
 mysql 个人笔记
mysql 个人笔记3.1. 索引基础
索引,存储引擎用于快速找到记录的一种数据结构
3.1 索引基础
- 索引可以包含一个或多个列的值
- MySQL 只能高效地使用索引的最左前缀列。
3.1.1 索引的类型
3.1.1.1 B Tree 索引
- 索引是在存储引擎层实现的
- B Tree 索引,使用 B Tree 存储数据,InnoDB 使用的是 B+Tree,B Tree 所有值按顺序存储,每个叶子到根的距离相同,B Tree 通过在节点中保存下层节点上下限的方式来引导查询,降低查询复杂度,提高查询效率。
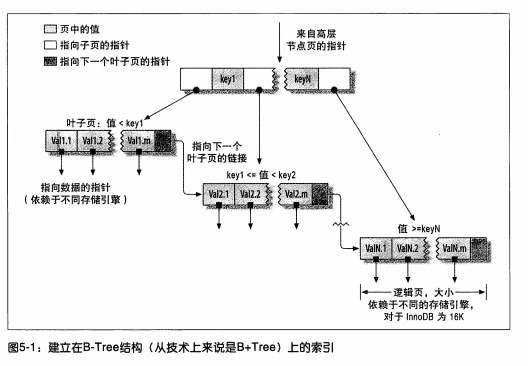
- 叶子节点中为被索引的数据,树的深度与表的大小直接相关。
- B Tree 索引列是顺序组织的,很适合范围查找
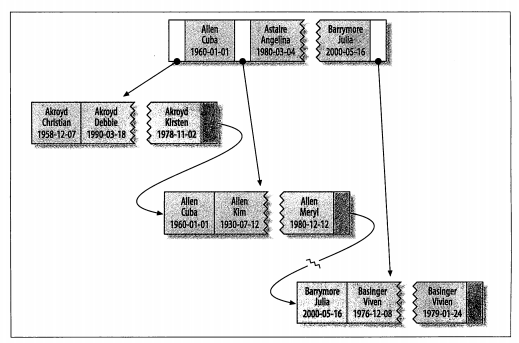
联合索引:
- key(last_name, first_name, dob)按照定义索引时的顺序进行排序。
- B Tree 索引适用于全健值、键值范围、最左键前缀查找。
- 除按值查找外,还可用于 order by 操作。
B Tree 索引限制:
- 如果不是按照索引最左列开始查找,则无法使用索引
- 不能跳过索引中的列
- 如果查询中有某个列的范围查询,则其右边列无法使用索引优化,(因为直接全覆盖了)
3.1.1.2 哈希索引
- 基于哈希表实现,对于每一行数据,对所有索引列计算一个哈希码,哈希码存储在哈希表中,并保存指向每个数据行的指针。MySQL中,只有 Memory 引擎显示支持哈希索引。
限制:
- 只包含哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行
- 并不是按照索引值顺序存储,所以无法用于排序
- 因为使用所有索引列进行哈希计算,所以不支持部分索引列匹配查找。
- 哈希索引只支持等值比较查询
- 出现哈希冲突时需要遍历链表中所有行,逐个比较。
- 冲突越多,代价越大。
InnoDB 自适应哈希索引:
InoDB 注意到某些索引值使用特别频繁时,会在内存中基于 B Tree 索引上再创建一个哈希索引,这是一个完全自动、内部的行为,用户无法控制或配置,如果有必要,完全可以关闭该功能。
创建自定义哈希索引,再B Tree 基础上创建一个伪哈希索引,使用哈希值进行索引查找,需要在 where 子句中 手动指定哈希函数。使用场景如 url 列索引,因为字符串过长,匹配速度会过慢,使用 CRC32 做伪哈希后匹配 url,再解决哈希冲突,值匹配会少很多。缺点时需要维护哈希值,可以手动维护,也可以使用触发器实现。不要使用 sha1() md5()作为哈希函数,哈希值是长字符串,会浪费大量空间,比较时也会很慢。sha1() md5() 是强加密函数,设计目标是最大限度消除冲突。CRC32() 出现大量冲突时,可以自定义一个 64 位哈希函数。
使用哈希索引进行查询时,必须在 where 子句中包含常量值,用于避免冲突
3.1.1.3 空间数据索引 R Tree
- 仅 MyISAM 支持,可用作地理数据存储
- 从所有维度来索引数据,无需列前后顺序
- 必须使用 MySQL GIS 相关函数维护数据
3.1.1.4 全文索引
- 查找文本关键字而非比较索引值
- 类似于搜索引擎
- 适用于 MATCH AGAINST 操作,而不是普通的 where 操作。






 关于 LearnKu
关于 LearnKu




推荐文章: