
认识Redis:不只是缓存,还有这些厉害的功能!
8 / 0 / 创建于 2年前
 云端源想 的个人博客
云端源想 的个人博客
在当今数据驱动的世界中,快速存取信息成为了技术发展的关键。而在众多存储解决方案中,Redis以其独特的魅力和强大的功能,成为了开发者们的宠儿。今天,就让我们一起来认识一下Redis。
一、Redis是什么,可以用来干什么?
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。

与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁、计数器、排行榜等。
Redis的常见应用
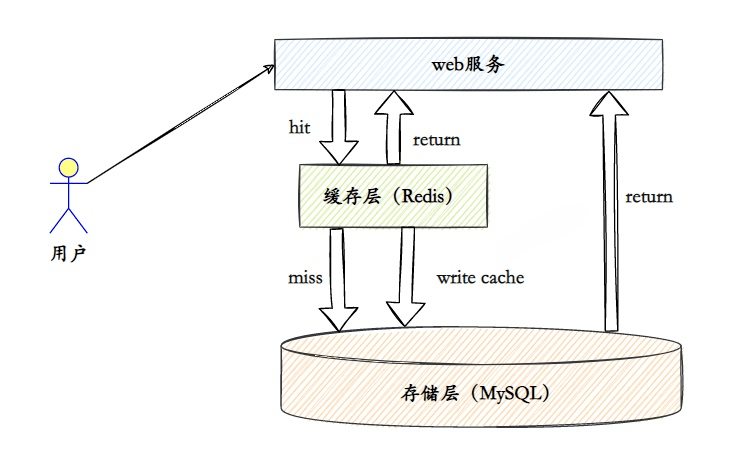
1.缓存
这是Redis应用最广泛地方,基本所有的Web应用都会使用Redis作为缓存,来降低数据源压力,提高响应速度。
2.计数器
Redis天然支持计数功能,而且计数性能非常好,可以用来记录浏览量、点赞量等等。
3.排行榜
Redis提供了列表和有序集合数据结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统。
4.社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新。
5. 消息队列
Redis提供了发布订阅功能和阻塞队列的功能,可以满足一般消息队列功能。
6. 分布式锁
分布式环境下,利用Redis实现分布式锁,也是Redis常见的应用。
7. 位操作
用于数据量上亿的场景下,例如几亿用户系统的签到,去重登录次数统计,某用户是否在线状态等等。这里要用到位操作——使用setbit、getbit、bitcount命令。
原理是:redis内构建一个足够长的数组,每个数组元素只能是0和1两个值,然后这个数组的下标index用来表示用户id(必须是数字哈),那么很显然,这个几亿长的大数组就能通过下标和元素值(0和1)来构建一个记忆系统。
二、Redis 有哪些数据结构类型?
Redis有五种基本类型和三种特殊的数据结构类型,下面我们分别来看一些都有哪些类型。

2.1 Redis的五种基本数据结构
string
字符串最基础的数据结构。字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字 (整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB。
字符串主要有以下几个典型使用场景:
缓存功能
计数
共享Session
限速
hash
哈希类型是指键值本身又是一个键值对结构。
哈希主要有以下典型应用场景:
缓存用户信息
缓存对象
list
列表(list)类型是用来存储多个有序的字符串。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色。
列表主要有以下几种使用场景:
消息队列
文章列表
set
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一 样的是,集合中不允许有重复元素,并且集合中的元素是无序的。
集合主要有如下使用场景:
标签(tag)
共同关注
sorted set
有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的是,它给每个元素设置一个权重(score)作为排序的依据。
有序集合主要应用场景:
用户点赞统计
用户排序
2.2 Redis 的三种特殊数据类型
Geo: Redis3.2推出的,地理位置定位,用于存储地理位置信息,并对存储的信息进行操作。
HyperLogLog: 用来做基数统计算法的数据结构,如统计网站的UV。
Bitmaps : 用一个比特位来映射某个元素的状态,在Redis中,它的底层是基于字符串类型实现的,可以把bitmaps成作一个以比特位为单位的数组。
三、Redis为什么这么快?
3.1 基于内存存储实现
我们都知道内存读写是比在磁盘快很多的,Redis基于内存存储实现的数据库,相对于数据存在磁盘的MySQL数据库,省去磁盘I/O的消耗。
3.2 高效的数据结构
我们知道,Mysql索引为了提高效率,选择了B+树的数据结构。其实合理的数据结构,就是可以让你的应用/程序更快。先看下Redis的数据结构&内部编码图:

SDS简单动态字符串
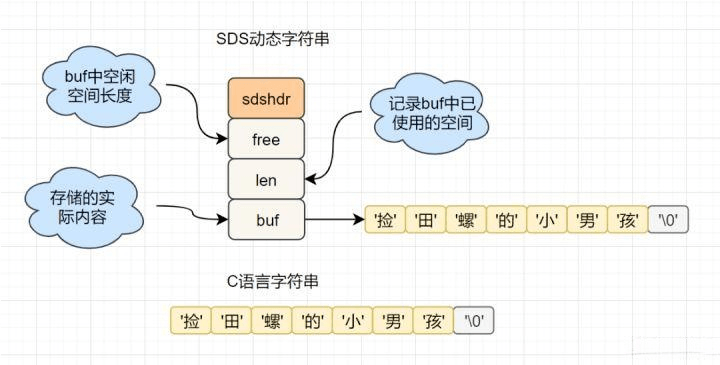
字符串长度处理: Redis获取字符串长度,时间复杂度为O(1),而C语言中,需要从头开始遍历,复杂度为O(n);
空间预分配: 字符串修改越频繁的话,内存分配越频繁,就会消耗性能,而SDS修改和空间扩充,会额外分配未使用的空间,减少性能损耗。
惰性空间释放: SDS 缩短时,不是回收多余的内存空间,而是free记录下多余的空间,后续有变更,直接使用free中记录的空间,减少分配。
二进制安全: Redis可以存储一些二进制数据,在C语言中字符串遇到’\0’会结束,而 SDS中标志字符串结束的是len属性。
字典
Redis 作为 K-V 型内存数据库,所有的键值就是用字典来存储。字典就是哈希表,比如HashMap,通过key就可以直接获取到对应的value。而哈希表的特性,在O(1)时间复杂度就可以获得对应的值。
跳跃表
跳跃表是Redis特有的数据结构,就是在链表的基础上,增加多级索引提升查找效率。
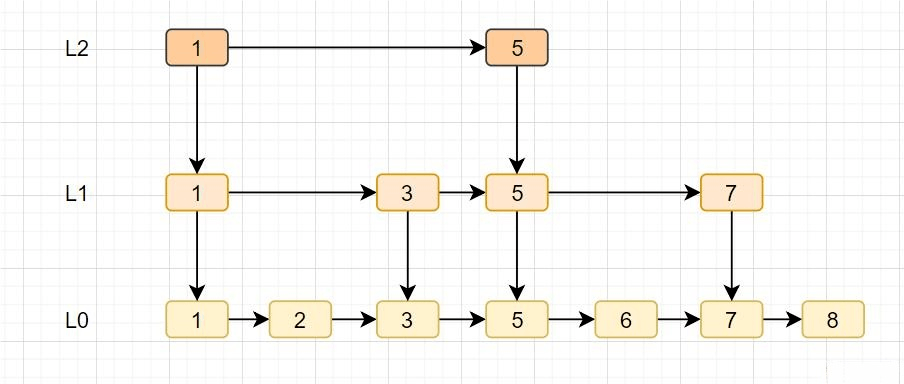
跳跃表支持平均 O(logN),最坏 O(N)复杂度的节点查找,还可以通过顺序性操作批量处理节点。
3.3 合理的数据编码
Redis 支持多种数据数据类型,每种基本类型,可能对多种数据结构。什么时候,使用什么样数据结构,使用什么样编码,是redis设计者总结优化的结果。
String: 如果存储数字的话,是用int类型的编码;如果存储非数字,小于等于39字节的字符串,是embstr;大于39个字节,则是raw编码。
List: 如果列表的元素个数小于512个,列表每个元素的值都小于64字节(默认),使用ziplist编码,否则使用linkedlist编码。
Hash: 哈希类型元素个数小于512个,所有值小于64字节的话,使用ziplist编码,否则使用hashtable编码。
Set: 如果集合中的元素都是整数且元素个数小于512个,使用intset编码,否则使用hashtable编码。
Zset: 当有序集合的元素个数小于128个,每个元素的值小于64字节时,使用ziplist编码,否则使用skiplist(跳跃表)编码。
3.4 合理的线程模型
I/O 多路复用
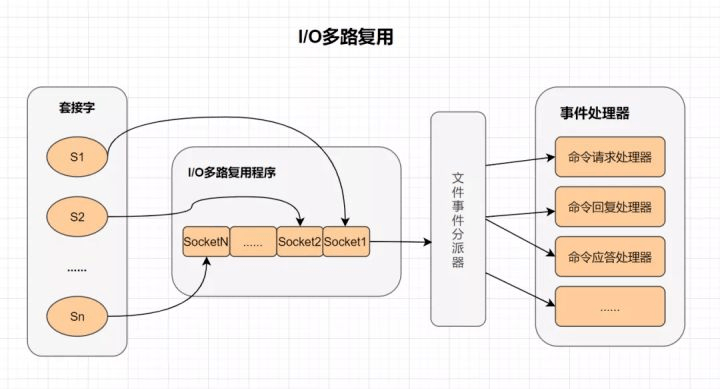
多路I/O复用技术可以让单个线程高效的处理多个连接请求,而Redis使用用epoll作为I/O多路复用技术的实现。并且,Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
什么是I/O多路复用?
I/O :网络 I/O
多路 :多个网络连接
复用:复用同一个线程。
IO多路复用其实就是一种同步IO模型,它实现了一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;而没有文件句柄就绪时,就会阻塞应用程序,交出cpu。
单线程模型
Redis是单线程模型的,而单线程避免了CPU不必要的上下文切换和竞争锁的消耗。也正因为是单线程,如果某个命令执行过长(如hgetall命令),会造成阻塞。
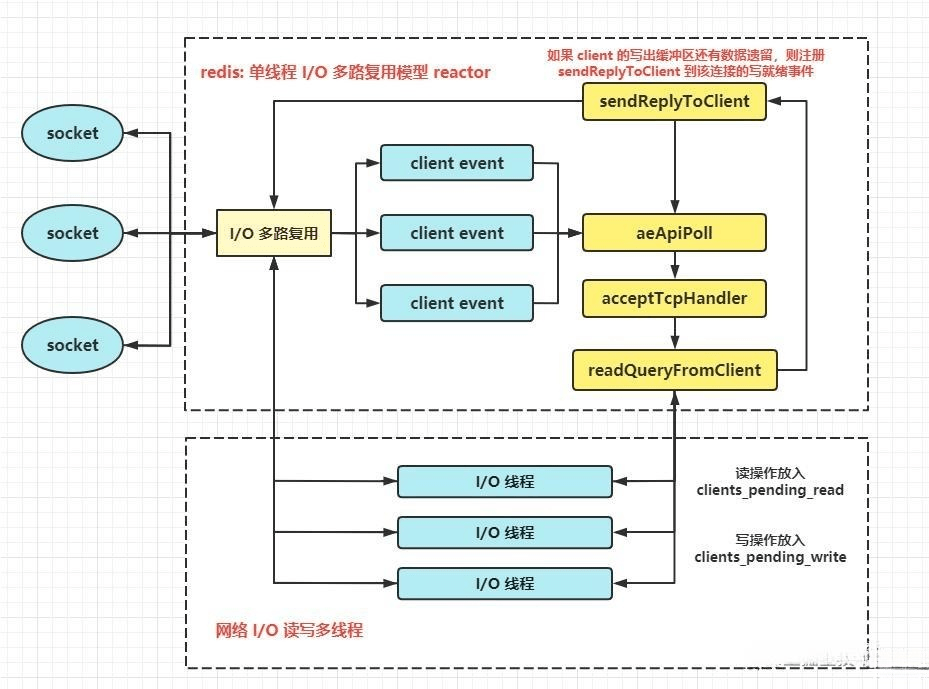
Redis是面向快速执行场景的数据库,所以要慎用如smembers和lrange、hgetall等命令。
Redis 6.0 引入了多线程提速,它的执行命令操作内存的仍然是个单线程。
3.5 虚拟内存机制
Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。
Redis的虚拟内存机制是什么?
虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
你还在苦恼找不到真正免费的编程学习平台吗?可以试试【云端源想】!课程视频、知识库、微实战、云实验室、一对一咨询……你想要的全部学习资源这里都有,重点是现在还是免费的!点这里即可查看!
四、什么是热Key问题,如何解决?
在Redis中,我们把访问频率高的key,称为热点key。
如果某一热点key的请求到服务器主机时,由于请求量特别大,可能会导致主机资源不足,甚至宕机,从而影响正常的服务。
而热点Key是怎么产生的呢?主要原因有两个:
用户消费的数据远大于生产的数据,如秒杀、热点新闻等读多写少的场景。
请求分片集中,超过单Redi服务器的性能,比如固定名称key,Hash落入同一台服务器,瞬间访问量极大,超过机器瓶颈,产生热点Key问题。
那么在日常开发中,如何识别到热点key呢?
凭经验判断哪些是热Key;
客户端统计上报;
服务代理层上报。
如何解决热key问题?
Redis集群扩容:增加分片副本,均衡读流量;
将热key分散到不同的服务器中;
使用二级缓存,即JVM本地缓存,减少Redis的读请求。
五、Redis 过期策略和内存淘汰策略
5.1Redis过期策略
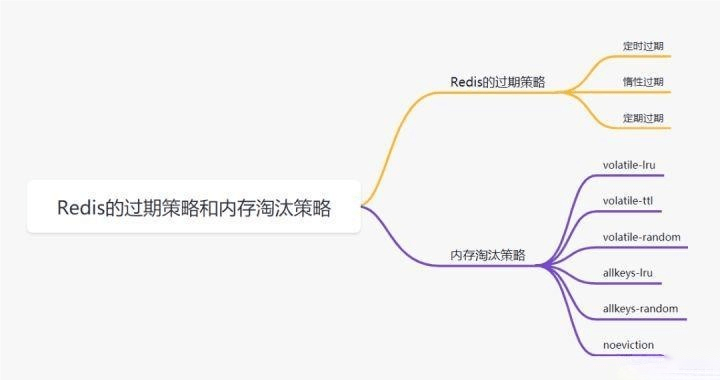
我们在set key的时候,可以给它设置一个过期时间,比如expire key 60。指定这key60s后过期,60s后,redis是如何处理的?
我们先来介绍几种过期策略:
定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即对key进行清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。
该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
expires字典会保存所有设置了过期时间的key的过期时间数据,其中:
key是指向键空间中的某个键的指针。
value是该键的毫秒精度的UNIX时间戳表示的过期时间。
键空间是指该Redis集群中保存的所有键。
Redis中同时使用了惰性过期和定期过期两种过期策略。
假设Redis当前存放30万个key,并且都设置了过期时间,如果你每隔100ms就去检查这全部的key,CPU负载会特别高,最后可能会挂掉。因此,redis采取的是定期过期,每隔100ms就随机抽取一定数量的key来检查和删除的。
但是呢,最后可能会有很多已经过期的key没被删除。这时候,redis采用惰性删除。在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间并且已经过期了,此时就会删除。
如果定期删除漏掉了很多过期的key,然后也没走惰性删除。就会有很多过期key积在内存内存,直接会导致内存爆的。或者有些时候,业务量大起来了,redis的key被大量使用,内存直接不够了,运维小哥哥也忘记加大内存了。
难道redis直接这样挂掉?不会的!Redis用8种内存淘汰策略保护自己~
5.2 Redis 内存淘汰策略
volatile-lru: 当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰。
allkeys-lru: 当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
volatile-lfu: 4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
allkeys-lfu: 4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰。
volatile-random: 当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据。
allkeys-random: 当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
volatile-ttl: 当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰。
noeviction: 默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: