
使用Postman测试ChatGPT API接口(GPT4)
1 / 0 / 创建于 2年前
 DogeDogeGo 的个人博客
DogeDogeGo 的个人博客
使用Postman测试ChatGPT API接口
介绍
在这篇博客中,我们将探索如何使用Postman这一流行的API测试工具,来测试OpenAI的ChatGPT API。这将为开发者提供一个快速、直观的方法来测试和开发基于ChatGPT的应用程序。
设置Postman环境
1.下载Postman:访问Postman官方网站下载并安装。
2.打开Postman并创建一个新的请求。
为ChatGPT API创建请求
1.在请求类型中选择“POST”。
2.输入ChatGPT的API URL(api.openai.com/v1/chat/completions)。
3.在Headers部分,添加你的API密钥,通常它可能像这样:Authorization: Bearer YOUR_API_KEY。
4.在请求体(Body)部分,选择“raw”并输入JSON格式的数据。例如:
{
"model": "gpt-4",
"messages": [{"role": "user", "content": "鲁迅为什么暴打周树人"}],
"max_tokens": 512,
"top_p": 1,
"temperature": 0.5,
"frequency_penalty": 0,
"presence_penalty": 0
}上述JSON格式数据解释:
model: "gpt-4"
这表示你想使用OpenAI的GPT-4模型来处理你的请求。OpenAI提供了多种模型,而gpt-4是其中之一。
messages: [{"role": "user", "content": "鲁迅为什么暴打周树人"}]
这是你与模型的交互消息。你作为用户发送了一个内容为“鲁迅为什么暴打周树人”的消息,并期待模型给出回应。
max_tokens: 512
这限制了模型回应的最大长度。在这里,你设置的是512个tokens。这意味着模型的回应不会超过512个tokens。
top_p: 1
这是一个与采样相关的参数,通常与temperature一起使用。它控制了模型在生成文本时的随机性。top_p=1意味着模型将考虑所有可能的下一个词,而不仅仅是最可能的那部分。
temperature: 0.5
温度是另一个控制随机性的参数。较高的温度(接近1)会让模型的输出更随机,而较低的温度(接近0)会让模型的输出更确定。0.5是一个中间值,提供了一定的随机性,但仍有一定的方向性。
frequency_penalty: 0 和 presence_penalty: 0
这两个参数可以用来惩罚或奖励特定的词汇出现在模型的输出中。在这里,它们都被设置为0,意味着不进行任何特殊处理。
简而言之,通过上述的请求体,告诉API:使用GPT-4模型回答关于“鲁迅为什么暴打周树人”的问题,而且回应的长度不应超过512个tokens,同时使用了一定的随机性但不太偏离主题。
-----
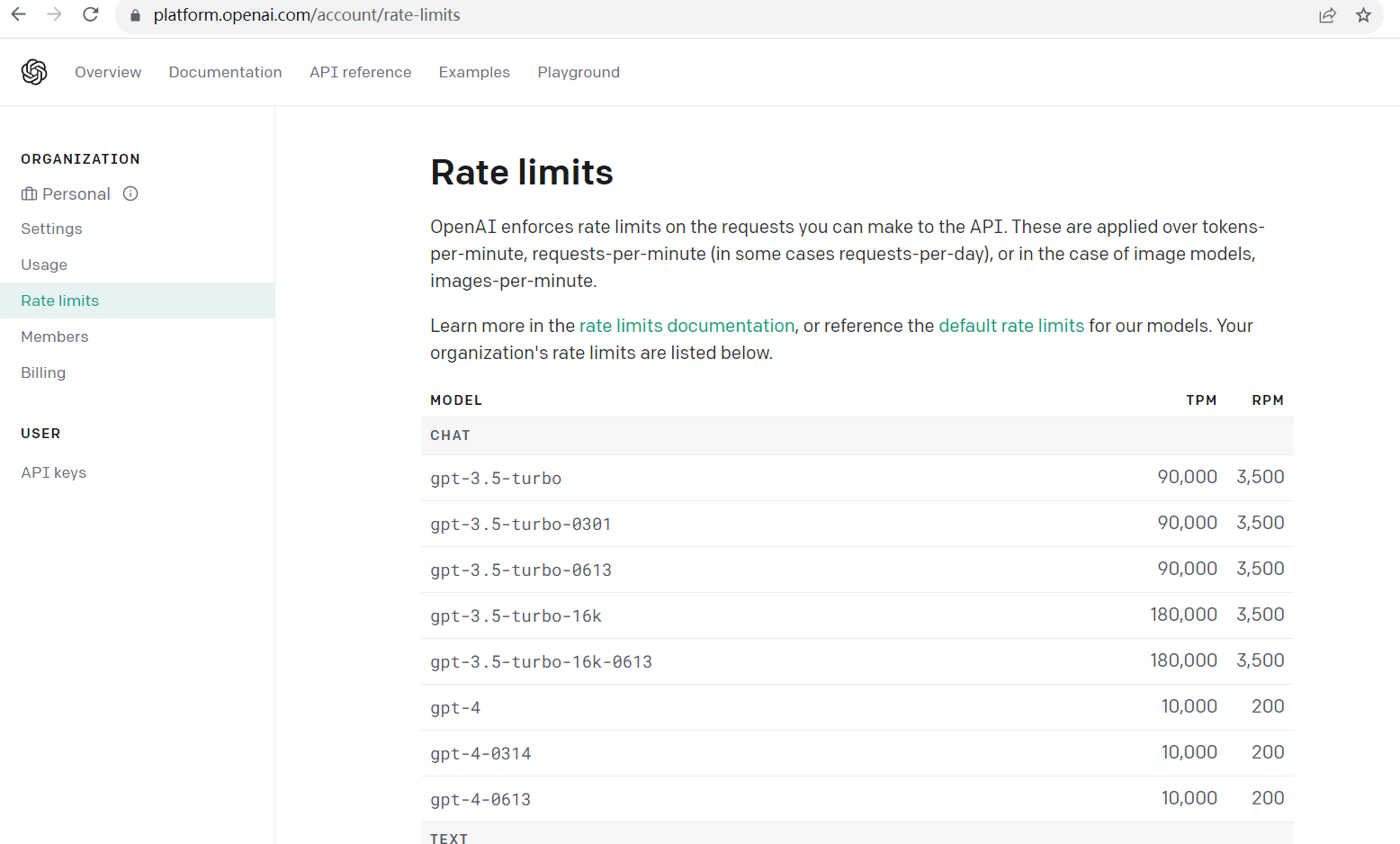
在请求中只有"model","messages"参数是必要的。5.ChatGPT Model 类型(platform.openai.com/account/rate-l...)
发送请求并接收响应
1.ChatGPT的响应

常见问题和调试技巧
如果你收到Error: Request timed out,这表示你的请求超时。需要开启系统代理
对于401错误,确保你的API密钥是正确的,并且没有被禁用。
如果你收到429错误,这表示你的请求过于频繁。根据前面的解释,你可能需要稍微等待,或者检查是否有多余的请求。
结论
Postman为开发者提供了一个非常简单且强大的工具,以测试和开发与API交互的应用。通过这篇指南,你应该已经了解了如何使用Postman来测试ChatGPT API,从而更好地集成到你的应用或服务中。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



