
使用 face-api.js 在你的浏览器中做人脸识别(基于 tensorflow.js)

我很兴奋地告诉你,终于可以在浏览器中运行人脸识别了!这篇文章我将介绍 face-api.js ,这个类库构建于 tensorflow.js 之上。它实现了多个 CNNs(卷积神经网络)以解决人脸检测、人脸识别和人脸标识检测的问题,并进行了优化适用于网络和移动设备。
与往常一样,我们将看一个简单的代码示例,演示几行代码就可以使用该软件包。如果您想先尝试一些示例,请查看演示页面! 但不要忘了回来读这篇文章。 ;)
让我们开始吧!
注意,该项目正在积极开发中。请务必查看我的最新文章,随时了解 face-api.js的最新功能:
如何通过深度学习解决人脸识别
如果您希望尽快入门,您可以跳过这一节,直接跳到代码中。但为了更好地了解face-api.js 中用于实现人脸识别的方法,我强烈建议您继续学习,因为我经常被问到这一点。
简单来讲,我们想要实现的是,根据给定的人脸图像来识别一个人。方法是,为我们想识别的每个人提供一个(或多个)图像,并用人名标记。我们将输入图像与参考数据进行比较,找到 最相似的 参考图像。如果两个图像足够相似,输出 人名,否则输出未知。
提起来很容易!然而,还有两个问题。首先,如果我们有一多人的图像,并且我们想识别所有人,那会怎么样?其次,我们需要能够获得两个人脸图像的相似度百分比,以便对它们进行比较……
人脸检测
第一个问题的答案是人脸检测。简单地说,我们将首先定位输入图像中的所有人脸。Face-api.js 为不同的使用情况实现多个人脸检测器。
最准确的人脸检测器是 SSD(单发多框检测器 Single Shot Multibox Detector),它是基于 MobileNet V1 的CNN,在网络顶部堆叠了一些附加的框预测层。
更进一步,face-api.js 实现了优化的 Tiny Face Detector,是 Tiny Yolo v2 的甚至更小版本,它利用深度可分离卷积代替常规卷积,与之相比,速度更快,但精度略低 SSD MobileNet V1。
最后,还有一个MTCNN(多任务级联卷积神经网络)实现,但是现在主要用于实验目的。
网络会返回每个面孔的边界框,以及相应的得分,例如每个边界框显示一张脸的概率。分数用于过滤边界框,因为图像可能根本不包含任何面孔。请注意,即使只有一个人,也应该执行面部检测以检索边界框。

人脸标志检测和人脸对齐
第一个问题解决了!但是,我想指出的是,我们要对齐边界框,以便我们可以在图像提取出来之前,将其传递到面部识别网络,因为这将使面部识别更加准确!
为此,face-api.js 实现了一个简单的 CNN,该 CNN 返回给定面部图像的 68 点面部界标:

从界标位置开始,边界框可以在面部居中。在下面,您可以看到人脸检测的结果(左)与对齐的人脸图像(右)的比较:

人脸识别
现在,我们可以将提取和对齐的人脸图像馈送到人脸识别网络中,该网络基于类似于 ResNet-34 的体系结构,基本上对应于在 dlib 中实现的体系结构。 该网络经过训练,学会将人脸特征映射到 人脸描述符 (128个值的特征向量),这通常也被称为人脸嵌入。
接下来回到我们最初比较两个人脸的问题:我们将使用每个提取到的人脸描述符,将它们与参考数据的人脸描述符进行比较。更准确地说,我们可以计算两个人脸描述符之间的 欧几里得度量(euclidean distance),并根据 阈值(threshold value) 判断两个人脸是否相似(对于150 x 150大小的人脸图像0.6是一个很好的阈值)。使用 欧几里得度量 效果出奇的好,当然你可以使用任何分类器。下面的 gif 通过欧几里得度量将两个人脸图像的比较可视化:

现在,我们已经掌握了面部识别理论,现在可以开始编写示例了。
码代码!
在这个简短的示例中,我们将逐步显示如何在以下显示多人的输入图像上进行人脸识别:
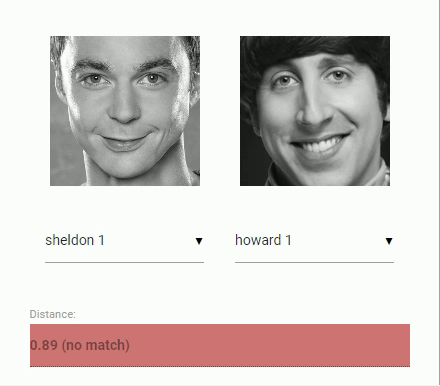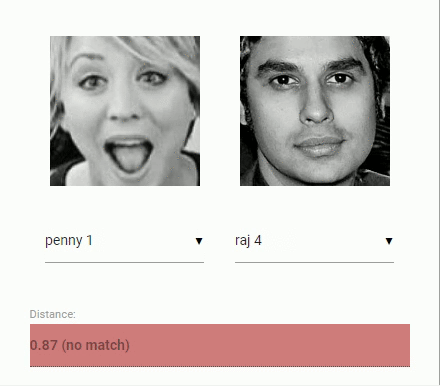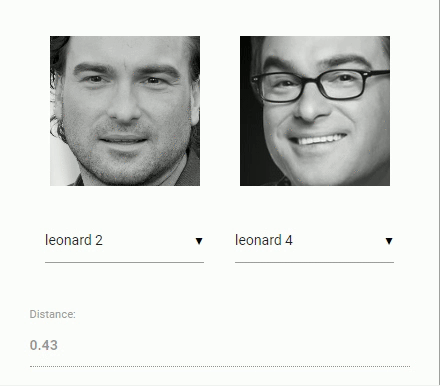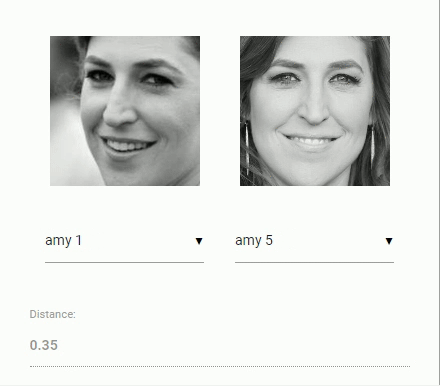
脚本
首先,从dist / face-api.js 或 dist/face-api.min.js 获取最新版本并包含以下脚本:
<script src="face-api.js"></script>如果您使用npm:
npm i face-api.js载入模型数据
根据您的应用程序的需求,您可以专门加载所需的模型,但是要运行一个完整的端到端示例,我们将需要加载人脸检测,人脸界标和人脸识别模型。模型文件可在仓库中找到,并可以在这里中找到。
模型权重已量化,与原始模型相比,模型文件大小减少了 75%,从而使您的客户端仅加载所需的最小数据量。此外,模型权重被划分为最大 4 MB 的块,以允许浏览器缓存这些文件,从而使它们仅需加载一次。
模型文件可以简单地以静态资产的形式在您的Web应用程序中提供,也可以将它们托管在其他位置,并且可以通过指定文件的路由或URL来加载。假设您是在 models 目录中提供它们,并在 public / models 下提供资产:
loadModels.js:
const MODEL_URL = '/models'
await faceapi.loadSsdMobilenetv1Model(MODEL_URL)
await faceapi.loadFaceLandmarkModel(MODEL_URL)
await faceapi.loadFaceRecognitionModel(MODEL_URL)从输入图像中接收到完整的人脸信息
神经网络支持 HTML 的 img、canvas 或 video 元素或 Tensors 的输入。检测输入图像的所有脸部边缘信息,我们只需要调用 detectAllFaces(input):
computeFullFaceDescriptions.js
const input = document.getElementById('myImage')
let fullFaceDescriptions = await faceapi.detectAllFaces(input).withFaceLandmarks().withFaceDescriptors()一个完整的脸部信息检测结果(边界盒 + 分值),好的脸部标示作为计算描述符。通过省略 faceapi.detectAllFaces(input,options) 的第二个 options 参数,SSD MobileNet V1 将默认用于人脸检测。要改 用Tiny Face Detector 或 MTCNN,只需指定相应的选项即可。
有关面部检测选项的详细文档,请参阅 github repo 自述文件中的相应部分。注意,您必须预先加载相应的模型,对于您要使用的面部探测器,就像我们对 SSD MobileNet V1 模型所做的那样。
返回的边界框和界标位置相对于原始图像或媒体的尺寸。如果显示的图像尺寸与原始图像尺寸不符,您可以简单地重制它们的尺寸:
fullFaceDescriptions = faceapi.resizeResults(fullFaceDescriptions)我们可以通过将边界框绘制到画布中来可视化检测结果:
drawDetections.js
faceapi.draw.drawDetections(canvas, fullFaceDescriptions)

我们可以通过在画布中绘制边界框来可视化检测结果:
drawLandmarks.js
faceapi.draw.drawLandmarks(canvas, fullFaceDescriptions)

通常,我的可视化工作所做的是在 img 元素的上面覆盖一层绝对定位的画布,这个画布和 img 元素宽高相同。(更多相关信息,请参见 github 示例)。
人脸识别
现在我们知道了如何在给定输入图像的情况下检索所有面部的位置和描述符,我们将获得一些分别显示一个人的图像并计算其面部描述符。这些描述符将是我们的 参考数据.
假设我们有一些可用的示例图像,我们首先从url获取图像,然后使用 faceapi.fetchImage 从其数据缓冲区创建 HTML 图像元素。对于每个获取的图像,我们将定位被摄对象的脸部并计算脸部描述符,就像我们之前对输入图像所做的那样:
computeReferenceDescriptors.js
const labels = ['sheldon' 'raj', 'leonard', 'howard']
const labeledFaceDescriptors = await Promise.all(
labels.map(async label => {
// 从url获取图像数据并将blob转换为HTMLImage元素
const imgUrl = `${label}.png`
const img = await faceapi.fetchImage(imgUrl)
// 检测图像中得分最高的人脸并计算其界标和人脸描述符
const fullFaceDescription = await faceapi.detectSingleFace(img).withFaceLandmarks().withFaceDescriptor()
if (!fullFaceDescription) {
throw new Error(`no faces detected for ${label}`)
}
const faceDescriptors = [fullFaceDescription.descriptor]
return new faceapi.LabeledFaceDescriptors(label, faceDescriptors)
})
)注意,这次我们使用 faceapi.detectSingleFace 将仅返回检测到的得分最高的人脸,因为我们假设在该图像中仅显示给定标签的字符。
现在,剩下要做的就是将从我们的输入图像到我们的参考数据中检测到的人脸的面部描述符匹配起来,例如带标签的人脸描述符。为此我们可以使用 faceapi.FaceMatcher,具体如下:
faceRecognition.js
// 0.6 是判断距离的好阈值
// 描述符是否匹配
const maxDescriptorDistance = 0.6
const faceMatcher = new faceapi.FaceMatcher(labeledFaceDescriptors, maxDescriptorDistance)
const results = fullFaceDescriptions.map(fd => faceMatcher.findBestMatch(fd.descriptor))人脸匹配器使用欧几里德距离作为相似性度量,事实证明效果很好。最后,我们为输入图像中检测到的每个脸部提供了最佳匹配,其中包含标签+匹配的欧式距离。
最后,我们可以将边界框及其标签绘制到画布中以显示结果:
drawResults.js
results.forEach((bestMatch, i) => {
const box = fullFaceDescriptions[i].detection.box
const text = bestMatch.toString()
const drawBox = new faceapi.draw.DrawBox(box, { label: text })
drawBox.draw(canvas)
})

好了!到目前为止, 我希望您对使用 api 有一个初步的了解。另外,我建议您查看回购中的其他示例。现在,尽情享受吧,祝您愉快! ;)
如果您喜欢这篇文章,请您留下一些赞,并关注我,或者在 twitter 上关注我 :). 也可以随时在 github repository 上留下星星, 请继续关注更多教程!
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。










 关于 LearnKu
关于 LearnKu




推荐文章: