
GO内存模型(同步机制)
0 / 0 / 创建于 3年前 /
 ycp 的个人博客
ycp 的个人博客
@[TOC]
概念
1. 先行发生
The happens before relation is defined as the transitive closure of the union of the sequenced before and synchronized before relations.
翻译:
happens before关系被定义为序列化before关系和同步化before关系的联合的传递闭包。
解析:
- happens before关系描述两个事件之间的先后顺序
- 序列化before关系表示单个goroutine内事件间的顺序
- 同步化before关系表示不同goroutine间由同步原语同步的顺序
- happens before关系是上述两个关系的联合
- 传递闭包表示如果A happens before B,B happens before C,那么A happens before C
可以理解为程序的执行顺序,在单个协程当中,程序先行发生的顺序就是程序表达的顺序
举个例子:
var a string
func hello() {
a = "hello, world"
print(a)
}我们说a = "hello, world",先行发生于print(a)。
var a string
func f() {
print(a)
}
func f2() {
a = "hello, world"
}
func hello() {
go f()
go f2()
}在多个协程对共享变量的读写中,为了保证读写的正确性,我们需要引入同步机制保证程序的顺序一致性执行。比如channel,sync、atomic package。在上面的例子中f()有可能打印空字符串或者"hello, world",随机的。print(a)不先行发生于a赋值,a赋值也不先行发生于print(a),我们就说这是并发的。我们应该如何保证f2的写入一定能被f()看到呢?这就是我们要讨论的内容。
编译器重排

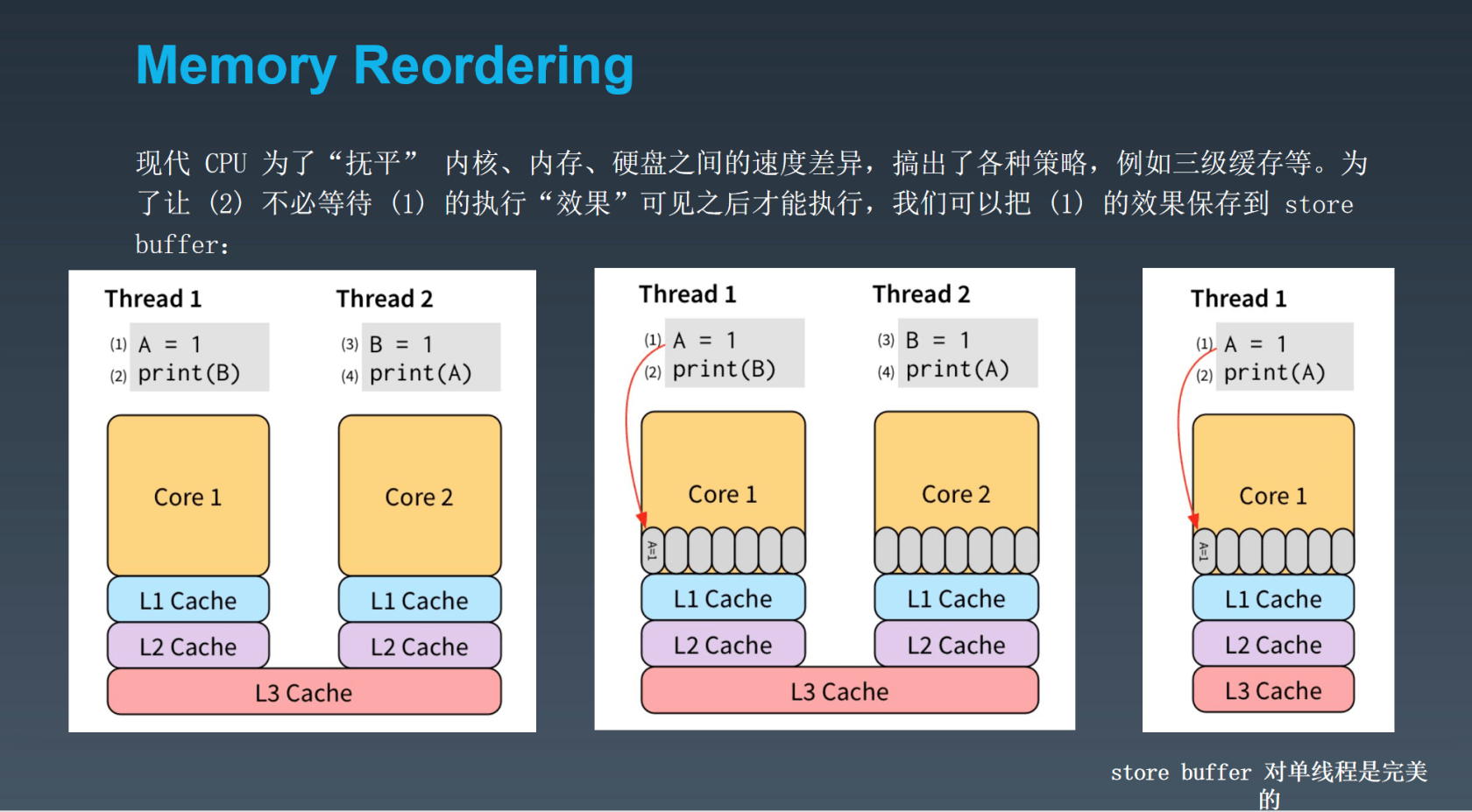
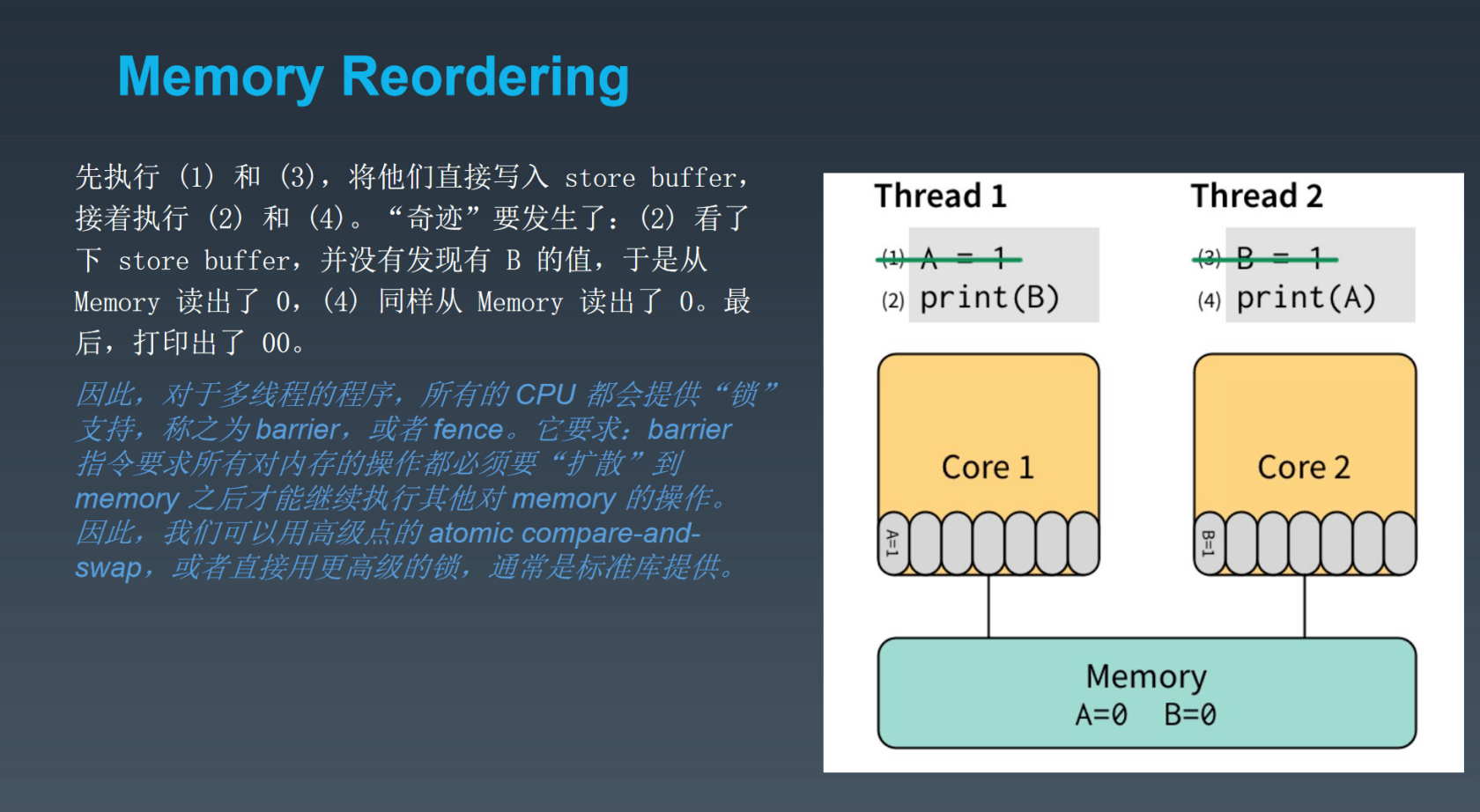
同步机制
以下是一些我们会用到的让程序保证顺序一致性执行的一些常用手段
init函数
一个函数的初始化函数可能在单个goroutine中执行,但是执行过程中有可能会开启另外一个协程并发执行,这时:
p引入包q,q的init函数结束先行发生于q的所有init函数的开始
所有的init函数执行完了才会执行main函数
协程的创建
新协程的创建先行发生与该协程的执行
var a string
func f() {
print(a)
}
func hello() {
a = "hello, world"
go f()
}这里f()一定能打印"hello, world",因为a的赋值先行发生于协程的创建,而协程的创建先行发生于函数的执行。
var a string
func f() {
print(a)
}
func hello() {
go f()
a = "hello, world"
}如果我们调整顺序
var a string
func f() {
print(a)
}
func hello() {
go f()
a = "hello, world"
}结果是随机的
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
hello, world
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
hello, world
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
hello, world
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
hello, world
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
hello, world
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
PS E:\code\go\go_study\advanced\memery_model> go run memery.go
hello, world也就是说gorountine 的退出不会保证先行发生于程序的任何事件
channel
- 无缓冲channel
当我们创建的chan 不带缓冲,chan的接收先行发生于chan的发送
var c = make(chan int)
var a string
func f() {
a = "hello, world"
<-c
}
func main() {
go f()
c <- 0
print(a)
}<-c先行发生于c <- 0,所以a一定能打印"hello, world"
- 带缓冲chanel
当我们创建的chan 带缓冲,当缓冲未满的时候,chan的发送先行发生于chan的接收。当缓冲满了,chan的接收先行发生于chan的发送
var c = make(chan int, 10)
var a string
func f() {
a = "hello, world"
c <- 0
}
func main() {
go f()
<-c
print(a)
}c <- 0先行发生于<-c,所以a一定能打印"hello, world"
容量为c的带缓冲chan的第k个接收,先行发生于第c+k个发送
var limit = make(chan int, 3)
func main() {
for _, w := range work {
go func(w func()) {
limit <- 1
w()
<-limit
}(w)
}
select{}
}这里当w()执行耗时任务,chan队列满了,第四个任务的 w 的 <-lmit 先行发生于 limit <- 1, 这样就能保证我们队列中只有3个任务在同时执行。
sync 包
1. sync.mutex
var l sync.Mutex
var a string
func f() {
a = "hello, world"
l.Unlock()
}
func main() {
l.Lock()
go f()
l.Lock()
print(a)
}For any sync.Mutex or sync.RWMutex variable l and n < m, call n of l.Unlock() is synchronized before call m of l.Lock() returns.
l执行了n次Unlock, n次Unlock先行发生于n+1次Lock操作
2. sync.rwmutex
对于同一个sync.RWMutex变量l:
- l.RLock() 和 l.RUnlock() 形成配对的读锁定/读解锁操作。
- 第n次l.RLock()发生在第n次l.RUnlock()之前。
- 第n次l.RUnlock() 先行发生于第n+1次l.Lock()。
- 读锁定和读解锁按照配对嵌套的顺序执行。
- 每次读解锁先行发生于下一次写锁定。
3. sync.once
var a string
var once sync.Once
func setup() {
a = "hello, world"
}
func doprint() {
once.Do(setup)
print(a)
}
func twoprint() {
go doprint()
go doprint()
}once 可以实现多个协程只执行一次setup代码,并且其他协程会阻塞直到setup函数返回才会继续运行下面的代码。
atomic
go
var counter int64
func worker() {
for {
// 原子递增计数器
atomic.AddInt64(&counter, 1)
}
}
func main() {
for i := 0; i < 10; i++ {
go worker()
}
time.Sleep(time.Second)
// 原子读取计数器
c := atomic.LoadInt64(&counter)
fmt.Println(c)
}相当于每次执行前都对变量加锁了。比如我们熟悉的i++,汇编成代码其实是3条指令,他是有可能被程序中断的,而atomic 可以实现原子性操作。
参考文献
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: