处理类,才能正常解析运行。比如上文中的循环节点,它的DSL应该是这样的:
{
"id": "id-1",
"type": "Activity",
"activityName": "Loop",
"label": "循环",
"inPorts": [
{
"id":"port-id-1",
"name":"input",
"label":""
}
],
"outPorts": [
{
"id":"port-id-2",
"name":"output",
"label":"单次输出"
},
{
"id":"port-id-3",
"name":"finished",
"label":"结束"
}
]
}
开发人员制作一个处理类LoopActivity用来处理循环节点的业务逻辑,并将这个类注册入解析引擎,key为loop。这个类,我们叫做活动(Activity)。解析引擎,根据activityName查找类,并创建实例。LoopActivity的类实现应该是这样:
export interface IActivity{
inputHandler (inputValue?: unknown, portName:string);
}
export class LoopActivity implements IActivity{
constructor(protected meta: INodeDefine<ILoopConfig>) {}
//输入处理
inputHandler (inputValue?: unknown, portName:string){
if(portName !== "input"){
console.error("输入端口名称不正确")
return
}
let count = 0
if (!_.isArray(inputValue)) {
console.error("循环的输入值不是数组")
} else {
for (const one of inputValue) {
this.output(one)
count++
}
}
//输出循环次数
this.next(count, "finished")
}
//单次输出
output(value: unknown){
this.next(value, "output")
}
next(value:unknown, portName:string){
//把数据输出到指定端口,这里需要解析器注入代码
}
}
解析引擎根据DSL,调用inputHanlder,把控制权交给LoopActivity的对象,LoopActivity处理完成后把数据通过next方法传递出去。它只需要关注自身的业务逻辑就可以了。
这里难点是,引擎如何让所有类似LoopActivity类的对象联动起来。这个实现是逻辑编排的核心,虽然实现代码只有几百行,但是很绕,需要静下心来好好研读接下来的部分。
编排引擎的设计
编排引擎类图
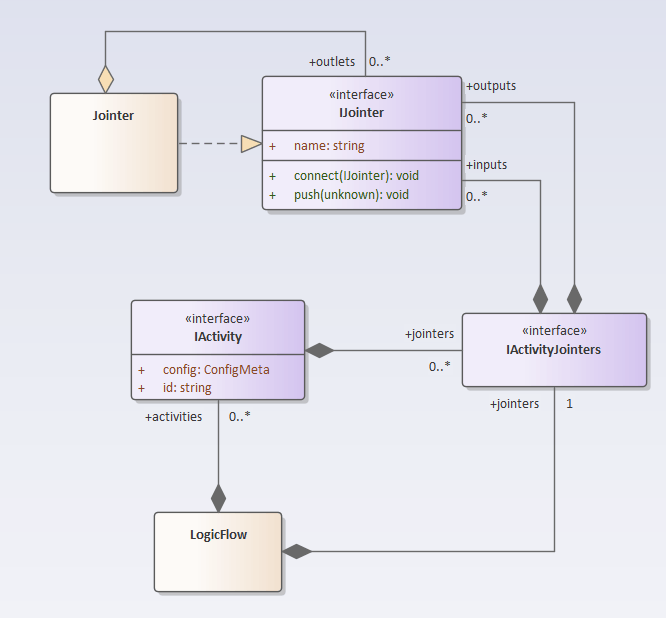
LogicFlow类,代表一个完整的逻辑编排。它解析一张逻辑编排图,并执行该图所代表的逻辑。
IActivity接口,一个元件节点的执行逻辑。不同的逻辑节点,实现不同的Activity类,这类都实现IActivity接口。比如循环元件,可以实现为
export class LoopActivity implements IActivity{
id: string
config: LoopActivityConfig
}LogicFlow类解析逻辑编排图时,根据解析到的元件节点,创建相应的IActivity实例,比如解析到Loop节点的时候,就创建LoopActivity实例。
LogicFlow还有一个功能,就是根据连线,给构建的IActivity实例建立连接关系,让数据能在不同的IActivity实例之间流转。先明白引擎中的数据流,是理解上述类图的前提。
解析引擎中的Jointer
在解析引擎中,数据按照以下路径流动: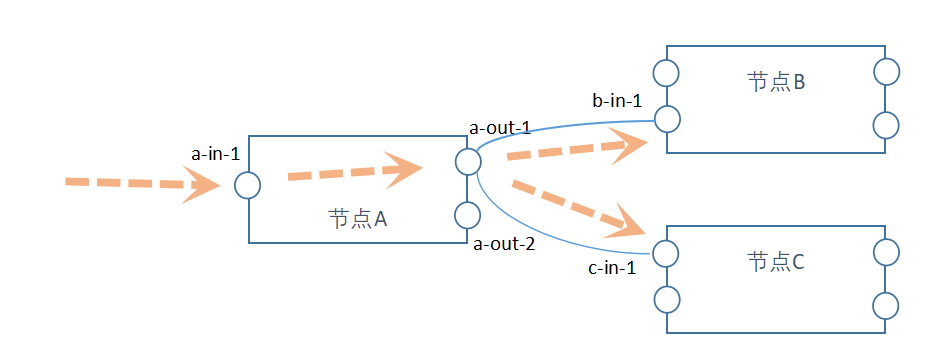
有三个节点:节点A、节点B、节点C。数据从节点A的“a-in-1”端口流入,通过一些处理后,从节点A的“a-out-1”端口流出。在“a-out-1”端口,把数据分发到节点B的“b-in-1”端口跟节点C的“c-in-1”端口。在B、C节点以后,继续重复类似的流动。
端口“a-out-1”要把数据分发到端口“b-in-1”和端口“c-in-1”,那么端口“a-out-1”要保存端口“b-in-1”和端口“c-in-1”的引用。就是说在解析引擎中,端口要建模为一个类,端口“a-out-1”是这个类的对象。要想分发数据,端口类跟自身是一个聚合关系。这种关系,让解析引擎中的端口看起来像连接器,故取名Jointer。一个Joniter实例,对应一个元件节点的端口。
在逻辑编排图中,一个端口,可以连接多个其它端口。所以,一个Jointer也可以连接多个其它Jointer。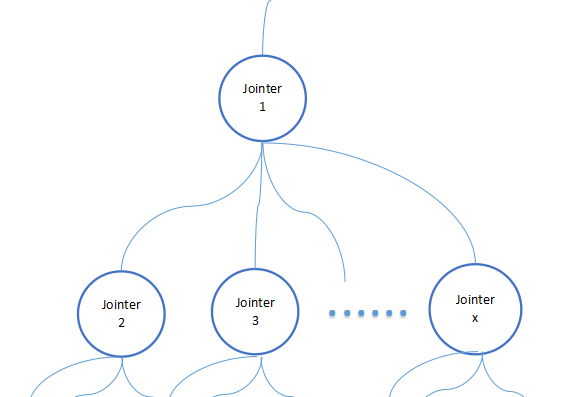
注意,这是实例的关系,如果对应到类图,就是这样的关系: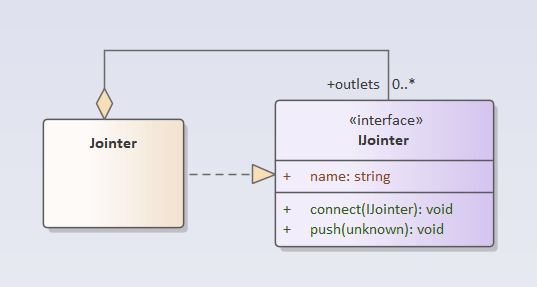
Jointer通过调用push方法把数据传递给其他Jointer实例。
connect方法用于给两个Joiner构建连接关系。
用TypeScript实现的话,代码是这样的:
//数据推送接口
export type InputHandler = (inputValue: unknown, context?:unknown) => void;
export interface IJointer {
name: string;
//接收上一级Jointer推送来的数据
push: InputHandler;
//添加下游Jointer
connect: (jointerInput: InputHandler) => void;
}
export class Jointer implements IJointer {
//下游Jonter的数据接收函数
private outlets: IJointer[] = []
constructor(public id: string, public name: string) {
}
//接收上游数据,并分发到下游
push: InputHandler = (inputValue?: unknown, context?:unknown) => {
for (const jointer of this.outlets) {
//推送数据
jointer.push(inputValue, context)
}
}
//添加下游Joninter
connect = (jointer: IJointer) => {
//往数组加数据,跟上面的push不一样
this.outlets.push(jointer)
}
//删除下游Jointer
disconnect = (jointer: InputHandler) => {
this.outlets.splice(this.outlets.indexOf(jointer), 1)
}
}在TypeScript跟Golang中,函数是一等公民。但是在类图里面,这个独立的一等公民是不好表述的。所以,上面的代码只是对类图的简单翻译。在实现时,Jointer的outlets可以不存IJointer的实例,只存Jointer的push方法,这样的实现更灵活,并且更容易把一个逻辑编排转成一个元件节点,优化后的代码:
//数据推送接口
export type InputHandler = (inputValue: unknown, context?:unknown) => void;
export interface IJointer {
//当key使用,不参与业务逻辑
id: string;
name: string;
//接收上一级Jointer推送来的数据
push: InputHandler;
//添加下游Jointer
connect: (jointerInput: InputHandler) => void;
}
export class Jointer implements IJointer {
//下游Jonter的数据接收函数
private outlets: InputHandler[] = []
constructor(public id: string, public name: string) {
}
//接收上游数据,并分发到下游
push: InputHandler = (inputValue?: unknown, context?:unknown) => {
for (const jointerInput of this.outlets) {
jointerInput(inputValue, context)
}
}
//添加下游Joninter
connect = (inputHandler: InputHandler) => {
this.outlets.push(inputHandler)
}
//删除下游Jointer
disconnect = (jointer: InputHandler) => {
this.outlets.splice(this.outlets.indexOf(jointer), 1)
}
}记住这里的优化:Jointer的下游已经不是Jointer了,是Jointer的push方法,也可以是独立的其它方法,只要参数跟返回值跟Jointer的push方法一样就行,都是InputHandler类型。这个优化,可以让把Activer的某个处理函数设置为入Jointer的下游,后面会有进一步介绍。
Activity与Jointer的关系
一个元件节点包含多个(或零个)入端口和多个(或零个)出端口。那么意味着一个IActivity实例包含多个Jointer,这些Jointer也按照输入跟输出来分组: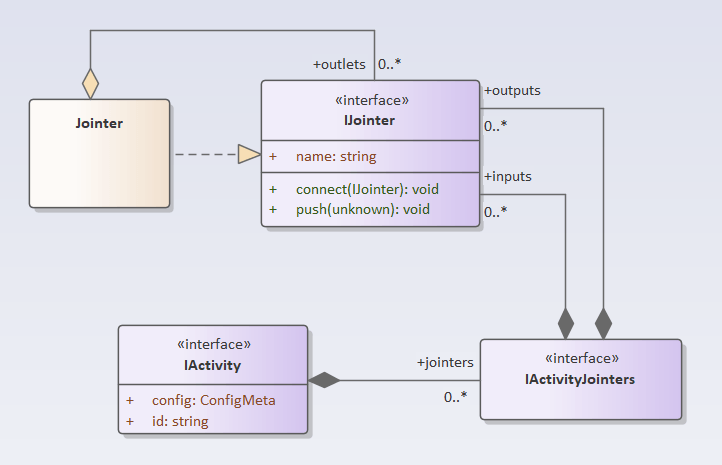
TypeScript定义的代码如下:
export interface IActivityJointers {
//入端口对应的连接器
inputs: IJointer[];
//处端口对应的连接器
outputs: IJointer[];
//通过端口名获取出连接器
getOutput(name: string): IJointer | undefined
//通过端口名获取入连接器
getInput(name: string): IJointer | undefined
}
//活动接口,一个实例对应编排图一个元件节点,用于实现元件节点的业务逻辑
export interface IActivity<ConfigMeta = unknown> {
id: string;
//连接器,跟元件节点的端口异议对应
jointers: IActivityJointers,
//元件节点配置,每个Activity的配置都不一样,故而用泛型
config?: ConfigMeta;
//销毁
destory(): void;
}入端口挂接业务逻辑
入端口对应一个Jointer,这个Jointer的连接关系:
逻辑引擎在解析编排图元件时,会给每一个元件端口创建一个Jointer实例:
//构造Jointers
for (const out of activityMeta.outPorts || []) {
//出端口对应的Jointer
activity.jointers.outputs.push(new Jointer(out.id, out.name))
}
for (const input of activityMeta.inPorts || []) {
//入端口对应的Jointer
activity.jointers.inputs.push(new Jointer(input.id, input.name))
}新创建的Jointer,它的下游是空的,就是说成员变量的outlets数组是空的,并没有挂接到真实的业务处理。要调用Jointer的connect方法,把Activity的处理函数作为下游连接过去。
最先想到的实现方式是Acitvity有一个inputHandler方法,根据端口名字分发数据到相应处理函数:
export interface IActivity<ConfigMeta = unknown> {
id: string;
//连接器,跟元件节点的端口异议对应
jointers: IActivityJointers,
//元件节点配置,每个Activity的配置都不一样,故而用泛型
config?: ConfigMeta;
//入口处理函数
inputHandler(portName:string, inputValue: unknown, context?:unknown):void
//销毁
destory(): void;
}
export abstract class SomeActivity implements IActivity<SomeConfigMeta> {
id: string;
jointers: IActivityJointers;
config?: SomeConfigMeta;
constructor(public meta: INodeDefine<ConfigMeta>) {
this.id = meta.id
this.jointers = new ActivityJointers()
this.config = meta.config;
}
//入口处理函数
inputHandler(portName:string, inputValue: unknown, context?:unknown){
switch(portName){
case PORTNAME1:
port1Handler(inputValue, context)
break
case PORTNAME2:
...
break
...
}
}
//端口1处理函数
port1Handler = (inputValue: unknown, context?:unknown)=>{
...
}
destory = () => {
//销毁处理
...
}
}LogicFlow解析编排JSON,碰到SomeActivity对应的元件时,如下处理:
//创建SomeActivity实例
const someNode = new SomeActivity(meta)
//构造Jointers
for (const out of activityMeta.outPorts || []) {
//出端口对应的Jointer
activity.jointers.outputs.push(new Jointer(out.id, out.name))
}
for (const input of activityMeta.inPorts || []) {
//入端口对应的Jointer
const jointer = new Jointer(input.id, input.name)
activity.jointers.inputs.push(jointer)
//给入口对应的连接器,挂接输入处理函数
jointer.connect(someNode.inputHandler)
}业务逻辑挂接到出端口
入口处理函数,处理完数据以后,需要调用出端口连接器的push方法,把数据分发出去: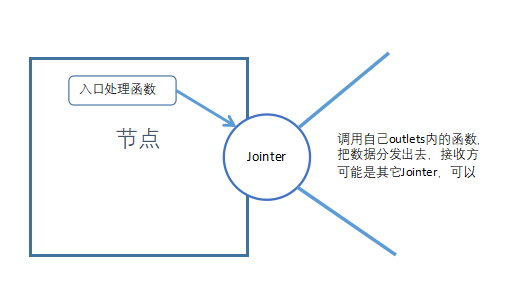
具体实现代码:
export abstract class SomeActivity implements IActivity<SomeConfigMeta> {
jointers: IActivityJointers;
...
//入口处理函数
inputHandler(portName:string, inputValue: unknown, context?:unknown){
switch(portName){
case PORTNAME1:
port1Handler(inputValue, context)
break
case PORTNAME2:
...
break
...
}
}
//端口1处理函数
port1Handler = (inputValue: unknown, context?:unknown)=>{
...
//处理后得到新的值:newInputValue 和新的context:newContext
//把数据分发到相应出口
this.jointers.getOutput(somePortName).push(newInputValue, newContext)
}
...
}入端口跟出端口,连贯起来,一个Activtity内部的流程就跑通了: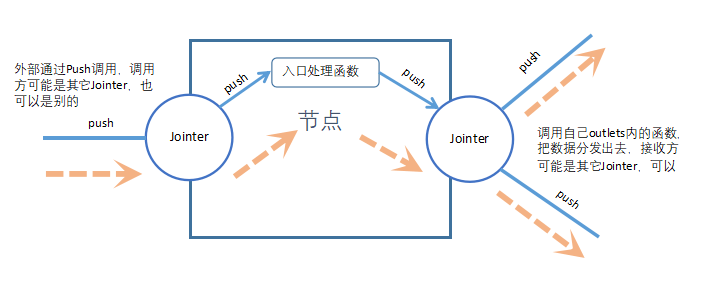
出端口挂接其它元件节点
入端口关联的是Activity的自身处理函数,出端口关联的是外部处理函数,这些外部处理函数有能是其它连接器(Jointer)的push方法,也可能来源于其它跟应用对接的部分。
如果是关联的是其他节点的Jointer,关联关系是通过逻辑编排图中的连线定义的。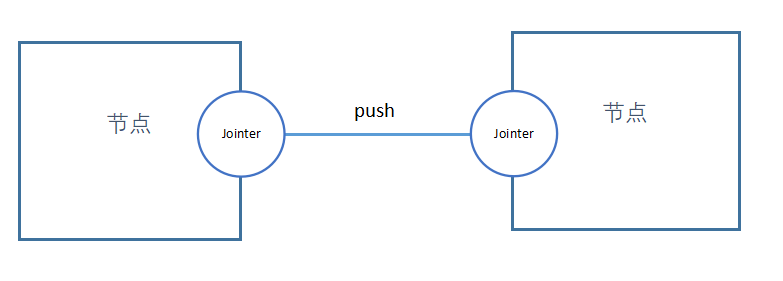
解析器先构造完所有的节点,然后遍历一遍连线,调用连线源Jointer的conect方法,参数是目标Jointer的push,就把关联关系构建起来了:
for (const lineMeta of this.flowMeta.lines) {
//先找起始节点,这个后面会详细介绍,现在可以先忽略
let sourceJointer = this.jointers.inputs.find(jointer => jointer.id === lineMeta.source.nodeId)
if (!sourceJointer && lineMeta.source.portId) {
sourceJointer = this.activities.find(reaction => reaction.id === lineMeta.source.nodeId)?.jointers?.outputs.find(output => output.id === lineMeta.source.portId)
}
if (!sourceJointer) {
throw new Error("Can find source jointer")
}
//先找起终止点,这个后面会详细介绍,现在可以先忽略
let targetJointer = this.jointers.outputs.find(jointer => jointer.id === lineMeta.target.nodeId)
if (!targetJointer && lineMeta.target.portId) {
targetJointer = this.activities.find(reaction => reaction.id === lineMeta.target.nodeId)?.jointers?.inputs.find(input => input.id === lineMeta.target.portId)
}
if (!targetJointer) {
throw new Error("Can find target jointer")
}
//重点关注这里,把一条连线的首尾相连,构造起连接关系
sourceJointer.connect(targetJointer.push)
}特殊的元件节点:开始节点、结束节点
到目前为止,解析引擎部分,已经能够成功解析普通的元件并成功连线,但是一个编排的入口跟出口尚未处理,对应的是编排图的输入节点(开始节点)跟输出节点(结束节点)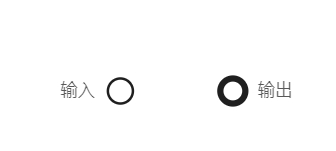
这两个节点,没有任何业务逻辑,只是辅助把外部输入,连接到内部的元件;或者把内部的输出,发送给外部。所以,这两个节点,只是简单的Jointer就够了。
如果把一个逻辑编排看作一个元件节点: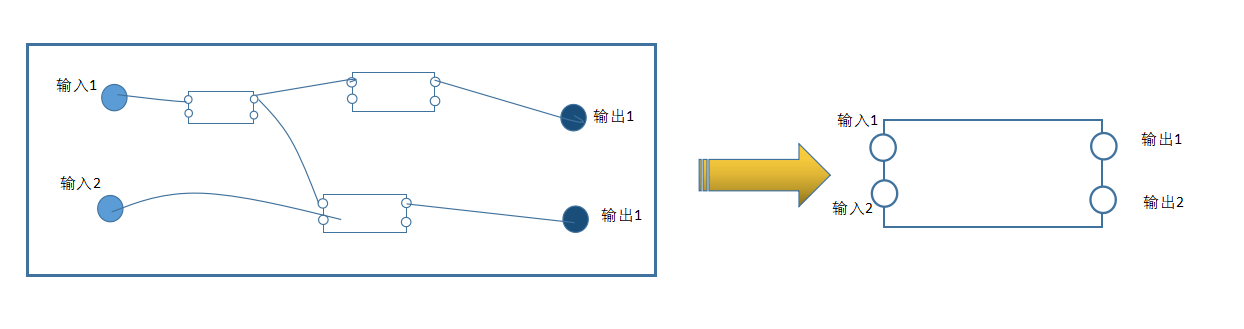
输入元件节点对应的是输入端口,输出元件节点对应的是输出端口。既然逻辑编排也有自己端口,那么LogicFlow也要聚合ActivityJointers: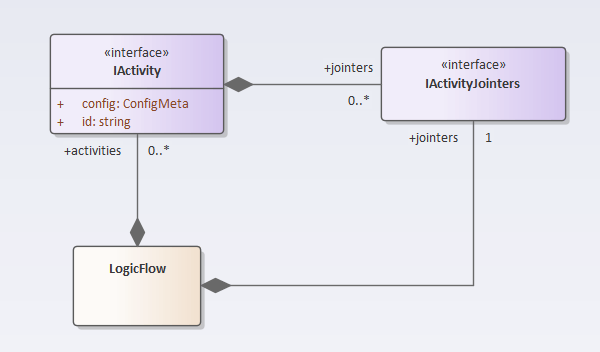
引擎解析的时候,要根据开始元件节点跟结束元件节点,构建LogicFlow的Jointer:
export class LogicFlow {
id: string;
jointers: IActivityJointers = new ActivityJointers();
activities: IActivity[] = [];
constructor(private flowMeta: ILogicFlowDefine) {
...
//第一步,解析节点
this.constructActivities()
...
}
//构建一个图的所有节点
private constructActivities() {
for (const activityMeta of this.flowMeta.nodes) {
switch (activityMeta.type) {
case NodeType.Start:
//start只有一个端口,可能会变成其它流程的端口,所以name谨慎处理
this.jointers.inputs.push(new Jointer(activityMeta.id, activityMeta.name || "input"));
break;
case NodeType.End:
//end 只有一个端口,可能会变成其它流程的端口,所以name谨慎处理
this.jointers.outputs.push(new Jointer(activityMeta.id, activityMeta.name || "output"));
break;
}
...
}
}
}经过这样的处理,一个逻辑编排就可以变成一个元件节点,被其他逻辑编排所引用,具体实现细节,本文后面再展开叙述。
根据元件节点创建Activity实例
在逻辑编排图中,一种类型的元件节点,在解析引擎中会对应一个实现了IActivity接口的类。比如,循环节点,对应LoopActivity;条件节点,对应ConditionActivity;调试节点,对应DebugActivity;拆分对象节点,对应SplitObjectActivity。
这些Activity要跟具体的元件节点建立一一对应关系,在DSL中以activityName作为关联枢纽。这样解析引擎根据activityName查找相应的Activity类,并创建实例。
工厂方法
如何找到并创建节点单元对应的Activity实例呢?最简单的实现方法,是给每个Activity类实现一个工厂方法,建立一个activityName跟工厂方法的映射map,解析引擎根据这个map实例化相应的Activity。简易代码:
//工厂方法的类型定义
export type ActivityFactory = (meta:ILogiFlowDefine)=>IActivity
//activityName跟工厂方法的映射map
export const activitiesMap:{[activityName:string]:ActivityFactory} = {}
export class LoopActivity implements IActivity{
...
constructor(protected meta:ILogiFlowDefine){}
inputHandler=(portName:string, inputValue:unknown, context:unknown)=>{
if(portName === "input"){
//逻辑处理
...
}
}
...
}
//LoopActivity的工厂方法
export const LoopActivityFactory:ActivityFactory = (meta:ILogiFlowDefine)=>{
return new LoopActivity(meta)
}
//把工厂方法注册进map,跟循环节点的activityName对应好
activitiesMap["loop"] = LoopActivityFactory
//LogicFlow的解析代码
export class LogicFlow {
id: string;
jointers: IActivityJointers = new ActivityJointers();
activities: IActivity[] = [];
constructor(private flowMeta: ILogicFlowDefine) {
...
//第一步,解析节点
this.constructActivities()
...
}
//构建一个图的所有节点
private constructActivities() {
for (const activityMeta of this.flowMeta.nodes) {
switch (activityMeta.type) {
...
case NodeType.Activity:
//查找元件节点对应的ActivityFactory
const activityFactory = activitiesMap[activityMeta.activityName]
if(activityFactory){
//创建Activity实例
this.activities.push(activityFactory(activityMeta))
}else{
//提示错误
}
break;
}
...
}
}
}
引入反射
正常情况下,上面的实现方法,已经够用了。但是,作为一款开放软件,会有大量的自定义Activity的需求。上面的实现方式,会让Activity的实现代码略显繁琐,并且所有的输入端口都要通过switch判断转发到相应处理函数。
我们希望把这部分工作推到框架层做,让具体Activity的实现更简单。所以,引入了Typescipt的反射机制:注解。通过注解自动注册Activity类,通过注解直接关联端口与相应的处理函数,省去switch代码。
代码经过改造以后,就变成这样:
//通过注解注册LoopActivity类
@Activity("loop")
export class LoopActivity implements IActivity{
...
constructor(protected meta:ILogiFlowDefine){}
//通过注解把input端口跟该处理函数关联
@Input("input")
inputHandler=(inputValue:unknown, context:unknown)=>{
//逻辑处理
...
}
...
}
//LogicFlow的解析代码
export class LogicFlow {
id: string;
jointers: IActivityJointers = new ActivityJointers();
activities: IActivity[] = [];
constructor(private flowMeta: ILogicFlowDefine) {
...
//第一步,解析节点
this.constructActivities()
...
}
//构建一个图的所有节点
private constructActivities() {
for (const activityMeta of this.flowMeta.nodes) {
switch (activityMeta.type) {
...
case NodeType.Activity:
//根据反射拿到Activity的构造函数
const activityContructor = ...//此处是反射代码
if(activityContructor){
//创建Activity实例
this.activities.push(activityContructor(activityMeta))
}else{
//提示错误
}
break;
}
...
}
}
}LogicFlow是框架层代码,用户不需要关心具体的实现细节。LoopActivity的代码实现,明显简洁了不少。
Input注解接受一个参数作为端口名称,参数默认值是input。
还有一种节点,它的输入端口是不固定的,可以动态增加或者删除。比如: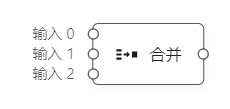
合并节点就是动态入口的节点,它的功能是接收入口传来的数据,等所有数据到齐以后,合并成一个对象转发到输出端口。这个节点,有异步等待的功能。
为了处理这种节点,我们引入新的注解DynamicInput。实际项目中合并节点Activity的完整实现:
import {
AbstractActivity,
Activity,
DynamicInput
} from '@rxdrag/minions-runtime';
import { INodeDefine } from '@rxdrag/minions-schema';
@Activity(MergeActivity.NAME)
export class MergeActivity extends AbstractActivity<unknown> {
public static NAME = 'system.merge';
private noPassInputs: string[] = [];
private values: { [key: string]: unknown } = {};
constructor(meta: INodeDefine<unknown>) {
super(meta);
this.resetNoPassInputs();
}
@DynamicInput
inputHandler = (inputName: string, inputValue: unknown) => {
this.values[inputName] = inputValue;、
//删掉已经收到数据的端口名
this.noPassInputs = this.noPassInputs.filter(name=>name !== inputName)
if (this.noPassInputs.length === 0) {
//next方法,把数据转发到指定出口,第二个参数是端口名,默认值input
this.next(this.values);
this.resetNoPassInputs();
}
};
resetNoPassInputs(){
for (const input of this.meta.inPorts || []) {
this.noPassInputs.push(input.name);
}
}
}
注解DynamicInput不需要绑定固定的端口,所以就不需要输入端口的名称。
子编排的解析
子编排就是一段完整的逻辑编排,跟普通的逻辑编排没有任何区别。只是它需要被其它编排引入,这个引入是通过附加一个Activity实现的。
export interface ISubLogicFLowConfig {
logicFlowId?: string
}
export interface ISubMetasContext{
subMetas:ILogicFlowDefine[]
}
@Activity(SubLogicFlowActivity.NAME)
export class SubLogicFlowActivity implements IActivity {
public static NAME = "system-react.subLogicFlow"
id: string;
jointers: IActivityJointers;
config?: ISubLogicFLowConfig;
logicFlow?: LogicFlow;
//context可以从引擎外部注入的,此处不必纠结它是怎么来的这个细节
constructor(meta: INodeDefine<ISubLogicFLowConfig>, context: ISubMetasContext) {
this.id = meta.id
//通过配置中的LogicFlowId,查找子编排对应的JSON数据
const defineMeta = context?.subMetas?.find(subMeta => subMeta.id === meta.config?.logicFlowId)
if (defineMeta) {
//解析逻辑编排,new LogicFlow 就是解析一段逻辑编排,也可以在别处被调用
this.logicFlow = new LogicFlow(defineMeta, context)
//把解析后的连接器对应到本Activity
this.jointers = this.logicFlow.jointers
} else {
throw new Error("No meta on sub logicflow")
}
}
destory(): void {
this.logicFlow?.destory();
this.logicFlow = undefined;
}
}因为不需要把端口绑定到相应的处理函数,故该Activity并没有使用Input相关注解。
嵌入式编排的解析
逻辑编排中,最复杂的部分,就是嵌入式编排的解析,希望小编能解释清楚。
再看一遍嵌入式编排的表现形式: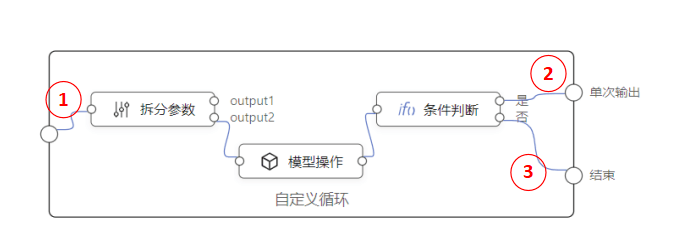
这是自定义循环节点。虽然它端口直接跟内部的编排节点相连,但是实际上这种情况是无法直接调用new LogicFlow 来解析内部逻辑编排的,需要进行转换。引擎解析的时候,把会把上面的子编排重组成如下形式: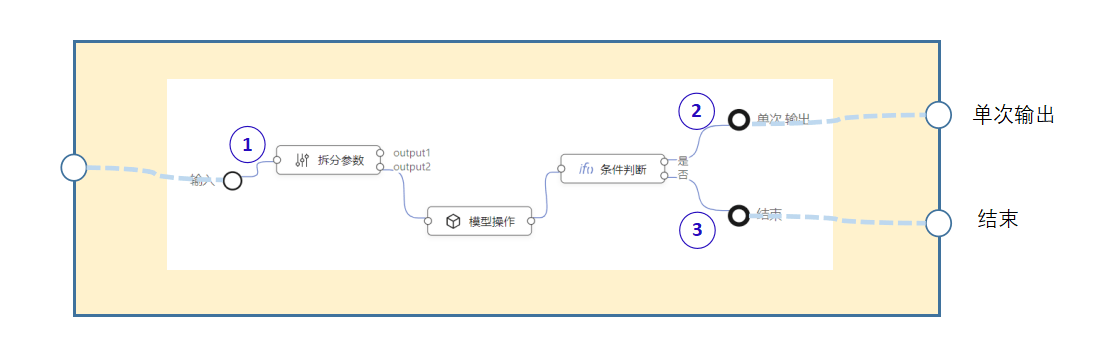
首先,给子编排添加输入节点,名称跟ID分别对应自定义循环的入端口名称跟ID;添加输出节点,名称跟ID分别对应自定义循环的出端口名称跟ID。
然后,把一个图中的红色数字标注的连线,替换成第二个图中蓝色数字标注的连线。
容器节点的端口,并不会跟转换后的输入节点或者输出节点直接连接,而是在实现中根据业务逻辑适时调用,故用粗虚线表示。
自定义循环具体实现代码:
import { AbstractActivity, Activity, Input, LogicFlow } from "@rxdrag/minions-runtime";
import { INodeDefine } from "@rxdrag/minions-schema";
import _ from "lodash"
export interface IcustomizedLoopConifg {
fromInput?: boolean,
times?: number
}
@Activity(CustomizedLoop.NAME)
export class CustomizedLoop extends AbstractActivity<IcustomizedLoopConifg> {
public static NAME = "system.customizedLoop"
public static PORT_INPUT = "input"
public static PORT_OUTPUT = "output"
public static PORT_FINISHED = "finished"
finished = false
logicFlow?: LogicFlow;
constructor(meta: INodeDefine<IcustomizedLoopConifg>) {
super(meta)
if (meta.children) {
//通过portId关联子流程的开始跟结束节点,端口号对应节点号
//此处的children是被引擎转换过处理的
this.logicFlow = new LogicFlow({ ...meta.children, id: meta.id }, undefined)
//把子编排的出口,挂接到本地处理函数
const outputPortMeta = this.meta.outPorts?.find(
port=>port.name === CustomizedLoop.PORT_OUTPUT
)
if(outputPortMeta?.id){
this.logicFlow?.jointers?.getOutput(outputPortMeta?.name)?.connect(
this.oneOutputHandler
)
}else{
console.error("No output port in CustomizedLoop")
}
const finishedPortMeta = this.meta.outPorts?.find(
port=>port.name === CustomizedLoop.PORT_FINISHED
)
if(finishedPortMeta?.id){
this.logicFlow?.jointers?.getOutput(finishedPortMeta?.id)?.connect(
this.finisedHandler
)
}else{
console.error("No finished port in CustomizedLoop")
}
} else {
throw new Error("No implement on CustomizedLoop meta")
}
}
@Input()
inputHandler = (inputValue?: unknown, context?:unknown) => {
let count = 0
if (this.meta.config?.fromInput) {
if (!_.isArray(inputValue)) {
console.error("Loop input is not array")
} else {
for (const one of inputValue) {
//转发输入到子编排
this.getInput()?.push(one, context)
count++
//如果子编排调用了结束
if(this.finished){
break
}
}
}
} else if (_.isNumber(this.meta.config?.times)) {
for (let i = 0; i < (this.meta.config?.times || 0); i++) {
//转发输入到子编排
this.getInput()?.push(, context)
count++
//如果子编排调用了结束
if(this.finished){
break
}
}
}
//如果子编排中还没有被调用过finished
if(!this.finished){
this.next(count, CustomizedLoop.PORT_FINISHED, context)
}
}
getInput(){
return this.logicFlow?.jointers?.getInput(CustomizedLoop.PORT_INPUT)
}
oneOutputHandler = (value: unknown, context?:unknown)=>{
//输出到响应端口
this.output(value, context)
}
finisedHandler = (value: unknown, context?:unknown)=>{
//标识已调用过finished
this.finished = true
//输出到响应端口
this.next(value, CustomizedLoop.PORT_FINISHED, context)
}
output = (value: unknown, context?:unknown) => {
this.next(value, CustomizedLoop.PORT_OUTPUT, context)
}
}基础的逻辑编排引擎,基本全部介绍完了,清楚了节点之间的编排机制,是时候定义节点的连线规则了。
节点的连线规则
一个节点,是一个对象。有状态,有副作用。有状态的对象没有约束的互连,是非常危险的行为。
这种情况会面临一个诱惑,或者说用户自己也分不清楚。就是把节点当成无状态对象使用,或者直接认为节点就是无状态的,不加限制的把连线连到某个节点的入口上。
比如上面计算学生总分例子,可能会被糊涂的用户连成这样: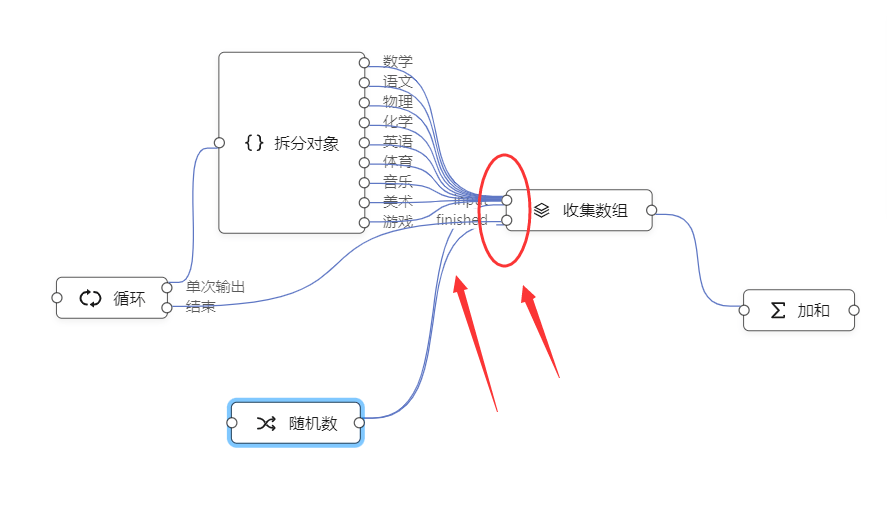
这种连接方式,直接造成收集数组节点无法正常工作。
逻辑编排之所以直观,在于它把每一个个数据流通的路径都展示出来了。在一个通路上的一个节点,最好只完成一个该通路的功能。另一个通路如果想完成同样的功能,最好再新建一个对象: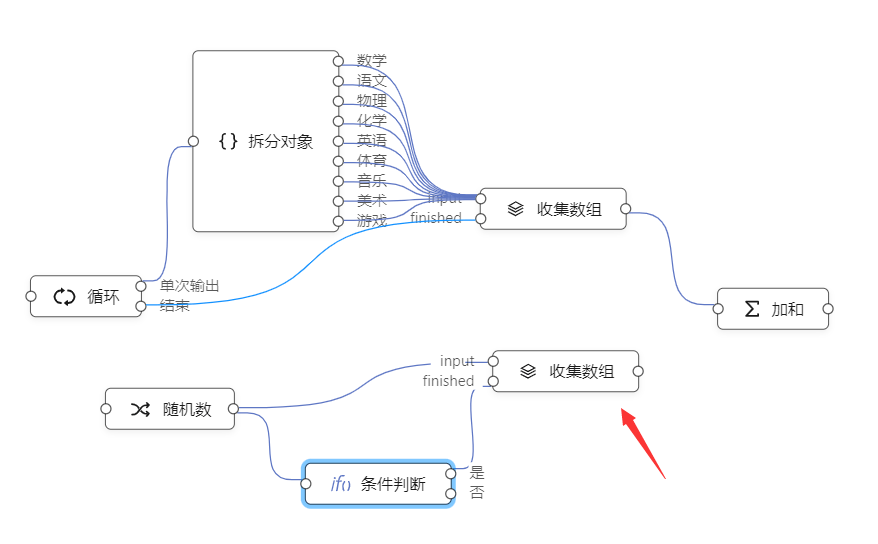
这样两个收集数组节点,就互不干扰了。
要实现这样的约束,只需要加一个连线规则:同一个入端口,只能连一条线。
有了这条规则,节点对象状态带来的不利影响,基本消除了。
在这样的规则下,收集数组节点的入口不能连接多条连线,只需要把它重新设计成如下形式: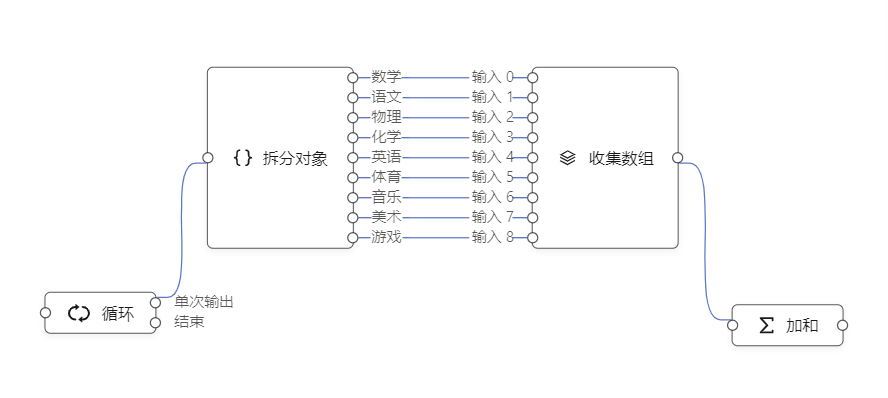
一个出端口,可以往外连接多条连线,用于表示并行执行。另一条规则就是:同一个出端口,可以有多条连线。
数据是从左往右流动,所以再加上最后一条规则:入端口在节点左侧,出端口在节点右侧。
所有的连线规则完成了,蛮简单的,编辑器层面可以直接做约束,防止用户输错。
编辑器的实现
编辑器布局
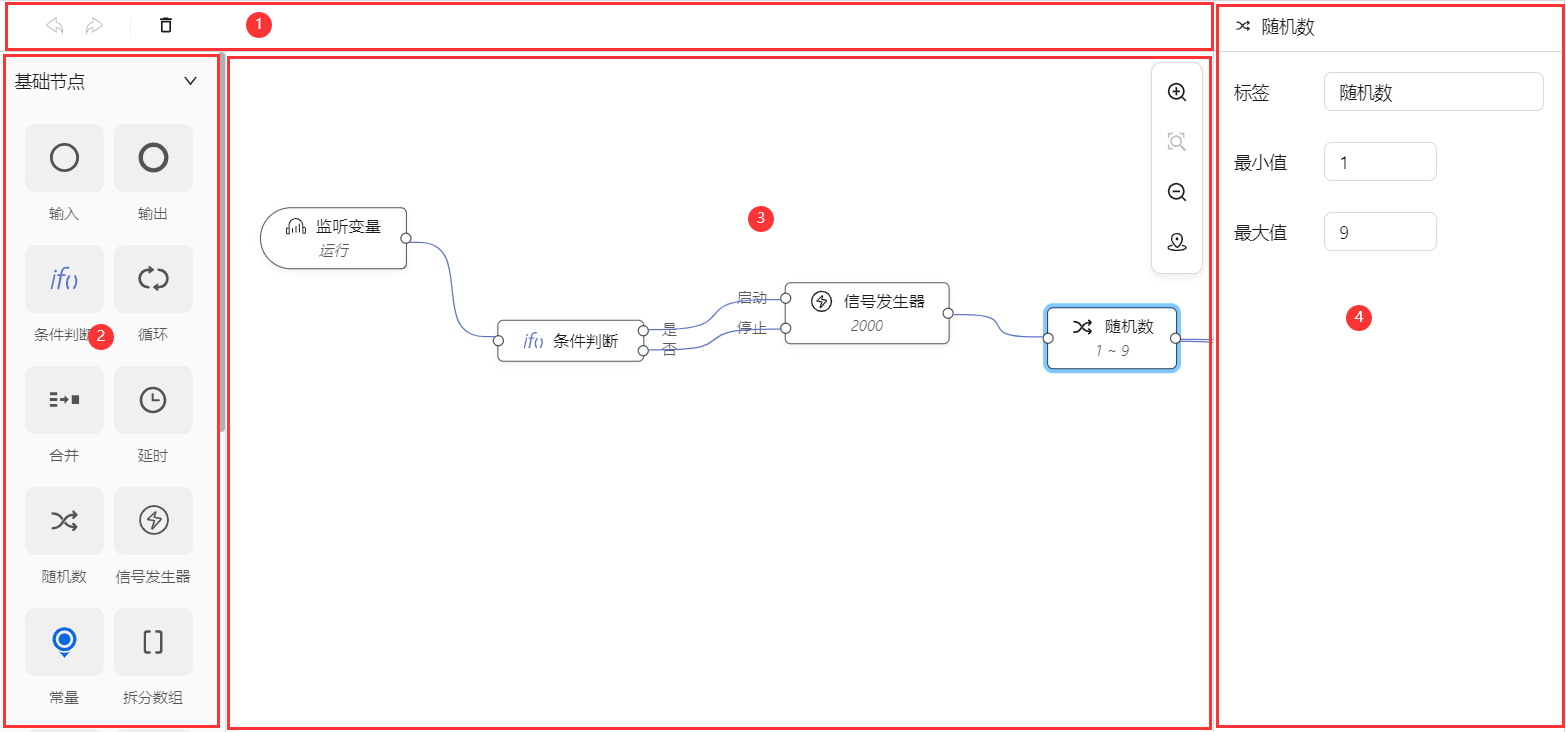
整个编辑器分为图中标注的四个区域。
- ① 工具栏,编辑器常规操作,比如撤销、重做、删除等。
- ② 工具箱(物料箱),存放可以被拖放的元件物料,这些物料是可以从外部注入到编辑器的。
- ③ 画布区,绘制逻辑编排图的画布。每个节点都有自己的坐标,要基于这个对DSL进行扩展,给节点附加坐标信息。画布基于阿里antv X6实现。
- ④ 属性面板,编辑元件节点的配置信息。物料是从编辑器外部注入的,物料对应节点的配置是变化的,所以属性面板内的组件也是变化的,使用RxDrag的低代码渲染引擎来实现,外部注入的物料要写到相应的Schema信息。低代码Schema相关内容,请参考另一篇文章《实战,一个高扩展、可视化低代码前端,详实、完整》
扩展DSL
前面定义的DSL用在逻辑编排解析引擎里,足够了。但是,在画布上展示,还缺少节点位置跟尺寸信息。设计器画布是基于X6实现的,要添加X6需要的信息,来扩展DSL:
这些信息,足以在画布上展示一个完整的逻辑编排图了。export interface IX6NodeDefine { /** 节点x坐标 */ x: number; /** 节点y坐标 */ y: number; /** 节点宽度 */ width: number; /** 节点高度 */ height: number; } // 扩展后节点 export interface IActivityNode extends INodeDefine { x6Node?: IX6NodeDefine }元件物料定义
工具箱区域②跟画布区域③显示节点时,使用了共同的元素:元件图标,元件标题,图标颜色,这些可以放在物料的定义里。
物料还需要:元件对应的Acitvity名字,属性面板④ 的配置Schema。具体定义:import { NodeType, IPortDefine } from "./dsl";
//端口定义
export interface IPorts {
//入端口
inPorts?: IPortDefine[];
//出端口
outPorts?: IPortDefine[];
}
//元件节点的物料定义
export interface IActivityMaterial<ComponentNode = unknown, NodeSchema = unknown, Config = unknown, MaterialContext = unknown> {
//标题
label: string;
//节点类型,NodeType在DLS中定义,这里根据activityType决定画上的图形样式
activityType: NodeType;
//图标代码,react的话,相当于React.ReactNode
icon?: ComponentNode;
//图标颜色
color?: string;
//属性面板配置,可以适配不同的低代码Schema,使用RxDrag的话,这可以是INodeSchema类型
schema?: NodeSchema;
//默认端口,元件节点的端口设置的默认值,大部分节点端口跟默认值是一样的,
//部分动态配置端口,会根据配置有所变化
defaultPorts?: IPorts;
//画布中元件节点显示的子标题
subTitle?: (config?: Config, context?: MaterialContext) => string | undefined;
//对应解析引擎里的Activity名称,根据这个名字实例化相应的节点业务逻辑对象
activityName: string;
}
//物料分类,用于在工具栏上,以手风琴风格分组物料
export interface ActivityMaterialCategory<ComponentNode = unknown, NodeSchema = unknown, Config = unknown, MaterialContext = unknown> {
//分类名
name: string;
//分类包含的物料
materials: IActivityMaterial<ComponentNode, NodeSchema, Config, MaterialContext>[];
}
只要符合这个定义的物料,都是可以被注入设计器的。
在前面定义DSL的时候, INodeDefine 也有一个一样的属性是 activityName。没错,这两个activityName指代的对象是一样的。画布渲染dsl的时候,会根据activityName查找相应的物料,根据物料携带的信息展示,入图标、颜色、属性配置组件等。
在做前端物料跟元件的时候,为了重构方便,会把activityName以存在Activity的static变量里,物料定义直接引用,端口名称也是类似的处理。看一个最简单的节点,Debug节点的代码。
Activity代码:
```typescript
import { Activity, Input, AbstractActivity } from "@rxdrag/minions-runtime"
import { INodeDefine } from "@rxdrag/minions-schema"
//调试节点配置
export interface IDebugConfig {
//提示信息
tip?: string,
//是否已关闭
closed?: boolean
}
@Activity(DebugActivity.NAME)
export class DebugActivity extends AbstractActivity<IDebugConfig> {
//对应INodeDeifne 跟IActivityMaterial的 activityName
public static NAME = "system.debug"
constructor(meta: INodeDefine<IDebugConfig>) {
super(meta)
}
//入口处理函数
@Input()
inputHandler(inputValue: unknown): void {
if (!this.config?.closed) {
console.log(`🪲${this.config?.tip || "Debug"}:`, inputValue)
}
}
}
物料代码:
import { createUuid } from "@rxdrag/shared";
import { debugSchema } from "./schema";
import { NodeType } from "@rxdrag/minions-schema";
import { Debug, IDebugConfig } from "@rxdrag/minions-activities"
import { debugIcon } from "../../icons";
import { DEFAULT_INPUT_NAME } from "@rxdrag/minions-runtime";
import { IRxDragActivityMaterial } from "../../interfaces";
//debug节点物料
export const debugMaterial: IRxDragActivityMaterial<IDebugConfig> = {
//对应Activity的Name
activityName: Debug.NAME,
//Svg格式的表
icon: debugIcon,
//显示标题,工具栏直接多语言化后显示,画布上节点Title的初值是这个,可以通过
//属性面板修改
label: "$debug",
//节点类型,普通的Activity
activityType: NodeType.Activity,
//图标颜色
color: "orange",
//默认端口
defaultPorts: {
inPorts: [
{
id: createUuid(),
name: DEFAULT_INPUT_NAME,
label: "",
},
],
},
//子标题,显示配置用的tip
subTitle: (config?: IDebugConfig) => {
return config?.tip
},
//属性面板Schema
schema: debugSchema,
}属性面板schema的配置就不展开了,感兴趣的朋友请参考Rxdrag的相关文章。该节点在编辑器中的表现: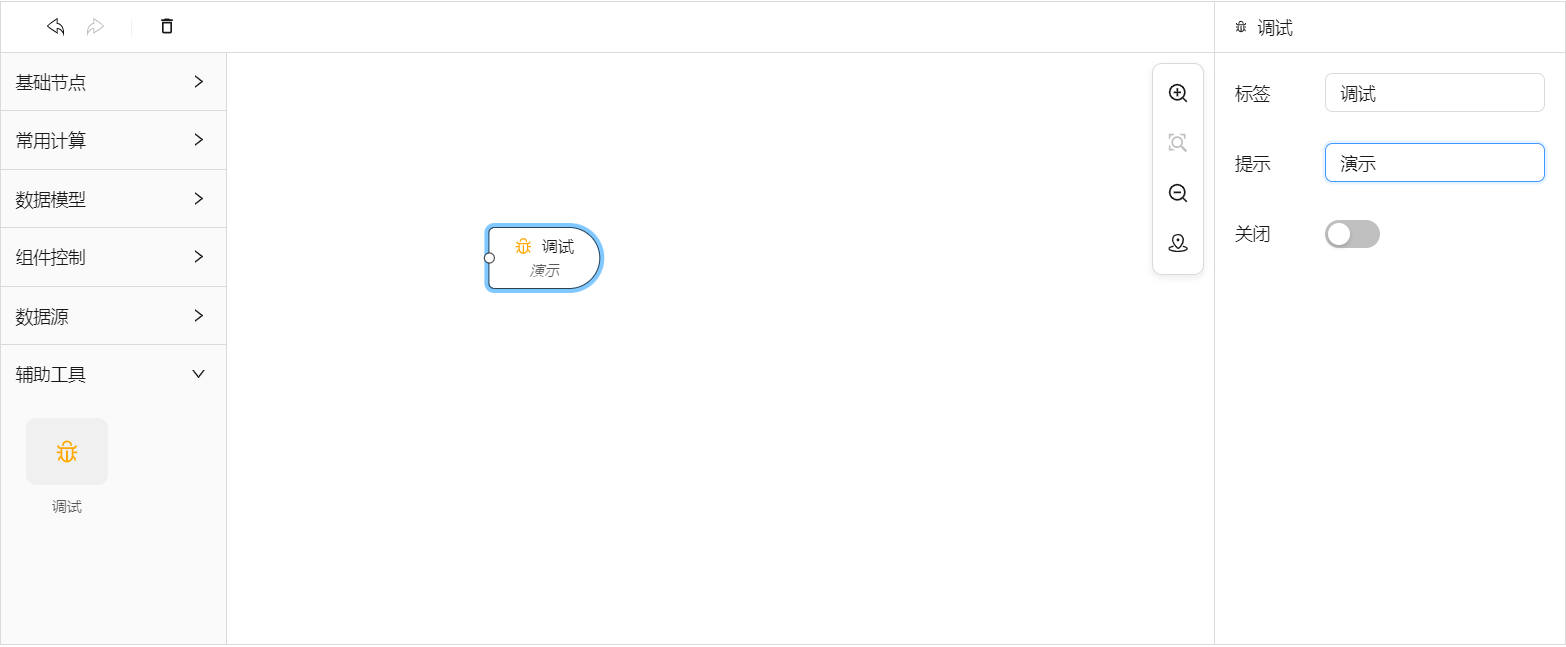
编辑器的状态管理
如果纯React应用的话,Recoil是不错的状态管理方案,幻想有一天可能会适配其它UI框架,就使用了对框架依赖较少的Redux作为状态管理工具。
编辑器所有状态:
import { INodeDefine, ILineDefine } from "@rxdrag/minions-schema";
//操作快照
export interface ISnapshot {
//全部节点
nodes: INodeDefine<unknown>[];
//全部连线
lines: ILineDefine[];
//当前选中元素
selected?: string,
}
//编辑器状态
export interface IState {
//是否被修改,该标识用于提示是否需要保存
changeFlag: number,
//撤销快照列表
undoList: ISnapshot[],
//重做快照列表
redoList: ISnapshot[],
//全部节点
nodes: INodeDefine<unknown>[];
//全部连线
lines: ILineDefine[];
//当前选中元素
selected?: string,
//画布缩放数值
zoom: number,
//是否显示小地图
showMap: boolean,
}编辑器就是围绕这份状态数据做功。建一个单独的类用来操作redux store:
//一个用来操作Redux状态数据的类,可以修改数据,也可以订阅数据的变化
export class EditorStore {
store: Store<IState>
constructor(debugMode?: boolean,) {
this.store = makeStoreInstance(debugMode || false)
}
dispatch = (action: Action) => {
this.store.dispatch(action)
}
//节省篇幅,本类不展开了,详细代码青岛rxdrag代码库查看
//地址:https://github.com/codebdy/rxdrag/blob/master/packages/minions/editor/logicflow-editor/src/classes/EditorStore.ts
...
}编辑器接口
编辑器被设计成一个React Library,方便其它项目的引用。其接口定义如下:
//主题颜色接口
export interface IThemeToken {
colorBorder?: string;
colorBgContainer?: string;
colorText?: string;
colorTextSecondary?: string;
colorBgBase?: string;
colorPrimary?: string;
}
//逻辑编排编辑器属性
export type LogicFlowEditorProps = {
value: ILogicMetas,
onChange?: (value: ILogicMetas) => void,
//编辑器支持的所有物料
materialCategories: ActivityMaterialCategory<ReactNode>[],
//属性面板用的的空间
setters?: IComponents,
logicFlowContext?: unknown,
//可以被引用的子编排
canBeReferencedLogflowMetas?: ILogicFlowDefine[],
//工具栏,false表示隐藏
toolbar?: false | React.ReactNode,
}
//逻辑编排编辑器对应的React组件
export const LogicMetaEditor = memo((
props: LogicFlowEditorAntd5rProps&{
token: IThemeToken,
}
) => {
...
}}深度集成的考量
编辑器有时候要跟其它编辑器,比如后端的领域模型编辑器深度集成,共享一套撤销、重做、删除按钮。比如: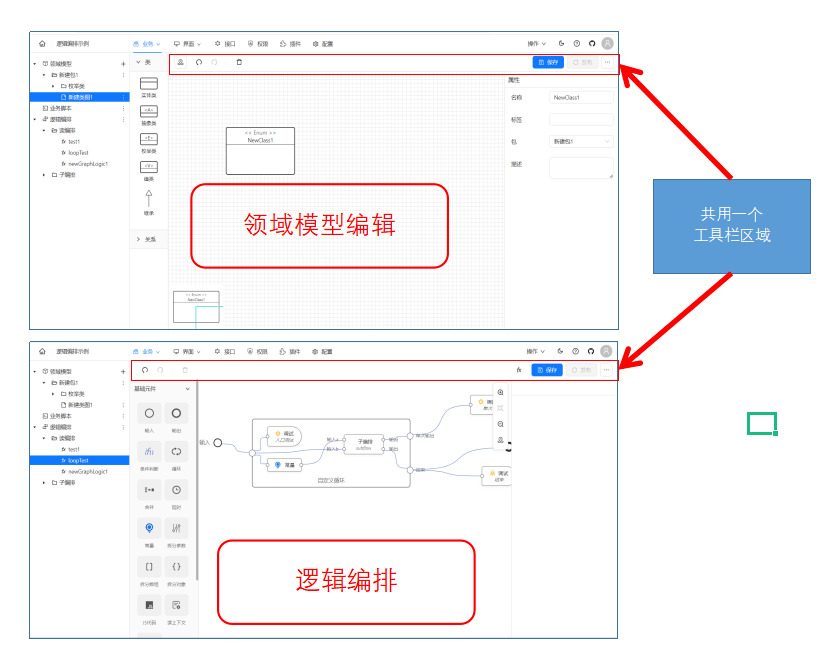
这种情况要通过给toolbar属性传入false,把编辑器原来的工具条隐藏掉。另外,要跟领域模型编辑器共用一个工具栏区域,需要在编辑器能在外部控制Redux store里面的内容。
为了实现这样的集成,添加一个上下文,用于下发一个全局的EditorStore。定义一个标签,叫LogicFlowEditorScope,用于限定逻辑编排编辑器的范围,只要是在标签内部,store数据可以随意修改。
import { memo, useMemo } from "react"
import { LogicFlowEditorStoreContext } from "../contexts";
import { EditorStore } from "../classes";
import { useEditorStore } from "../hooks";
//用于创建全局EditorStore,并通过Context下发
const ScopeInner = memo((props: {
children?: React.ReactNode
}) => {
const { children } = props;
const store: EditorStore = useMemo(() => {
return new EditorStore()
}, [])
return (
<LogicFlowEditorStoreContext.Provider value={store}>
{children}
</LogicFlowEditorStoreContext.Provider>
)
})
//编辑器Scope定义
export const LogicFlowEditorScope = memo((
props: {
children?: React.ReactNode
}
) => {
const { children } = props;
//去外层Store
const parentStore = useEditorStore()
return (
//如果外层已经创建Scope,那么直接用外层的,反之新建一个
parentStore ?
<>{children}</>
:
<ScopeInner>
{children}
</ScopeInner>
)
})这个LogicFlowEditorScope会在逻辑编辑器的根部放置一个,如果编辑器外部没有定义,就是用这个默认的。如果外部已经定义了,那么就用外部的。
领域模型编辑器集成的时候,只要在工具栏外层放置一个LogicFlowEditorScope,就可以方便的操作编辑器里的内容了:
import { memo } from "react"
import { UmlEditorInner, UmlEditorProps } from "./UmlEditorInner"
import { RecoilRoot } from "recoil"
import { LogicFlowEditorScope } from "@rxdrag/minions-logicflow-editor"
//领域模型UML编辑器部分
export const UmlEditor = memo((props: UmlEditorProps) => {
return <RecoilRoot>
//外层放置逻辑编排的Scope
<LogicFlowEditorScope>
<UmlEditorInner {...props} />
</LogicFlowEditorScope>
</RecoilRoot>
})
...
//创建逻辑编排编辑起的时候,toolbar赋值false
<LogicFlowEditorAntd5
materialCategories={activityMaterialCategories}
locales={activityMaterialLocales}
token={token}
value={value?.logicMetas || EmpertyLogic}
logicFlowContext={logicFlowContext}
onChange={handleChange}
setters={{
SubLogicFlowSelect,
}}
canBeReferencedLogflowMetas={canBeReferencedLogflowMetas}
//隐藏默认工具栏
toolbar={false}
/>
...前端逻辑编排
前端逻辑编排主要编排的内容是组件的联动,组件数据的填充以及服务端数据的获取及存储等内容。这些内容,就是一般被称作业务逻辑的内容。
通常的实现方式中,这些业务逻辑会与ui组件紧密结合,甚至很多被写在了组件内部。想让逻辑编排的适应能力更强,最好能够把这些内容从组件中剥离出来,形成独立的业务层,尽可能压缩UI层的厚度,UI层就像美女,瘦的总是比胖的好看些,如果不认同的话欢迎留言讨论。
像React这样的框架,组件有自己的生命周期管理,在低代码项目中,如果业务逻辑跟组件搅在一起,业务逻辑就跟组件的生命周期也搅在一起了,处理这样的代码,是非常痛苦的过程。
所以,有人喜欢mobx,可以不用过度关注React的生命周期。
mobx是把双刃剑,有有点也有缺点。如果用mobx做低代码平台,基本不好兼容现有的组件库,所有组件都要重新封装一层,就像formily做的那样。这样的方式不能说不好,只是小编不喜欢。就像姑娘,自己不喜欢的姑娘照样很多人抢,自己梦寐以求的姑娘,别人可能敬而远之。或许,这就是生活吧。百花齐放的世界里,可以肆意选择的感觉挺好。
组件控制器
想要ui层变瘦,就不要在组件内部加太多的业务逻辑,只是通过组件自身的props控制组件的行为,只需在组件外层加一个控制器,来控制组件的props就好。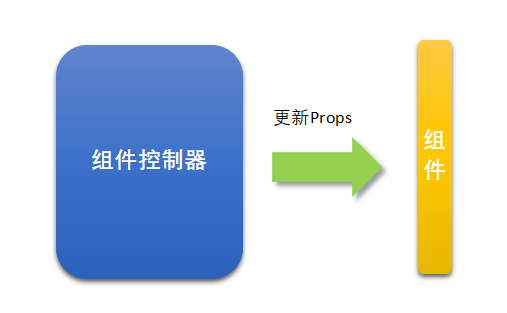
加入控制器以后,组件之间的交互联动,就变成了控制器之间的交互了,并且可以通过逻辑编排来编排这些控制器。
不同的实现方式,有不同的优点跟缺点。逻辑编排也一样,他可能并不适合所有的业务逻辑,对于CRUD这样简单的业务,逻辑编排反而显得笨重了。
不需要逻辑编排的场景,可能需要给组件配置一个其它的控制器。所以,组件控制器可以遵循相同的接口,并且可以有不同的实现: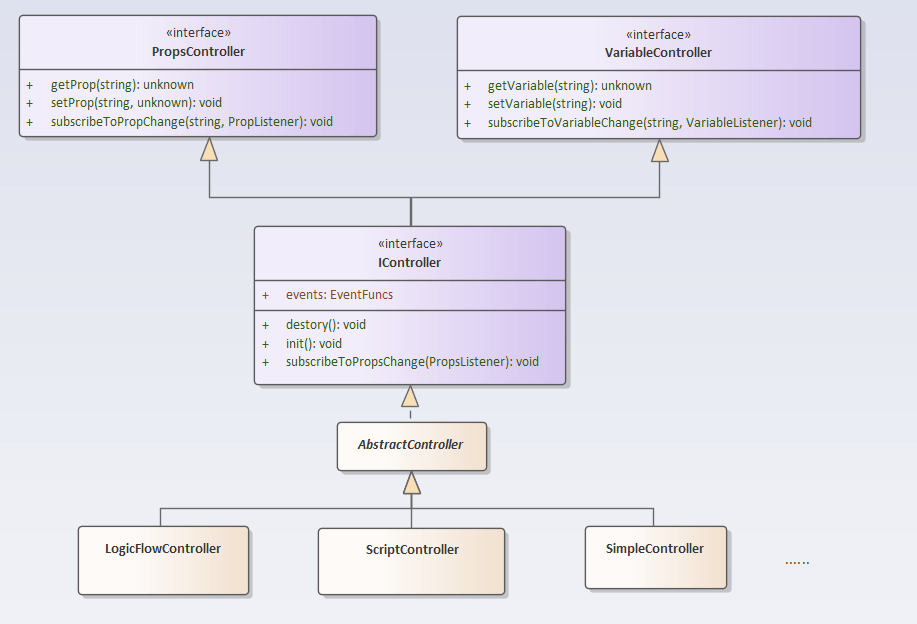
用了不少继承,这里也没必要争论该用继承还是该用组合,代码量不大,习惯了这样写。看不惯的朋友,可以用组合再实现一遍。
控制器IController接口实现了两个接口:属性控制器(IPropsController)跟变量控制器(IVariableController)。属性控制器用来管理组件的属性,这里的属性只是数值类型的属性,不包含函数类型的属性(也就事件),事件需要单独处理。变量控制器用来管理控制器的自定义变量,有点类似类的成员变量。也是不同控制器之间交换数据的重要手段。
不管是属性控制器还是变量控制器,都实现了相应的订阅(subscribe)方法,用于监听其变化,有点mobx之类的Proxy感觉,控制器监听到了Props的变化,会通过自身的subscribeToPropsChange方法发布出去,用于更新组件。要注意的是,属性控制器(IPropsController)的订阅方法订阅的是单个属性的变化,而这里订阅的是全部属性的变化,这里实现的内部使用了属性控制器(IPropsController)的subscribeToPropChange方法。
AbstractController是所有Controller的基类,封装了控制器的通用逻辑。
下面的三个控制器分别是:
- 逻辑编排控制器(LogicFlowController),顾名思义,用逻辑编排实现控制器的业务逻辑。这是框架内置控制器,
- 脚本控制器(ScriptController),用JS脚本实现控制器的业务逻辑。这也是框架内置控制器。
- 简单控制器(SimpleController),本控制器不是框架内置的,属于自定义控制器,放在了代码的Expamle部分(代码中可能叫ShortcutController)。因为有些简单的CRUD操作,几不需要编排控制器,也不需要脚本控制器,就定义这些简易控制器。还可以根据需要定义其它控制器,并把这些控制器注入到编辑器跟解析引擎。
控制器在Page Schema中的配置
前端逻辑编排的应用场景是低代码,低代码平台中,用DSL(通常是JSON Schema)来描述一个页面。这里以RxDrag的Schema定义为例,介绍控制器的配置,逻辑编排部分可以独立于Rxdrag运行,您可以用类似的方式整合到其它低码平台的Schema中。
RxDrag中组件元数据的定义:
泛型属性x-controller是控制器的DSL,在我们这里给它这样一个定义:export interface INodeMeta< IField = unknown, INodeController = unknown > { componentName: string; props?: { [key: string]: unknown; }; 'x-field'?: IField; //节点控制器,逻辑编排用 'x-controller'?: INodeController; //锁定子控件 locked?: boolean; //自己渲染,引擎不渲染 selfRender?: boolean; }import { ILogicFlowDefine } from "@rxdrag/minions-schema";
//控制器变量定义
export interface IVariableDefineMeta {
//变量标识
id: string;
//变量名称
name: string;
//变量默认值
defaultValue?: unknown;
}
//控制器元数据定义,相当于控制器配置的DSL
export interface IControllerMeta {
//控制器标识
id: string;
//控制器类型,因为控制器可以注入很多种,类型不固定,这里不能用枚举,只能用字符串
controllerType?: string;
//是否全局,配置控制器的可见范围
global?: boolean;
//控制器名称
name?: string;
}
//逻辑编排控制器
export interface ILogicFlowControllerMeta extends IControllerMeta {
//组件事件对应的逻辑编排,通过name与组件的事件建立联系
events?: ILogicFlowDefine[];
//控制器的交互,相当于子编排,可以被其他编排调用
reactions?: ILogicFlowDefine[];
//控制器的变量
variables?: IVariableDefineMeta[];
}
//脚本控制器
export interface IScriptControllerMeta extends IControllerMeta {
//脚本代码
script?: string
}
只给出了逻辑编排控制器跟脚本控制器DSL的定义,简易控制器跟框架实现关系不大,属于自定义控制器,这里就不深入展开了。
## 控制器与组件的绑定
低代码一般两种方式渲染页面:1、有一个渲染引擎,渲染页面DSL(通常是JSON);2、生成前端代码。
作者自己的低代码平台还没做出码,这里只讨论第一种情况。
低代码渲染引擎以组件节点为单位,递归渲染页面Schema:根据componentName拿到组件实现函数,并渲染。当渲染引擎解析到字段x-controller时,就在外面套一个高阶组件withController,在这个高阶组件里完成控制器与目标组件的绑定。
渲染引擎相关代码:
```typescript
export const ComponentView = memo((
props: ComponentViewProps
) => {
const { node, ...other } = props
//拿到组件定义函数
const com = usePreviewComponent(node.componentName)
//根据需要包装组件
const Component = useMemo(() => {
return com &&
withController(//通过高阶组件,绑定控制器与目标组件
com,
node["x-controller"] as ILogicFlowControllerMeta,
node.id,
)
}, [com, node]);
...
return (
Component &&
(
node.children?.length ?
<Component {...node.props} {...other}>
{
!node.selfRender && node.children?.map(child => {
return (<ComponentView key={child.id} node={child} />)
})
}
</Component>
: <Component {...node.props} {...other} />
)
)
})高阶组件内部的绑定代码:
export function withController(WrappedComponent: ReactComponent, meta: IControllerMeta | undefined, schemaId: string): ReactComponent {
if (!meta?.id || !meta?.controllerType) {
return WrappedComponent
}
return memo((props: any) => {
const [changedProps, setChangeProps] = useState<any>()
const [controller, setController] = useState<IController>()
//运行时引擎,通过它来创建控制器
const runtimeEngine = useRuntimeEngine();
//拿到controller对应的唯一标识
const controllerKey = useControllerKey(meta, schemaId)
const handlePropsChange = useCallback((name: string, value: any) => {
setChangeProps((changedProps: any) => {
return ({ ...changedProps, [name]: value })
})
}, [])
useEffect(() => {
if (meta?.controllerType && runtimeEngine && controllerKey) {
//创建控制器
const ctrl = runtimeEngine.getOrCreateController(meta, controllerKey)
//初始化
ctrl.init(controllers, logicFlowContext);
//订阅属性变化
const unlistener = ctrl?.subscribeToPropsChange(handlePropsChange)
setController(ctrl)
return () => {
ctrl?.destory()
unlistener?.()
}
}
}, [controllerKey, handlePropsChange, runtimeEngine])
const newProps = useMemo(() => {
//组装最新的Props,注意,组件的事件也在这里完成的绑定
return { ...props, ...controller?.events, ...changedProps }
}, [changedProps, controller?.events, props])
return (
controller
//通过上下文下发Controller,这样可以在组件内拿到Controller
//只是应对特例,因为只有极少情况需要在组件内部调用Controller
? <ControllerContext.Provider value={controller}>
//最新的Props传入目标组件
<WrappedComponent {...newProps} />
</ControllerContext.Provider>
: <>Can not creat controller </>
)
})控制器的可见范围
上面只完成了一个控制器,并且这个控制器是孤立的,并没有跟其他控制器发生关系。想要发生关系,控制器就不能是孤立的,需要相互认识(一方知道另一方的引用,或者一方知道另一方的查找方法)。
让控制器相互知道的方式有:
1、全部控制器注册到一个全局变量里面,所有控制器都能访问这个变量;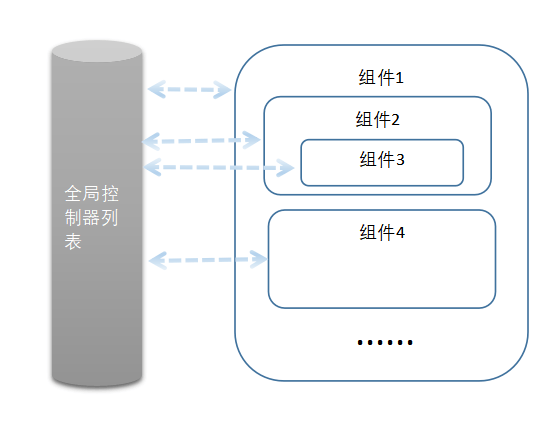
2、通过Context下发控制器,子组件的控制器能访问所有的父组件的控制器,父组件的控制器访问不了子控件的控制器。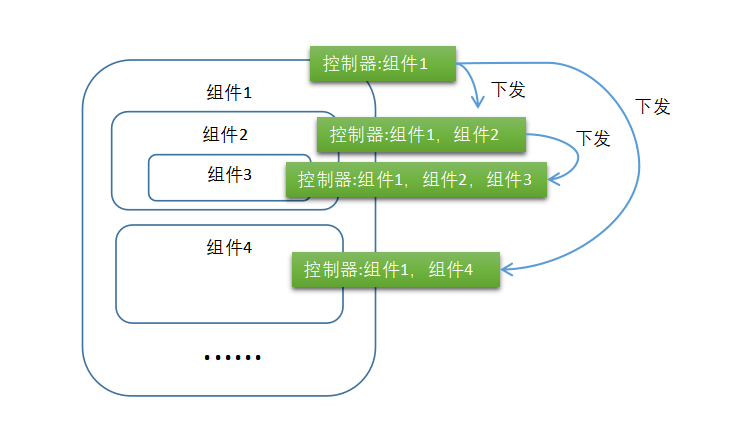
3、前两种方式的组合,默认通过第二种方式传递控制器,如果控制器在设计其中被配置为全局,则按照第一种方式传递。
第一种方式已经很直观了,为什么还要考虑第二种跟第三种?或者说压根忘掉第二种,直接用第一种。
答案是低代码平台的组件设计是否支持,就是跟低代码平台的组件设计理念相关。作者本人是业余选手,项目经验不多,不知道哪种方案更合理。就把可能的情况罗列一下,有观点朋友欢迎留言给点意见,不胜感激。
原子化组件设计
不同的低代码平台,组件的设计粒度是不一样的。作者自己的的低码平台,提倡的是原子化的组件设计,很多组件的设计粒度很细。这种情况下,不可能每个组件都附加一个控制器,很多组件只是用来调整页面布局,根本不需要控制器。
所以,在前端配置页面,加了控制器选择组件,用于指示给组件启用哪种类型的控制器: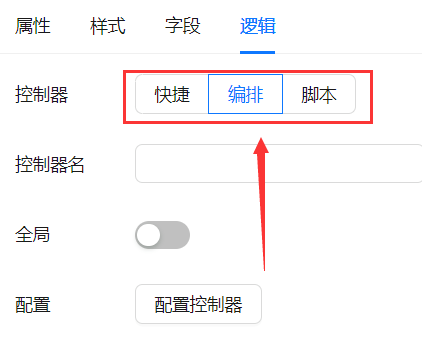
这个单选按钮组,是可以不选的,不选时意味着不需要给组件配置控制器。
原子化组件设计,组件的粒度很细,细到列表也是有各种组件组合而成,列表内的组件是可以随意拖入的,比如下面这个列表行中的“编辑”、“删除”按钮: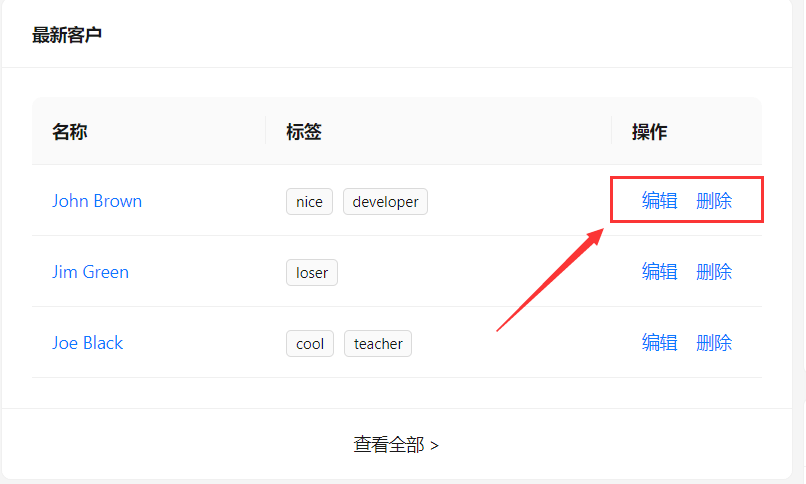
这些行组件是根据数据行记录而动态创建的,原子化的设计对这些列表没有太多的封装,所以无法从全局拿到这些动态创建组件的控制器。
在这种情况下,通过context下发控制器是个不错的选择,所有子组件的控制都可以访问父组件控制器。部分需要全局共享的控制器,就在界面中配置为全局。这两种方式结合,基本可以满足控制器之间的交互需求。
高阶组件withController的实现代码变成:
import { ReactComponent } from "@rxdrag/react-shared"
import { memo, useCallback, useEffect, useMemo, useState } from "react"
import { ControllerContext, ControllersContext } from "../contexts"
import { useControllers } from "../hooks/useControllers"
import { Controllers, IController, ILogicFlowControllerMeta as IControllerMeta } from "@rxdrag/minions-runtime-react"
import { useLogicFlowContext } from "../hooks/useLogicFlowContext"
import { useRuntimeEngine } from "../hooks/useRuntimeEngine"
import { useControllerKey } from "../hooks/useControllerKey"
export function withController(WrappedComponent: ReactComponent, meta: IControllerMeta | undefined, schemaId: string): ReactComponent {
if (!meta?.id || !meta?.controllerType) {
return WrappedComponent
}
return memo((props: any) => {
//发生变化的props
const [changedProps, setChangeProps] = useState<any>()
//组件自身的控制器
const [controller, setController] = useState<IController>()
//所有上级控制器+全局控制器
const controllers = useControllers()
//管理控制器的运行时引擎
const runtimeEngine = useRuntimeEngine();
//控制器唯一标识,根据层级关系跟控制器本身ID组合产生,用于唯一标识一个控制器
const controllerKey = useControllerKey(meta, schemaId)
//处理控制器中的props变化
const handlePropsChange = useCallback((name: string, value: any) => {
setChangeProps((changedProps: any) => {
return ({ ...changedProps, [name]: value })
})
}, [])
useEffect(() => {
if (meta?.controllerType && runtimeEngine && controllerKey) {
//给组件创建控制器
const ctrl = runtimeEngine.getOrCreateController(meta, controllerKey)
//初始化控制器
ctrl.init(controllers);
//监听props变化
const unlistener = ctrl?.subscribeToPropsChange(handlePropsChange)
setController(ctrl)
return () => {
ctrl?.destory()
unlistener?.()
}
}
}, [controllerKey, controllers, handlePropsChange, runtimeEngine])
//把该组件可见的控制器打包成一个数组
const newControllers: Controllers = useMemo(() => {
return controller ? { ...controllers, [controller.id]: controller } : controllers
}, [controller, controllers])
//最新的props
const newProps = useMemo(() => {
return { ...props, ...controller?.events, ...changedProps }
}, [changedProps, controller?.events, props])
return (
controller
? <ControllersContext.Provider value={newControllers}>
<ControllerContext.Provider value={controller}>
<WrappedComponent {...newProps} />
</ControllerContext.Provider>
</ControllersContext.Provider>
: <>Can not creat controller </>
)
})
}
这种实现方式其实已经足够灵活了,能够应对几乎常见的需求,但是,比起后面的粗粒度组件设计,用户体验确实要差一些,用户需要理解的概念有点多,需要配置的东西也有点多。
当然,实际的项目中,从列表外面访问列表行内组件的场景几乎没有,所以只要把外围的组件控制器放入全局,供列表内组件使用,也是可以的。这样,就不需要context了,但是这样应对不了列表套列表的情况。或许列表套列表的情况不多吧。
小编也想用户体验更好些,但是做起来就不由自主的兼顾了更多的灵活性,可能把最终用户当成自己了吧。后面可能需要更多的在项目中磨练自己,有跟作者方向一致的朋友,欢迎联系作者,我们可以一起做一些项目相互学习、共同成长。
粗粒度组件设计
粗粒度组件的设计,会带来非常良好的用户体验。
这是跟原子化组件完全不同的设计理念,每个组件的功能比较多,一个页面仅需要非常少的组件就能完成。
既然组件较少,每个组件配置一个控制器(或者类似控制器的东西),把这些控制器设置为全局,逻辑编排的时候,这些全局控制器可以相互调用,直观方方便。
粗粒度的组件,同样会有列表,列表要如何处理呢?
可以把列表做成功能全面的组件,行内组件以卡槽的方式插入列表。这种情况下,自然的会假设没有编排列表套列表这样的变态需求。
逻辑编排编辑器设计的时候,可以直接从物料箱(工具箱)选择组件控制器,进行编排。
在上文中,我们只定义了基础的IController接口,实现了基础的抽象类AbstractController。AbstractController下面派生出来的子类,不管是逻辑编排控制器还是脚本控制器,都没有实现太多的业务逻辑,而是把业务逻辑留给了逻辑编排或者脚本来完成。
既然组件的粒度变粗了,必然是包含了某些业务逻辑。可以把这些逻辑重新还给组件,让每个组件或者组件的控制器包含自己的业务逻辑。
粗粒度组件更友好的编排方式
控制器,是软件设计实现层面的东西,最终用户可能不需要关心这样的实现细节。控制器这个概念的添加,无疑会增加用户的理解成本。对用户来讲,最直观的理解对象是组件。
在逻辑编排中,如果以组件而不是控制器为编排对象,会更加有利于用户的理解,比如: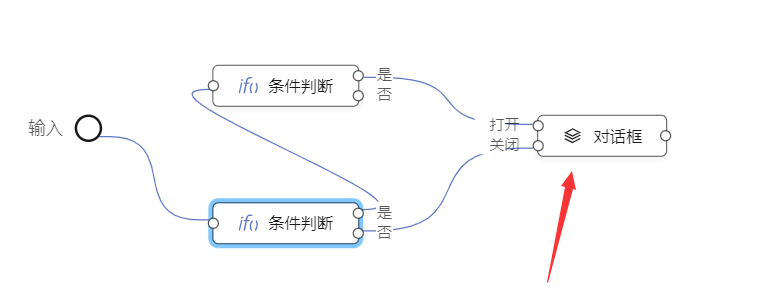
图中对话框的这个元件节点,是不是更直观,更容易理解?
在我们已经设计的架构体系里,能实现这样的效果?
当然可以,并且可以继续用控制器(通用控制器或者特殊控制器都行),加入有个通用控制器叫DefaultController,它是AbstractConroller的一个子类,实现了常用的控制器功能。可以为对话框组件,定制一个单独的元件节点,节点保有组件控制器DefaultController的一个引用就可以: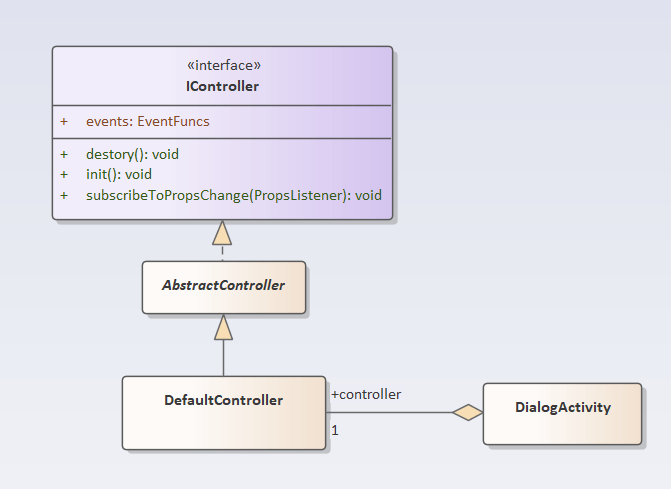
给DialgoActivity配置上相应物料,就可以以组件的面貌参与逻辑编排了,虽然内部基于控制器IController实现,但用户是感知不到IController存在的。元件物料定义:
//上下文中的控制器参数
export interface IControllerEditorContextParam {
//所有能访问的控制器
controllers?: ILogicFlowControllerMeta[],
//当前组件控制器
controller?: ILogicFlowControllerMeta,
}
export const dialogMaterial: IRxDragActivityMaterial<IPropConfig, IControllerEditorContextParam> = {
icon: dialogIcon,
label: "对话框",
activityType: NodeType.Activity,
defaultPorts: {
inPorts: [
{
id: createUuid(),
name: DialogAtivity.PORT_OPEN,
label: "打开",
},
],
outPorts: [
{
id: createUuid(),
name: DialogAtivity.PORT_CLOSE,
label: "关闭",
},
],
},
//属性面板Schema
schema: dialogSchema,
//副标题显示具体哪个对话框
subTitle: (config?: IPropConfig, context?: IControllerEditorContextParam) => {
const controllerName = context?.controllers?.find(controler => controler.id === config?.param?.controllerId)?.name
return controllerName ? (controllerName + "/" + (config?.param?.prop || "")) : ""
},
activityName: DialogAtivity.NAME,
}
DialogActivity的定义大致如下(作者没做粗粒度组件,故以下代码不来自真实代码,只是示意):
export interface IControllerContext {
controllers: Controllers,
}
export interface IControllerParam {
controllerId?: string
}
export interface IDialogConfig {
param?: IControllerParam
}
@Activity(DialogActivity.NAME)
export class DialogActivity extends AbstractActivity<IDialogConfig> {
public static NAME = "dialog"
public static PORT_OPEN = "open"
public static PORT_CLOSE = "close"
//组件控制器
controller: IController
constructor(meta: INodeDefine<IDialogConfig>, context?: IControllerContext) {
super(meta, context)
if (!meta.config?.param?.controllerId) {
throw new Error("ReadProp not set controller id")
}
const controller = context?.controllers?.[meta.config?.param?.controllerId]
if (!controller) {
throw new Error("Can not find controller")
}
this.controller = controller
}
@Input(DialogActivity.PORT_OPEN)
openHandler = () => {
this.controller.setProp("open", true)
}
@Input(DialogActivity.PORT_CLOSE)
closeHandler = () => {
this.controller.setProp("close", true)
}
}
朋友,读到这里,业务逻辑跟ui层解耦的魅力,您体会到了吗?
前端逻辑编排编辑器
Rxdrag项目中,前端编辑器的项目构成:
整个逻辑编排功能分为两个顶层包:
- minions,包含逻辑编排运行时、设计器跟DSL定义(schema),本包不依赖antd,就是说如果你的项目不想引入antd或者说antd的版本跟作者不一样,可以使用这个包,但不能使用下面另一个包。
- minions-antd5,跟antd5相关的部分,全部都在这个包里,这个包大部分都是设计器相关的东西,运行时相关的东西仅包含Activity的定义。
具体每个包的详细解释:
minions
-editor 编辑器相关,可能会依赖runtime包。
-controller-editor 控制器编排编辑器。包含了对组件控制器的编排,主要用于前端,基于下面的logicflow-editor实现。
-logicflow-editor 最基础的逻辑编排编辑器,不包含前端控制器编排相关内容。后端编排编辑器可以基于这个实现。
-runtime 运行时,逻辑编排的解析引擎相关,不依赖于editor包的任何东西。
-activities 预定义的Activities,也就是元件节点的实现逻辑。比如循环、条件等
-runtime-core 逻辑编排解析引擎核心包,react无关。
-runtime-react 逻辑编排解析引擎react相关部分,包括控制器相关内容。
minions-antd5,
-controller-editor-antd5 控制器编排编辑器,依赖antd5,依赖logicflow-editor-antd5
-logicflow-editor-antd5 普通编排编辑器,依赖antd5
-minions-react-antd5-activites antd5相关的Activities
-minions-react-materials 物料定义,这些物料的实现依赖antd5和rxdrag低代码引擎部分。
具体代码实现内容不少,感兴趣的话自行翻代码库看看吧,篇幅所限,无法进一步展开了。
控制器的注入
本节内容只是针对原子化组件低代码平台的,并未考虑粗粒度组件,粗粒度组件不需要注入控制器,只需要使用DefaultController就可以。
低代码平台中,逻辑编排的配置是以属性配置组件的形式出现的: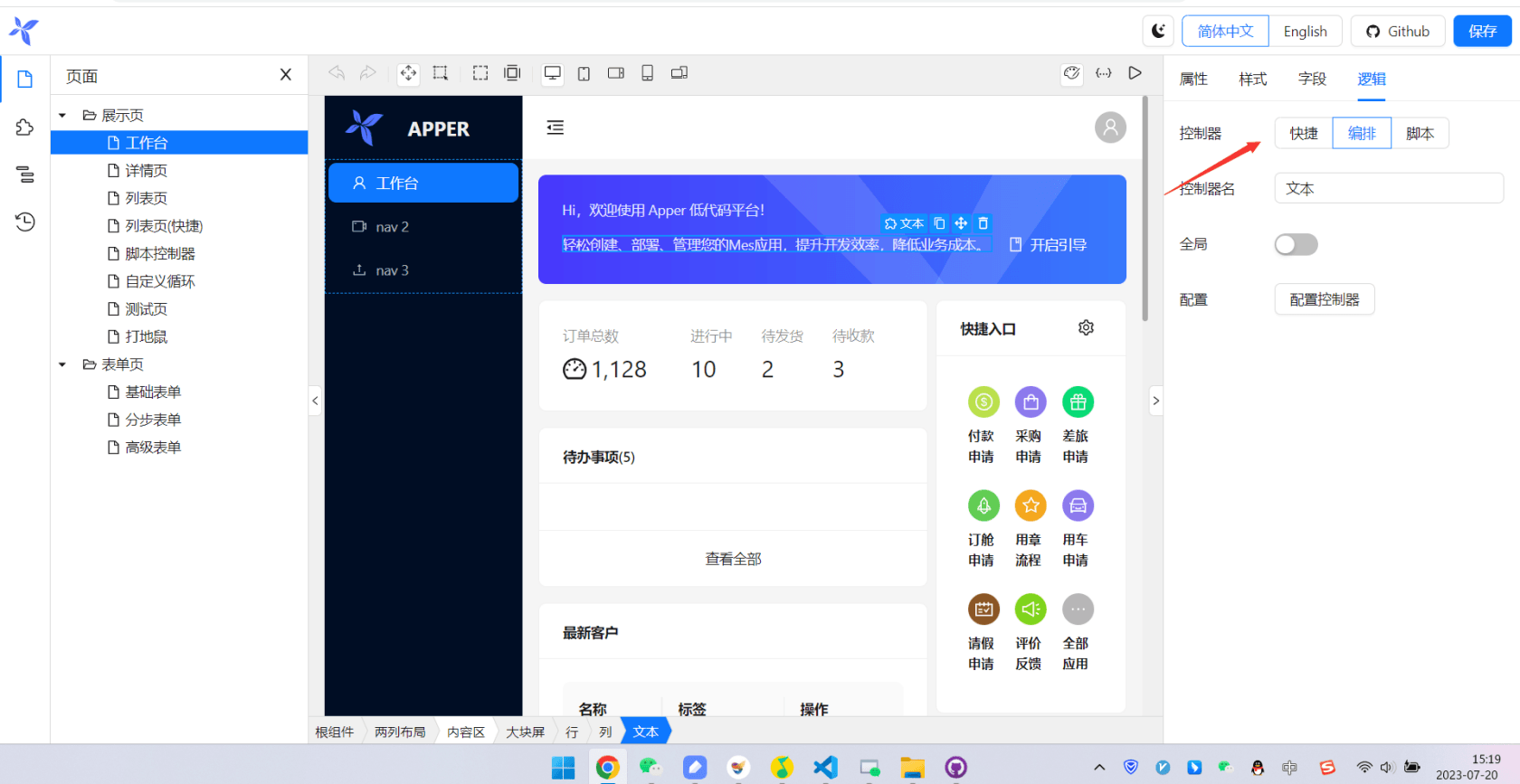
这些控制器是可以注入的,这个跟具体低代码平台的实现机制有关,这里只是提一下思路,根本文主题关系不大,就不详细展开了。
后端逻辑编排
后端逻辑编排的设计器使用的是logicflow-editor-antd5这个包,编辑器部分的实现跟前端逻辑编排基本一致。本节主要讨论后端解析引擎的实现。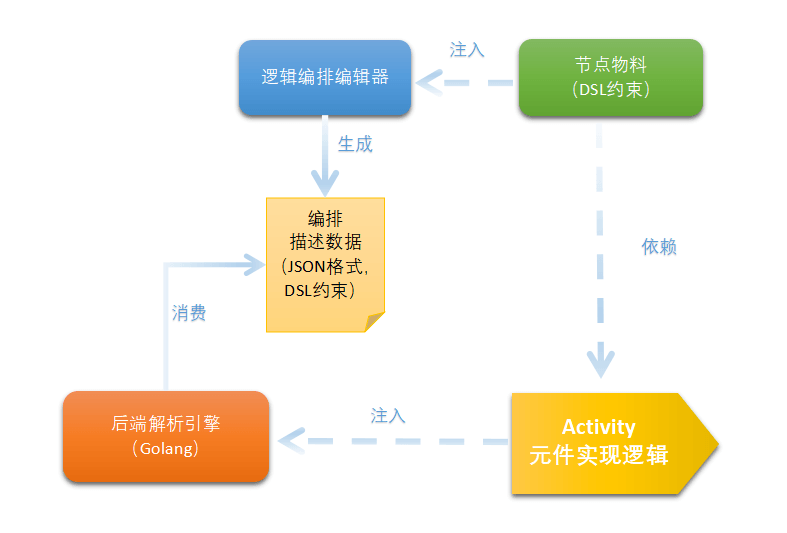
前端定义元件节点物料,把物料注入逻辑编排编辑器。后端定义元件实现逻辑(Activity),把Activity注入后端编排解析引擎。节点物料依赖Activity,通过activityName关联。
逻辑编排编辑器生成产物是JSON格式的编排描述数据,后端引擎消费这个JSON,转化成具体的执行逻辑。
逻辑编排解析引擎的代码量并不大,相当于把前面讨论的Typescript实现转译为一份golang的实现。项目代码结构: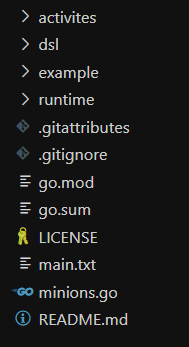
这是一个golang library,可以在其他golang项目中被引用,作者在自己的低代码平台中,使用了这个库。代码结构关键部分:
- activities,预定义元件的实现逻辑。
- dsl,就是上面Typescript定义的那份DSL,这里转译成Golang。
- example,该库使用例子,后面会实现,现在还没有。
- runtime,逻辑编排解析引擎。
DSL转译
//端口定义 type PortDefine struct { //ID Id string `json:"id"` //名称 Name string `json:"name"` //标题 Label string `json:"label"` }
//线的连接点
type PortRef struct {
//节点ID
NodeId string json:"nodeId"
//端口ID
PortId string json:"portId"
}
//连线定义
type LineDefine struct {
Id string json:"id"
//源节点
Source PortRef json:"source"
//目标节点
Target PortRef json:"target"
}
//节点定义
type NodeDefine struct {
Id string json:"id"
//名称
Name string json:"name" //嵌入编排,端口转换成子节点时使用
//节点类型,对应Typescript的枚举
Type string json:"type"
//元件对应Activity名称
ActivityName string json:"activityName"
//标题
Label string json:"label"
//配置
Config map[string]interface{} json:"config"
//入端口
InPorts []PortDefine json:"inPorts"
//出端口
OutPorts []PortDefine json:"outPorts"
//子节点,嵌入式节点用,比如自定义循环节点、事务节点
Children LogicFlowMeta json:"children"
}
//一段逻辑编排
type LogicFlowMeta struct {
//所有节点
Nodes []NodeDefine json:"nodes"
//所有连线
Lines []LineDefine json:"lines"
}
//子编排,可以被其它编排调用
type SubLogicFlowMeta struct {
//组合一段编排数据
LogicFlowMeta
//用于调用寻址
Id string
}
就是简单定义,没有什么需要特殊解释的。
## Activity的实现
在前端编排引擎的实现中,我们用了放射中的注解来收集Ativity跟它的端口处理函数。golang中并没有注解,并且也没有办法通过Struct的名字拿到Struct。这部分,就不得不做一些变通的处理。
第一次尝试,充分利用泛型,使用工厂方法,在runtime模块定义一个注册工厂方法的函数:
```go
//注册工厂方法,用于创建Activity实例
func RegisterActivity(name string, factory interface{}) {
activitiesMap.Store(name, factory)
}
//工厂方法的泛型
func NewActivity[Config any, T Activity[Config]](meta *dsl.ActivityDefine) *T {
var activity T
activity.GetBaseActivity().Init(meta)
return &activity
}Activity相应的实现方式:
type DebugConfig struct {
Tip string `json:"tip"`
Closed bool `json:"closed"`
}
type DeubugActivity struct {
BaseActivity runtime.BaseActivity[DebugConfig]
}
func init() {
//注册工厂函数
runtime.RegisterActivity(
"debug",
//把泛型定义的工厂方法实例化为具体方法
runtime.NewActivity[DebugConfig, DeubugActivity],
)
}
func (d* DeubugActivity) GetBaseActivity() *runtime.BaseActivity[DebugConfig] {
return &d.BaseActivity
}
这个实现方式能够正常运行,并且引擎代码相对简单。但是,实现一个Activity的代码看起来有些复杂,增加了用户的心智负担,还是希望Activity的定义能够更简单些。
最后,放弃了泛型,具体类型由引擎通过反射来识别,注册时只传入一个Activity实例,Activity的复杂度,转移到了引擎内部:
type DebugConfig struct {
Tip string `json:"tip"`
Closed bool `json:"closed"`
}
type DebugActivity struct {
Activity runtime.Activity[DebugConfig]
}
func init() {
runtime.RegisterActivity(
"debug",
DebugActivity{},
)
}是不是看起来简单多了?
端口与端口处理函数的绑定
golang没有注解,不能像Typescript那样,通过注解把端口跟端口处理函数关联起来。但是golang有反射,通过一个变量,能够拿到变量的类型,并且创建另一个同类型的实例。通过方法名称,能够拿到并调用这个实例上的方法。所以,不需要注解,可以直接通过端口名字调用对应端口处理函数,只要端口名字跟端口处理函数的名字一致(首字母大小写不敏感),这些都是在框架内完成的。
上面Debug对应的input端口处理函数,不需要任何额外处理,直接这么写,框架能自动完成绑定,下面这个函数会被自动绑定到input入端口:
func (d *DebugActivity) Input(inputValue any, ctx context.Context) {
config := d.Activity.GetConfig()
...
}编排引擎的详细实现原理这里就不展开了,感兴趣的话请参考上面的前段编排引擎部分吧。
对接函数参数的处理
在前端,一个编排对应的是组件的一个事件,事件是一个函数,事件的参数会以数组的形式传给入口的inputValue,使用的时候用数组拆分元,把参数拆出来使用: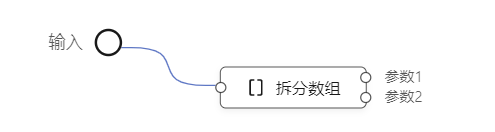
组件函数的参数,没有名字信息不能转成map:
//这种方式使用函数,参数没有名字信息,只有顺序信息
(...args: unknown[]) => inputOne.push(args)在后端,作者把一个逻辑编排对应一个graphql接口(field),它的参数是map,没有顺序信息,不能转成数组,只能用对象拆分元件来拆分参数: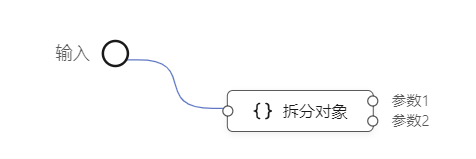
是的,你没看错,同样是参数分解,前后端不一致了,可能会给用户造成困扰。
目前想了一个折中的办法,不管是前端编排还是后端编排,都建一个名字是“参数分解”的元件,只是后端是基于对象拆分实现,前端是基于数组拆分实现。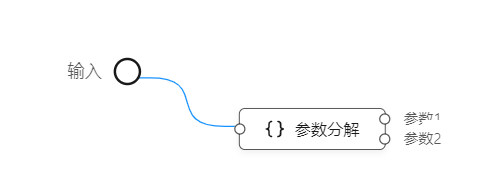
后端的逻辑编排的集成
在低代码平台中,后端的逻辑编排要跟后端其它服务集成在一起,有两种实现方式:
- 逻辑编排是单独的服务
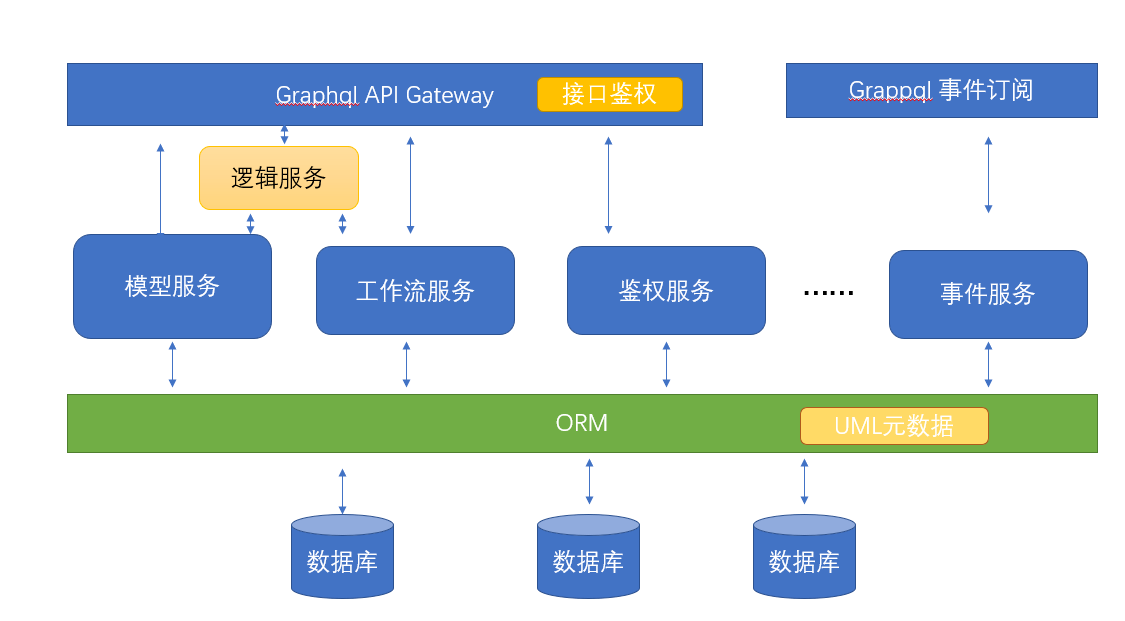
- 逻辑编排跟模型服务集成在一起
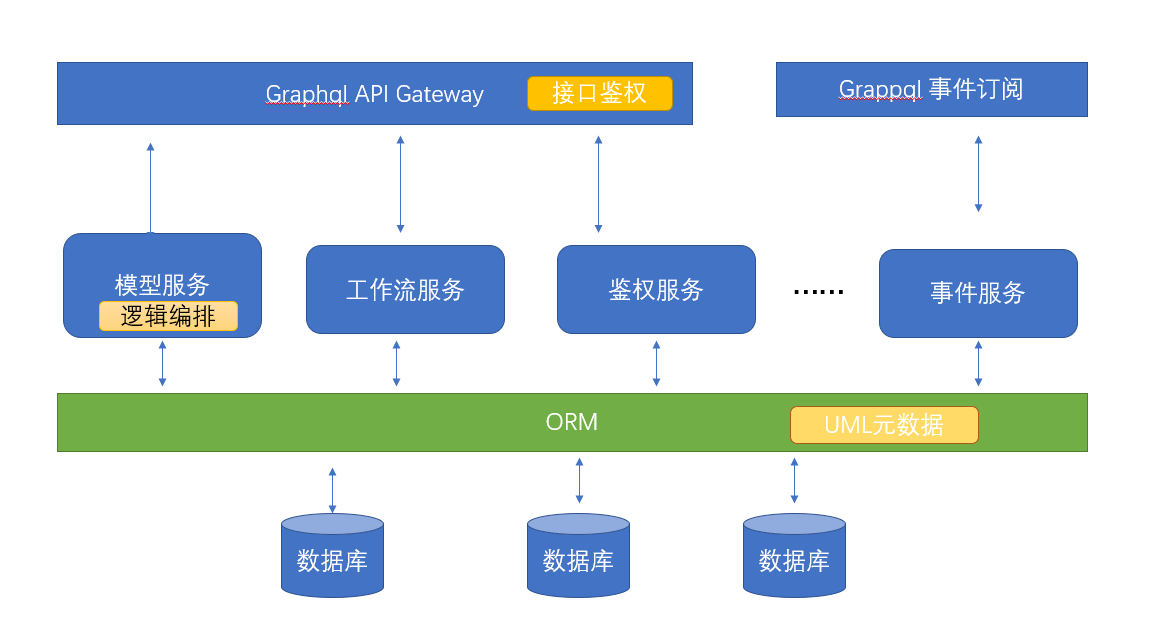
这两种实现方式,小编倾向于后者。理由有两个:
- 逻辑编排独立成一个微服务,更加了事务编排的难度
- 逻辑编排独立成微服务,不方便给编排添加后面说的类型系统。
展望未来
逻辑编排的介绍接近尾声了,虽然洋洋洒洒2w字,感觉还是浅尝辄止,很多内容没有深入下去,实际代码相比文章还是要复杂些,感兴趣的朋友欢迎翻阅代码并交流。
文中并没有涉及逻辑编排中的一个重要内容,类型约束。有了类型约束,用户编排的效率会提高很多,出错的概率会降低很多。类型可以编辑器增加智能提示,输入限制,给解析引擎的类型转换提供支持。
接下来,会以UML类图的形式,给自己的低代码平台提供领域模型。这个领域模型,贯穿模型前后端,并衍生出一套类型系统,附加到低代码的各个部分,自然也会附加到逻辑编排这部分。类型系统的思路,来自大佬徐飞的一篇文章。
今年写了两篇长文,一篇是《实战,一个高扩展、可视化低代码前端,详实、完整》还有一篇就是本文。上一篇重点在可视化编辑部分,本篇重点是逻辑编排。还欠缺页面的数据模型部分,会在不远的将来补上。总结
本文主要写了数据流驱动的逻辑编排运行原理、编辑器、解析引擎等内容,涵盖前端编排跟后端编排。虽然质量不怎么样,但是却是用心在写,前后花了一个星期的时间。希望能给需要的朋友一点帮助或者启发,价值便是我的动力所在。
有不同意见的朋友欢迎留言讨论,没事找事的朋友,欢迎来战。感谢
感谢板砖团队的MyBricks产品,它提供了宝贵的思路,让Rxdrag的逻辑编排部分得以完成。
感谢网友陌路及其团队成员提供的支持,每次迷茫的时候,跟他们讨论一下,总会有一种豁然开朗的感觉。
感谢网友青铜提供支持,正是因为他的鼎力相助,才能让我这个环境小白成功的做了一个Monorepo项目。
感谢一致以来关注跟支持我的朋友,朋友们的支持给了我莫大的鼓励,希望在未来的日子里,我们还能相互陪伴一起走的更远。
最后,感谢CCTV,虽然不知道它做了什么,但是总觉还是要提前感谢一下,说不定它某一天真能做些什么。
希望在以后的日子里,帮到的人越来越多。也希望以后文章的感谢列表越来越长。
本作品采用《CC 协议》,转载必须注明作者和本文链接















 关于 LearnKu
关于 LearnKu




推荐文章: