
Redis 入门 - 3(集合 set、有序集合 sort set)
3 / 0 / 创建于 8年前 /
 大眼鱼 的个人博客
大眼鱼 的个人博客
Redis 入门 - 3(集合 set、有序集合sort set)
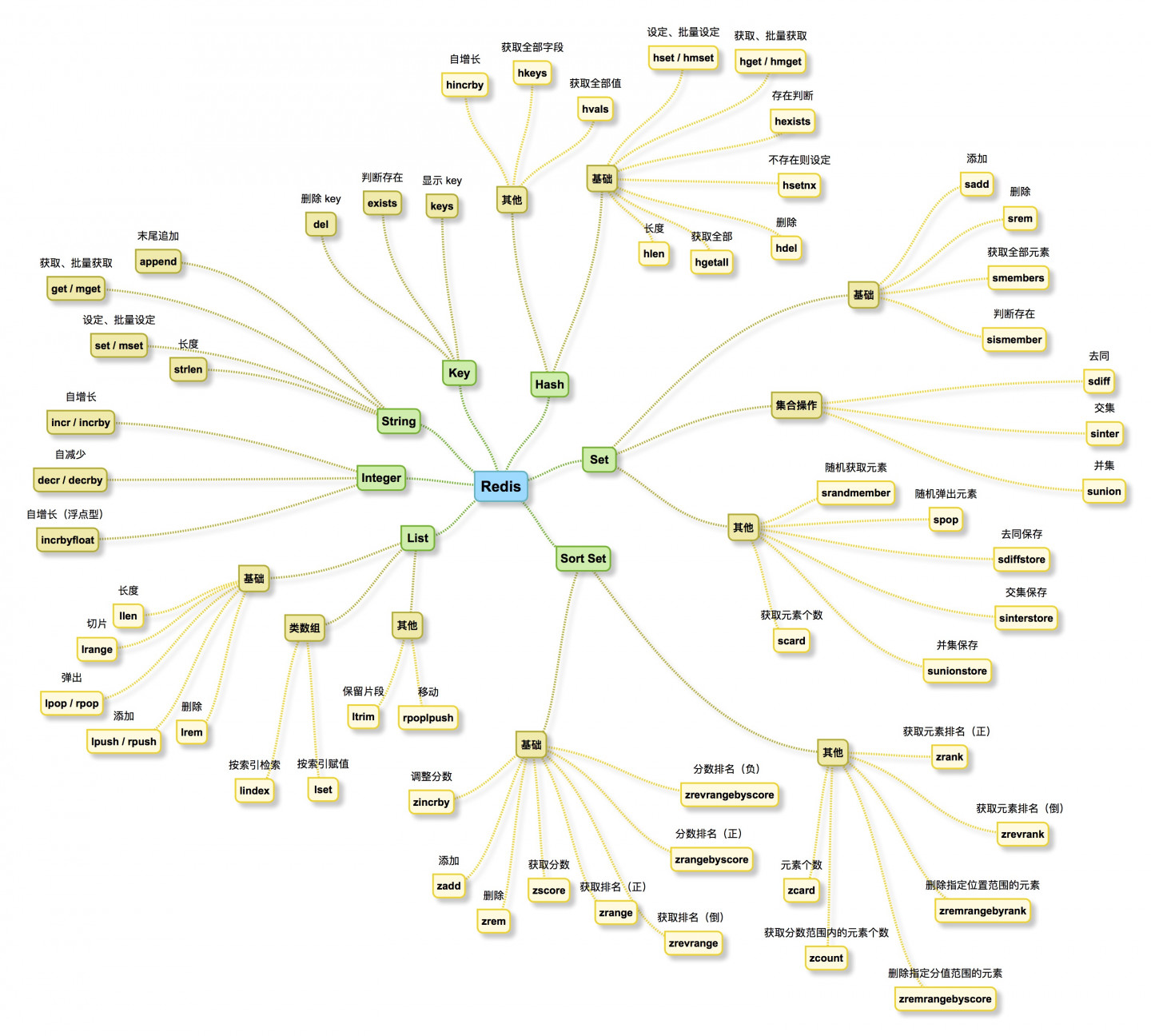
集合(Set)
集合,是一组无序且唯一的数据集。
在实际应用中,可以应用于“标签”、“属性”,这类需经常扩展或组合查询的场景
基础命令
增加
// 如果元素已存在,则忽略该命令(该命令具有批量功能)。返回成功加入的元素数量
SADD key_name member [other members]删除
// 删除元素(该命令具有批量功能)。返回删除成功的个数
SREM key_name member [other members]获取全部
// 返回集合下的所有元素
SMEMBERS key_name判断是否存在
// 存在返回 1,不存在返回 0
SISMEMBER key_name member集合运算
去同
// 返回 key_name1 中剔除 key_name2 中相同元素的部分
SDIFF key_name1 key_name2 [其他 keys]交集
// 返回 key_name1 和 key_name2 的交集
SINTER key_name1 key_name2 [其他 keys]并集
// 返回 key_name1 和 key_name2 的并集
SUNION key_name1 key_name2 [其他 keys]其他命令
获取元素个数
// 返回元素个数
SCARD key_name集合运算并存储结果
去同
// 结果存储在 destination 键中,可用于多步集合运算
SDIFFSTORE destination key_name [key_names...]交集
SINTERSTORE destination key_name [key_names...]并集
SUNIONSTORE destination key_name [key_names ...]随机获取元素
// 无 count 时,随机获取一个元素
// count > 0 时,随机获取 count 个不重复的元素,如果 count 大于集合元素数时,返回全部
// count < 0 时,随机获取 |count| 个元素(可能重复)
SRANDMEMBER key_name [count]弹出一个元素
// 随机选择一个元素弹出
SPOP key_name有序集合(Sort set)
有序集合,同集合一致,但为每个元素关联了一个分数,使我们能够获得分数最高或最低的前 N 个元素,当然也可按范围获取元素
但有序集合更加消耗内存,读取任意位置的数据都会很快,更加便捷的排序调整
基础命令
增加元素
// 返回新加入集合的元素个数
// score 可以为 integer 或 float,也可为 -inf(负无穷)或 +inf(正无穷)
ZADD key_name score member [other scores members]
// 更新,将原 member 的 score 调整为 new_score
ZADD key_name new_score member删除一个或多个元素
// 返回成功删除的元素个数
ZREM key_name memeber [other members]获得元素的分数
// 返回分数
ZSCORE kye_name member获得排名在某个范围的元素列表
// 首先按照分数从小到大排序
// (如果元素的分数相同,则对 member 按照字典顺序排列 “0”<...“9”<“A”<...“Z”<“a”...<“z”)
// 再根据索引(0 开始)结合 start 和 end 的要求返回元素
// 当加上 WITHSCORE 时,同时返回分数
ZRANGE key_name start end [WITHSCORE]
// 按照分数从大到小,其他同 ZRANGE
ZREVRANGE key_name start end [WITHSCORE]获得指定分数范围的元素
// 首先会对 key_name 按从小到大排列
// 返回分数在 min 和 max 之间的元素(注意:包含 min 和 max)
ZRANGEBYSCORE key_name min max [WITHSCORE] [LIMIT offset count]
// LIMIT 可在检索的结果中,偏移(往后数)offset 个位置,取 count 个元素
// 在 students 集合中获取分数为 70 ~ 100 分之间,并跳过前 2 个,取 3 个元素
ZRANGEBYSCORE students 70 100 WITHSCORE LIMIT 2 3
// 不希望包含 min 或 max 时,使用“(”(同数学中的集合符号,( 不包含,[ 包含)
ZRANGEBYSCORE key_name 80 (100
// 按从大到小排列,其他一致
ZREVRANGEBYSCORE key_name min max [WITHSCORE] [LIMIT offset count]调整某个元素的分数
// 给元素增加 increment 的分值,返回更改后的分数
// increment 可以为正(加),也可以为负(减)
// 如果指定元素不存在,则先创建,初始化为 0,再调整
ZINCRBY key_name increment member其他命令
获取集合中元素的数量
// 返回个数
ZCARD key_name获得指定分数范围内的元素个数
// 同 ZRANGEBYSOCRE 中的 min 和 max 一致
// 包含 min 和 max,不包含的话,可以使用“(”
ZCOUNT key_name min max按照排名范围删除元素
// 先从小到大排列,再根据索引位置,删除 start 和 end 间的所有元素(注意:包含 start 和 end)
// 返回删除元素个数
ZREMRANGEBYRANK key_name start end按照分数范围删除元素
// 删除分数范围内的所有元素
ZREMRANGEBYSCORE key_name min max获取元素的排名
// 从小到大排列,返回索引值(0 开始)
ZRANK key_name member
// 从大到小排列,返回索引值(0 开始)
ZREVRANK key_name member总结
实践 - 版本 v3.0
目标
- 使用集合类型,为任务管理系统增加标签功能
- 为每条 task 定义一个 task:id:tags(集合)的键存储标签
- 为每个标签,定义一个 tag:name:count 存储都有哪些 task 使用了该 tag:name
- 可按标签分类检索
- 使用有序集合类型,实现文章按照日期排序的功能(新增、更新都会触发日期的更新),task:sort
本作品采用《CC 协议》,转载必须注明作者和本文链接









 关于 LearnKu
关于 LearnKu




推荐文章: