
「Golang进阶之路」底层原理篇
270 / 0 / 创建于 1年前 /
 iceymoss 的个人博客
iceymoss 的个人博客
[toc]
写在前面
在 Go 语言的设计哲学中,简洁性和高效性始终是其核心追求。然而,这种表面的简洁背后,蕴含着精心设计的数据结构和巧妙的实现机制。本文将深入探讨 Go 语言中最基础且最重要的核心数据结构,包括 string、slice、map、sync.Map、channel gmp的g,m,p、defder、context 、select等,以及并发编程中不可或缺的 goroutine、mutex、waitgroup 等同步原语。
通过对这些数据结构的底层实现、内存模型、性能特征和最佳实践的深入分析,我们不仅能更好地理解 Go 语言的设计思想,也能在实际开发中做出更明智的技术选择。无论是处理日常的业务逻辑,还是构建高性能的系统,对这些核心数据结构的深入理解都是至关重要的,相信我读完本文你会对go会有进一步理解。
String底层原理
String底层结构
在 Go 语言中,字符串类型 string 的底层存储结构是一个只读的字节切片。它使用 UTF-8 编码来表示 Unicode 字符串,这意味着一个字符串可能由多个字节组成。Go 的字符串类型设计为不可变类型,即一旦创建,就不能修改其内容。这种不可变性确保了字符串在并发环境下的安全性。
具体来说,Go 的 string 类型包含两部分数据:
- 字符串长度:存储字符串的字节数,而不是字符数。Go 的字符串是字节序列,每个字符可能由多个字节组成。
- 字节切片指针:指向实际存储字符串字节的数组的指针。
Go 语言的字符串存储结构可以用以下伪代码表示:
type StringHeader struct {
Len int // 字符串的字节数
Data uintptr // 指向字节切片的指针
}示例,下图展示了字符串abc的存储结构:
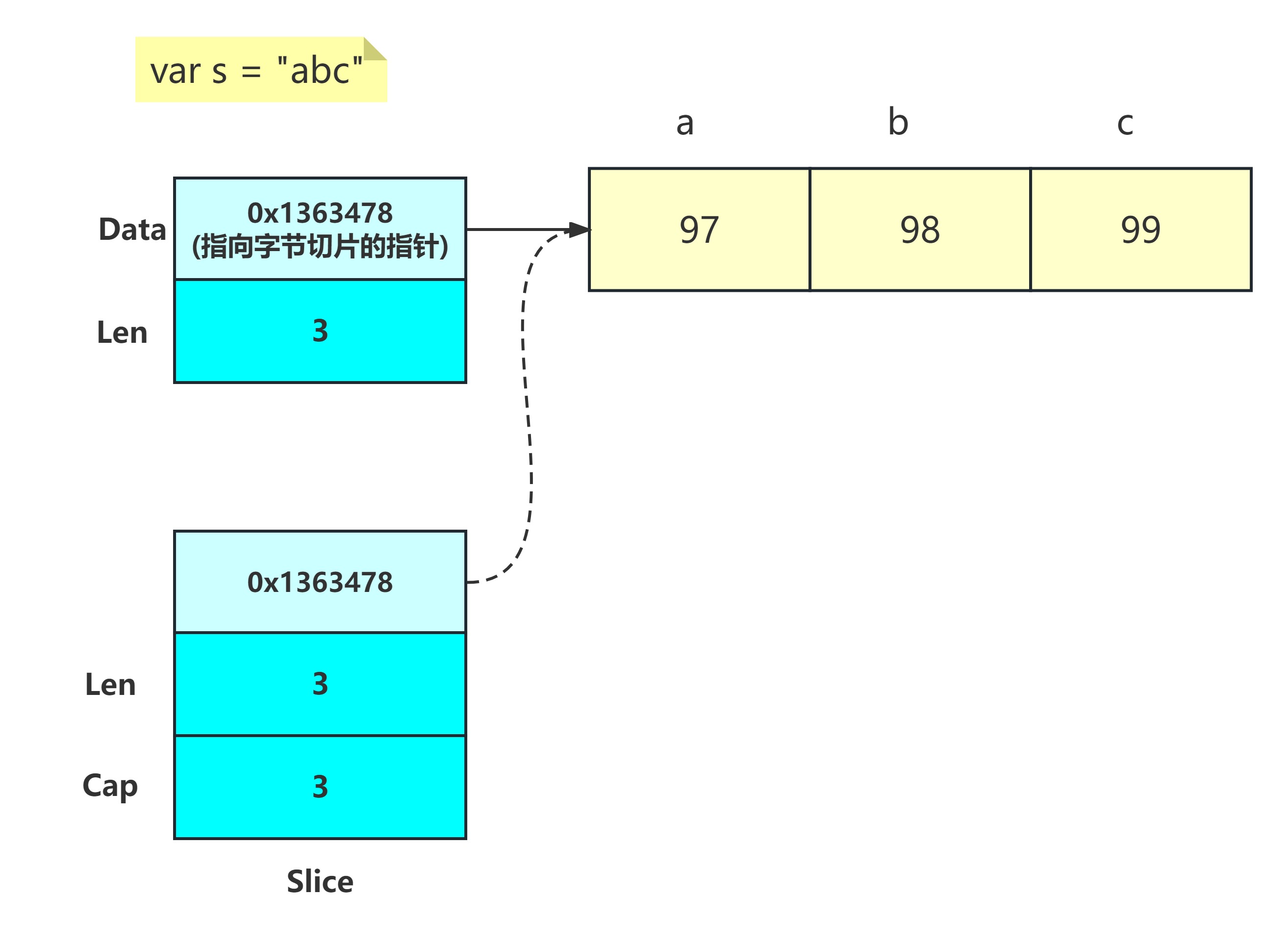
我们可以通过下面的代码来获取字符串的底层数据:
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
s1 := "abc"
// unsafe.Pointer 是通用指针类型,可以:
// 1. 任何类型的指针 <-> unsafe.Pointer
// 2. unsafe.Pointer <-> uintptr
ptr := (*reflect.StringHeader)(unsafe.Pointer(&s1))
fmt.Println(ptr)
//字符串Data的地址
fmt.Println(unsafe.Pointer(ptr.Data))
//获取Data地址所指向的数据
fmt.Println((*[3]byte)(unsafe.Pointer(ptr.Data))) //&[97 98 99]
}输出:
&{4309323690 3}
0x100db0faa
&[97 98 99]注意:字符串底层虽然是一个字节切片,但这个数组的元素是不可变的,我们可以对字符串重新赋值,但不能直接修改字符串中的某个字符,比如:
s1 := "abcd"
s1[1] = 'd' //编译不通过知识补充
unsafe.Sizeof 用于获取类型或变量在内存中占用的字节数。
示例:
func main() { fmt.Println(unsafe.Sizeof(true)) // 1字节 fmt.Println(unsafe.Sizeof(int8(0))) // 1字节 fmt.Println(unsafe.Sizeof(int16(0))) // 2字节 fmt.Println(unsafe.Sizeof(int32(0))) // 4字节 fmt.Println(unsafe.Sizeof(int64(0))) // 8字节 fmt.Println(unsafe.Sizeof(int(0))) // 8字节(64位系统) fmt.Println(unsafe.Sizeof("")) // 16字节(string header) }
思考:Go语言为什么将字符串设计为只读呢?或者说字符串的不可变性会带来什么好处呢?
答:字符串作为使用频率非常高的基本数据类型,它的不可变性可以避免字符串的并发安全问题,可以被多个Goroutine共享。此外字符串本身包含了字节序列的长度,使得获取字符串长度的操作时间复杂度是O(1)。
当然,这种不可变的特性也是有代价的,就是在对字符串修改的时候会产生副本而占用额外的内存空间。
面试题:通过unsafe.Sizeof计算字符串“hello”的结果是多少?为什么?
别急接着看下面的内容
String长度
我们先来看一个示例:
package main
import (
"fmt"
"unsafe"
)
func main() {
s1 := "abc"
s2 := "中文"
fmt.Println(len(s1), unsafe.Sizeof(s1))
fmt.Println(len(s2), unsafe.Sizeof(s2))
}输出:
3 16
6 16对于字母“abc”,其len为3,而字符串“中文”二字的长度为6,可见在Go语言中len不能简单理解为字符串中的字符个数。为什么一个中文字符的长度是3而一个英文字母的长度却是1呢?
理解字符串len
首先我们需要理解字符串len到底指什么?
字符串的len其实是指这个字符串中字节个数而非字符个数。
理解字符串编码
我们知道 Go 语言的字符串是以 UTF-8 格式保存的,而UTF-8编码是Unicode的编码的一种实现方式。
为了解决字符集间互不兼容的问题,包罗万象的 Unicode 字符集出场了。Unicode(统一码)由非营利组织统一码联盟负责,整理了世界上大部分的字符系统,使得计算机可以用更简单统一的方式来呈现和处理文字。
Unicode 本身只定义了字符与码点的映射关系,相当于定义了一套标准,而这套标准真正在计算机中落地时,则有多种编码格式。
目前常见到的有 3 种编码格式:UTF-8、UTF-16 和 UTF-32。
UTF是 Unicode Transformation Format 的缩写,意思是 Unicode 字符转换格式。
码点
字符的编码方式是为了解决字符的码点值在计算机中如何存储和表示的问题。Unicode标准为全球各种人类语言中的每个字符制定了一个独一无二的值。 但Unicode标准中的基本单位不是字符,而是码点(code point)。
在UTF-8编码中,一个码点值可能由1到4个字节组成。
UTF-8编码为了节省空间,是根据码点值的大小进行存储的。
比如0到127的码点值用一个字节即可存储,所以码点值小的前 128 个字符的码点值(U+0000~U+007F)使用 1 个字节表示,而且这128个字符的码点是与 ASCII 字符重合的码点;
带变音符号的拉丁文、希腊文、西里尔字母、阿拉伯文等使用 2 个字节来表示;
而东亚文字(包括汉字)使用 3 个字节表示;
其他极少使用的语言的字符则使用 4 个字节表示。
比如,每个英文码点值都是由一个字节组成,而每个中文码点值均由三个字节组成。码点本质上是将所有Unicode 字符集中按照一定的顺序排列后给每个字符的一个固定序列号,这个序列号的值就是码点。
上面的例子中字符串“abc”是由3个码点组成,每个码点需要一个字节进行UTF-8编码。而字符串“中文”是由2个码点组成,每个码点需要3个字节进行UTF-8编码。
码点很好理解,它的前 128 个字符其实跟 ASCII码是一一致的,只是unicode编码能表示更多的字符,当然也是由不同的组织维护的。
如果我们需要获取字符串的Unicode 字符个数,应该怎么获取呢?
Go语言提供了一个rune类型,用来表示一个Unicode 码点。所以我们可以先将字符串转成rune类型的切片,再计算切片的个数就能得到这个字符串的Unicode码点的个数,也就该字符的Unicode字符数了。
例如以下示例:
func main() {
s1 := "abc"
s2 := "中文"
fmt.Println(UnicodeLen(s1), UnicodeLen(s2)) //输出:3,2
}
func UnicodeLen(s string) int {
r := []rune(s)
return len(r)
}同样,如果需要按照字符去迭代用一个字符串我们也需要先转成rune, 要获取字符串的字符长度可以转为rune
for i, b := range s2 {
fmt.Println(i, b)
}
fmt.Println("======================")
for i, c := range []rune(s2) {
fmt.Println(i, c)
}
fmt.Println("======================")
for i, c := range []rune(s2) {
fmt.Printf("i:%d;c:%s", i, string(c))
}输出:
0 20013
3 25991
======================
0 20013
1 25991
======================
i:0;c:中i:1;c:文理解了len的含义我们再来看字符串的Sizeof值。为什么上面字符串“abc”和字符串“中国”的Sizeof值都是16呢?
这是因为unsafe.Sizeof返回的是数据类型的大小,而string在Go语言中其实是一个结构体类型:
type StringHeader struct {
Data uintptr //指向底层字节切片的指针
Len int //表示字符串的字节数
}我们可以看到字符串的运行时表示中,字符串是包含了两个字段的,一个具体的数据指针,为uintptr类型,还有一个就是字符串的长度,为int类型。在64位操作系统上uintptr和int都是8字节,所以字符串这种数据类型的大小为16。
String原理小结
Go 语言的字符串类型是一个只读的字节切片,原生支持 UTF-8 编码。字符串的底层存储结构是一个结构体,这个结构体有两个字段,分别是字符串的字节数和指向存储字符串数据的字节切片的指针。其中字节数是int类型,字节切片的指针是uintptr类型,所以字符串这种数据类型的大小为16.需要注意的是,字符串的len是指字符串的字节数并不是其实际的字符个数。如果需要获取字符个数可以转成rune的切片类型在计算切片的长度。
字符串可以被重新赋值,但不允许直接通过下标修改其字符。这种不可变性确保了字符串操作的并发安全性。
不同String拼接方式的性能分析
1. 使用+拼接
示例:
s1 := "ab"
s2 := "cd"
fmt.Println("连接符 +:", s1+s2)由于字符串是不可变的,使用+拼接两个字符串时,会生成一个新的字符串。这个操作就需要开辟一段新的空间,每拼接一次都需要开辟一次空间,所以使用这种方式拼接大量字符串时会导致频繁的对象创建,同时旧的对象需要被GC回收,导致拼接大量字符串时效率低下。
2. 字符串格式化函数fmt.Sprintf
s1 := "ab"
s2 := "cd"
s := fmt.Sprintf("%s%s", s1, s2)
fmt.Println("fmt.Sprintf:", s)源码:
func Sprintf(format string, a ...any) string {
p := newPrinter()
p.doPrintf(format, a)
s := string(p.buf)
p.free()
return s
}
// newPrinter allocates a new pp struct or grabs a cached one.
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}从源码中可以看到,函数fmt.Sprintf在对字符串操作过程中会创建新对象,并使用了对象池,并且每次拼接都会对字符串切片进行强制转化,每次拼接操作都需要经历对象创建,字符串格式化,string转化和对象释放的操作,所以整体性能较差。
3. 预分配bytes.Buffer
s1 := "ab"
s2 := "cd"
var buf bytes.Buffer
buf.Grow(len(s1) + len(s2))
buf.WriteString(s1)
buf.WriteString(s2)
fmt.Println("bytes.Buffer:", buf.String())bytes.Buffer跟+号拼接的不同点在于,它实现了一种预分配机制,当有新的字符串需要追加时,它可能会预申请更多的空间,避免后续频繁的空间申请。
我们可以通过下面的代码进行验证:
func BuilderCapResize() {
var str = "abcd"
var builder bytes.Buffer
cap := 0
for i := 0; i < 10000; i++ {
if builder.Cap() != cap {
fmt.Println(builder.Cap())
cap = builder.Cap()
}
builder.WriteString(str)
}
}输出:
64
128
256
512
1024
2048
4096
8192
16384
32768
655364. 预分配strings.Builder
s1 := "ab"
s2 := "cd"
var bu strings.Builder
bu.Grow(len(s1) + len(s2))
bu.WriteString(s1)
bu.WriteString(s2)
fmt.Println("strings.Buffer:", bu.String())strings.Builder跟bytes.Buffer类似,也有预分配机制,但预分配规则有所差异,我们可以通过下面的代码进行验证:
func BuilderCapResize() {
var str = "abcd"
var builder strings.Builder
cap := 0
for i := 0; i < 10000; i++ {
if builder.Cap() != cap {
fmt.Println(builder.Cap())
cap = builder.Cap()
}
builder.WriteString(str)
}
}输出:
8
16
32
64
128
256
512
1408
2048
3072
4096
5376
6912
9472
12288
16384
21760
28672
40960扩容源码:
func (b *Builder) Grow(n int) {
b.copyCheck()
if n < 0 {
panic("strings.Builder.Grow: negative count")
}
if cap(b.buf)-len(b.buf) < n {
b.grow(n)
}
}
func (b *Builder) grow(n int) {
buf := make([]byte, len(b.buf), 2*cap(b.buf)+n)
copy(buf, b.buf)
b.buf = buf
}可见,当buffer的容量减去buffer的长度小于当前需要追加的字符串长度时才会触发扩容,并且扩容到当前2被的buffer容量加上当前需要追加的字符串的长度。
总结:strings.Builder整体性能比bytes.Buffer略高,虽然strings.Builder 和 bytes.Buffer 底层都是一个 []byte,但是 bytes.Buffer 转换字符串时重新申请了内存空间用来存放, 而 strings.Builder 直接将底层的 []byte 转换为字符串返回。
5. 预分配[]byte
s1 := "ab"
s2 := "cd"
bt := make([]byte, 0, len(s1)+len(s2))
bt = append(bt, s1...)
bt = append(bt, s2...)
fmt.Println("预分配[]byte:", string(bt))[]byte是切片类型,切片本身也会有预扩容机制,所以不管是我们是否预先申请全部空间,由于byte切片也需要经过string的转化,所以总体性能比strings.Builder略差。
6. strings.join
sl := []string{"ab", "cd"}
str := strings.Join(sl, "")
fmt.Println("strings.Join:", str)源码:
// Join concatenates the elements of its first argument to create a single string. The separator
// string sep is placed between elements in the resulting string.
func Join(elems []string, sep string) string {
switch len(elems) {
case 0:
return ""
case 1:
return elems[0]
}
n := len(sep) * (len(elems) - 1)
for i := 0; i < len(elems); i++ {
n += len(elems[i])
}
var b Builder
b.Grow(n)
b.WriteString(elems[0])
for _, s := range elems[1:] {
b.WriteString(sep)
b.WriteString(s)
}
return b.String()
}通过源码可以看出strings.join也是基于strings.builder来实现的。但是join方法内调用了b.Grow(n)方法进行了容量的预分配,由于传入的切片长度固定,所以提前进行容量分配可以减少内存分配,这个拼接方式是非常高效的。
经过基准测试得出结论:
大量字符串使用+进行拼接,如果固定字符串使用常量会节省一定的空间,因为常量是编译期间预分配的,但是在频繁进行追加常量字符串的情况下,其执行效率不一定比追加变量字符串要高。但是两个常量字符串的拼接一定会比两个变量字符串的拼接快很多,且内存占用也会更小(通过BenchmarkStringPlus3-16和BenchmarkStringPlus4-16的运行结果可以看出)。
fmt.sprintf的执行效率跟+拼接相近。byte切片使用预分配空间进行字符串追加,其执行效率有显著提升。byte切片转字符串使用零拷贝转换可以进一步提升执行效率降低内存占用。
拼接性能总结
当拼接两个固定字符串时,可以将其定义为常量。strings.Builder在大量字符串拼接的场景下性能表现比较出众,也是官方推荐的字符串拼接方式,在拼接大量字符串和高并发场景下推荐使用。日常使用不必过于纠结,更多的关注代码的风格和可读性即可,因为代码的简洁本身也是一种生产力,只有在极少的情况下需要考虑极致性能的场景下去选择性能更高的拼接方式。
字符串切片导致的内存泄露分析
字符串底层存储的实际是指向一个字节切片的指针。在使用字符串的过程中,特别大量字符串的截取操作的场景,我们就需要关注字符串操作过程中的内存占用。
字符串切片导致的内存泄露通常是因为对字符串进行截取的情况,截取后的字符串切片引用了原始字符串,在某些场景下无法及时释放对原始字符串的引用,导致原始字符串无法被垃圾回收。这种情况下,切片会持有原始字符串的内存,即使不再需要该切片,原始字符串的内存也无法释放,从而导致内存泄露。
避免切片引用原始字符串导致内存泄露
将子字符串表达式的结果转换为一个字节切片,再转成string类型
s1 = string([]byte(s[:20]))从上面的示例代码中我们可以看出,这里会发生2次内存拷贝。一次是截取后进行了字节切片的转换,另一次是字节切片转字符串。
截取后在前面+拼接一个新字符串再从第一个字符串开始截取
s1 := (" " + s[:20])[1:]由于字符串的不可变性,拼接的动作会生成新的字符串副本,使得字符串的底层字节切片拷贝到了一个新的内存空间。这种方式进行一次内存拷贝,只会浪费一个字节的空间。
使用strings.Builder对新字符串进行重新构造
var b strings.Builder b.Grow(20) b.WriteString(s[:20]) s1 := b.String()这种方式是直接重新构造一个字符串,生成的字符串显然也会指向新的内存块
字符串转成 byte 切片,会发生内存拷贝?
这个问题先看示例:
package main
import (
"fmt"
"reflect"
"strings"
"unsafe"
)
func main() {
s := strings.Repeat("1", 1<<20)
ptr := (*reflect.StringHeader)(unsafe.Pointer(&s))
fmt.Println("s pointer:", unsafe.Pointer(ptr.Data))
//转字节切片
s1 := []byte(s) //新空间
ptr = (*reflect.StringHeader)(unsafe.Pointer(&s1))
fmt.Println("s1:", unsafe.Pointer(ptr.Data))
//强转
s2 := string(s1) //新空间
ptr = (*reflect.StringHeader)(unsafe.Pointer(&s2))
fmt.Println("s2:", unsafe.Pointer(ptr.Data))
s3 := *(*string)(unsafe.Pointer(&s1)) //零拷贝,共用底层结构,将s1的指针转为通用指针类型,然后再将其转为string的指针,最后取地址值
ptr = (*reflect.StringHeader)(unsafe.Pointer(&s3))
fmt.Println("s3:", unsafe.Pointer(ptr.Data))
//字节切片转字符串
s4 := string(s1) //新空间
ptr = (*reflect.StringHeader)(unsafe.Pointer(&s4))
fmt.Println("s4:", unsafe.Pointer(ptr.Data))
s5 := *(*[]byte)(unsafe.Pointer(&s)) //零拷贝
ptr = (*reflect.StringHeader)(unsafe.Pointer(&s5))
fmt.Println("s5:", unsafe.Pointer(ptr.Data))
s6 := stringToBytes(s)
ptr = (*reflect.StringHeader)(unsafe.Pointer(&s6))
fmt.Println("s6:", unsafe.Pointer(ptr.Data))
}
func stringToBytes(s string) []byte {
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
b := *(*[]byte)(unsafe.Pointer(&reflect.SliceHeader{
Data: strHeader.Data,
Len: strHeader.Len,
Cap: strHeader.Len,
}))
return b
}输出:
s pointer: 0x11500000
s1: 0x11600000
s2: 0x11700000
s3: 0x11600000
s4: 0x11800000
s5: 0x11500000
s6: 0x11500000结论:
我们可以看到字符串s转成字节切片s1后,其底层指向的字符串的实际存储地址是发生了改变的。说明字符串在转字节切片的过程是发生了内存拷贝的。实际上,将字符串转换为字节切片 bytes,会在内存中创建一个新的字节切片,并将字符串的内容复制到新的字节切片中。这样做是为了避免在字节切片中修改字符串的内容,因为字符串是不可变的。将字节切片s1强转成字符串s2同样也发生了内存拷贝。
如果要实现高效的字符串与字节切片之间的转换就需要减少或避免额外的内存分配操作。
可以通过使用 unsafe 包来实现字符串到字节切片的零拷贝转换。但是要注意,使用 unsafe 包是不安全的,因为它可以绕过 Go 语言的类型系统和内存安全检查。在一般情况下,建议使用标准的字符串转换方法 []byte(str) 来实现字符串到字节切片的转换,这样是安全且易于理解的方式。
Slice 底层原理
Slice的底层数据结构
直接看slice的底层数据结构:
源码位置:
$GOROOT/src/runtime/slice.go
type slice struct {
array unsafe.Pointer //指向底层数组的指针:指向切片引用的底层数组的起始位置
len int //切片的长度:表示切片中元素的个数
cap int //切片的容量:表示底层数组中可访问的元素个数,从切片的第一个元素开始算起。(cap>=len)
}切片的底层存储结构为:

Go 编译器在创建的切片的时候会给切片创建一个底层数组,默认情况下这个数组的长度跟切片元素的个数是相等的,当后续向切片追加元素时会对切片进行扩容,以避免频繁的空间申请。
如何去理解切片和数组的本质差异呢?
其实我们可以把切片理解为数组的描述符,这里的描述符其实就是切片的直接值部。切片在赋值及传参过程中都是直接值部进行传递,也就是切片底层数据的地址,长度和容量信息。而这些信息在传值过程中的代价是很小的,而数组在作为函数参数传递的过程中会将数组的值传递到函数中,这样对于大数组的参数传递代价是很大的。所以切片的结构我们可以类比文件的快捷方式,我们复制一个快捷方式并不会复制原始文件,通过快捷方式我们也能访问到实际的文件。这里的快捷方式可以理解为切片变量,实际的文件就可以理解为切片所指向的数组元素。
切片的特性
切片的设计是为了弥补数组的缺陷,数组有两个明显的缺陷:
- 元素个数不可变;
- 传值开销大
所以切片的两个重要特性跟上面两点刚好相反:
- 切片的元素个数是可变的,支持动态追加元素到切片。为了避免动态追加元素导致频繁的内存空间的申请,所以切片还有个容量的属性,可以在追加切片的过程中动态扩容以减少内存空间的申请次数;
- 切片传值的过程传递的是底层数据所指向的指针地址,传值开销小。
下面来看一个示例:
package main
import (
"log"
"strconv"
"unsafe"
)
func init() {
log.SetFlags(log.Lshortfile)
}
func main() {
arr := [3]int{1, 2, 3}
log.Printf("arr:%p", &arr) // arr:0x14000016090
f1(arr) // f1 arr:0x140000160c0
s := []int{1, 2, 3}
log.Printf("s:%p", s) // s:0x140000160d8
f2(s) // f2 s:0x140000160d8
s1 := s
log.Printf("s1 ptr: %p", s1) //s1 ptr: 0x140000160d8
f3(s) //f3 param:0x140000160f0
log.Printf("s : %v; ptr: %p", s, s) //s : [1 2 3]; ptr: 0x140000160d8
s2 := s[:1]
log.Printf("s2 : %v;s2-cap:%d ptr: %p", s2, cap(s2), s2) //s2 : [1];s2-cap:3 ptr: 0x140000160d8
s3 := s[1:2]
log.Printf("s3 : %v;s3-cap:%d ptr: %p", s3, cap(s3), s3) //s3 : [2];s3-cap:2 ptr: 0x140000160e0
//64位OS, 所以对于int值的尺寸需要根据strconv.IntSize获取
log.Println(strconv.IntSize) //64
for i, v := range s {
log.Printf("i:%d,v:%d,ptr:%v,uintptr:%v", i, v, unsafe.Pointer(&s[i]), uintptr(unsafe.Pointer(&s[i])))
}
// i:0,v:1,ptr:0x140000160d8,uintptr:1374389625048
// i:1,v:2,ptr:0x140000160e0,uintptr:1374389625056
// i:2,v:3,ptr:0x140000160e8,uintptr:1374389625064
}
func f1(a [3]int) {
log.Printf("f1 arr:%p", &a)
}
func f2(param []int) {
log.Printf("f2 s:%p", param)
}
func f3(param []int) {
s3 := []int{4, 5, 6}
param = s3
log.Printf("f3 param:%p", param)
}
我们可以看到,数组通过参数传到函数中其地址是发生改变了的,在main函数中变量arr的地址为0x14000016090,而传参到函数f1后,其地址变为0x140000160c0;
而切片在main函数中和传参到f2函数,其地址都为0x140000160d8。
在main函数中对切片进行赋值后其地址也跟s是一样的,因为切片的赋值和传值都是拷贝的直接值部,也就是相当与文件快捷方式的复制,他们指向的底层存储还是同一个。
在函数f3中,我们对传进进来的参数param进行了重新赋值,结果实参的地址发生了变化,并且main的切片s并没有改变。这一点可能跟我们对其他很多编程语言中值传递和指针传递的认知会有区别。如果我们把切片传值看成是指针传递或者引用传值,就很难解释这个现象。其实对于Golang中赋值和传参我们不能使用简单的值传递或者引用传递去看这个问题,之前反复介绍直接值部和间接值部的概念也是这个原因。如果我们理解了golang中切片的赋值是直接值部的赋值就很容易理解这里的现象了。前面我们强调过在Go语言中赋值操作和函数调用传参都是将原始值的直接部分复制给了目标值。如果原始值含有间接部分,则在赋值完成后,目标值和原始值的直接部分将引用着相同的间接部分。也就是说,两个值共享了底层的间接值部。对于函数f3中,首先s3的声明会申请一个新的切片,s3赋值给param的过程本质上是将s3的直接值部赋值给了param。可以理解为实参param作为一个快捷方式,之前是指向文件a,现在指向了文件b。所以文件a只是少了一个引用关系,它本身存储的值并未发生改变(简单点说就是:go本质上是值传递,然后入参的切片底层的指针被指向了一个新切片)。
切片的赋值过程,可以通过下面的示意图来理解:

此外,切片的截取也只是相当于改变了快捷方式中的一些元信息,比如切片的长度信息。而它的数据其实跟切片s共享了同一块内存空间,当我们从切片的第2个元素(也就是下标为1的元素开始截取时),截取后切片的起始地址是指向了原切片第2个元素的起始地址。这里同样需要注意切片截取过程中的内存泄露问题,在前面讲到的字符串切片的内存泄露是同样的问题。
slice的如何扩容机制
先看示例:
package main
import "log"
func init() {
log.SetFlags(log.Lshortfile)
}
func main() {
s := []int{1, 2, 3}
log.Printf("s-ptr:%p; s-cap:%d", s, cap(s))
s = append(s, 4)
log.Printf("s-ptr:%p; s-cap:%d", s, cap(s))
s = append(s, 5)
log.Printf("s-ptr:%p; s-cap:%d", s, cap(s))
}输出:
main.go:10: s-ptr:0xc0000aa060; s-cap:3
main.go:12: s-ptr:0xc0000be0c0; s-cap:6
main.go:14: s-ptr:0xc0000be0c0; s-cap:6通过上面的例子,我们发现第一次对切片进行追加元素时,内存地址会发生变化,而再次追加元素时,内存地址却没有变化,同时在第二追加元素后,切片的容量从开始的3变成了6.
这说明切片在追加的过程中会触发扩容,由于切片的地址是连续的,扩容后需要分配一块连续的内存空间给切片,所以一旦发生扩容就可能会产生内存拷贝,将原切片拷贝到一块新的内存空间。这也就是为什么发生扩容后切片的起始地址会发生改变的原因。
我在网上看到的一些结论:
使用 append 向切片追加元素的时候,实际上是往底层数组添加元素。但是底层数组的长度是固定的,它在声明的时候就申请了固定的一段连续的内存空间,没法再添加新的元素了。如果需要追加新的元素就需要将底层数组迁移到新的内存位置,新底层数组的长度也会增加,这样就可以放置新增的元素。同时,为了应对未来可能再次发生的 append 操作,新的底层数组的长度,也就是新 slice 的容量是留了一定的 buffer 的。否则,每次添加元素的时候,都会发生迁移,成本太高。而切片的扩容规则也就是新 slice 预留的 buffer 大小的规则。网上大多数的文章都是这样描述的:当原 slice 容量小于 1024 的时候,新 slice 容量变成原来的 2 倍;原 slice 容量超过1024 ,新 slice 容量变成原来的 1.25 倍
对于”原 slice 容量超过1024 ,新 slice 容量变成原来的 1.25 倍”这种说法其实是不准确的,我们根据切片扩容的源码具体来看看总结规则:
代码路径:
$GOROOT\src\runtime\slice.go
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
// oldLen 为旧的切片底层数组的长度
oldLen := newLen - num
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(oldPtr, uintptr(oldLen*int(et.size)), callerpc, abi.FuncPCABIInternal(growslice))
}
if msanenabled {
msanread(oldPtr, uintptr(oldLen*int(et.size)))
}
if asanenabled {
asanread(oldPtr, uintptr(oldLen*int(et.size)))
}
// 分配的新的长度不能小于 0(整数溢出的时候会是负数)
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
// 如果结构或数组类型不包含大小大于零的字段(或元素),则其大小为零。
//(空数组、空结构体,type b [0]int、type zero struct{})
// 两个不同的零大小变量在内存中可能具有相同的地址
if et.size == 0 {
// append 不应创建具有 nil 指针但长度非零的切片。
// 在这种情况下,我们假设 append 不需要保留 oldPtr。
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
// newcap 是新切片底层数组的容量
newcap := oldCap
// 两倍容量
doublecap := newcap + newcap
if newLen > doublecap {
// 如果追加元素之后,新的切片长度比旧切片 2 倍容量还大,
// 则将新的切片的容量设置为跟长度一样
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
// 旧的切片容量小于 256 的时候,进行两倍扩容
newcap = doublecap
} else {
// oldCap >= 256 检查 0<newcap 以检测溢出并防止无限循环。
for 0 < newcap && newcap < newLen {
// 从小切片的增长 2 倍过渡到大切片的增长 1.25 倍
newcap += (newcap + 3*threshold) / 4
}
// 当 newcap 计算溢出时,将 newcap 设置为请求的上限
if newcap <= 0 {
newcap = newLen
}
}
}
// 计算实际所需要的内存大小
// 是否溢出
var overflow bool
// lenmem 表示旧的切片长度所需要的内存大小
//(lenmem 就是将旧切片数据复制到新切片的时候指定需要复制的内存大小)
// newlenmem 表示新的切片长度所需要的内存大小
// capmem 表示新的切片容量所需要的内存大小
var lenmem, newlenmem, capmem uintptr
//根据 et.size 做一些计算上的优化:
// 对于 et.size= 1,我们不需要任何除法/乘法。
// 对于 goarch.PtrSize,编译器会将除法/乘法优化为移位一个常数。
// 对于 2 的幂,使用可变移位。
switch {
case et.size == 1://// 比如 []byte,所需内存大小 = size
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize:
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):// 比如 []int64,所需内存大小 = size << shift,也就是 size * 2^shift(2^shift 是 et.size)
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.TrailingZeros64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.TrailingZeros32(uint32(et.size))) & 31
}
lenmem = uintptr(oldLen) << shift
newlenmem = uintptr(newLen) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
capmem = uintptr(newcap) << shift
default:
lenmem = uintptr(oldLen) * et.size
newlenmem = uintptr(newLen) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
capmem = uintptr(newcap) * et.size
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from oldLen to newLen.
// Only clear the part that will not be overwritten.
// The reflect_growslice() that calls growslice will manually clear
// the region not cleared here.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in oldPtr since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(oldPtr), lenmem-et.size+et.ptrdata)
}
}
// 旧切片数据复制到新切片中,复制的内容大小为 lenmem
//(从 oldPtr 复制到 p)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}
}通过上面的源码我们可以发现, 切片并非简单的按照之前容量的倍数进行扩容的,当然,不同的Go版本可能会有所区别,go1.20.4中大致规则可总结如下:
当切片在容量较小的情况下,确实会进行 2 倍扩容,但是随着容量的增长,扩容的增长因子会逐渐降低。 新版本的 growslice 实现中,只有容量小于 256 的时候才会进行 2 倍扩容, 然后随着容量的增长,扩容的因子会逐渐降低,但并不是直接降到 1.25,而是根据类型的size会做一些优化。我们需要理解的是这种扩容方式的的好处在哪里,这是我们值得借鉴的。当切片容量较小时,进行2倍扩容不会占用太多额外空间,也减少了内存分配的次数。但当切片容量过大时,按照倍数扩容就很浪费存储空间了,这其实是在存储和计算之间进行的权衡,而切片的扩容方式就是充分考虑到内存分配次数和内存空间的占用之间的平衡而设计的一套算法规则。
使用建议
在实际应用中,如果我们事先知道切片的容量大小,可以通过使用 make 函数预分配足够的容量,避免频繁的扩容操作。例如:
slice := make([]int, 0, 1000) // 创建一个容量为 1000 的切片通过预分配足够的容量,可以避免频繁的扩容操作,提高程序的性能。
思考题
package main
import "fmt"
func main() {
// 题目 1: 切片的基本操作
a := []int{1, 2, 3, 4, 5}
b := a[1:4]
b[0] = 10
fmt.Println(a) // 输出: [1 10 3 4 5]
fmt.Println(b) // 输出: [10 3 4]
// 题目 2: 切片的容量和长度
c := make([]int, 3, 5)
fmt.Println(len(c), cap(c)) // 输出: 3 5
c = append(c, 1, 2, 3)
fmt.Println(len(c), cap(c)) // 输出: 6 10
// 题目 3: 切片的共享底层数组
d := []int{1, 2, 3, 4, 5}
e := d[:2]
f := d[2:]
e = append(e, 10)
fmt.Println(d) // 输出: [1 2 10 4 5]
fmt.Println(e) // 输出: [1 2 10]
fmt.Println(f) // 输出: [10 4 5]
// 题目 4: 切片的扩容
g := []int{1, 2, 3}
h := append(g, 4)
i := append(g, 5)
fmt.Println(g) // 输出: [1 2 3]
fmt.Println(h) // 输出: [1 2 3 4]
fmt.Println(i) // 输出: [1 2 3 5]
// 题目 5: 切片的零值
var j []int
if j == nil {
fmt.Println("j is nil") // 输出: j is nil
}
j = append(j, 1)
fmt.Println(j) // 输出: [1]
}Map底层原理
map的实现方式
map是由键值对key-value组成的,key只会出现一次,实现方式有下面两种:
哈希查找表(Hash table)
哈希查找表有一定的概率会出现“碰撞”问题,也就是不同的key可能会被hash到同一个bucket。通常有两种方式解决碰撞问题:链表法和开放地址法。
链表法是将所有哈希地址相同的记录都链接在同一条链表中,称为同义词子表,在哈希表中只存储所有同义词子表的头指针。
链表法的优点是简单且无堆积现象,由于非同义词不会发生冲突,因此平均查找长度较短;适合于造表前无法确定表长的情况;节省空间;删除操作易于实现,缺点是需要额外的指针空间;当装填因子较大时,查找效率会降低。
开放地址法是在发生碰撞时,通过某种探测技术在散列表中形成一个探测序列,沿此序列逐个单元地查找,直到找到给定的关键字或者碰到一个开放的地址为止。
开放地址法的优点是不需要额外的指针空间;当装填因子较小时,查找效率较高。开放地址法的缺点是探测过程复杂且可能失败;存在堆积现象,即非同义词也会发生冲突;删除操作困难。
Go语言使用就是哈希查找表并通过链表法来解决hash碰撞的问题。
搜索树(Search tree)
搜索树法一般采用自平衡搜索树,包括:AVL 树,红黑树。
Go map的底层数据结构
首先我们来看看map在源码中的定义:
源码位置:$GOROOT/src/runtime/map.go
// 定义了map的结构
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // 元素的个数, 也就是len() 的值
flags uint8 //map 的状态标记,用于标识 map 的各种状态,例如:1、有遍历器使用;2、有遍历器使用旧桶;3、有协程正在写入;4、等量扩容
B uint8 //bucket个数为:2^B;可以保存的元素个数:填充因子(默认6.5) * 2^B items)
noverflow uint16 /// 溢出桶数量
hash0 uint32 // 哈希因子
buckets unsafe.Pointer // Buckets数组,大小为 2^B
oldbuckets unsafe.Pointer // 发生扩容前的Buckets,在增长时非nil
nevacuate uintptr // 迁移状态,进度
extra *mapextra // 用于存储一些不是所有哈希表都需要的字段
}
type mapextra struct {
//指向bmap类型切片的指针,bmap类型是哈希表中存储数据的基本单元。
//overflow字段用于存储所有溢出桶的指针,溢出桶是当哈希表中某个位置发生冲突时,用于存放多余数据的额外桶。
//overflow字段只有在哈希表的键和值都不包含指针并且可以内联时才使用,这样可以避免扫描这些哈希表。
overflow *[]*bmap
//这也是一个指向bmap类型切片的指针,它用于存储旧哈希表中的溢出桶的指针,
//旧哈希表是当哈希表需要扩容时,原来的哈希表称为旧哈希表,新分配的哈希表称为新哈希表。
//oldoverflow字段也只有在键和值都不包含指针并且可以内联时才使用。
oldoverflow *[]*bmap
//指向bmap类型的指针,它用于存储一个空闲的溢出桶,当需要分配一个新的溢出桶时,就从nextOverflow中取出一个,
//如果nextOverflow为空,则从堆上分配一个新的溢出桶。
nextOverflow *bmap
}
//定义了hmap.buckets中每个bucket的结构
type bmap struct {
//tophash不仅仅用来存放key的哈希高8位,在不同场景下它还可以标记迁移状态,bucket是否为空等.当tophash对应的K/V被使用时,存的是key的哈希值的高8位;当tophash对应的K/V未被使用时,存的是K/V对应位置的状态
//bucketCnt 是常量=8,一个bucket最多存储8个key/value对
tophash [bucketCnt]uint8
}根据上面的结构我们可以知道map的键值对是存储到bucket里面的,每个bucket最多可以存储8个键值对。
map的结构示意图:
如何理解bmap
从什么的结构体可知buckets中是[]bmap切片,我们来看看bmap究竟是什么样的
type bmap struct {
tophash [bucketCnt]uint8
}上面的结构只是表面(src/runtime/hashmap.go)的结构,编译期间会被拓展,动态地创建一个新的结构:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}这就和上面图的bmap结构相对应,bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
接着来看示意图:

上图就是 bucket 的内存模型,HOB Hash 指的就是 top hash。 注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式。源码里说明这样的好处是在某些情况下可以省略掉 padding 字段,节省内存空间。
当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的情况下,会把 bmap 标记为不含指针,这样可以避免 gc 时扫描整个 hmap。但是,我们看 bmap 其实有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来。
type mapextra struct {
// overflow[0] contains overflow buckets for hmap.buckets.
// overflow[1] contains overflow buckets for hmap.oldbuckets.
overflow [2]*[]*bmap
// nextOverflow 包含空闲的 overflow bucket,这是预分配的 bucket
nextOverflow *bmap
}哈希函数
map 的一个关键点在于,哈希函数的选择。在程序启动时,会检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。这是在函数 alginit() 中完成,位于路径:src/runtime/alg.go 下。
hash 函数,有加密型和非加密型。 加密型的一般用于加密数据、数字摘要等,典型代表就是 md5、sha1、sha256、aes256 这种; 非加密型的一般就是查找。在 map 的应用场景中,用的是查找。 选择 hash 函数主要考察的是两点:性能、碰撞概率。
Key定位的流程
key 经过哈希计算后得到哈希值,共 64 个 bit 位(以64位机器为例),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。还记得前面提到过的 B 吗?
示例:
如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32。
例如,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
1001011100001111011011001000111100101010001001011001010101001010切分前8位和后5位得到:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010用后5 个 bit 位,也就是 01010,值为 10来确定哪一个桶,这里也就是 10 号桶。这个操作实际上就是取余操作,但是取余开销太大,所以代码实现上用的位操作代替。
再用哈希值的高 8 位,也就是10010111,其实就是bmap中的tophash字段,找到此 key 在 bucket 中的位置,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。buckets 编号就是桶编号,当两个不同的 key 落在同一个桶中,也就是发生了哈希冲突。冲突的解决手段是用链表法:在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key,如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
流程示意图:
map的写入流程
计算hash,确定key的位置
根据hash低位从buckets数组中确认存入buckets的位置;根据hash高8位确认bucket内的位置 确认key是否存在,若存在则获取数据存入地址,否则获取overflow buckets,继续第一步;
如果需要扩容,则进行扩容后,继续第一步;
如果buckets已满会存入overflow buckets,overflow buckets也满了,就会新建overflow bucket,获取key和elem的地址并存入数据
map的如何扩容机制
随着新的键值的写入,map会进行扩容,也会随着key的删除可能触发缩容。和切片不同的是map 可以根据新增的 key-value 动态的伸缩,因此map没有固定的长度限制,在使用make初始化的时候要我们可以指定其初始长度。我们来看看map具体是怎么进行扩容的?
map发生扩容情况
当map元素达到某个阈值
当map元素过多可能会增加 hash 冲突的概率,导致map读取效率下降因此当 map 的元素过多,超过一定的阈值后,就应该对 map 的数据元素进行重整,平衡数据的读取速度。这个阈值是由下面的扩容因子决定的:
bucketCntBits = 3 bucketCnt = 1 << bucketCntBits // Maximum average load of a bucket that triggers growth is 6.5. // Represent as loadFactorNum/loadFactorDen, to allow integer math. loadFactorNum = 13 loadFactorDen = 2 // overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor. func overLoadFactor(count int, B uint8) bool { return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen) }也就是count > LoadFactor * 2^B (LoadFactor =loadFactorNum/loadFactorDen=6.5)
计算示例:
// 扩容条件分解 count > LoadFactor * 2^B 其中: - count: map中的元素个数 - LoadFactor: 负载因子 6.5 - 2^B: 桶的数量 - B: 桶数量的幂次 // 例如: B = 4 时: - 桶数量 = 2^4 = 16 - 扩容阈值 = 6.5 * 16 = 104 - 当元素个数 > 104 时需要扩容
其中count 指的是当前 map 里的元素个数,2^B 是指当前 map 里 buckets 数组长度,从这可以看出元素越来越多,即 count 越来越大,则越可能触发扩容。
overflow 数量过多,但元素很少
这种情况的产生,是因为出现了大量数据的插入和删除,导致 overflow 不能回收,所以也要进行数据重整。
我们重点来看看第一种情况的扩容过程。首先,hmap 会先增加 B 的值,也就是 buckets 数组的数量。然后,重新计算 key 所需要迁移的桶的位置,以便让数据能均衡的分布在新老 buckets 桶里。当然,Go 并不会一下子就把所有的数据都迁移完毕,而是一种懒迁移的机制。它会等到用到某个 key 时,检查此时 key 的迁移状态,再作出迁移动作。从上面的扩容过程我们也可以看出为什么 map 是无序的了,因为原本在一个 bucket 上的数据有可能被迁移到其他的 bucket 上了,会被打乱顺序。
具体的扩容过程如下:
- 在扩容时,调用hashGrow函数,如果负载因子超载,则会进行双倍重建。当溢出桶的数量过多时,会进行等量重建。
- 新桶会存储到buckets字段,旧桶会存储到oldbuckets字段。map中extra字段的溢出桶也进行同样的转移。
- 数据转移遵循写时复制(copy on write)的规则,只有在真正赋值时,才会选择是否需要进行数据转移。也就说这个过程是渐进的,并不是一次性将所有键值对都搬移到新的哈希表中,而是逐步迁移的。这样可以避免一次性的大量内存分配和复制操作,减少了扩容时的性能开销;
- 在迁移的过程中,新的哈希表会被标记为正在扩容状态,这样在查找键值对时,会同时在新旧两个哈希表中进行查找,直到所有的键值对都已经迁移到新的哈希表中。
- 迁移完成后,旧的哈希表会被丢弃,释放其占用的内存空间。
- 需要注意的是,由于哈希表的大小是2的幂次方,因此扩容后的大小总是2的幂次方,这样可以保证哈希函数计算得到的哈希值能够在新的哈希表中找到对应的桶,避免了重新计算哈希值的开销。
总的来说,
map的扩容过程是一种动态的调整大小的机制,它允许map在存储越来越多的键值对时保持高效的查找性能。对于第二种情况的数据重整,就比较简单了。只要在当前 bucket 里收缩各个 overflow 到空位上即可。
map 中的 key 为什么是无序的
当我们向map中插入键值对时,map会首先计算键的哈希值,并根据哈希值找到对应的桶(bucket)。每个桶中存储着一个或多个键值对,最多8个。
- 由于哈希函数的随机性和哈希冲突的存在,不同的键可能会被映射到哈希表中的不同桶。因此,插入键值对的顺序并不能决定键在哈希表中的位置,导致
map中的键是无序的;或者说hash算法本身就无法确保key的有序性。 - 当我们对
map进行遍历时,每次遍历的顺序可能是不同的。前面我们讲过,map会进行懒迁移,当map的key被访问使会检查它的迁移状态从而可能会将这个key迁移到新的bucket。这也导致了map的无序性以及每次迭代时元素顺序的不确定性; - 从Go 1.12版本开始,Go语言在
runtime中引入了一种伪随机的哈希算法,以减少哈希冲突带来的风险。这种伪随机哈希算法使得同样的key在不同运行时或不同机器上可能会被映射到不同的桶,从而进一步增加了map中键的无序性。
在实际开发过程中我们经常需要按照指定的顺序处理map的数据,比如搜索业务中,我们得到的搜索结果是一个切片,但是在对这些数据的处理过程中我们需要将其转换成map,处理完数据后再将新的数据以切片的形式输出。这个过程中,如果我们不刻意对map进行排序,就可能导致最终输出的结果顺序会发生变化。
如果需要对map中的键进行排序,可以将键拷贝到一个切片中,并对切片进行排序。这样可以得到有序的键序列,但是需要额外的内存和时间开销。
package main
import (
"fmt"
"sort"
)
func main() {
m := make(map[int]string)
keys := make([]int, 0, 3)
m[1] = "v1"
m[2] = "v2"
m[3] = "v3"
for k, v := range m {
keys = append(keys, k)
fmt.Println("k:", k, "v:", v)
}
//对key进行排序
sort.Ints(keys)
//根据key的值对map进行遍历
for _, key := range keys {
fmt.Println("sorted key :", key, "value:", m[key])
}
}输出:
k: 2 v: v2
k: 3 v: v3
k: 1 v: v1
sorted key : 1 value: v1
sorted key : 2 value: v2
sorted key : 3 value: v3我们直接对m进行遍历时,它的元素输出顺序是随机的,我们可以多运行几次。然后通过排序后的key去访问map中的元素时,就可以按照预期的顺序读取map的元素了。
为什么不能对map的元素取地址
前面我们讲到map的底层数据结构是一个哈希表。当我们向map中添加键值对时,Go语言会自动进行扩容和重新哈希等操作,以保证map的性能和空间效率。而这些操作可能会导致map中的键值对在内存中重新分布。如果我们允许对map的元素取地址,并通过指针访问map中的键值对,那么当map进行扩容或重新哈希时,指向旧键值对的指针将会变得无效,这是map元素不能取址的本质原因。
具体而言,为了保证元素索引的效率,map底层的哈希表只会为它所有的键值维护一段连续的内存段。当map中键值对增加到一定程度时,就需要开辟新的内存段来扩容。扩容的过程是将原来内存段上的值全部拷贝到新开辟的内存段上。即使map的内存段没有触发扩容,某些哈希表的实现也可能在当前内存段中移动其中的元素。总之,map中元素的地址会因为各种原因改变。如果Go语言的map去维护这些指针值,会增加Go编译器和运行时的复杂度,最主要的是会影响程序的运行效率,所以Go不支持取map元素的地址。
nil map 和空 map 的区别
nil map
当一个map变量被声明但未初始化时,它的值为nil。这就是所谓的”nil map”,也就是未分配内存的map。
一个”nil map” 不能直接用于存储键值对,否则会导致运行时错误(panic)。如果试图向”nil map” 存储数据,会引发runtime panic,这一点跟切片是有区别的。
例如:
var m map[string]int // 这是一个nil map
fmt.Println(m) // 输出: map[]
fmt.Println(m["key"]) //0
delete(m, "key")
m["key"] = 1 // 运行时错误: panic: assignment to entry in nil map空 map
“空 map” 是指已经初始化的map,但其中没有任何键值对。
空 map 是合法的,可以直接用于存储和读取键值对,而不会引发运行时错误。
m := make(map[string]int) // 这是一个空 map
fmt.Println(m) // 输出: map[]
m["key"] = 1 // 添加键值对
fmt.Println(m) // 输出: map[key:1]所以nil map和空map的本质区别体现在是否分配内存,也就是是否对map类型变量进行了初始化。
需要注意的是,切片和map在赋值的表现上是有差异的
package main
import "log"
func init() {
log.SetFlags(log.Lshortfile)
}
func main() {
m := make(map[string]string)
m1 := m
m1["age"] = "18"
m["name"] = "iceymoss"
log.Printf("m:%v;ptr:%p", m, m) //输出: m:map[age:18 name:iceymoss];ptr:0x1400007e0f0
log.Printf("m1:%v;ptr:%p", m1, m1) //输出: m1:map[age:18 name:iceymoss];ptr:0x1400007e0f0
s := make([]string, 0, 10)
s1 := s
log.Printf("s:%v;ptr:%p", s, s) //输出: s:[];ptr:0x14000116000
log.Printf("s1:%v;ptr:%p", s1, s1) //输出: s1:[];ptr:0x14000116000
s1 = append(s1, "v1")
log.Printf("s:%v;ptr:%p", s, s) //输出: s:[];ptr:0x14000116000
log.Printf("s1:%v;ptr:%p", s1, s1) //输出: s1:[v1];ptr:0x14000116000
}从上面示例中可以看到:map重新赋值后m1和m是共享同一块底层空间的,所以当我们向赋值后的map(m1)中增加元素时,赋值前的map(m)中也会有这个元素;
map 中删除一个 key,它的内存会释放么
先说结论:删除map的key是无法达到回收map内存空间的目的的。即map不会因为删除了一个键值对而自动缩小哈希表的容量,因为map的扩容机制,golang语言中的map使用了一种称为渐进式扩容法的动态调整方法,它只会在插入新元素时根据装填因子来判断是否需要扩容,并且扩容过程是分批进行的,也就是我们前面讲到的懒迁移的策略。所以map中即使删除了key也不会立马回收空间。
接下来可以验证一下:
package main
import (
"fmt"
"log"
"runtime"
)
const Cnt = 10000000
var m = make(map[int]int, Cnt)
func init() {
log.SetFlags(log.Lshortfile)
}
func main() {
for i := 0; i < Cnt; i++ {
m[i] = i
}
runtime.GC()
log.Println(getMemStats())
for k, _ := range m {
delete(m, k)
}
runtime.GC()
log.Println(getMemStats())
m = nil
runtime.GC()
log.Println(getMemStats())
}
func getMemStats() string {
var m runtime.MemStats
runtime.ReadMemStats(&m)
return fmt.Sprintf("分配的内存 = %vKB, GC的次数 = %v\n", m.Alloc/1024, m.NumGC)
}输出:
main.go:22: 分配的内存 = 314382KB, GC的次数 = 2
main.go:27: 分配的内存 = 314384KB, GC的次数 = 3
main.go:30: 分配的内存 = 104KB, GC的次数 = 4map的内存泄露问题
删除map的key之后,其元素是没法被GC回收的,也就说map的容量只能增加不能减少,当频繁删除map中的元素时,它们所占用的桶并不会主动被释放,从而可能出现内存泄露。
那我们如果希望手动去触发map的空间回收,可以怎么实现呢?
如果想要减少map所占用的内存大小,需要重新创建一个新的map,并将旧map赋值为nil或者让它超出作用域范围,以便于垃圾回收器回收旧map。然后再将新的map赋值给旧的map。这样相当于强制对map进行了一次重整,就可以释放掉旧map中的key删除但而保留的内存空间。
正确的使用方式:
func mapMemoryRelease() {
// 原始map
oldMap := make(map[int]string)
// 添加数据
for i := 0; i < 1000000; i++ {
oldMap[i] = fmt.Sprintf("value_%d", i)
}
//注意不能直接newMap = oldMap,这样的话属于浅拷贝,他们还是够用底层的hmap的
// 深拷贝
// 删除数据后,创建新map
newMap := make(map[int]string, len(oldMap))
for k, v := range oldMap {
if k >= 900000 { // 只保留需要的数据
newMap[k] = v
}
}
// 释放旧map
oldMap = nil
// 重新赋值
oldMap = newMap
}总结下map使用过程中的几个注意点
- map不是线程安全的,不支持并发写,map 在进行读取 key 的时候会检查当前的 hmap.flags 字段,如果发现该值是一个写状态值的话,则会直接 panic;
- 不要依赖map的元素遍历顺序,因为map 的元素是无序的;
- 由于map元素会在访问后可能进行懒迁移,所以map的元素是不可寻址的,在编写代码过程中不要依赖map中value的地址;
- 尽量使用cap参数创建map,以提升map平均访问性能,减少频繁扩容带来的不必要损耗。
- 当使用 float 作为 map 的 key 时,由于 float 精度问题,会出现获取不到 float key 对应 value 的情况,所以应避免使用 float 作为map的key;
sync.Map的原理
sync map的底层数据结构
核心数据结构如下:
type Map struct {
//加锁,用于保护dirty字段
mu Mutex
// 存储只读数据,原子操作,并发安全
read atomic.Pointer[readOnly]
// 存储最新写入的数据,通过加锁确保并发安全
dirty map[any]*entry
//计数器,从read中读失败则+1,达到一定值时将dirty的数据提升为read
misses int
}
// readOnly is an immutable struct stored atomically in the Map.read field.
type readOnly struct {
m map[any]*entry // 只读map,用于快速读取
amended bool // 标记dirty map是否包含read map中没有的key
}sync.Map的底层数据结构本质上还是使用的map,只不过在map的基础上做了优化。从上面的结构体字段我们可以看出其在map上的一些优化:
实现并发安全的两个思路分别是 原子操作 和 加锁, 原子操作由于是直接面向硬件的一组不可分割的指令,所以效率要比加锁高很多,因此 Map 的基本思路就是尽可能多的使用原子操作,直到迫不得已才去使用锁机制,sync map使用了两个原生的map作为存储介质,分别是read map和dirty map(只读字典和脏字典),具体实现如下:
- read 和 dirty 两个字段将读写分离。读取时会先查询 read字段,不存在再查询 dirty,写入时则只写入 dirty。读取 read 不需要加锁,而读或写 dirty 都需要加锁。由于只需要在dirty 字段上加锁。这种读写分离的设计提高了sync.Map的读效率;
- 通过misses 字段来统计 read 被穿透的次数(被穿透是指在read上找不到需要读 dirty 的情况),超过一定次数则将 dirty 数据同步到 read 上;
- 删除数据通过标记来延迟删除;删除的过程同样也是也从read中查找,如果在read中,则调用delete()函数将key所指向的条目的指针设置为nil。否则就需要到dirty中查找再执行delete()方法。延时删除体现在当read和dirty一致的时,触发重塑的过程。重塑的过程,会将nil状态的entry,全部挤压到expunged状态中,同时将非expunged的entry浅拷贝到dirty中(所谓浅拷贝其实就是指针操作,并不是复制真实数据),这样可以避免read的key无限的膨胀(也就是存在大量逻辑删除的key)。最终,在dirty再次升级为read的时候,这些逻辑删除的key就可以被释放了。
sync.map的使用
这个没什么好说的,直接看示例:
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.WaitGroup{}
//m := make(map[int]int)
m := sync.Map{}
for i := 0; i < 10; i++ {
x := i
wg.Add(1)
go func() {
//m[x] = x
m.Store(x, x)
wg.Done()
}()
}
wg.Wait()
//按key读取
value, ok := m.Load(1)
if ok {
fmt.Println(value)
}
//遍历
m.Range(func(key, value any) bool {
fmt.Println("key:", key, "value:", value)
//if key == 3 {
// // 终止遍历
// return false
//}
return true
})
//支持不同类型的k/v
m.Store("k1", "v1")
v1, ok := m.Load("k1")
if ok {
fmt.Println(v1)
}
}输出:
1
key: 1 value: 1
key: 5 value: 5
key: 6 value: 6
key: 7 value: 7
key: 8 value: 8
key: 0 value: 0
key: 9 value: 9
key: 4 value: 4
key: 3 value: 3
key: 2 value: 2
v1sync map与普通map的区别
- 无须初始化,直接声明即可,普通map需要先通过字面量或者make进行初始化;
- sync map可以存储不同类型的数据,map的键和值的数据类型在声明时必须指定;
- sync.Map只能通过指定的方法进对键值进行读写,使用Store()方法来写入键值对,使用Load()方法获取指定key的value,使用 Delete方法删除指定key,同时还提供了两个特殊方法:LoadOrStore() 存在就返回,不存在就插入,LoadAndDelete 如果存在的话,同时删除这个 key
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,继续迭代遍历时,返回 false,终止遍历。
关于并发map的使用我们需要注意以下几点:
- 如果确定map不会存在并发冲突的问题,或者可以规避并发冲突的情况下尽量优先使用普通的map;
- sync map对元素的访问使用了读写分离的机制来减少锁操作。与普通map加锁实现相比,sync map的性能会更好,使用也更简单,所以遇到map并发场景可以直接使用sync map。
channel 的底层原理
channel是什么
Golang中的channel是一种用于goroutine之间通信的机制,它可以帮助我们实现并发编程中的数据传递和同步操作。
Go语言设计者对并发编程的建议是不要通过共享内存来通信,而是通过通讯来共享内存,这是Go语言的设计哲学,而通道就是实现这种设计哲学的工具。通过共享内存来通讯和通过通讯来共享内存是并发编程中的两种编程风格。 当通过共享内存来通讯的时候,我们需要一些传统的并发同步技术(比如互斥锁)来避免数据竞争。而Go语言提供的channel可以让并发同步通过通讯来共享内存。
channel的底层数据结构
channel的底层结构如下:
直接看源码:
源码路径:$GOPATH/src/runtime/chan.go
type hchan struct {
//当前队列中元素的个数。当我们向channel发送数据时,qcount会增加1;当我们从channel接收数据时,qcount会减少1
qcount uint
//如果我们在创建channel时指定了缓冲区的大小,那么dataqsiz就等于指定的大小;否则,dataqsiz为0,表示该channel没有缓冲区。
dataqsiz uint
//buf字段是一个unsafe.Pointer类型的指针,指向缓冲区的起始地址。如果该channel没有缓冲区,则buf为nil。
buf unsafe.Pointer
//表示缓冲区中每个元素的大小。当我们创建channel时,Golang会根据元素的类型计算出elemsize的值。
elemsize uint16
// channel 是否已经关闭,当我们通过close函数关闭一个channel时,Golang会将closed字段设置为true。
closed uint32
//表示下一次接收元素的位置.当我们从channel接收数据时,Golang会从缓冲区中recvx索引的位置读取数据,并将recvx加1
recvx uint
//表示下一次发送元素的位置。在channel的发送操作中,如果缓冲区未满,则会将数据写入到sendx指向的位置,并将sendx加1。如果缓冲区已满,则发送操作会被阻塞,直到有足够的空间可用。
sendx uint
// 等待接收数据的 goroutine 队列,用于存储等待从channel中读取数据的goroutine。当channel中没有数据可读时,接收者goroutine会进入recvq等待队列中等待数据的到来。当发送者goroutine写入数据后,会将recvq等待队列中的接收者goroutine唤醒,并进行读取操作。在进行读取操作时,会先检查recvq等待队列是否为空,如果不为空,则会将队列中的第一个goroutine唤醒进行读取操作。同时,由于recvq等待队列是一个FIFO队列,因此等待时间最长的goroutine会排在队列的最前面,最先被唤醒进行读取操作。
recvq waitq
// 等待发送数据的 goroutine 队列。sendq 字段是一个指向 waitq 结构体的指针,waitq 是一个用于等待队列的结构体。waitq 中包含了一个指向等待队列中第一个协程的指针和一个指向等待队列中最后一个协程的指针。当一个协程向一个 channel 中发送数据时,如果该 channel 中没有足够的缓冲区来存储数据,那么发送操作将会被阻塞,直到有另一个协程来接收数据或者 channel 中有足够的缓冲区来存储数据。当一个协程被阻塞在发送操作时,它将会被加入到 sendq 队列中,等待另一个协程来接收数据或者 channel 中有足够的缓冲区来存储数据。
sendq waitq
//channel的读写锁,确保多个gorutine同时访问时的并发安全,保证读写操作的原子性和互斥性。当一个goroutine想要对channel进行读写操作时,首先需要获取lock锁。如果当前lock锁已经被其他goroutine占用,则该goroutine会被阻塞,直到lock锁被释放。一旦该goroutine获取到lock锁,就可以进行读写操作,并且在操作完成后释放lock锁,以便其他goroutine可以访问channel底层数据结构。
lock mutex
}channel的结构示意图:

channel的底层数据结构是由一个双向链表(环形队列)和一个锁组成的。当一个goroutine向一个channel发送数据时,它会先获取锁,然后将数据添加到链表的末尾,并释放锁。当一个goroutine从一个channel接收数据时,它也会先获取锁,然后从链表的头部取出数据,并释放锁。
在Golang中,每个channel都有一个缓冲区(存在缓冲区为0的情况),用于存储传递的数据。当一个goroutine向一个channel发送数据时,数据会被放入缓冲区中,如果缓冲区已满,那么该goroutine会被阻塞到sendq的阻塞队列中,直到有足够的空间可以存储数据为止。当一个goroutine从一个channel接收数据时,数据会从缓冲区中取出,如果缓冲区为空,那么该goroutine会被阻塞到recvq的阻塞队列中,直到有数据可供接收为止。
当一个goroutine向一个已满的channel发送数据时,它会被阻塞,并加入到该channel的发送队列中。当一个goroutine从一个空的channel接收数据时,它也会被阻塞,并加入到该channel的接收队列中。当有数据可供发送或接收时,Golang的调度器会从相应的队列中取出一个goroutine,并将其唤醒,以便它可以执行发送或接收操作。
channel缓冲区
channel缓冲区是一个连续的内存空间,他是一个环形队列,用于存储 channel 中的元素。缓冲区的大小由 dataqsiz 字段指定。
等待队列
等待队列是一个包含多个 sudog 结构体的链表,用于存储正在等待发送或接收数据的 goroutine。当有数据可用时,等待队列中的 goroutine 会被唤醒并继续执行。
type waitq struct {
first *sudog // 队列头部指针
last *sudog // 队列尾部指针
}sudog 结构体
sudog是channel最核心的数据结构。sudog 代表了一个在等待队列中的 goroutine,它包含了等待的 goroutine 的信息,如等待的 channel、等待的元素值、等待的方向(发送或接收)等。
// sudog 结构体是一个用于等待队列中的 goroutine 的结构体,
// 它包含了等待的 goroutine 的信息,如等待的 channel、等待的元素值、
// 等待的方向(发送或接收)等。
type sudog struct {
// 等待的 goroutine
g *g
// 指向下一个 sudog 结构体
next *sudog
// 指向上一个 sudog 结构体
prev *sudog
//等待队列的元素
elem unsafe.Pointer
// 获取锁的时间
acquiretime int64
// 释放锁的时间
releasetime int64
//用于实现自旋锁。当一个gorutine需要等待另一个gorutine操作完成,
//而等待时间很短的情况下就会使用自旋锁。
//它会先获取当前的ticket值,并将其加1。然后,它会不断地检查结构体中的ticket字段是否等于自己的ticket值,
//如果相等就说明获取到了锁,否则就继续自旋等待。当锁被释放时,另一个goroutine会将ticket值加1,从而唤醒等待的goroutine。
//需要注意的是,自旋锁适用于等待时间很短的场景,如果等待时间较长,就会造成CPU资源的浪费
ticket uint32
// 等待的 goroutine是否已经被唤醒
isSelect bool
//success 表示通道 c 上的通信是否成功。
//如果 goroutine 是因为在通道 c 上接收到一个值而被唤醒,那么 success 为 true;
//如果是因为通道 c 被关闭而被唤醒,那么 success 为 false。
success bool
//用于实现gorutine的堆栈转移
//当一个 goroutine 调用另一个 goroutine 时,它会创建一个 sudog 结构体,并将自己的栈信息保存在 sudog 结构体的 parent 字段中。
//然后,它会将 sudog 结构体加入到等待队列中,并等待被调用的 goroutine 执行完成。
//当被调用的 goroutine 执行完成时,它会将 sudog 结构体从等待队列中移除,并将 parent 字段中保存的栈信息恢复到调用者的栈空间中。
//这样,调用者就可以继续执行自己的任务了。
//需要注意的是,sudog 结构体中的 parent 字段只在 goroutine 调用其他 goroutine 的时候才会被使用,
//因此在普通的 goroutine 执行过程中,它是没有被使用的。
parent *sudog // semaRoot binary tree
//用于连接下一个等待的 sudog 结构体
//等待队列是一个链表结构,每个 sudog 结构体都有一个 waitlink 字段,用于连接下一个等待的 sudog 结构体。
//当被等待的 goroutine 执行完成时,它会从等待队列中移除对应的 sudog 结构体,
//并将 sudog 结构体中的 waitlink 字段设置为 nil,从而将其从等待队列中移除。
//需要注意的是,waitlink 字段只有在 sudog 结构体被加入到等待队列中时才会被使用。
//在普通的 goroutine 执行过程中,waitlink 字段是没有被使用的。
waitlink *sudog // g.waiting list or semaRoot
//待队列的尾部指针,waittail 字段指向等待队列的尾部 sudog 结构体。
//当被等待的 goroutine 执行完成时,它会从等待队列中移除对应的 sudog 结构体,并将 sudog 结构体中的 waitlink 字段设置为 nil,
//从而将其从等待队列中移除。同时,waittail 字段也会被更新为等待队列的新尾部。
//需要注意的是,waittail 字段只有在 sudog 结构体被加入到等待队列中时才会被使用。
//在普通的 goroutine 执行过程中,waittail 字段是没有被使用的。
waittail *sudog // semaRoot
//在golang中,goroutine是轻量级线程,其调度由golang运行时系统负责。当一个goroutine需要等待某些事件的发生时,
//它可以通过阻塞等待的方式让出CPU资源,等待事件发生后再被唤醒继续执行。这种阻塞等待的机制是通过wait channel实现的。
//在sudog结构体中,c字段指向的wait channel是一个用于等待某些事件发生的channel。
//当一个goroutine需要等待某些事件时,它会创建一个sudog结构体,并将该结构体中的c字段指向wait channel。
//然后,它会将该sudog结构体加入到wait channel的等待队列中,等待事件发生后再被唤醒继续执行。
//当一个goroutine需要等待某些事件时,它会将自己加入到wait channel的等待队列中,并阻塞等待事件发生。
//当事件发生后,wait channel会将等待队列中的goroutine全部唤醒,让它们继续执行。
//这种机制可以有效地避免busy waiting,提高CPU利用率。
c *hchan // channel
}sudog 中所有字段都受 hchan.lock 保护。acquiretime、releasetime、ticket 这三个字段永远不会被同时访问。对 channel 来说,waitlink 只由 g 使用。只有在持有 semaRoot 锁的时候才能访问这三个字段。isSelect 表示 g 是否被选择,g.selectDone 必须进行 硬件同步原语(CAS) 才能在被唤醒的竞争中胜出。success 表示 channel c 上的通信是否成功。如果 goroutine 在 channel c 上传了一个值而被唤醒,则为 true;如果因为 c 关闭而被唤醒,则为 false。
g 结构体
g 结构体是 Golang 中的 goroutine 结构体,这个结构体比较复杂,它包含了 goroutine 的运行状态、栈信息、等待的信号等信息。
type g struct {
stack stack // goroutine 的栈信息
atomicstatus atomic.Uint32 // goroutine 的运行状态
sched gobuf // goroutine 调度器上下文信息
atomicstatus uint32 // 原子级别的 goroutine 运行状态
waitreason waitReason // goroutine 等待的原因
sig uint32 // goroutine 等待的信号
...
}有缓冲的channel和无缓冲的channel的区别
channel按照读写分类,可以分为下面几类:
单向只读channel
var readOnlyChan <-chan int // channel 的类型为 int单向只写channel
var writeOnlyChan chan<- int双向可读可写channel
var ch chan int注意:
- 写一个只读的channel或者读一个只写的channel都会导致编译不通过。
- 双向channel可以隐式装换成单向channel,但是单向channel无法隐式转换成双向channel,单向只读channel和单向只写channel之间也不能互相转换:
var c chan int var c2 chan<- int var c3 <-chan int c2 = c c3 = c c = c2 //编译不通过 c = c3 //编译不通过 c2 = c3 //编译不通过 fmt.Println(c2, c3)
按照有无缓冲可以分为下面两类:
每个channel值有一个容量属性。 一个容量为0的channel值称为一个非缓冲通道(unbuffered channel),一个容量不为0的通道值称为一个缓冲通道(buffered channel)
channel类型的零值也使用预声明的nil来表示。 一个非零通道值必须通过内置的make函数来创建。 比如make(chan int, 1)将创建一个元素类型为int且容量为1的通道值。 第二个参数指定了这个通道的容量。容量这个参数是可选的,它的默认值为0。
- 带缓冲区的 channel,定义了缓冲区大小,可以存储多个数据;
- 不带缓冲区的 channel,只能存一个数据,并且只有当该数据被取出才能存下一个数据.
readOnlyChanWithBuff := make(<-chan int, 2) // 只读且带缓存区的 channel
readOnlyChan := make(<-chan int) // 只读且不带缓存区 channel
writeOnlyChanWithBuff := make(chan<- int, 4) // 只写且带缓存区 channel
writeOnlyChan := make(chan<- int) // 只写且不带缓存区 channel
ch := make(chan int, 10) // 可读可写且带缓存区无缓冲的channel
无缓冲的channel也叫做同步channel,它的特点是发送和接收操作是同步的。当一个goroutine向一个无缓冲的channel发送数据时,它会被阻塞,直到另一个goroutine从该channel中接收数据为止。同样地,当一个goroutine从一个无缓冲的channel中接收数据时,它也会被阻塞,直到另一个goroutine向该channel中发送数据为止。
需要注意的是,这里所说的阻塞是指我们正确使用channel的情况下,对于无缓冲的channel来说,只有当发送方和接收方同时准备好才不会导致死锁,这也就意味着我们需要在读取channel前异步写channel:
func f1() {
ch := make(chan int)
go func() {
ch <- 1
}()
fmt.Println(<-ch)
}比如上面的代码中我们是可以正常读写一个无缓冲的channel。
如果我们在新的协成读取一个channel或者写一个channel都不会发生死锁,比如:
//只写不对
func f2() {
ch := make(chan int)
go func() {
fmt.Println("开始写入ch")
ch <- 1 //只会阻塞在当前协程中
fmt.Println("写入ch完成") //没有机会执行
}()
}
//只读不写
func f3() {
ch := make(chan int)
go func() {
fmt.Println("开始读取ch")
fmt.Println(<-ch)//永久阻塞,随主协程一起退出
fmt.Println("读取ch完成") //没有机会执行
}()
time.Sleep(time.Second * 3)
}
//读写都在不同的协程中,则先声明读channel也不会导致死锁了
func f4() {
ch := make(chan int)
go func() {
fmt.Println(<-ch)
}()
go func() {
ch <- 1
}()
time.Sleep(time.Second)
}
//如果我们先读,再异步写channel是会导致死锁的,因为读的动作就已经阻塞住了,后面写的工作没机会执行,死锁
func f5() {
ch := make(chan int)
fmt.Println(<-ch)
go func() {
ch <- 1
}()
}
//在同一个协程中读写channel,死锁
func f6() {
ch := make(chan int)
ch <- 1 //写入时会一直阻塞,等待读取
<-ch //读取时,由于上面已经阻死了,永远走不到这里
}
//在同一个协程中写channel但没有读,死锁
func f7() {
ch := make(chan int)
ch <- 1
}
//在同一个协程中只读,死锁
func f8() {
ch := make(chan int)
<-ch
}
//相互等待,死锁
func f9() {
ch := make(chan int)
ch1 := make(chan int)
go func() {
for {
select {
case <-ch:
ch1 <- 1
}
}
}()
for {
select {
case <-ch1:
ch <- 1
}
}
//在同一个协程中读写无缓冲的channel并不一定会导致死锁,如果读写channel之前存在耗时很长的协程,则会阻塞住当前协程
func f10() {
var ch chan int
go test()
fmt.Println("永久阻塞")
<-ch
}
func test() {
for {
time.Sleep(time.Second)
}
}有缓冲的channel
有缓冲的channel也叫做异步channel,它的特点是发送和接收操作是非阻塞的。当一个goroutine向一个有缓冲的channel发送数据时,如果该channel的缓冲区未满,发送操作会立即成功;否则,发送操作也会被阻塞,直到缓冲区有足够的空间。同理,当一个goroutine从一个有缓冲的channel中接收数据时,如果该channel的缓冲区非空,接收操作会立即成功;否则,接收操作会被阻塞,直到缓冲区有数据为止。
与无缓冲channel明显不同的是,有缓冲的channel由于存在一定的缓冲空间,在缓冲空间未满的情况下,在同一个gorutine中进行读写并不会阻塞而发生死锁。注意这里的前提条件是缓冲区未满的情况下。比如:
//我们创建了一个有缓冲的channel,缓冲区大小为1。然后我们向该channel中发送数据,并通过`<-ch`从该channel中接收数据,并打印出来。由于该channel是有缓冲的,因此发送和接收操作是非阻塞的,发送操作可以立即成功,并将数据放入缓冲区中,接收操作也可以立即成功,从缓冲区中取出数据并打印出来
func f11() {
ch := make(chan int, 1)
ch <- 1
fmt.Println(<-ch)
}
//缓冲区已满,发送方阻塞,没有接收方而发生死锁
func f12() {
ch := make(chan int, 1)
ch <- 1
ch <- 2
}
//只接收没有发送导致死锁
func f12_1() {
ch := make(chan int, 1)
fmt.Println(<-ch)
}
//缓冲区不为空,接收方阻塞而无法开启新的发送方而导致死锁
func f13() {
ch := make(chan int, 1)
<-ch
ch <- 1
}
//两个goroutine中有缓冲的channel相互等待而产生死锁
func f14() {
ch := make(chan int, 2)
ch1 := make(chan int, 2)
go func() {
for {
select {
case <-ch:
ch1 <- 1
}
}
}()
for {
select {
case <-ch1:
ch <- 1
}
}
}使用channel的注意事项
关闭channel后并不为nil
首先一个未初始化的channel肯定是nil的,channel的零值是nil。这里需要注意的是一个关闭的channel是不是nil呢?
通过下面的实例来理解:
var ch chan struct{}
var ch1 = make(chan struct{})
fmt.Println("ch == nil:", ch == nil) //ch == nil: true
fmt.Println("ch1 == nil:", ch1 == nil) //ch1 == nil: false
close(ch1)
fmt.Println("关闭后ch1 == nil:", ch1 == nil) //关闭后ch1 == nil: false可见,关闭后的channel并不为nil。
向nil的channel发送和读取数据会导致panic
channelmap一样,也是需要先使用make初始化后才能使用的,如果我们直接向一个nil的channel发送或者接收数据都会发生阻塞而导致死锁
func f1() {
var c chan int
go func() {
c <- 1
}()
fmt.Println(<-c)
}输出:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive (nil chan)]:在前面小节中我们使用make初始化后执行了相同的代码,使用make初始化后的代码是可以正常执行的,但这里nil的channel是会导致panic的,也就是nil的channel是无法单独在当前协程中发送和接收消息的,即使是在当前协程中接收然后新开协程发送,或者在当前协程中发送,在新的协程中接收,都会导致死锁而产生panic.
需要注意的是,在当前协程中向nil 的channel中发送或读取数据,是因为阻塞而导致的死锁,并不是由于空指针导致的异常。如果读取和发送都是新的协程中进行,则新的协程会一直阻塞直到主协程退出,可以用这个示例验证:
func f2() {
var c chan int
go func() {
fmt.Println("开始发送")
c <- 1
fmt.Println("阻塞在发送") //永远不会执行
}()
go func() {
fmt.Println("开始接收")
fmt.Println(<-c)
fmt.Println("阻塞在接收") //永远不会执行
}()
time.Sleep(time.Second)
}上面的例子中c是一个nil的channel,在新的协程中发送和接收数据,会一直阻塞在发送和接收的地方,直到随主协程退出。最终输出的结果为:
开始发送
开始接收由此我们可以得出结论:在当前协程中,向nil的channel中发送数据或者从一个nil的channel接收数据都会发生阻塞而导致死锁。
nil的channel关闭数据会导致panic
需要注意的是,nil的channel是不能执行关闭操作的,向一个nil的channel关闭数据会导致panic.
当我们尝试关闭一个nil channel时,程序会抛出一个panic异常。因为nil channel并不是一个可以被关闭的channel。可以看下面的示例代码:
var c chan int
close(c) // panic: close of nil channel向关闭channel发送数据会panic
在前面介绍过,当一个channel关闭后,它并不是一个nil channel。
那如果我们向一个已经关闭的channel中发送会发什么panic的
func f1() {
ch := make(chan int)
close(ch)
go func() {
fmt.Println("开始接收数据")
fmt.Println("<-ch:", <-ch)
fmt.Println("数据接收完成")
}()
go func() {
fmt.Println("开始发送数据")
ch <- 1
fmt.Println("发送数据完毕")
}()
time.Sleep(time.Second)
}输出:
开始发送数据
开始接收数据
<-ch: 0
panic: send on closed channel
goroutine 7 [running]:
main.f1.func2()向关闭的channel读取数据可以正常读取
其实可以从关闭的channel读取数据的,并不会发现死锁或者panic的,会读取到这个channel中数据类型的默认值ch := make(chan int),比如这里channel的数据类型为int,其默认值为0,所以我们读取出的值为0
示例:
func f2() {
ch := make(chan int)
close(ch)
for {
select {
case c := <-ch:
fmt.Println(c)
time.Sleep(time.Second)
}
}
}输出:
0
0
0
0
0
0
0
...而且从一个关闭的channel中读取数据是不会阻塞的,即使这个channel是一个无缓冲的channel:
func f3() {
ch := make(chan int)
close(ch)
<-ch //读取已经关闭的channel ,不会阻死
println("完成") //这句会输出
}
func f4() {
ch := make(chan int)
go func() {
close(ch)
println("已关闭ch") //这句会输出
}()
<-ch //这里读取时也不会组塞住
println("完成") //这句会输出
}所以在关闭一个channel之前,如果我们无法确定这个channel是不是nil,也得先判断这个channel是不是nil再进行关闭。
我们已经知道了向一个关闭的channel中发送数时会导致panic,
所以我们在向一个channel中发送数据时,需要先判断这个channel是否已经关闭了。
那么我们应该怎么判断一个channel是否已经关闭了呢?
首先我们需要了解channel关闭后的一些特性:
当我们使用range语句遍历一个channel时,当channel关闭时,range语句才会结束执行
func f5() { ch := make(chan int) go func() { for i := 0; i < 5; i++ { ch <- i time.Sleep(time.Second) } close(ch) }() for x := range ch { fmt.Println(x) } }我们通常在使用channel之前就需要对channel进行判断,所以这个特性一般不用来判断一个channel是够已经关闭
读取channel时,如果channel已经关闭,会返回一个零值和一个标识,我们可以通过这个标识来判断channel是否已经关闭,在实际使用中我们通常会结合select来读取channel
func f6() { ch := make(chan int) go func() { for i := 0; i < 10; i++ { ch <- i } close(ch) }() for { select { case data, ok := <-ch: if !ok { fmt.Println("channel closed") return } fmt.Println("data:", data) } } }输出:
data: 0 data: 1 data: 2 data: 3 data: 4 data: 5 data: 6 data: 7 data: 8 data: 9 channel closed
多次关掉 channel 会触发运行时错误
func f7() {
c := make(chan int)
defer close(c)
go func() {
c <- 1
close(c)
}()
fmt.Println(<-c)
}不要使用channel传输大的数据
channel中传输数据的大小是有限制的,Go官方编译器中channel最大能传输的尺寸为64KB。比如下面例子在官方编译器中将会导致编译错误:
func f10() {
arr := [4096]string{}
fmt.Println(unsafe.Sizeof(arr))
ch := make(chan [4096]string)
go func() {
ch <- arr
}()
time.Sleep(time.Second)
}输出了:
./main.go:141:2: channel element type too large (>64kB)主要原因是channel在传递过程中元素值是需要经过复制的,在一个值从一个协程传递到另一个协程的过程中,这个值将被至少被复制一次,如果传递的这个值在某个channel的缓存队列中停留过,则这个值在传递的过程中将被复制两次。一次复制发生在从发送协程向缓冲队列推入此值的时候,另一个复制发生在接收协程从缓冲队列取出此值的时候。 和赋值以及函数调用传参一样,当一个值被传递时,只有它的直接部分被复制。所以为了避免过大的复制成本,官方编译器对channel的元素尺寸进行了限制,我们在平时编程过程中也需要注意,不要使用channel传输过大的数据。
注意通道和协程的垃圾回收
需要注意的是,一个channel会被它的发送队列的协程和接收数据的所有协程引用着,如果一个channel的发送队列或接收队列有一个不为空这个通道肯定不会被垃圾回收。
对于协程而言,如果一个协程处于某个channel的某个协程队列之中,即使这个channel只被这个协程所引用,这个协程也不会被垃圾回收,只有当这个协程退出后才能被垃圾回收。
小结
关于对通道的操作,我们可以做如下总结:
- 关闭一个nil通道或者重复关闭一个通道将产生一个panic。
- 向一个已关闭的通道发送数据也将导致panic。
- 向一个nil channel发送数据或者从一个nil 的channel接收数据都将使当前协程永久阻塞,而且读或写中任意一个操作发生在当前协程都会导致死锁。
GMP中的底层数据结构
这里来重点介绍Go语言的协程调度器GMP模型中的G,M,P他们在Go中都是长什么样的,我们来看看GMP在Go源码中的结构定义,这有利于我们对GMP调度流程的理解。
GMP是Go语言的协程调度模型,它由三种结构体组成:G、M和P。
- G代表goroutine,也就是协程,包含了协程的状态、栈、上下文等信息。它一般所占的栈内存为2KB,运行过程中如果栈空间不够用则会自动扩容。它可以被理解成一个被打包的代码段。
- M代表machine,也就是工作线程,就是真正用来执行代码的线程。它包含了线程的状态、寄存器、信号掩码等信息,由Go的runtime管理它的生命周期。在Go语言中有两个特殊的M:一个是主线程,它专门用来处理主线逻辑;另一个是一个监控线程sysmon,它不需要P就可以执行,监控线程里面是一个死循环,不断地检测是否有阻塞或者执行时间过长的G,发现之后将抢占这些G。每个M结构有三个G,gsignal是M专门处理runtime的信号的G,可以处理一些唤醒机制,G0是在执行runtime调度代码的时候需要切换到的G,还有一个G就是当前M需要执行的用户逻辑的G。
- P代表processor,也就是逻辑处理器,包含了运行和就绪的协程队列、本地缓存、定时器等信息。P是工作线程M所需的上下文环境,也可以理解为一个M运行所需要的Token,当P有任务时需要创建或者唤醒一个M来执行它队列里的任务。所以P的数量决定了并行执行任务的数量,可以通过runtime.GOMAXPROCS来设定,现在的Go版本中默认为CPU的核心数。一个P对应一个M,P结构中带有runnext字段和一个本地队列,runnext字段中存储的就是下一个被M执行的G,每个P带有一个256大小的本地数组队列,这个队列是无锁的。
G在源码中的定义
Go版本:1.20.4
源码路径:$GOROOT\src\runtime\runtime2.go
为了文章不枯燥,这里我提取了一些常见的字段出来:
type g struct {
// 1. 执行上下文 - 最核心的部分
stack stack // 当前G的栈内存范围,执行函数调用时使用,我们常说的协程暂用2KB很多程度就是指这个协程栈
sched gobuf // 调度上下文,保存寄存器状态,用于恢复执行
m *m // 当前执行该G的M(系统线程),最后真正执行G的就是在M上
// 2. 状态控制
atomicstatus uint32 // G的当前状态(running/waiting等),协程也需要有自己的状态
goid uint64 // G的唯一标识符
// 3. 异常处理
_panic *_panic // panic链表
_defer *_defer // defer链表
// 4. 调试信息
gopc uintptr // 创建该G的go语句的程序计数器
startpc uintptr // G的入口函数地址
waitreason waitReason // G阻塞的原因
// 5. 性能分析
labels unsafe.Pointer // pprof标签
timer *timer // time.Sleep使用的定时器
}结合一个场景:
// 1. Goroutine创建和执行
func ExampleGoroutine() {
// 创建新的G
go func() {
// 此时会分配新的g结构体
// stack: 分配2KB初始栈空间
// startpc: 设置为此匿名函数的地址
// goid: 分配唯一ID
// ... 执行代码 ...
}()
}
// 2. 异常处理
func ExamplePanicRecover() {
defer func() {
if r := recover(); r != nil {
// 通过g._panic链表处理panic
// 可以获取完整的panic调用链
}
}()
panic("error") // 创建新的_panic,加入g._panic链表
}
// 3. Channel操作
func ExampleChannel() {
ch := make(chan int)
go func() {
ch <- 1
// 1. G可能进入waiting状态
// 2. waitreason会记录channel操作
// 3. 保存sched上下文以便后续恢复
}()
}- 每个 G 都有自己的状态,状态保存在
atomicstatus字段,共有16种状态值(状态枚举定义在runtime2.go文件开头)。 - 每个 G 在状态发生变化时,即
atomicstatus字段值被改变时,都需要保存当前G的上下文的信息,这个信息存储在sched字段,其数据类型为gobuf。 - 每个 G 都有三个与抢占有关的字段,分别为
preempt、preemptStop和premptShrink - 每个 G 都有自己的唯一id, 字段为
goid; - 每个 G 最多可以绑定一个
m,如果未绑定,则值为nil - 每个 G 都有自己内部的
defer和panic。 - G 可以被阻塞,并存储有阻塞原因,字段
waitsince和waitreason - G 可以被进行 GC 扫描,相关字段为
gcscandone、atomicstatus(_Gscan与上面除了_Grunning状态以外的其它状态组合)
完整个G结构体,字段都有注释,「Golang进阶之路」GMP底层结构说明
M在源码中的定义
Go版本:1.20.4
源码路径:$GOROOT\src\runtime\runtime2.go
同样,这里现给出一些常见的字段:
type m struct {
// 1. G相关的核心字段
g0 *g // 最重要:用于执行调度等系统任务的特殊G
curg *g // 最重要:当前正在运行的用户G
p puintptr // 最重要:当前绑定的P
nextp puintptr // 重要:下一个要绑定的P
oldp puintptr // 重要:系统调用前的P
// 2. 状态相关字段
spinning bool // 重要:是否在自旋找工作
blocked bool // 重要:是否被阻塞
mallocing int32 // 是否在分配内存
// 3. ID和计数
id int64 // M的唯一标识符
ncgocall uint64 // cgo调用次数
// 4. 调度相关
schedlink muintptr // 调度器链表
lockedg guintptr // 锁定的G
}场景:
G0和Curg
// 场景:处理HTTP请求 func HandleHTTP(w http.ResponseWriter, r *http.Request) { // 此时的M状态: // m.curg = 当前处理HTTP请求的G // m.g0 = 用于执行调度的系统G // 当需要进行调度时: if needSchedule { // 1. 切换到g0执行调度代码 // 2. g0使用系统栈执行调度 // 3. 选择新的G后,切换回用户栈执行 } // 当发生系统调用时: db.Query("SELECT ...") { // 1. 通过g0处理系统调用 // 2. 保存curg的状态 // 3. 系统调用完成后恢复 } }P的绑定场景
// 场景:执行数据库操作 func DBOperation() { // 正常执行Go代码时 rows, err := db.Query("SELECT * FROM users") { // 此时M状态: // m.p = 当前绑定的P // m.oldp = nil // 发起系统调用时: syscall.Read() { // 1. 保存当前P m.oldp = m.p // 2. 解绑P允许其他M使用 m.p = nil // 3. 系统调用阻塞中... // 此时其他M可以获取这个P执行其他G } // 系统调用完成后: // 1. 尝试重新获取原来的P // 2. 如果原P被占用,尝试获取其他P // 3. 没有可用P时,将G放回全局队列 } }自旋状态场景
// 场景:处理并发任务 func ProcessTasks() { // 创建多个工作goroutine for i := 0; i < 100; i++ { go worker() } // M的自旋行为: // 1. 当工作较少时 if noWork && shouldSpin { m.spinning = true // M会自旋寻找工作: // - 检查本地队列 // - 检查全局队列 // - 尝试窃取其他P的任务 } // 2. 找到工作后 if foundWork { m.spinning = false // 开始执行找到的G } }阻塞和锁定场景
// 场景:使用互斥锁 func ConcurrentOperation() { var mu sync.Mutex mu.Lock() // 此时M状态: // m.blocked = true(如果等待锁) // m.lockedg = 当前G(如果获得锁) // 临界区操作... mu.Unlock() // m.blocked = false // m.lockedg = nil }系统调用场景
// 场景:文件操作 func FileOperation() { file, _ := os.Open("large.file") // 读取文件时: buf := make([]byte, 4096) n, err := file.Read(buf) { // 1. 系统调用前: // m.p = 当前P // m.oldp = nil // 2. 进入系统调用: // m.p = nil // m.oldp = 保存的P // 3. 系统调用返回: // 尝试恢复P的绑定 } }mallocing场景
// 场景:处理大量数据 func ProcessLargeData() { // 1. 创建大切片 data := make([]int, 1000000) { // 此时M状态: // m.mallocing = 1 // 标记正在分配内存 // 内存分配过程... // 分配完成: // m.mallocing = 0 } // 2. 并发分配场景 go func() { // 如果当前M正在分配内存 if m.mallocing == 1 { // 避免重入,等待分配完成 // 或切换到其他M执行 } }() }ID和CGO调用计数场景
// 场景:调用C函数的Go程序 /* #include <stdio.h> void printMessage(char* msg) { printf("%s\n", msg); } */ import "C" func CGOExample() { // 1. 跟踪M的身份 // m.id 用于标识不同的M // 常用于调试和跟踪问题 // 2. 调用C函数 message := C.CString("Hello from Go") { // 每次CGO调用都会增加计数 // m.ncgocall++ // 用于监控CGO调用频率 // 帮助识别CGO调用过多的性能问题 } C.printMessage(message) } // 调试工具示例 func DebugInfo() { // 打印M的信息 fmt.Printf("M(id=%d) has made %d cgo calls\n", m.id, m.ncgocall) }调度相关字段场景
// 场景:复杂的调度情况 func SchedulingExample() { // 1. schedlink的使用 // 当M需要被链接到调度器时 if m.spinning { // M会被加入到调度器链表 // m.schedlink指向链表中的下一个M // 用于管理空闲或等待调度的M } // 2. lockedg的使用场景 runtime.LockOSThread() { // 将当前G锁定到特定M // m.lockedg = 当前G的指针 // 适用场景: // - GUI操作必须在同一线程 // - 某些系统调用要求线程一致 } defer runtime.UnlockOSThread() { // 解除锁定 // m.lockedg = nil } }
- 每个 m 都持有一个特殊的goroutine,我们称之为g0,它具有调度栈的能力。调度和执行系统调用时会先切换到这个g
- m 可以与一个G相绑定,字段
curg - m 可以与P绑定,也可以不绑定,如果已绑定则字段p不为
nil - m 可以记录下次和上次绑定的p,字段
nextp和oldp - 如果m 没有工作可做的话,它会通过自旋积极再找一个活干
- blocked记录m会不会在
note阻塞 - preemptGen可以记录对m完成信号抢占的次数
- 一个m最多可以持有10个锁
M的完整字段:「Golang进阶之路」GMP底层结构说明
P在源码中的定义
Go版本:1.20.4
源码路径:$GOROOT\src\runtime\runtime2.go
可以重点理解这些字段:
type p struct {
// 1. 基础标识字段
id int32 // P的ID
status uint32 // P的状态
link puintptr // 用于链接P结构体
m muintptr // 关联的M
// 2. 本地任务队列管理
runqhead uint32 // 队列头
runqtail uint32 // 队列尾
runq [256]guintptr // 本地队列,固定256大小
runnext guintptr // 下一个优先执行的G
// 3. 调度统计
schedtick uint32 // 调度次数
syscalltick uint32 // 系统调用次数
// 4. 内存管理
mcache *mcache // 内存分配缓存
// 5. GC相关
gcBgMarkWorker guintptr // GC标记worker
gcw gcWork // GC工作缓存
gcMarkWorkerMode gcMarkWorkerMode // GC标记模式
// 6. 定时器管理
timers []*timer // 定时器切片
numTimers atomic.Uint32 // 定时器数量
}场景:
基础状态管理示例
// P的生命周期示例 func PLifecycleExample() { // 1. P的创建和初始化 p := &p{ id: pid, status: _Pidle, // 初始为空闲状态 mcache: allocMCache(), // 分配内存缓存 } // 2. P被M获取 func acquireP() { // P变为运行状态 p.status = _Prunning // 关联到M p.m = getg().m } // 3. 系统调用时P的状态变化 func syscall() { // P进入系统调用状态 p.status = _Psyscall // 解除与M的关联 p.m = 0 } }本地队列管理示例
// 任务调度示例 func TaskSchedulingExample() { // 1. 添加任务到本地队列 func runqput(p *p, gp *g, next bool) { if next { // 设置为下一个要执行的G oldnext := p.runnext p.runnext = guintptr(unsafe.Pointer(gp)) if oldnext != 0 { // 将之前的next放入队列 runqput(p, oldnext, false) } return } // 添加到本地队列 if p.runqtail - p.runqhead < uint32(len(p.runq)) { p.runq[p.runqtail%uint32(len(p.runq))] = guintptr(unsafe.Pointer(gp)) p.runqtail++ return } // 本地队列满,放入全局队列 globrunqput(gp) } // 2. 获取要执行的任务 func findRunnable() *g { // 优先检查runnext if gp := p.runnext; gp != 0 { return gp } // 从本地队列获取 if gp := runqget(p); gp != nil { return gp } // 尝试从全局队列获取 if gp := globrunqget(); gp != nil { return gp } } }实际应用场景
// Web服务器场景 func WebServerExample() { http.HandleFunc("/api", func(w http.ResponseWriter, r *http.Request) { // 1. 请求处理作为新的goroutine go func() { // P的状态变化: // - schedtick增加(新的调度) // - 可能进入本地队列或作为runnext // 2. 数据库操作 rows, err := db.Query("SELECT * FROM users") { // P的状态变化: // - syscalltick增加 // - 状态变为_Psyscall // - 可能与当前M解绑 } // 3. 使用定时器 timer := time.NewTimer(5 * time.Second) { // 定时器被添加到P的timers切片 // p.numTimers增加 } }() }) } // 并发处理场景 func ConcurrentProcessingExample() { // 1. 工作池模式 pool := make(chan struct{}, 100) for i := 0; i < 1000; i++ { pool <- struct{}{} // 控制并发数 go func(id int) { defer func() { <-pool }() // P的调度行为: // 1. 任务进入本地队列 // p.runq[p.runqtail] = newG // p.runqtail++ // 2. 处理任务时可能发生状态转换 processTask(id) { // - 可能触发GC(gcMarkWorkerMode变化) // - 可能进行内存分配(使用mcache) // - 可能创建定时器(更新timers) } }(i) } }内存和GC示例
// 内存分配和GC场景 func MemoryAndGCExample() { // 1. 内存分配 func allocObject() { // 使用P的mcache分配内存 if obj := p.mcache.alloc(size); obj != nil { return obj } // mcache不足时补充 p.mcache.refill(size) } // 2. GC工作 func gcWork() { // P参与GC标记 if p.gcMarkWorkerMode == gcMarkWorkerDedicated { // 专注于GC工作 gcDrain(&p.gcw) } else { // 普通模式下的GC工作 gcDrainUntilPreempt(&p.gcw) } } }
- 每个P都有自己的状态,分别为
_Pidle、_Prunning、_Psyscall、_Pgcstop、_Pdead - 每个P都存储有自己被
调度次数和系统调用的次数,字段schedtick和syscalltick - P 可以绑定一个M。但也可以不绑定,这时m值为
nil,字段m - 每个P 都有一个自己的
runq,用来存放可以runnable状态的 goroutines, 最多可以存放256个 goroutine。一般在介绍GMP关系时,我们称之为 local queue 或 LRQ,当然还有一个global queue, 有时候也简写成 GRQ - 每个P都可能有一个
runnext的 goroutine。如果此字段不为nil,则P下次执行G的时候,优先执行此字段的goroutine - P可以缓存goroutine,字段
goidcache - gcw,gcMarkWorkerMode,gcMarkWorkerStartTime用于P的GC缓冲,GC工作模式和GC标记工作器开始的时间;
- P可以有多个timer, 以slice 形式存储, 字段
timers - P可以缓存堆上面的
mspan对象 - P 有一个抢占标记,字段为
preempt。如果为ture ,则表示P立即进入调度 - P结构体移除了pad
P的结构体的完整字段:「Golang进阶之路」GMP底层结构说明
Defer的底层原理
defer是go语言中的一个关键字,同时它也是go语言的重要特性,类似Java中的finally可以用来指定在函数返回前执行的代码。
使用defer关键字的代码段可以延迟到函数执行完毕后,在函数返回前执行。
它主要用于资源的释放和异常的捕获。比如打开文件或发起请求后关闭资源,加锁后在函数返回前的解锁操作,关闭数据库链接,捕获异常等。
defer的底层数据结构
源码位置:$GOPATH/src/runtime/runtime2.go
type _defer struct {
// 参数和返回值的内存大小
siz int32
//表示该_defer语句是否已经开始执行
started bool
//表示该_defer语句的优先级
//当一个_defer语句被执行时,它会被添加到_defer链表中,而heap字段则用于将_defer语句添加到一个优先队 列中,以便在函数返回时按照一定的顺序执行_defer语句。在_defer链表中,后添加的_defer语句会先被执行,而在优先队列中,heap值较小的_defer语句会先被执行。这个字段的值是在_defer语句被添加到_defer链表时根据一定规则计算出来的,通常是根据_defer语句的执行顺序和作用域等因素计算而得。在函数返回时,Go语言会按照heap值的大小顺序执行_defer语句。如果多个_defer语句的heap值相同,则它们会按照它们在_defer链表中的顺序依次执行。这个机制可以确保_defer语句按照一定的顺序执行,从而避免了一些潜在的问题。
heap bool
// 表示该_defer用于具有开放式编码_defer的帧。开放式编码_defer是指在编译时已经确定_defer语句的数量和位置,而不是在运行时动态添加_defer语句。在一个帧中,可能会有多个_defer语句,但只会有一个_defer结构体记录了所有_defer语句的信息,而openDefer就是用来标识该_defer结构体是否是针对开放式编码_defer的
openDefer bool
//_defer语句所在栈帧的栈指针(stack pointer)
//在函数调用时,每个函数都会创建一个新的栈帧,用于保存函数的局部变量、参数和返回值等信息。而_defer语句也被保存在这个栈帧中,因此需要记录栈指针以便在函数返回时找到_defer语句。当一个_defer语句被执行时,它会被添加到_defer链表中,并记录当前栈帧的栈指针。在函数返回时,Go语言会遍历_defer链表,并执行其中的_defer语句。而在执行_defer语句时,需要使用保存在_defer结构体中的栈指针来访问_defer语句所在栈帧中的局部变量和参数等信息。需要注意的是,由于_defer语句是在函数返回之前执行的,因此在执行_defer语句时,函数的栈帧可能已经被销毁了。因此,_sp字段的值不能直接使用,需要通过一些额外的处理来确保_defer语句能够正确地访问栈帧中的信息。
sp uintptr
//_defer语句的程序计数器(program counter)
//程序计数器是一个指针,指向正在执行的函数中的下一条指令。在_defer语句被执行时,它会被添加到_defer链表中,并记录当前函数的程序计数器。当函数返回时,Go语言会遍历_defer链表,并执行其中的_defer语句。而在执行_defer语句时,需要让程序计数器指向_defer语句中的函数调用,以便正确地执行_defer语句中的代码。这就是为什么_defer语句需要记录程序计数器的原因。需要注意的是,由于_defer语句是在函数返回之前执行的,因此在执行_defer语句时,程序计数器可能已经指向了其它的函数或代码块。因此,在执行_defer语句时,需要使用保存在_defer结构体中的程序计数器来确保_defer语句中的代码能够正确地执行。
pc uintptr // pc 计数器值,程序计数器
// defer 传入的函数地址,也就是延后执行的函数
fn *funcval
//efer 的 panic 结构体
_panic *_panic
//用于将多个defer链接起来,形成一个defer栈
//当程序执行到一个 defer 语句时,会将该 defer 语句封装成一个 _defer 结构体,并将其插入到 defer 栈的顶部。当函数返回时,程序会从 defer 栈的顶部开始依次执行每个 defer 语句,直到 defer 栈为空为止。每个 _defer 结构体中的 link 字段指向下一个 _defer 结构体,从而将多个 _defer 结构体链接在一起。当程序执行完一个 defer 语句后,会将该 defer 从 defer 栈中弹出,并将其 link 字段指向的下一个 _defer 结构体设置为当前的 defer 栈顶。这样,当函数返回时,程序会依次执行每个 defer 语句,从而实现 defer 语句的反转执行顺序的效果。需要注意的是,由于 _defer 结构体是在运行时动态创建的,因此 defer 栈的大小是不固定的。在编写程序时,应该避免在单个函数中使用大量的 defer 语句,以免导致 defer 栈溢出。
link *_defer
}这里我们可以重点理解:size、started、sp、fn、_panic、link
defer本质上是一个用链表实现的栈的结构,我们可以看到,在defer的底层结构中有一个link的指针,这个指针会指向链表的头部,也就是我们每次声明defer的时候,就会将这个defer的数据插入到链表的头部的位置。在获取defer执行的时候是从链表的头部开始获取defer的,所以这就是为什么最后声明的defer最先执行的原因。
在 Golang 的源码中,defer 语句的实现主要涉及到以下几个部分:
- runtime.deferproc 函数:该函数用于将一个函数和其参数封装成一个 _defer 结构体,并将其插入到当前协程的 defer 栈中。
- runtime.deferreturn 函数:该函数用于在函数返回时执行 defer 栈中的 _defer 结构体。
- runtime.deferredFunc 函数:该函数用于执行一个 _defer 结构体中封装的函数,并在执行过程中捕获 panic
下面是runtime.deferproc的核心源码:
func deferproc(siz int32, fn *funcval) { // arguments of fn follow fn
gp := getg() //获取goroutine结构
if gp.m.curg != gp {
// go code on the system stack can't defer
throw("defer on system stack")
}
...
d := newdefer(siz) //新建一个defer结构
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
d.link = gp._defer // 新建defer的link指针指向g的defer
gp._defer = d // 新建defer放到g的defer位置,完成插入链表表头操作
d.fn = fn
d.pc = callerpc
d.sp = sp
...
}defer说明
Golang 的 defer 语句底层实现是通过一个栈来实现的。每个函数都有一个 defer 栈,当遇到 defer 语句时,会将要执行的语句压入该栈中。当函数返回时,会从 defer 栈中依次取出语句执行,直到栈为空为止。因为 defer 栈是与函数绑定的,所以不同的函数之间的 defer 栈是独立的,互不干扰。
在 Golang 中,defer 语句的实现是通过两个函数来完成的:runtime.deferproc 和 runtime.deferreturn。当遇到 defer 语句时,会调用 runtime.deferproc 函数将要执行的语句压入 defer 栈中。当函数返回时,会调用 runtime.deferreturn 函数从 defer 栈中取出语句执行。这两个函数都是 Golang 运行时库中的函数,不能直接调用。
每个 defer 语句都对应一个_defer 实例,多个实例使用指针连接起来形成一个单链表,保存在 gotoutine 数据结构中,每次插入_defer 实例,均插入到链表的头部,函数结束再一次从头部取出,从而形成后进先出的效果。
defer在很大程度上简化我们的代码,我们可以使用defer来做一些收尾工作,在日常开发中申请资源后立即使用 defer 关闭资源是个非常好的编码习惯
defer的执行顺序和使用场景
执行顺序
在Golang中,defer语句用于在函数结束时执行某个操作。这个操作可能是释放资源、关闭文件、记录日志、恢复异常等。
defer语句的执行顺序是先进后出(LIFO),即最后一个defer语句最先执行。当函数执行完毕时,所有defer语句都会被执行。
在前面的我们了解到defer是一个用链表实现的栈的结构,最后声明的defer会被插入到链表的头部,执行的时候会从链表的头部开始取出,所以最后声明的defer会最先被执行。
示例:
package main
import "fmt"
func main() {
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
}输出:
3
2
1使用场景
关闭文件或网络连接
func readFile(filename string) (string, error) { f, err := os.Open(filename) if err != nil { return "", err } defer f.Close() // 使用 defer 语句关闭文件 content, err := ioutil.ReadAll(f) if err != nil { return "", err } return string(content), nil }关闭http响应
package main import ( "log" "net/http" ) func main() { url := "http://www.baidu.com" resp, err := http.Get(url) if err != nil { log.Fatal(err) } defer resp.Body.Close() // 关闭响应体 // 处理响应数据 }关闭数据库链接
func queryDatabase() error { db, err := sql.Open("mysql", "user:password@tcp(localhost:3306)/database") if err != nil { return err } defer db.Close() // 在函数返回前关闭数据库连接 // 查询数据库 return nil }释放锁
var mu sync.Mutex var balance int func lockRelease(amount int) { mu.Lock() defer mu.Unlock() // 在函数返回前解锁 balance += amount }捕捉异常
func f() { defer func() { if err := recover(); err != nil { fmt.Println(string(debug.Stack())) } }() panic("unknown") }取消任务
func runTask() error { ctx, cancel := context.WithCancel(context.Background()) defer cancel() // 在函数返回前取消任务 go doTask(ctx) // 等待任务完成 return nil }记录程序耗时
func trackTime() { start := time.Now() defer func() { log.Printf("Time took: %v", time.Since(start).Milliseconds()) }() // 执行一些操作 time.Sleep(time.Second * 3) }
场景题:打开10万个文件,如何使用defer关闭资源?
在golang中,可以使用defer语句来确保在函数结束时关闭文件资源。如果需要打开的文件非常多,我们在使用defer关闭资源时需要注意什么呢?
一般来说文件操作都是比较耗时的操作,而操作系统对同时打开的文件句柄数量是有限制的,在大多数linux操作系统上为1024,我们可以通过ulimit -n指令查看,所以在操作大量文件时,我们需要考虑文件句柄的消耗。
先来看一个错误示例:
func processFiles() error {
for i := 0; i < 100000; i++ {
file, err := os.Open("file" + strconv.Itoa(i) + ".txt")
if err != nil {
return err
}
defer file.Close()
// 处理文件内容
// ...
}
return nil
}这里使用到了defer但是,打开了10个文件资源,最后需要等processFiles执行完成后统一由defer释放资源,这么搞直接给系统搞崩溃吧
看一下这个示例:
func processFiles2() error {
var wg sync.WaitGroup
for i := 0; i < 100000; i++ {
wg.Add(1)
go func(index int) {
defer wg.Done()
processFile("file" + strconv.Itoa(i) + ".txt")
}(i)
}
wg.Wait()
return nil
}
func processFile(filePath string) error {
file, err := os.Open(filePath)
if err != nil {
return err
}
defer file.Close()
// 处理文件内容
// ...
return nil
}这样是不是好了很多?
但上面的程序并不是完全安全的,如果文件处理速度很慢,会存在协程堆积的情况,这样不仅会消耗大量的资源句柄,大量的文件同时载入内存,也可能导致系统内存占用过高,同样存在风险。所以这里我们需要使用协程池来控制同时存活的协程数量,这里我们最好搞一个协程池。
defer容易踩坑的地方
defer表达式与return表达式的执行先后顺序
先来看一道笔试题:
func main(){
fmt.Println(f(2))
}
func f(x int) (r int) {
defer func() {
r += x // 修改返回值
}()
return x + x // <=> r = x + x; return
}在执行return 语句时,会先将return表达式的值计算出来并保存在返回值寄存器中,然后执行 defer 语句,最后将返回值寄存器中的值返回给调用方。所以这里会先计算出x+x的值赋值给r,注意,这里return x + x是简写了赋值语句,这里等价于r = x + x, 此时r的值为4。接着再执行defer中r += x表达式,执行完成后r的值在4的基础上再次加上了x(也就是2),所以最终执行结果为6。
defer语句的估值时刻
接着我们再来分析defer语句的估值时刻,我们先看看下面3个实例:
defer中变量的估值时刻
func f1() { x := 0 defer fmt.Println(x) //理解defer可以先思考一下defer的实现原理和对应的这三个方法: //1. runtime.deferproc 函数:该函数用于将一个函数和其参数封装成一个 _defer 结构体,并将其插入到当前协程的 defer 栈中。 //2. runtime.deferreturn 函数:该函数用于在函数返回时执行 defer 栈中的 _defer 结构体。 //3. runtime.deferredFunc 函数:该函数用于执行一个 _defer 结构体中封装的函数,并在执行过程中捕获 panic。 x = 1 fmt.Println("done") //输出: //done //0defer中实参的估值时刻
func f2() { x := 0 defer func(paramx int) { fmt.Println(paramx) }(x) x = 1 fmt.Println("done") } //输出: //done //0defer中闭包的估值时刻
func f3() { x := 0 defer func() { fmt.Println(x) }() x = 1 fmt.Println("done") } //输出: //done //1
大家可以先自己分析下上面3个示例的输出结果。
首先defer是在函数结束时执行的,所以上面3个实例中输出的字符串”done”肯定是最先输出的,然后再输出defer中变量x的值。
首先,对于 defer 语句后面的表达式,它也是在 defer 语句执行前进行估值的。在执行 defer 语句时,先计算表达式的值,然后将其保存在一个新的栈帧中,并将该栈帧推入 defer 栈中。当函数执行完毕时,defer 栈中的所有栈帧会按照后进先出的顺序被执行,每个栈帧中保存的表达式也会被依次执行。
所以前两个示例中,defer后面的语句在推入 defer 栈的时候,读取到的变量x的值是当前时刻x的值,也就是0.但在第三个示例中,推入defer栈中的是一个闭包函数,而这个闭包函数是在defer执行的时候从defer栈中取出后再执行这个闭包函数的,这个时候闭包函数中的变量x会读取到被赋值为1之后的x值。所以在defer代码块被推入到defer栈中的时候,对于闭包函数内的变量估值是有区别的,这里是我们需要特别留意的地方。
接下来我们修改一下我们defer的第一个例子:
func main() {
fmt.Println(f(2))
}
func f(x int) (r int) {
defer func(param int) {
r += param // 修改返回值
}(x) // 修改返回值
return x + x // <=> r = x + x; return
}
//返回:6这里的defer中,我们通过参数将x传到defer函数中,此时推入defer的param值为2,然后还是先执行return表达式中的x + x 赋值给r,然后将返回值的结果放入到寄存器中,此时r的值依然为4,这时候执行defer函数时拿到的r的值就变成了4,再加上2输出还是6。
如果我们在defer中传的是r的值,则运行结果又会是什么呢?
func main() {
fmt.Println(f(2))
}
func f(x int) (r int) {
defer func(param int) {
r = param + x // 修改返回值
}(r) // 修改返回值
return x + x // <=> r = x + x; return
}
//返回:2首先还是先将defer函数推入到defer栈,这时候实参传入函数的param值为0,x为2,然后执行return表达式,将x + x 赋值给r,此时返回值寄存器中r的值为4,接着取出defer函数执行,将param + x,也就是2赋值给r,此时返回值被重新赋值为2,所以上面的程序最终输出结果为2。
对于defer中匿名函数的估值时机,我们通过下面的例子加深理解:
func f4() {
func() {
for x := 0; x < 3; x++ {
defer fmt.Println("x:", x)
}
}()
//输出:
//2
//1
//0
func() {
for y := 0; y < 3; y++ {
defer func() {
fmt.Println("y:", y)
}()
}
}()
//输出:
//3
//3
//3
}在上面的两个for循环中,第一个for循环中,defer语句后面的是一个输出语句,而第二个for循环中,defer声明的是一个闭包函数。首先在第一个for循环中,输出语句中的变量x在for循环执行的过程中,也就是输出语句被推到defer栈的时候被估值,也就是这里的x值在被推入defer栈的时候就已经被估值了,执行的时候从栈的头部开始取出执行,所以第一个for循环中最终输出的是2,1,0。
而在第二个for循环中,闭包函数在被推入defer栈的时候,闭包的变量并没有立马别估值,它是在从defer栈中取出执行时才开始估值的,而defer的执行时在这个for循环结束后,所以在第二个for循环中defer闭包中y的值就是这个for循环结束后y的值。
注意for循环的执行机制,在第一for循环执行时,y=0,执行结束后将y自增,此时y=1,第二次for循环执行时,y=1,循环执行结束再将y自增,此时y=2,第三次for循环时y=2,而循环结束后y被自增,最终跳出for循环后y的值为3.所以第二for循环最终输出的是3个3。
为了进一步理解defer和return表达式的估值时机,我们看一个更复杂的例子:
func main() {
f5()
}
func f5() int {
defer func(x int) {
fmt.Println("defer:", x)
}(f6())
fmt.Println("f5")
return f7()
}
func f6() int {
fmt.Println("f6")
return 1
}
func f7() int {
fmt.Println("f7")
return 2
}
//输出:
//f6
//f5
//f7
//defer:1在上面的实例中,我们调用的是f5函数,在f5函数中首先会将defer后面的代码段推入到defer栈,在推入到defer栈时会先解析defer声明的这个函数的实参,这里实参传入的是f6(),所以最先执行的是f6函数,最先打印出的是f6,这里defer入栈前就会将f6的执行结果1随着这个函数一起被推到了defer栈中。接着会直接执行fn字符串的打印,输出f5.
然后就开始执行return表达式,将表达式的结果放到返回值寄存器中,所以此时f7被执行,返回值寄存器中存储的值为2,最后再从defer栈中取出defer函数执行,此时f5中的defer函数才会被执行,打印的是defer: 1。
我们来看另一道笔试题,写出下面程序的输出结果:
package main
import "fmt"
type number int
func (n number) print() { fmt.Println(n) }
func (n *number) pprint() { fmt.Println(*n) }
func main() {
var n number
defer n.print()
defer n.pprint() //n地址的值变为了123
defer func() { n.print() }() //闭包
defer func() { n.pprint() }() //闭包
n = 123
}
//输出:
//123
//123
//123
//0分析下上面程序的输出结果。
如果没有扎实的基本功,很多三五年经验的go开发者都可能会栽跟头。
首先上面的4个defer的执行顺序依然是从最后一个defer开始向前执行,我们先看后面两个defer语句,在这两个defer语句中都是一个闭包函数,我们上面讲过,defer中的闭包函数是在defer执行时从defer栈中取出执行的,这时候读取到的n的值是赋值后的n的值,这里不管是传n的地址还是n的值,最终的输出结果依然是123.
我们再来看看前两个defer语句,其中第二个defer语句调用的是n的指针方法,也就是第二个defer在被推入defer栈时,这个方法传入的是n的地址,最终从defer栈中取出执行时,由于n的地址所指向的值已经发生改变了,所以第二个defer最终的输出结果也是123。而第一个defer在被推入defer栈的时候,它传递的是n的值,由于在第一个defer声明时,n的值为0,所以第一个defer最终输出结果为0。
defer使用总结经验
避免直接在for循环中使用defer,例如:
func leak() { for i := 0; i < 100000; i++ { defer fmt.Println(i) // 延迟函数在循环结束后才执行 } }优化:
func noLeak() { for i := 0; i < 100000; i++ { func() { //do something defer fmt.Println(i) // 延迟函数在每次循环结束后执行 }() } }避免在defer函数中引用了大对象或者闭包变量,容易导致该对象或变量不能及时被垃圾回收器回收。
func leak() { data := make([]byte, 1024*1024) // 大对象 defer func() { fmt.Println(data) // 延迟函数引用了大对象 }() }优化:避免这种内存泄漏的方法是在defer函数执行后显式地将对象或变量置为nil
func noLeak() { data := make([]byte, 1024*1024) // 大对象 defer func() { fmt.Println(data) // 延迟函数引用了大对象 data = nil // 显式地将对象置为nil }() }
context 底层原理
context是什么
context顾名思义,就是上下文,这里特指协程的上下文。
它是 Go 语言在 1.7 版本中引入标准库的接口,用于在 goroutine 之间传递上下文信息和控制信号,包括跟踪、取消信号和超时等信息。这些信息可以被多个 Goroutine 共享和使用,从而实现协作式的并发处理。
随着 context 包的引入,标准库中很多接口因此加上了 context 参数,例如 database/sql包。context 几乎成为了并发控制和超时控制的标准做法。
context的结构
type Context interface {
// 当 context 被取消或者到了 deadline,返回一个被关闭的 channel
//它是一个只读的Channel,也就是说在整个生命周期都不会有写入操作,只有当这个channel被关闭时,才会读取到这个channel对应类型的零值,否则是无法读取到任何值的。正式因为这个机制,当子协程从这个channel中读取到零值后可以做一些收尾工作,让子协程尽快退出。
Done() <-chan struct{}
// 在 channel Done 关闭后,返回 context 取消原因,这里只有两种原因,取消或者超时。
Err() error
// 返回 context 是否会被取消以及自动取消时间(即 deadline)
//通过这个时间我们可以判断是否有必要进行接下来的操作,如果剩余时间太短则可以选择不继续执行一些任务,可以节省系统资源。
Deadline() (deadline time.Time, ok bool)
// 获取 key 对应的 value
Value(key interface{}) interface{}
}context的使用场景
在实际开发中,我们经常会遇到需要在多个 Goroutine 之间传递请求作用域的上下文的情况,主要包含下面这3种情况:
信息传递
跨越多个 Goroutine 处理一个请求时,需要将请求上下文传递到每个Goroutine 中,比如我们可以将请求的 ID ,用户身份等信息传递给处理这个请求的多个Goroutine中
package main
import (
"context"
"fmt"
"sync"
)
// 自定义类型作为 context 的 key
type contextKey string
const (
requestIDKey contextKey = "request_id"
userTokenKey contextKey = "user_token"
)
func main() {
// 创建携带元数据的上下文
ctx := context.WithValue(context.Background(), requestIDKey, "REQ-123")
ctx = context.WithValue(ctx, userTokenKey, "Bearer XYZ789")
var wg sync.WaitGroup
wg.Add(2)
// 启动多个处理协程
go processOrder(ctx, &wg)
go logRequest(ctx, &wg)
wg.Wait()
}
func processOrder(ctx context.Context, wg *sync.WaitGroup) {
defer wg.Done()
// 从上下文中提取值
if reqID, ok := ctx.Value(requestIDKey).(string); ok {
fmt.Printf("Processing order for request: %s\n", reqID)
}
}取消任务
当某个 Goroutine 需要取消请求时,需要通知其他 Goroutine 停止处理。
比如当上层任务取消或超时时,可以通知下层任务及时退出,避免资源浪费或泄露。
package main
import (
"context"
"fmt"
"sync"
"time"
)
func main() {
ctx, cancel := context.WithCancel(context.Background())
var wg sync.WaitGroup
// 启动 3 个工作协程
for i := 1; i <= 3; i++ {
wg.Add(1)
go worker(ctx, i, &wg)
}
// 2 秒后取消所有任务
time.AfterFunc(2*time.Second, func() {
fmt.Println("\nMain: Sending cancel signal")
cancel()
})
wg.Wait()
fmt.Println("All workers exited")
}
func worker(ctx context.Context, id int, wg *sync.WaitGroup) {
defer wg.Done()
for {
select {
case <-ctx.Done():
fmt.Printf("Worker%d: Received cancel\n", id)
return
default:
fmt.Printf("Worker%d: Processing...\n", id)
time.Sleep(500 * time.Millisecond)
}
}
}超时控制
当某个 Goroutine 超时时,需要通知其他 Goroutine 停止处理。
比如可以为每个任务设定一个截止时间,一旦达到截止时间之后,任务会被自动取消。
package main
import (
"context"
"fmt"
"sync"
"time"
)
func main() {
// 设置 800 毫秒超时
ctx, cancel := context.WithTimeout(context.Background(), 800*time.Millisecond)
defer cancel()
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
if err := databaseQuery(ctx); err != nil {
fmt.Println("Error:", err)
}
}()
wg.Wait()
}
func databaseQuery(ctx context.Context) error {
// 模拟耗时操作
defer fmt.Println("Database connection closed")
// 使用 channel 模拟数据库响应
result := make(chan bool)
go func() {
time.Sleep(1 * time.Second) // 实际需要 1 秒完成
result <- true
}()
select {
case <-ctx.Done():
return fmt.Errorf("query canceled: %w", ctx.Err())
case <-result:
fmt.Println("Query succeeded")
return nil
}
}context的一些最佳实践
在函数签名中传递
context参数,而不是作为结构体字段或者全局变量。type MyStruct struct { // 不要在这里存储context } func (m *MyStruct) myMethod(ctx context.Context, arg1 string, arg2 int) error { // 使用ctx传递请求上下文 }将 context 作为第一个参数传递
将context 作为第一个参数传递可以让代码更加清晰和易于理解,同时也可以避免误用 context。
不要在内层函数创建context
不要在被调用的函数内部创建 context,因为这样会导致 context 的使用范围不明确,容易导致 context 的误用和泄漏。应该在函数调用的上层函数中创建 context。
比如存在以下调用关系:
f1()调用了f2(),f2()调用了f3()f1()->f2()->f3()
我们应该在f1()中创建context,让整个调用链都传递context。

及时取消 context
在不需要继续处理请求时,应该及时取消 context。这样可以避免资源的浪费,同时也可以避免因为无法及时释放资源而导致的内存泄漏
package main import ( "context" "time" ) func main() { parentCtx := context.Background() ctx, cancel := context.WithTimeout(parentCtx, time.Second*5) defer cancel() // 在函数中检查ctx.Done()来判断是否需要取消 if err := longRunningFunction(ctx, "param1", 123); err != nil { // 如果发生错误,调用cancel()来取消请求 cancel() } } func longRunningFunction(ctx context.Context, arg1 string, arg2 int) error { select { case <-time.After(time.Second * 5): // 执行操作 case <-ctx.Done(): // 返回错误,取消请求 return ctx.Err() } return nil }
不要在 context 中存储大量数据
context 主要用于传递请求范围内的数据,但不应该用于存储大量的数据。context 应该只存储必要的数据,比如请求 ID、用户 ID 或者其他必要的元数据。
此外,context 中存储的数据可能会被传递到其他地方,或者直接作为日志输出,因此不建议在 context 中存储敏感数据,例如密码、密钥等。
不要滥用 context
context 应该只在当前请求范围内使用,不应该在全局范围内使用。如果你需要在多个请求之间共享数据,应该考虑使用其他机制,例如全局变量或者数据库。
waitgroup的实现原理
waitgroup的用法
WaitGroup是Go语言中用于等待一组goroutine完成的工具。它的实现原理涉及到原子操作和条件变量
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
//增加异步任务
wg.Add(1)
go func() {
task(i, wg)
}()
}
//等待全部goroutine完成
wg.Wait()
}
func task(i int, wg sync.WaitGroup) {
fmt.Println(i)
//标记异步任务完成
wg.Done()
}上面的代码有两个比较明显的问题:
- WaitGroup通过函数进行传参时需要传指针类型,因为它里面的计数器是需要在函数中进行修改的;
- for循环中使用Goroutine没有对循环变量i进行重新赋值,导致最终获取的是最后一轮循环结束后i自增后的值
优化一下:
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 10; i++ {
x := i
//增加异步任务
wg.Add(1)
go func() {
task(x, &wg)
}()
}
//等待全部goroutine完成
wg.Wait()
}
func task(i int, wg *sync.WaitGroup) {
fmt.Println(i)
//标记异步任务完成
wg.Done()
}WaitGroup的用法比较简单,当我们启动一个异步任务时,我们通过调用Add方法增加任务数量,当任务完成后调用Done()方法标记任务结束。然后在主Goroutine中通过Wait()方法等待全部Goroutine完成后再继续执行后续的代码。
waitgroup的实现原理
waitgroup本质上是维护了一个计数器,它提供了三个方法来操作计数器:Add()、Done()和Wait()。
Add(delta int):增加计数器的值,可以为正数或负数。正数表示增加等待的goroutine数量,负数表示减少等待的goroutine数量。该方法使用原子操作来保证计数器的安全更新。Done():相当于Add(-1),表示一个goroutine已经完成,将计数器减一。Wait():阻塞等待,直到计数器的值为0。当计数器为0时,所有等待的goroutine都已完成,Wait()方法会返回。
当调用Wait()方法时,如果计数器的值不为0,则当前goroutine会进入等待状态,同时会将当前goroutine加入到等待队列中。在调用Done()方法时,如果计数器的值变为0,则会唤醒所有等待的goroutine,使它们继续执行。
WaitGroup的源码实现不到100行,我们可以看看它的源码:
源码路径:$GOROOT\src\sync\waitgroup.go
type WaitGroup struct {
noCopy noCopy
state atomic.Uint64 // high 32 bits are counter, low 32 bits are waiter count.
sema uint32
}
func (wg *WaitGroup) Add(delta int) {
if race.Enabled {
if delta < 0 {
// Synchronize decrements with Wait.
race.ReleaseMerge(unsafe.Pointer(wg))
}
race.Disable()
defer race.Enable()
}
state := wg.state.Add(uint64(delta) << 32)
v := int32(state >> 32)
w := uint32(state)
if race.Enabled && delta > 0 && v == int32(delta) {
// The first increment must be synchronized with Wait.
// Need to model this as a read, because there can be
// several concurrent wg.counter transitions from 0.
race.Read(unsafe.Pointer(&wg.sema))
}
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
if v > 0 || w == 0 {
return
}
// This goroutine has set counter to 0 when waiters > 0.
// Now there can't be concurrent mutations of state:
// - Adds must not happen concurrently with Wait,
// - Wait does not increment waiters if it sees counter == 0.
// Still do a cheap sanity check to detect WaitGroup misuse.
if wg.state.Load() != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// Reset waiters count to 0.
wg.state.Store(0)
for ; w != 0; w-- {
runtime_Semrelease(&wg.sema, false, 0)
}
}
// Done decrements the WaitGroup counter by one.
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
func (wg *WaitGroup) Wait() {
if race.Enabled {
race.Disable()
}
for {
state := wg.state.Load()
v := int32(state >> 32)
w := uint32(state)
if v == 0 {
// Counter is 0, no need to wait.
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
// Increment waiters count.
if wg.state.CompareAndSwap(state, state+1) {
if race.Enabled && w == 0 {
// Wait must be synchronized with the first Add.
// Need to model this is as a write to race with the read in Add.
// As a consequence, can do the write only for the first waiter,
// otherwise concurrent Waits will race with each other.
race.Write(unsafe.Pointer(&wg.sema))
}
runtime_Semacquire(&wg.sema)
if wg.state.Load() != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
}
}WaitGroup结构有3个字段,noCopy字段是一个空结构体,它用来标记WaitGroup结构体不应该被复制,它会进行强制检测,如果检测到我们的程序中 WaitGroup 有复制的操作,那么程序就会报错;state是一个Uint64的原子类型,用于存储 WaitGroup 的状态信息。高位的 32 bits 对应的是 counter 计数器,用来表示目前还没有完成任务的协程个数;低 32 bits 对应的是 waiter 的数量,表示目前已经调用了 WaitGroup.Wait 的协程个数。
sema 是一个 uint32 类型的字段,用于实现信号量。由于wait可能被调用多次,这时候需要确保只有第一个等待者会执行写入,同时也需要确保调用 Wait 方法之前至少已经调用了一个 Add 方法。wait方法中的一些操作需要与Add方法中的操作同步,以确保不会互相干扰。
Add 函数主要功能是将 counter加上新增的协程数量。
这里为什么是 delta 要左移 32 位呢?
因为 state 函数拿出的 64 位变量,高 32 bits 是 counter,低 32 bits 是waiter,此处的 delta 是要加到 counter 上,因此才需要 delta 左移 32 位。Done 函数是调用Add函数实现的,当Goroutine任务完成时调用Done 函数使counter-1。
Wait 函数 主要是增加 waiter 的个数。它主要是通过 atomic.CompareAndSwapUint64 函数 CAS (比较并且交换)的方式来操作 waiter 的。
小结
主要介绍了waitgroup的用法和实现原理。在使用waitgroup的时候,其传参需要传指针类型,因为需要在函数中对waitgroup内部的数据进行修改,在waitgroup的结构体中会通过nocopy字段进行检测,如果没有使用指针类型就会抛出异常。waitgroup的第二个字段state,它是一个Uint64的原子类型,用于存储 WaitGroup 的状态信息。高位的 32 bits 对应的是 counter 计数器,用来表示目前还没有完成任务的协程个数;低 32 bits 对应的是 waiter 的数量,表示目前已经调用了 WaitGroup.Wait 的协程个数。第三个字段sema 是一个 uint32 类型的字段,用于实现信号量。
当调用Add(delta int)方法时可以增加或减少计数器的值,正数表示增加等待的goroutine数量,负数表示减少。这个方法使用原子操作来保证计数器的安全更新;
当调用Wait()方法时,如果计数器的值不为0,则当前goroutine会进入等待状态,同时会将当前goroutine加入到等待队列中。在调用Done()方法时,如果计数器的值变为0,则会唤醒所有等待的goroutine,使它们继续执行。
互斥锁和读写锁的实现原理
Go语言内置了两种锁的实现:
- 读写锁(sync.RWMutex)
- 互斥锁(sync.Mutex)
他们都实现了接口:
代码路径:$GOROOT/src/sync/mutex.go
// A Locker represents an object that can be locked and unlocked.
type Locker interface {
Lock()
Unlock()
}互斥锁实现原理
来看看互斥锁是怎么实现的
源码路径:$GOROOT/src/sync/mutex.go
type Mutex struct {
state int32 // 锁的状态
sema uint32 // 信号量,用于管理等待队列
}
// Lock 尝试获取锁
func (m *Mutex) Lock() {
// 尝试快速获取锁, 快速路径:使用原子操作 CompareAndSwapInt32 尝试快速获取锁。如果 state 是 0(表示未锁定),则将其设置为 mutexLocked,表示锁定成功。
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
// 如果成功,且启用了竞争检测,则记录获取锁的操作
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// 如果快速路径失败,进入慢速路径,自旋
m.lockSlow()
}
// lockSlow 处理锁竞争的情况
func (m *Mutex) lockSlow() {
// 这里会涉及到将当前 goroutine 放入等待队列
// 并在锁可用时唤醒
// 具体实现较为复杂,涉及信号量和调度器的交互
}读写锁的底层原理
源码路径:$GOROOT/src/sync/mutex.go
type RWMutex struct {
w Mutex // 用于控制写操作的排他性
writerSem uint32 // 写操作的信号量
readerSem uint32 // 读操作的信号量
readerCount atomic.Int32 // 当前正在进行的读操作数量
readerWait atomic.Int32 // 正在等待完成的读操作数量
}
// RLock 获取读锁
func (rw *RWMutex) RLock() {
// 增加 readerCount,表示有新的读操作
if rw.readerCount.Add(1) < 0 {
// 如果有写操作在等待,当前读操作需要等待
rw.rlockSlow()
}
}
// rlockSlow 处理读锁的慢速路径
func (rw *RWMutex) rlockSlow() {
// 这里会涉及到等待写操作完成
// 并在可以安全读取时继续
}
// Lock 获取写锁
func (rw *RWMutex) Lock() {
// 获取写锁,阻塞所有新的读写操作
rw.w.Lock()
// 等待所有读操作完成
rw.waitForReaders()
}
// waitForReaders 等待所有读操作完成
func (rw *RWMutex) waitForReaders() {
// 检查 readerCount,如果有读操作在进行,等待其完成
if rw.readerCount.Load() != 0 {
// 等待机制,通常涉及信号量
}
}互斥锁是一种混合锁,其实现方式包含了自旋锁,同时参考了操作系统锁的实现。
sync.RWMutex提供了比sync.Mutex更加细粒度的锁控制,将读锁和写锁做了分离,读写锁是基于sync.Mutex互斥锁实现的,通过readerCount的值来达到读写锁通信的目的。
Go锁的一些特性
基本特性
RWMutex是单写多读锁,它可以加多个读锁或者一个写锁;
读锁占用的情况下会阻止写,但不会阻止读,多个 goroutine 可以同时获取读锁;
写锁会阻止其他 goroutine(无论读和写)进来,整个锁由该 goroutine 独占;
读写锁适用于读多写少的场景。互斥锁是一种混合锁,其实现方式包含了自旋锁,同时参考了操作系统锁的实现。而读写锁在自旋锁的基础上提供了比sync.Mutex更加细粒度的锁控制,将读锁和写锁做了分离,读写锁是基于sync.Mutex互斥锁实现的。
不可重入性
获取读锁之后再获取写锁会发生fatal error
Go语言中的锁是不可重入的,也就是不允许获取读锁之后再获取写锁,在java中会直接导致死锁,而在Go语言中会直接抛出fatal error导致程序终止
//1. 不可重入性
func NonReentrant() {
rw := sync.RWMutex{}
rw.RLock()
fmt.Println("获取读锁")
rw.Lock() //读锁未解锁的情况下操作获取写锁会导致panic
fmt.Println("获取写锁")
rw.RUnlock()
rw.Unlock()
}报错内容如下:
获取读锁
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [sync.RWMutex.Lock]:
sync.runtime_SemacquireRWMutex(0xd?, 0x40?, 0x0?)
......
......
......
exit status 2写锁只有在读锁和写锁都处于未加锁的状态下才能成功加锁
上面我们演示了先加读锁,在读锁未解锁的请款下加写锁时会导致程序异常终止,同样,在写锁未解锁的情况下再加写锁会导致死锁。
func OnlyOneWriteLock() {
lock := sync.RWMutex{}
//lock := sync.Mutex{}
lock.Lock()
defer lock.Unlock()
fmt.Println("获取写锁")
lock.Lock() //写锁未解锁的情况下会阻塞
fmt.Println("获取写锁")
defer lock.Unlock()
}输出:
获取写锁
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [sync.Mutex.Lock]:
......
......
......
exit status 2加锁和解锁可以由不同的协程来执行
func main() {
lock := sync.Mutex{}
for {
//未解锁将在此处阻塞
lock.Lock()
fmt.Println("LockandUnlockIndiffGoroutine-main:获取锁")
go LockandUnlockIndiffGoroutine(&lock)
time.Sleep(1)
}
}
func LockandUnlockIndiffGoroutine(lock *sync.Mutex) {
time.Sleep(time.Second)
lock.Unlock()
fmt.Println("LockandUnlockIndiffGoroutine:释放锁")
}输出:
LockandUnlockIndiffGoroutine-main:获取锁
LockandUnlockIndiffGoroutine-main:获取锁
LockandUnlockIndiffGoroutine:释放锁
LockandUnlockIndiffGoroutine:释放锁
LockandUnlockIndiffGoroutine-main:获取锁
LockandUnlockIndiffGoroutine:释放锁
LockandUnlockIndiffGoroutine-main:获取锁
LockandUnlockIndiffGoroutine:释放锁
LockandUnlockIndiffGoroutine-main:获取锁
LockandUnlockIndiffGoroutine:释放锁
LockandUnlockIndiffGoroutine-main:获取锁
LockandUnlockIndiffGoroutine:释放锁
LockandUnlockIndiffGoroutine-main:获取锁
LockandUnlockIndiffGoroutine:释放锁
LockandUnlockIndiffGoroutine-main:获取锁
...读锁未释放时,写锁也会被阻塞
为了避免多个协程并发操作,写锁会确保当前只有一个协程能获取锁。同样为了避免读到脏数据,在读锁未释放时,写锁也会被阻塞
//写锁未释放,无法获取写锁
func getLock() {
mutex := sync.RWMutex{}
mutex.Lock()
fmt.Println("获取到写锁")
go func() {
time.Sleep(time.Second * 2)
mutex.Unlock()
}()
//会被阻塞,等待子协程释放锁
mutex.Lock()
fmt.Println("主协程再次获取写锁")
}
//写锁未释放前,无法获取读锁
func getRLock() {
mutex := sync.RWMutex{}
mutex.Lock()
fmt.Println("获取到写锁")
go func() {
time.Sleep(time.Second * 2)
mutex.Unlock()
}()
//会被阻塞,等待子协程释放锁
mutex.RLock()
fmt.Println("主协程再次获取写锁")
}
//读锁未释放,无法获取写锁
func getRLock1() {
lock := sync.RWMutex{}
lock.RLock()
fmt.Println("加读锁")
go func() {
time.Sleep(3 * time.Second)
lock.RUnlock()
}()
//读锁解锁前会阻塞
lock.Lock()
fmt.Println("主协程获取写锁成功")
}性能测试
package main
import (
"fmt"
"sync"
"time"
)
type Counter struct {
count int64
lock sync.RWMutex
}
func (c *Counter) ReadValue() int64 {
c.lock.Lock()
defer c.lock.Unlock()
return c.count
}
func (c *Counter) ReadValue1() int64 {
c.lock.RLock()
defer c.lock.RUnlock()
return c.count
}
func (c *Counter) ReadValue2() int64 {
return c.count
}
func (c *Counter) Incr(delta int64) {
c.lock.Lock()
defer c.lock.Unlock()
c.count += delta
}
func main() {
c := Counter{}
c.Incr(1)
const Num = 10000000
t := time.Now()
for i := 0; i < Num; i++ {
go func() {
c.ReadValue()
}()
}
fmt.Println("ReadValue cost:", time.Since(t).Milliseconds())
t1 := time.Now()
for i := 0; i < Num; i++ {
go func() {
c.ReadValue1()
}()
}
fmt.Println("ReadValue1 cost:", time.Since(t1).Milliseconds())
t2 := time.Now()
for i := 0; i < Num; i++ {
go func() {
c.ReadValue2()
}()
}
fmt.Println("ReadValue2 cost:", time.Since(t2).Milliseconds())
}
输出:
ReadValue cost: 1785
ReadValue1 cost: 1403
ReadValue2 cost: 1323可以看出,读取频繁的场景,加读锁跟不加锁耗时更长,而加写锁的耗时比加读锁更长。
通过锁来控制goroutine的顺序:
func ControlGoroutineOrder() {
m := sync.RWMutex{}
m.Lock()
go func() {
m.Lock()
fmt.Println("go1")
m.Unlock()
}()
go func() {
fmt.Println("go2")
m.Unlock()
}()
time.Sleep(5 * time.Second)
}输出:
go2
go1select的底层原理
- select语句就是用来监听和channel有关的IO操作,当IO操作发生时,触发相应的case操作,所以它是用于处理多个通道操作的一种机制。
select的底层数据结构是一个用于存储 case 条件和对应操作的数据结构。它并不是一个常规的数据类型,而是由编译器在编译时生成的结构。有了select语句,可以实现更灵活的多通道操作; - select本质是实现了多路IO复用机制。linux操作系统主要有3种常见的IO模型:poll,epoll和select。而go的select与linux的系统IO模型中的select类似。它可以用于检测是否有就绪(ready)的读写事件;
select在语法结构上与switch的控制结构类似,与switch不同的是,select中虽然也有多个case,但是这些case中的表达式都必须与 Channel 的操作有关,也就是 Channel 的读写操作。
select 底层结构
所有的case语句一起组成scase的结构数组[]scase
源码路径:$GOROOT/src/runtime/select.go
type scase struct {
c *hchan // chan的结构体类型指针
elem unsafe.Pointer // 读或者写的缓冲区地址
}
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}当前Go版本(Go1.20.4)中,scase包含了两个字段,由于非 default的 case中都与 channel的发送和接收数据有关,所以在 scase结构体中也包含一个 c字段用于存储 case中使用的 channel,elem为当前 case语句所操作的 channel指针,这也说明了一个 case语句只能操作一个 channel。
select执行过程可以看成一个函数,函数输入 case数组,输出选中的 case,然后执行选中的 case分支的代码块,selectgo的具体实现参考「Golang进阶之路」GMP底层结构和select实现说明
这里看一下函数定义:
// selectgo函数实现了Go语言中的select语句。
//遍历所有的case语句,如果所有的case都未就绪,则走default,如果没有default,则会阻塞。
//如果有就绪channel,则直接跳出随机进行管道操作并返回
// 第一个返回值返回的是被选择的scase的索引,这个索引就是需要执行的case分支;
// 第一个返回值标记这个case语句是否接收到了一个值。
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool) {
if debugSelect {
print("select: cas0=", cas0, "\n")
}
....
}selectgo 函数实现的功能就是从 select 控制结构中的多个 case 中选择一个需要执行的 case,然后返回被选择的 case 的索引。这个索引就是当前被选中的case在 select 语句中的位置;第二个返回值表示的是当前case是否成功从 channle中读取了数据,如果选中的 case是从 channel中读数据,则该返回值表示是否读取成功。
在编译期间,Go 语言会对 select 语句进行优化,根据 select 中语句的不同选择了不同的优化路径,其中一项优化是对于空的 select 语句会被直接转换成 block 函数的调用,直接挂起当前 Goroutine,让出CPU。所以我们如果想让当前协程不退出的话,不应该使用死循环的方式,应该通过空select实现。
select的特性
select-case分支流程控制语法跟switch-case分支流程控制语法很相似,但也有很多不同点:
- switch后面是可以存在表达式或语句的,但select后面是不允许的,select仅支持管道,而且是单协程操作;
- select-case分支中不能使用fallthrough语句,因为select-case执行机制中每次只能有一个case被激活;
- 每个case语句仅能处理一个管道,要么读要么写。每个case关键字后必须跟随一个通道接收数据操作或者一个通道发送数据操作;通道接收数据操作可以作为源值出现在一条简单赋值语句中;
- 所有的非阻塞case操作中每次将只有一个被随机选择执行(而不是按照从上到下的顺序),然后执行这个操作对应的case分支代码块;
- 在所有的case操作均为阻塞的情况下,如果default分支存在,则default分支代码块将得到执行; 否则,当前协程将被推入所有阻塞操作中相关的通道的发送数据协程队列或者接收数据协程队列中,并进入阻塞状态。所以一个不含任何分支的select-case代码块select{}将使当前协程处于永久阻塞状态。存在default语句,select将不会阻塞,但是存在default会影响性能。
随机性可以用这个验证一下:
func main() {
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
ch1 <- 1
ch2 <- 2
for i := 0; i < 2; i++ {
fmt.Println("i:", i)
select {
case <-ch1:
fmt.Println("ch1")
case <-ch2:
fmt.Println("ch2")
}
}
}本作品采用《CC 协议》,转载必须注明作者和本文链接











 关于 LearnKu
关于 LearnKu




推荐文章: