
使用 Go 编写数据转换管道
0 / 0 / 创建于 2年前 /
 落尘埃 的个人博客
落尘埃 的个人博客
作为数据工程师,我们负责构建、维护和扩展数据管道以满足业务需求。将数据从一个地方移动到另一个地方,转换数据并将其交付到数据仓库,这个在我们的日常生活中相当普遍。在本文中,我将向您展示如何编写一个简单但功能强大的代码来负责处理和丰富数据管道中的数据。更具体地说,我们将专注于 ETL(提取、转换和加载)的转换部分。
代码结构
首先,我们看一下代码的结构以及每个文件在我们的转换管道中表示的内容。下面是文件夹和文件结构的高级概述:

现在,对代码的每个部分进行更深入的解释。

数据文件夹是我们从源中提取数据后数据的表示形式。例如,它可以是由生产者推送到 rabbitMQ 上的队列并由我们的代码使用的记录。
person.go:
package data
import "time"
type Person struct {
Name string
Surname string
City string
DateOfBirth time.Time
Height float64
Weight float64
}
type PersonTreated struct {
completeName string
country string
age int
bmi float64
}
func NewPerson(name, surname, city string, dateOfBirth time.Time, height, weight float64) Person {
return Person{
Name: name,
Surname: surname,
City: city,
DateOfBirth: dateOfBirth,
Height: height,
Weight: weight,
}
}
func NewPersonTreated(completeName, country string, age int, bmi float64) PersonTreated {
return PersonTreated{
completeName: completeName,
country: country,
age: age,
bmi: bmi,
}
}在此代码中,我们定义了两个结构,Person 和 PersonTreated。前者代表一个人的基本信息,后者在经过我们的管道处理和丰富后,会保存一个人的信息。为了使我们的代码更习惯,我们还定义了两个构造函数来初始化我们的结构。请注意,我们正在从 Person 导出字段,对于 PersonTreatment,我们将保持其字段未导出。其原因将很快解释。
转换器文件夹包含负责对数据应用转换的所有文件。
transformer.go:

在这里,我们定义了一个实现方法 Transform() 的接口。这是负责将转换应用于数据的方法。
strings.go:
package transformer
import "strings"
type ToUpper struct {
Input string
Output string
}
type JoinStrings struct {
Input []string
Output string
}
func NewToUpper(input string) *ToUpper {
return &ToUpper{Input: input}
}
func NewJoinStrings(inputs ...string) *JoinStrings {
return &JoinStrings{Input: inputs}
}
func (t *ToUpper) Transform() {
t.Output = strings.ToUpper(t.Input)
}
func (t *JoinStrings) Transform() {
t.Output = strings.Join(t.Input, " ")
}在这里,我们定义了两个实现转换器接口的结构。ToUpper:
- 此结构表示将字符串转换为大写的转换操作。
- 它有两个字段: Input 输入字符串和 Output 存储转换结果的 。
JoinStrings:
- 此结构表示将字符串切片联接到单个字符串中且它们之间有空格的转换操作。
- 它有两个字段: Input ,这是输入字符串的一部分,以及 Output 存储转换结果的 。
为了使我们的代码更习惯,我定义了用于初始化字符串转换器的构造函数。
enrichment.go
package transformer
import (
"math"
"time"
)
type EnrichCountryByCity struct {
City string
Country string
}
type EnrichAgeByDateOfBirth struct {
DateOfBirth time.Time
Age int
}
type EnrichBMIByHeightAndWeight struct {
Height float64
Weight float64
BMI float64
}
func NewEnrichCountryByCity(city string) *EnrichCountryByCity {
return &EnrichCountryByCity{City: city}
}
func NewEnrichAgeByDateOfBirth(dateOfBirth time.Time) *EnrichAgeByDateOfBirth {
return &EnrichAgeByDateOfBirth{DateOfBirth: dateOfBirth}
}
func NewEnrichBMIByHeightAndWeight(height, weight float64) *EnrichBMIByHeightAndWeight {
return &EnrichBMIByHeightAndWeight{Height: height, Weight: weight}
}
func (t *EnrichCountryByCity) Transform() {
var countries map[string]string
countries = make(map[string]string)
countries["LONDON"] = "UK"
t.Country = countries[t.City]
}
func (t *EnrichAgeByDateOfBirth) Transform() {
currentDate := time.Now()
birthDate := t.DateOfBirth
// Calculate age based on the difference in years
age := currentDate.Year() - birthDate.Year()
// Check if the birthdate for this year has occurred or not
if birthDate.YearDay() > currentDate.YearDay() {
age--
}
t.Age = age
}
func (t *EnrichBMIByHeightAndWeight) Transform() {
t.BMI = math.Round(t.Weight / (t.Height * t.Height))
}在这里,我们定义了三个实现转换器接口的结构。EnrichCountryByCity:
- 此结构表示将数据扩充操作,用于将城市映射到其相应的国家/地区。
- 它有两个字段: City (输入城市)和 Country (输出国家/地区)。
EnrichAgeByDateOfBirth: - 此结构表示数据扩充操作,用于根据出生日期计算人员的年龄。
- 它有两个字段: DateOfBirth (输入的出生日期)和 Age (计算的年龄)。
EnrichBMIByHeightAndWeight:
- 此结构表示数据扩充操作,用于根据一个人的身高和体重计算一个人的 BMI(身体质量指数)。
- 它有三个字段: Height (以米为单位的输入高度)、 Weight (以千克为单位的输入重量)和 BMI (计算的体重指数)。
同样,我定义了用于初始化扩充转换器的构造函数。

管道文件夹包含定义新管道、向其添加阶段并最终运行它的逻辑。
pipeline.go:
package pipeline
import (
"fmt"
"github.com/codeis4fun/go-data-pipeline/transformer"
)
type stage struct {
name string
transformer transformer.Transformer
}
type pipeline struct {
name string
stages []stage
}
func NewPipeline(name string) *pipeline {
return &pipeline{
name: name,
stages: []stage{},
}
}
func (p *pipeline) AddStage(name string, transformation transformer.Transformer) *pipeline {
p.stages = append(p.stages, stage{name: name, transformer: transformation})
return p
}
func (p *pipeline) Run() {
fmt.Println("Running pipeline:", p.name)
for _, s := range p.stages {
fmt.Println("Running stage:", s.name)
s.transformer.Transform()
}
fmt.Print("Pipeline finished\n\n")
}在这里,我为它定义了两个结构,一个构造函数和两个方法。stage:
- 此结构表示数据管道中的处理阶段。
- 字段
name:表示舞台名称的字符串。transformer:类型的transformer.Transformer字段,指示此阶段将使用转换器应用转换。
Pipeline:
- 此结构表示数据处理管道。
- 字段
name:表示管道名称的字符串。stages:结构的一部分stage,用于保存管道的各个阶段。
NewPipeline:
- NewPipeline() 是一个构造函数,用于创建 Pipeline 结构的新实例。
- 它需要一个 name 参数来设置管道的名称。
- 它初始化 stages 字段的空切片,并返回指向新创建的管道的指针。
AddStage:
- AddStage 是 Pipeline 结构体的方法。
- 它允许您向管道添加处理阶段。
- 它采用一个 name 参数作为阶段的名称和一个参数,该 transformation 参数应是实现接口的 transformer.Transformer 转换器。
- 它将具有指定名称和转换器的新 stage 结构追加到管道的 stages 切片,并返回指向更新管道的指针。
Run:
- Run 是 Pipeline 结构体的方法。
- 它通过循环访问其阶段并应用转换来执行管道。
- 它打印消息,指示管道和每个阶段正在运行。
- 它在每个阶段的转换器上调用 Transform 该方法以执行实际的数据转换。
- 最后,它会打印一条消息,指示管道已完成。
在我向您详细解释了代码中的每个步骤之后,让我们深入了解 main.go 看看如何使用它来处理和丰富我们的数据。
现在,让我们想象一个用例来创建我们的main.go来实现我们想要的目标。首先,我们有一个叫“John Doe”的人,1980年1月1日出生于伦敦,身高1.8米,体重80公斤。在这种情况下,我们的目标是处理和丰富我们的数据,以获得他的全名、出生国家、年龄和 BMI。
为了实现这一点,我们的main.go可以类似于这样:
main.go:
package main
import (
"fmt"
"time"
"github.com/codeis4fun/go-data-pipeline/data"
"github.com/codeis4fun/go-data-pipeline/pipeline"
"github.com/codeis4fun/go-data-pipeline/transformer"
)
func main() {
// data
person := data.NewPerson("John", "Doe", "London", time.Date(1980, 1, 1, 0, 0, 0, 0, time.UTC), 1.8, 80)
// transformations
nameToUppercase := transformer.NewToUpper(person.Name)
surnameToUppercase := transformer.NewToUpper(person.Surname)
cityToUppercase := transformer.NewToUpper(person.City)
// Create a pipeline
p1 := pipeline.NewPipeline("Transform name, surname and city")
// Add stages to the pipeline
p1.
AddStage("transform name to uppercase", nameToUppercase).
AddStage("transform surname to uppercase", surnameToUppercase).
AddStage("transform city to uppercase", cityToUppercase)
// Run the pipeline
p1.Run()
// transformations
joinNameAndSurname := transformer.NewJoinStrings(nameToUppercase.Output, surnameToUppercase.Output)
enrichCountryByCity := transformer.NewEnrichCountryByCity(cityToUppercase.Output)
enrichAgeByDateOfBirth := transformer.NewEnrichAgeByDateOfBirth(person.DateOfBirth)
enrichBMIByWeightAndHeight := transformer.NewEnrichBMIByHeightAndWeight(person.Height, person.Weight)
// Create a pipeline
p2 := pipeline.NewPipeline("Transform to complete name, enrich country, enrich age and enrich BMI")
// Add stages to the pipeline
p2.
AddStage("transform to complete name", joinNameAndSurname).
AddStage("enrich country by city", enrichCountryByCity).
AddStage("enrich age by date of birth", enrichAgeByDateOfBirth).
AddStage("enrich BMI by weight and height", enrichBMIByWeightAndHeight)
// Run the pipeline
p2.Run()
// Assign the output of the pipeline to the data
personTreated := data.NewPersonTreated(joinNameAndSurname.Output, enrichCountryByCity.Country, enrichAgeByDateOfBirth.Age, enrichBMIByWeightAndHeight.BMI)
// Print the result
fmt.Printf("Person treated: %+v\n", personTreated)
}让我们分解代码,使其目的更易于理解:
1. Data Initialization 数据初始化
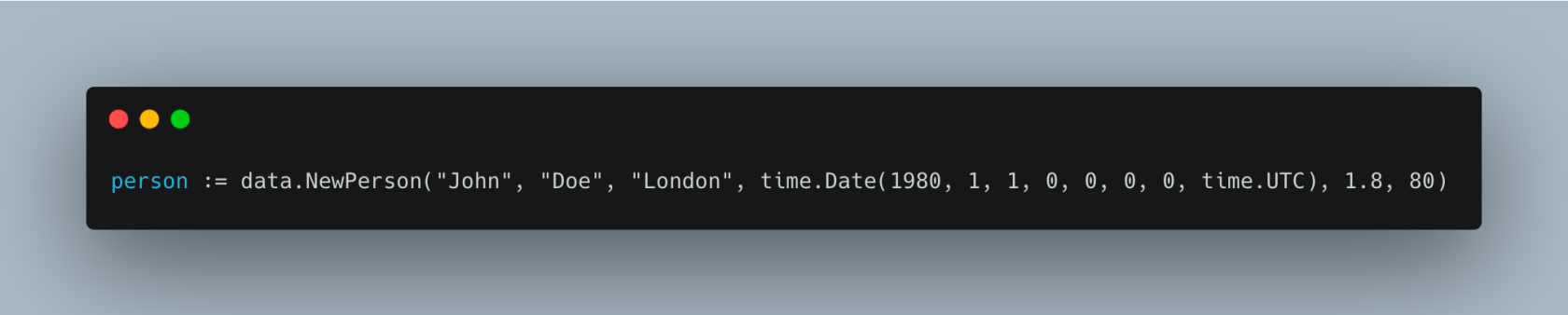
在这里,我们创建了一个 Person 结构体的实例,代表一个名叫 John Doe 的人,他于 1980 年 1 月 1 日出生于伦敦,身高 1.8 米,体重 80 公斤。
2. 第一个管道的转换

在这里,我们创建三个转换器,将姓名、姓氏和城市转换为大写。另外,现在是时候解释为什么导出 Person 字段了。这是必要的,因为我们打算将这些字段用作转换器的参数,这些转换器位于 data 包外部。
3. 运行第一个管道

在这里,我们创建一个 管道 ,将大写转换添加为阶段 p1 ,然后运行管道。这会将姓名、姓氏和城市转换为大写并显示结果:
4. 第二个管道的转换
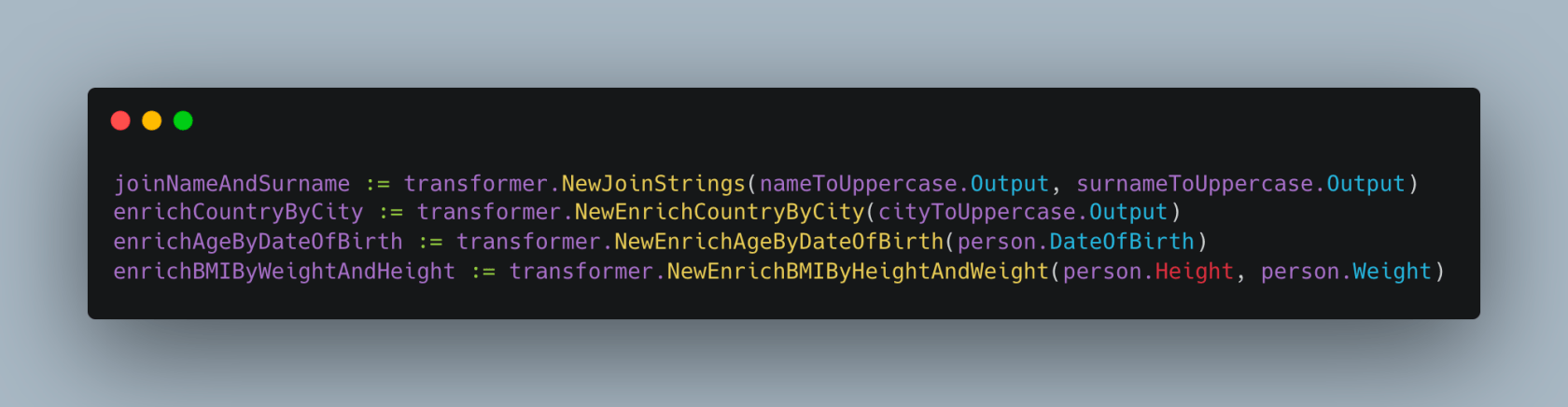
在这里,我们创造了用于连接名字和姓氏的变形金刚,按城市丰富国家,按出生日期丰富年龄,通过体重和身高丰富BMI。请注意,我们必须运行第一个管道才能拥有 nameToUpperCase.Output 和 surnameToUppercase.Output 处理过的字段。
5. 运行第二个管道

在这里,我们创建另一个管道,添加用于完成名称的转换,丰富国家,年龄和BMI作为阶段,运行管道 p2 并显示结果:

6. 分配管道输出

在这里,我们创建 PersonTreated 结构的新实例,从转换的输出中分配值。
7. 打印结果

最后但并非最不重要的一点是,我们将在屏幕上打印结果:

总而言之,此代码演示了一个数据转换管道,该管道获取人员的基本信息,执行各种转换,并丰富数据以获取具有完整详细信息的已处理人员对象。
以下是包含完整代码的存储库:github.com/ozeer/transformation
英文原文:medium.com/@nicholascarballo/writi...
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: