
OpenClaw:安装与使用上的一些分享
52 / 0 / 创建于 5个月前 /
 Sown 的个人博客
Sown 的个人博客
最近这只“龙虾”实在太火了,我也专门买了一台 Mac mini 来实际体验。
下面结合我的真实环境和遇到的问题,聊聊 OpenClaw 的安装和使用。
安装
下面以这台 Mac mini 为例说明安装过程。
# 下载并安装
curl -fsSL https://openclaw.ai/install.sh | bash在我写这篇文章的这个版本里,由于是全新机器,系统里还没有安装 Homebrew,安装脚本会先报错提示,并且提醒需要 sudo 权限来运行脚本。
我的做法是:先单独安装好 Homebrew,然后再执行上面的安装命令,而不是直接用 sudo 去跑 curl ... | bash。
配置
openclaw onboard --install-daemon这条命令会启动配置向导,在命令行界面一步步提问。你可以通过键盘上下方向键选择,按回车确认,大部分场景跟着提示走就能完成初始配置。
如果第一次配置没选好,也不用紧张,后面可以随时重新配置,执行:
openclaw configure如果这两种方式都改不了你想要的细节,那还有一招:手动修改配置文件:
~/.openclaw/openclaw.json这种方式改完之后,需要重启 OpenClaw 的守护进程,配置才会真正生效。
接下来我挑选几个个人觉得比较关键的配置项展开说一下。
Models(模型)
这里我一开始选择的是 minimax-cn/MiniMax-M2.1:先在 MiniMax CN 官网订阅对应套餐,创建并复制一个 token,然后在配置向导里的输入框里粘贴即可完成绑定。
后续我准备切到 GLM 的方案,连续包年 216/年,整体性价比非常不错,尤其是中文场景下体验更好。
推荐链接:www.bigmodel.cn/glm-coding?ic=WAL8...
可能的问题
以 MiniMax 举例,如果我们在配置 Model 时选择了带 “-cn” 的型号,由于国内外模型的 API 地址并不一样,默认配置有时还是会调用到国外的 endpoint。
这种情况下,就需要手动改一下配置文件中对应模型的配置,把 baseUrl 从 https://api.minimax.io/anthropic 修改为 https://api.minimaxi.com/anthropic。
Channels(聊天渠道)
执行如下命令,然后依次选择 Channel -> 你想要的聊天工具:
openclaw configure这里我目前依次配置了三种渠道:
1. WhatsApp
这是目前最简单也最“接地气”的方式:用手机扫码登录,然后在终端里输入一个配对码确认,基本就能用了。
2. Telegram
需要先创建一个 bot,拿到 bot 的 token,然后再绑定上你自己的 user id(可以通过常见的辅助机器人获取),之后就可以和自己的机器人单聊来驱动 OpenClaw。
3. Discord
这一种相对最复杂一些:先在 Discord 个人设置里打开「开发者模式」,然后到 discord.com/developers/application... 创建应用,再创建 Bot、配置 OAuth2 并把 Bot 加到指定服务器/频道中。
官方文档写得比较详细,推荐直接参考:docs.openclaw.ai/zh-CN/channels/di...
三种方式的比较
Discord 频道天然支持会话隔离,对不同项目来说非常友好。我打算在项目开发场景下按项目创建不同频道,一个频道对应一个项目。
另外,我设置的是不 @bot 时它不会自动介入聊天,这样平时一些项目备忘、讨论记录可以直接贴在频道里,需要 AI 参与时再 @ 一下就好。
WhatsApp 给我的感觉人味儿更重,而且私密性更好。后面我会把它更多当成个人助理:比如提醒、通知,甚至一些需要打电话沟通前的准备。
Telegram 我尝试过把 bot 加到群组里使用,但在我的配置下并没有正常工作,可能和权限/设置有关,目前还是以和 bot 的私聊为主。
目前的使用方式
上面提到,我现在使用的是 MiniMax,后面会逐步切到 GLM。虽然国产模型整体表现已经不错,但我目前还不打算直接让它承担主要的 Coding 工作,而是继续用 Claude 来写代码。
不过,如果直接在 OpenClaw 里配置在线版 Claude,封号风险会比较大。所以我的做法是先在本地安装 claude 命令行工具,然后让 OpenClaw 去调用这个本地的 Claude,相当于通过一层本地代理来使用它。
这里就依靠Claude的两个参数
-p:不进入会话,执行完成后输出结果
--dangerously-skip-permissions:允许所有需要确认的操作这两个参数结合起来,就非常适合作为“被其它程序调用的后端执行器”使用,这点必须给 Claude CLI 点个赞。
有人可能会担心 --dangerously-skip-permissions 会不会太危险。我的建议是:如果你调用的是自己写好的、经过验证的 Skill,绝大部分场景问题不大;但在 Skill 逻辑还不成熟、或者可能涉及删除/覆盖文件等操作时,还是要格外小心,可以优先在测试项目里跑一遍。
在这样的前提下,我们就可以让机器人以一种相对安全、自动化的方式去执行任务:
1\. 进入到 ~/WebstormProjects/projectA
2\. 执行如下shell命令如下:
claude -p --dangerously-skip-permissions " 使用 skill ... "
3\. 执行完成之后总结一下任务情况
4\. 任务情况正常就提交并推送代码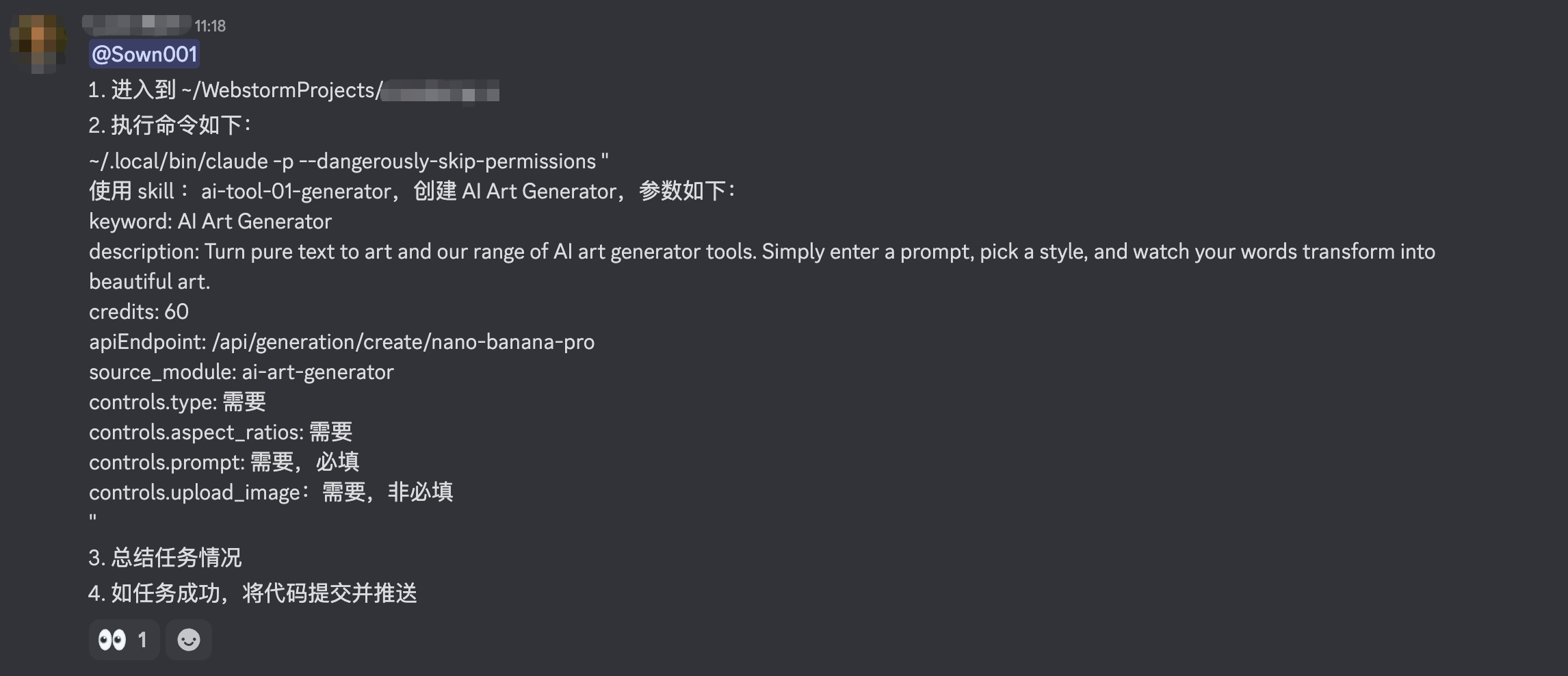
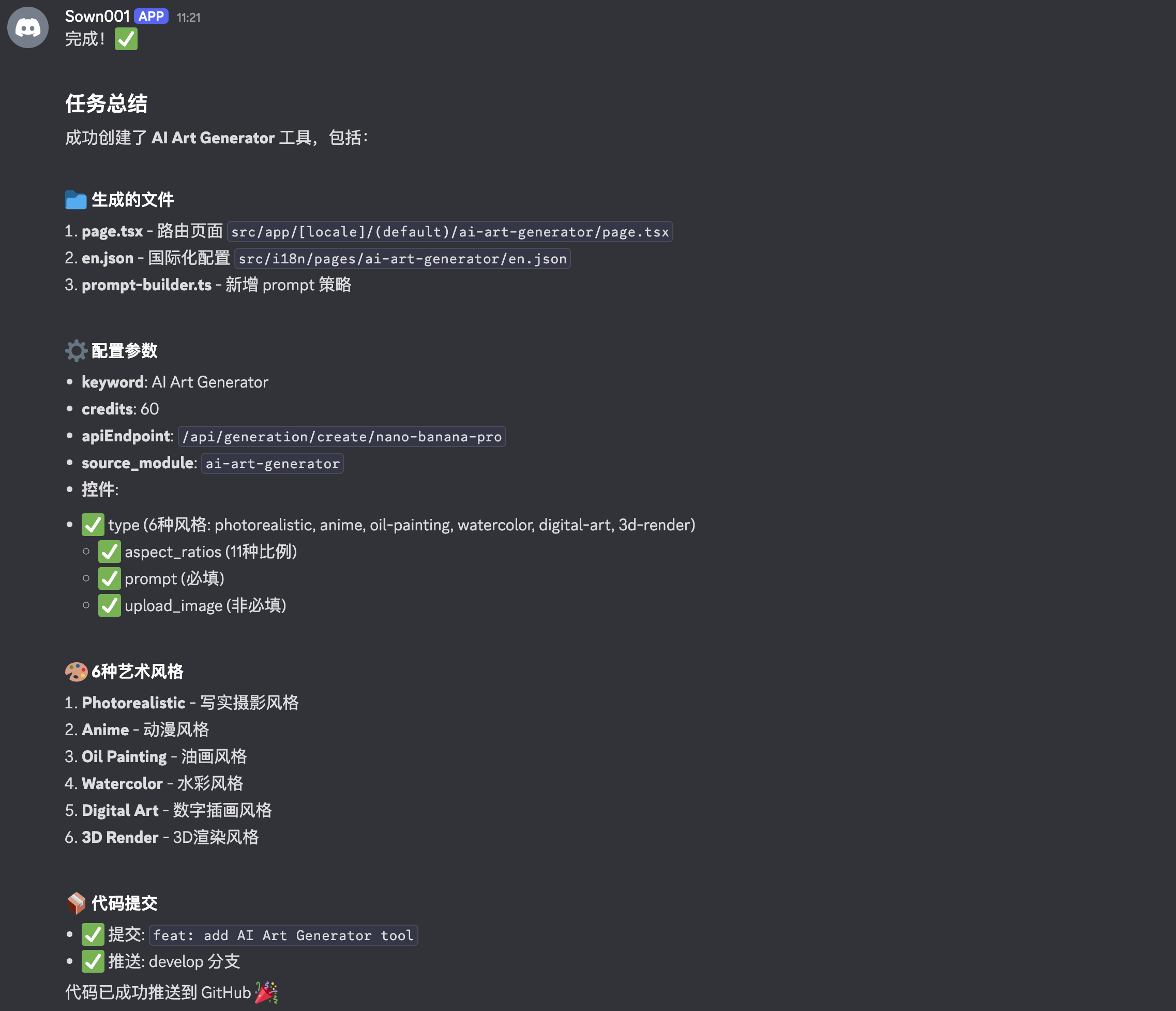
持续做的事
完善 Skill
接下来我会把日常开发中那些「经常重复、但又比较耗脑子」的流程,慢慢沉淀成一个个独立的 Skill,比如:
- 新项目初始化、脚手架搭建
- 常见 Bug 的排查路径
- 例行重构/代码清理的步骤
这些东西本质上就是“基建”:前期花点时间打牢,后面每次调用时,AI 直接沿着这条已经铺好的路跑,效率和稳定性都会高很多。
同时,我也会在实际使用后不断回写经验:每当某个 Skill 出错或者不够好用,就在对应的 md 里补充一两句说明,久而久之它就会变成一套越来越贴合自己工作方式的「AI 工作手册」。
使用更多 OpenClaw 功能
另一方面,我也会在不打扰现有业务节奏的前提下,逐步尝试更多 OpenClaw 的能力,比如:
- 在更多项目里接入不同的 Channel,看看哪种沟通方式最自然
- 尝试让它参与到代码评审、任务拆分、文档梳理等不同环节
- 把一些和业务强相关的流程拆分出来,看看能否做成专门的 Skill 组合
目标不是「为了用功能而用功能」,而是结合手头正在做的项目,一步一步地把这些能力自然地嵌到工作流里。
后续如果有比较成熟的实践,我也会再写几篇更聚焦的文章,把具体案例、配置细节和踩坑记录分享出来。
体会
OpenClaw + Skill 这种组合,我目前有几点体会:
token 消耗
如果只靠一句话需求,频繁让 AI 去读取整个项目,token 消耗会非常惊人,长期看其实并不太可持续。
而 Skill 不一样,它是一条相对固定的“逻辑链”,从输入、处理到参考结果、模版都可以复用,整体在 token 和时间上的消耗都会更可控。
可迭代性
以前我们可能习惯把 prompt 零散地放在各种笔记软件里,不好管理版本。现在可以把每个 Skill 独立成一个 md 文件,直接放在项目里管理。
每次执行出错时,还可以顺手让 AI 帮忙把这次的经验补充到对应的 skill.md 中,就像在持续更新 claude.md 这种知识库一样。
编程心态
如果每次都是临时的一句话需求,AI 很容易频繁犯错,自己也会越来越依赖“聊天”而不是“设计流程”,久而久之反而会觉得调用 AI 编程是一种负担。
把需求抽象成可复用的 Skill,本质上是在训练自己用工程思维、用模块化方式来和 AI 合作,这种心智的转变会在中长期里慢慢体现价值。
Skill 结合 OpenClaw 的爆发点
上面三点更多是围绕 Skill 本身的好处,而当 Skill 逐渐完善之后,真正让它们“爆发”的,是 OpenClaw:
- OpenClaw 帮你把这些 Skill 接到各种渠道上,让它们随时待命,变成可以随手召唤的「能力面板」
- 守护进程常驻在本地/服务器,能把复杂任务拆成一连串自动化步骤交给 Skill 执行
- 对接项目代码仓库、日志、工具链之后,Skill 不再只是一个「聪明的 prompt」,而是贴在真实生产环境上的一套自动化工作流
简单说,Skill 更像是「知识和流程的沉淀」,而 OpenClaw 则是那个把它们组织起来、调度起来、真正落地到项目里的「总控室」。两者叠加的那一刻,才是我觉得最有想象力、也最值得长期投入的地方。
总结
这篇文章基本是按「最小可行步骤」把 OpenClaw 从安装到使用走了一遍,更多是把我自己遇到的问题和一些选择背后的原因讲清楚,方便你少踩一点坑。
最后,我还是想强烈邀请你早点参与进来,一起探索:
1. 调整思维习惯和认知,慢慢养成和 AI 合作的工作方式
2. 尽早找出一条真正适合自己的 AI 开发之路,而不是简单跟风工具
3. 让项目从一开始就朝「AI 编程友好」的框架和架构去设计
4. 多建设、多总结、多分享,一起成长
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



