
 通过测试学习 Go 编程
通过测试学习 Go 编程基于属性的测试
基于属性的测试
一些公司会要求您在面试过程中进行 Roman Numeral Kata 。 本章将说明如何使用TDD解决它。
我们将编写一个函数,将阿拉伯数字 (数字0到9)转换为罗马数字
如果您没有听说过罗马数字,它们就是罗马人写下数字的方式。
通过将符号粘贴在一起来构建它们,这些符号代表数字。
I 为 1, III 是 3。
看起来很简单,但是有一些有趣的规则。 V表示 5,但是 IV 是 4 (不是 IIII)。
MCMLXXXIV 是1984年。这看起来很复杂,很难想象我们如何从一开始就编写代码来解决这个问题。
正如本书所强调的,软件开发人员的一项关键技能是尝试写出最小可用代码,然后再进行『迭代』。 TDD 工作流程有助于促进迭代开发。
因此,让我们从 1 开始而不是1984年。
先写测试
func TestRomanNumerals(t *testing.T) {
got := ConvertToRoman(1)
want := "I"
if got != want {
t.Errorf("got %q, want %q", got, want)
}
}照着本书做下来,你应该会觉得先写测试是一件稀松平常的事情了。
尝试运行测试
./numeral_test.go:6:9: undefined: ConvertToRoman
让编译器指导来指导我们。
编写最少代码以运行测试,并检查失败的测试输出
创建我们的函数但尚未通过测试,始终确保测试失败符合您的预期:
func ConvertToRoman(arabic int) string {
return ""
}运行:
=== RUN TestRomanNumerals
--- FAIL: TestRomanNumerals (0.00s)
numeral_test.go:10: got '', want 'I'
FAIL编写最少的代码以使其通过
func ConvertToRoman(arabic int) string {
return "I"
}重构
目前还没有太多需要重构的地方。
我知道硬编码结果感觉很奇怪,但使用 TDD,我们希望尽可能长时间远离『红色』。虽然我们的代码并没有写很多,但是一件完成了 API 的定义,并写了一条有用的测试。
现在使用这种不安的感觉编写新的测试,以迫使我们编写稍微不那么愚蠢的代码。
先编写测试
我们可以使用子测试很好地对测试进行分组
func TestRomanNumerals(t *testing.T) {
t.Run("1 gets converted to I", func(t *testing.T) {
got := ConvertToRoman(1)
want := "I"
if got != want {
t.Errorf("got %q, want %q", got, want)
}
})
t.Run("2 gets converted to II", func(t *testing.T) {
got := ConvertToRoman(2)
want := "II"
if got != want {
t.Errorf("got %q, want %q", got, want)
}
})
}尝试运行测试
=== RUN TestRomanNumerals/2_gets_converted_to_II
--- FAIL: TestRomanNumerals/2_gets_converted_to_II (0.00s)
numeral_test.go:20: got 'I', want 'II'没有太多惊喜
编写足够的代码以使其通过
func ConvertToRoman(arabic int) string {
if arabic == 2 {
return "II"
}
return "I"
}是的,仍然感觉我们没有解决问题。因此,我们需要编写更多测试以推动我们前进。
重构
我们的测试有些重复。当您测试某种感觉像是“给定输入X,我们期望Y”的问题时,您可能应该使用基于表的测试。
func TestRomanNumerals(t *testing.T) {
cases := []struct {
Description string
Arabic int
Want string
}{
{"1 gets converted to I", 1, "I"},
{"2 gets converted to II", 2, "II"},
}
for _, test := range cases {
t.Run(test.Description, func(t *testing.T) {
got := ConvertToRoman(test.Arabic)
if got != test.Want {
t.Errorf("got %q, want %q", got, test.Want)
}
})
}
}现在,我们可以轻松添加更多的案例,而无需编写更多的测试样板。
让我们朝着 3 继续前进。
先写测试
将以下内容添加到我们的案例中
{"3 gets converted to III", 3, "III"},尝试运行测试
=== RUN TestRomanNumerals/3_gets_converted_to_III
--- FAIL: TestRomanNumerals/3_gets_converted_to_III (0.00s)
numeral_test.go:20: got 'I', want 'III'编写足够的代码以使其通过
func ConvertToRoman(arabic int) string {
if arabic == 3 {
return "III"
}
if arabic == 2 {
return "II"
}
return "I"
}重构
好的,这样我就开始不喜欢这些 if 语句了,我们现在这是根据 arabic 来判断输出,这很傻。
对于更复杂的数字,我们将进行某种算术和字符串连接。
让我们考虑一下这些想法进行重构,它可能不适合最终解决方案,但这没关系。我们总是可以丢掉我们的代码,并从指导我们的测试中重新开始。
func ConvertToRoman(arabic int) string {
var result strings.Builder
for i:=0; i<arabic; i++ {
result.WriteString("I")
}
return result.String()
}您之前可能没有使用过 strings.Builder
Builder 用于使用写入方法高效构建字符串。它最大限度地减少了内存复制。
通常,在遇到实际性能问题之前,我不会费心进行此类优化,但代码量并不比追加到字符串上的『手动』大多少,因此我们可以使用更高效的方法。
DRY 很重要
事情现在开始变得更加复杂。罗马人在他们的智慧中认为重复的字符将变得难以阅读和计数。因此,罗马数字的规则是同一字符不能在一行中重复超过 3 次。
取而代之的是取下一个最高的符号,然后在其左侧放置一个符号来“减去”。并非所有符号都可以用作减法器;只有I(1)、X(10)和C(100)。
例如,罗马数字中的 5 是 V。要创建 4,您不执行 IIII,而是执行IV。
先写测试
{"4 gets converted to IV (can't repeat more than 3 times)", 4, "IV"},尝试运行测试
=== RUN TestRomanNumerals/4_gets_converted_to_IV_(cant_repeat_more_than_3_times)
--- FAIL: TestRomanNumerals/4_gets_converted_to_IV_(cant_repeat_more_than_3_times) (0.00s)
numeral_test.go:24: got 'IIII', want 'IV'编写足够的代码以使其通过
func ConvertToRoman(arabic int) string {
if arabic == 4 {
return "IV"
}
var result strings.Builder
for i:=0; i<arabic; i++ {
result.WriteString("I")
}
return result.String()
}重构
虽然我不喜欢我们硬代码写死的模式,但是只能先继续:
func ConvertToRoman(arabic int) string {
var result strings.Builder
for i := arabic; i > 0; i-- {
if i == 4 {
result.WriteString("IV")
break
}
result.WriteString("I")
}
return result.String()
}
}为了使 4 与我当前的思想“相符”,我现在从阿拉伯数字开始递减,并在我们的字符串中添加符号。不确定从长远来看是否可行,但让我们看看!
接下来是 5
先写测试
{"5 gets converted to V", 5, "V"},尝试运行测试
=== RUN TestRomanNumerals/5_gets_converted_to_V
--- FAIL: TestRomanNumerals/5_gets_converted_to_V (0.00s)
numeral_test.go:25: got 'IIV', want 'V'编写足够的代码以使其通过
只需复制我们为 4 做的方法:
func ConvertToRoman(arabic int) string {
var result strings.Builder
for i := arabic; i > 0; i-- {
if i == 5 {
result.WriteString("V")
break
}
if i == 4 {
result.WriteString("IV")
break
}
result.WriteString("I")
}
return result.String()
}重构
在这样的循环中产生的结果通常是一种待被调用的抽象信号。短路循环是提高可读性的有效工具,但它也可以告诉你其他的信息。
我们在循环我们的阿拉伯数字,如果我们碰到某些符号,我们就叫它 break,但我们 真正 做的是用愚蠢的方式减去 i。
func ConvertToRoman(arabic int) string {
var result strings.Builder
for arabic > 0 {
switch {
case arabic > 4:
result.WriteString("V")
arabic -= 5
case arabic > 3:
result.WriteString("IV")
arabic -= 4
default:
result.WriteString("I")
arabic--
}
}
return result.String()
}-
我们从代码中读出的信息并结合基本的场景测试,可以看出,要构建一个罗马数字,我们需要
arabic自减 -
for循环不再依赖于i,相反,我们将继续构建字符串,直到arabic自减到结束
我很确定这种方法对 6 (VI)、7 (VII) 和 8 (VIII) 也是有效的。尽管如此,也需要将这些用例添加到我们的测试套件中并进行检查(为了简单起见,我将不包括代码,如果您不确定,请查看 github 中的示例)。
9 遵循与 4 相同的规则,即我们应该从下列数字的表示法中减去 I。10 用带 X 的罗马数字表示;因此 9 应该是 IX。
首先编写测试
{"9 gets converted to IX", 9, "IX"}尝试运行测试
=== RUN TestRomanNumerals/9_gets_converted_to_IX
--- FAIL: TestRomanNumerals/9_gets_converted_to_IX (0.00s)
numeral_test.go:29: got 'VIV', want 'IX'编写足够的代码让测试通过
我们可以采用与之前相同的方法
case arabic > 8:
result.WriteString("IX")
arabic -= 9重构
感觉 代码仍在告诉我们某个地方需要重构,但是对我们来说还不是很明显,所以让我们继续往下开发。
我也会跳过此处的代码,但是在你的测试用例中添加一个 10 来测试,他应该返回 X,请在完成此功能后再继续往下阅读。
这是我添加的一些测试,我相信我的代码到数字 39 之前都是可以正常工作的
{"10 gets converted to X", 10, "X"},
{"14 gets converted to XIV", 14, "XIV"},
{"18 gets converted to XVIII", 18, "XVIII"},
{"20 gets converted to XX", 20, "XX"},
{"39 gets converted to XXXIX", 39, "XXXIX"},如果你曾经做过 OO(面向对象)编程,你应该会带着疑问来看待 switch 语句。通常,一些命令式代码中捕获的概念或数据,实际上可以在类结构中进行捕获。
Go 并不是严格意义上的面向对象,但这并不意味着我们完全忽略了面向对象提供的服务(就像有些人告诉你的那样)。
我们的 switch 语句描述了罗马数字以及行为的具体内容。
我们可以通过将数据与行为解耦来重构它。
type RomanNumeral struct {
Value int
Symbol string
}
var RomanNumerals = []RomanNumeral {
{10, "X"},
{9, "IX"},
{5, "V"},
{4, "IV"},
{1, "I"},
}
func ConvertToRoman(arabic int) string {
var result strings.Builder
for _, numeral := range RomanNumerals {
for arabic >= numeral.Value {
result.WriteString(numeral.Symbol)
arabic -= numeral.Value
}
}
return result.String()
}这样感觉好多了。我们已经将数字周围的一些规则声明为数据,而不是隐藏在算法中,我们可以看到我们是如何处理阿拉伯数字的,并尝试将符合条件的符号添加到结果中。
这种抽象适合更大的数字吗? 扩展测试套件,让它适用于罗马数字 50,即 L。
这是一些测试用例,请尝试让它们通过。
{"40 gets converted to XL", 40, "XL"},
{"47 gets converted to XLVII", 47, "XLVII"},
{"49 gets converted to XLIX", 49, "XLIX"},
{"50 gets converted to L", 50, "L"},需要帮助? 你可以在这个要点中看到要添加的符号。
其他内容!
这是其他的符号
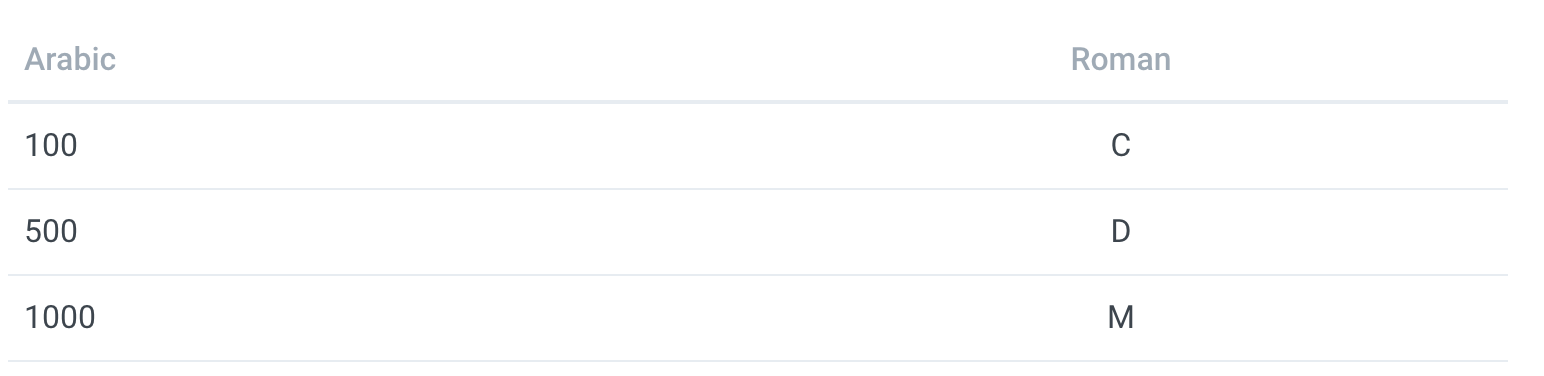
对于其余的符号采用相同的方法,应该只是将数据添加到测试和符号数组中。
你的代码适用于 1984: MCMLXXXIV 吗?
这是我的最终测试套件
func TestRomanNumerals(t *testing.T) {
cases := []struct {
Arabic int
Roman string
}{
{Arabic: 1, Roman: "I"},
{Arabic: 2, Roman: "II"},
{Arabic: 3, Roman: "III"},
{Arabic: 4, Roman: "IV"},
{Arabic: 5, Roman: "V"},
{Arabic: 6, Roman: "VI"},
{Arabic: 7, Roman: "VII"},
{Arabic: 8, Roman: "VIII"},
{Arabic: 9, Roman: "IX"},
{Arabic: 10, Roman: "X"},
{Arabic: 14, Roman: "XIV"},
{Arabic: 18, Roman: "XVIII"},
{Arabic: 20, Roman: "XX"},
{Arabic: 39, Roman: "XXXIX"},
{Arabic: 40, Roman: "XL"},
{Arabic: 47, Roman: "XLVII"},
{Arabic: 49, Roman: "XLIX"},
{Arabic: 50, Roman: "L"},
{Arabic: 100, Roman: "C"},
{Arabic: 90, Roman: "XC"},
{Arabic: 400, Roman: "CD"},
{Arabic: 500, Roman: "D"},
{Arabic: 900, Roman: "CM"},
{Arabic: 1000, Roman: "M"},
{Arabic: 1984, Roman: "MCMLXXXIV"},
{Arabic: 3999, Roman: "MMMCMXCIX"},
{Arabic: 2014, Roman: "MMXIV"},
{Arabic: 1006, Roman: "MVI"},
{Arabic: 798, Roman: "DCCXCVIII"},
}
for _, test := range cases {
t.Run(fmt.Sprintf("%d gets converted to %q", test.Arabic, test.Roman), func(t *testing.T) {
got := ConvertToRoman(test.Arabic)
if got != test.Roman {
t.Errorf("got %q, want %q", got, test.Roman)
}
})
}
}-
我移除了
description,因为我觉得 data 描述了足够的信息。 -
我添加了一些极端的案例,目的是让我们对代码更加有信心。使用基于表的测试,实现它是很容易的。
我没有更改算法,我要做的就是更新 RomanNumerals 数组。
var RomanNumerals = []RomanNumeral{
{1000, "M"},
{900, "CM"},
{500, "D"},
{400, "CD"},
{100, "C"},
{90, "XC"},
{50, "L"},
{40, "XL"},
{10, "X"},
{9, "IX"},
{5, "V"},
{4, "IV"},
{1, "I"},
}解析罗马数字
我们还没有完成。接下来,我们将编写一个将罗马数字转换为 int 的函数。
首先编写测试
我们可以通过一些重构来重用我们的测试用例
将 cases 变量移到测试之外作为 var 块中的包变量。
func TestConvertingToArabic(t *testing.T) {
for _, test := range cases[:1] {
t.Run(fmt.Sprintf("%q gets converted to %d", test.Roman, test.Arabic), func(t *testing.T) {
got := ConvertToArabic(test.Roman)
if got != test.Arabic {
t.Errorf("got %d, want %d", got, test.Arabic)
}
})
}
}注意,我现在使用切片功能只运行一个测试(cases[:1]),因为尝试让这些测试同时通过是一个太大的飞跃。
尝试运行测试
./numeral_test.go:60:11: undefined: ConvertToArabic编写最少的代码让运行测试,并检查失败的测试输出
添加新的函数定义
func ConvertToArabic(roman string) int {
return 0
}现在运行测试应该会失败
--- FAIL: TestConvertingToArabic (0.00s)
--- FAIL: TestConvertingToArabic/'I'_gets_converted_to_1 (0.00s)
numeral_test.go:62: got 0, want 1编写足够的代码让测试通过
你知道应该做什么
func ConvertToArabic(roman string) int {
return 1
}接下来,在我们的测试中更改切片索引以移动到下一个测试用例(例如, cases[:2])。用你所能想到的最愚蠢的代码,继续为第三种情况编写愚蠢的代码(有史以来最好的书,对吗?)这是我的愚蠢的代码。
func ConvertToArabic(roman string) int {
if roman == "III" {
return 3
}
if roman == "II" {
return 2
}
return 1
}通过运行的实际代码 的愚蠢性,我们可以开始看到与以前类似的模式。我们需要遍历输入并构建 一些东西,在本例中为 total。
func ConvertToArabic(roman string) int {
total := 0
for range roman {
total++
}
return total
}首先编写测试
接下来我们转到 cases[:4] (IV),该操作现在失败了,它返回了 2,因为这是字符串的长度。
编写足够的代码让测试通过
// 早些时候...
type RomanNumerals []RomanNumeral
func (r RomanNumerals) ValueOf(symbol string) int {
for _, s := range r {
if s.Symbol == symbol {
return s.Value
}
}
return 0
}
// 稍后..
func ConvertToArabic(roman string) int {
total := 0
for i := 0; i < len(roman); i++ {
symbol := roman[i]
// 如果可以的话,向前看下一个符号,当前的符号是以 10 为基数的 (仅有效的减法器)
if i+1 < len(roman) && symbol == 'I' {
nextSymbol := roman[i+1]
// 构建两个字符串
potentialNumber := string([]byte{symbol, nextSymbol})
// 获取两个字符串的值
value := romanNumerals.ValueOf(potentialNumber)
if value != 0 {
total += value
i++ // 在下一个循环中也跳过这个字符
} else {
total++
}
} else {
total++
}
}
return total
}这么做很可怕,但确实有效。太糟糕了,我觉得有必要添加评论。
-
我希望能够查找给定罗马数字的整数值,因此我从我们
RomanNumeral的数组中创建一个类型,然后向其中添加一个方法,即ValueOf。 -
接下来,在循环中,我们需要向前看,如果 字符串足够大并且 单前符号是有效的减法器。 目前它只是
I(1) ,但也可以是X(10) 或C(100)。-
如果它同时满足这两个条件,且它是特殊的减法器,则需要查找该值并将其加到 total 中,否则忽略它。
-
然后我们需要进一步增加
i,这样我们就不会把这个符号数两次了。
-
重构
我并不相信这是长久的方法,而且我们也会做一些有趣的重构。但我不会这么做,以防我们的方法完全错了。我宁愿让更多的测试先通过,然后看看结果如何。与此同时,我让第一个 if 语法不那么可怕了。
func ConvertToArabic(roman string) int {
total := 0
for i := 0; i < len(roman); i++ {
symbol := roman[i]
if couldBeSubtractive(i, symbol, roman) {
nextSymbol := roman[i+1]
// 构建两个字符串
potentialNumber := string([]byte{symbol, nextSymbol})
// 获取两个字符串的值
value := romanNumerals.ValueOf(potentialNumber)
if value != 0 {
total += value
i++ // 在下一个循环中也跳过这个字符
} else {
total++
}
} else {
total++
}
}
return total
}
func couldBeSubtractive(index int, currentSymbol uint8, roman string) bool {
return index+1 < len(roman) && currentSymbol == 'I'
}首先编写测试
让我们继续进行 cases[:5]
=== RUN TestConvertingToArabic/'V'_gets_converted_to_5
--- FAIL: TestConvertingToArabic/'V'_gets_converted_to_5 (0.00s)
numeral_test.go:62: got 1, want 5编写足够的代码让测试通过
除了进行减法运算外,我们的代码还假定每个字符都是 I,这就是为什么值是 1的原因。我们应该能够重用我们的 ValueOf 方法来解决这个问题。
func ConvertToArabic(roman string) int {
total := 0
for i := 0; i < len(roman); i++ {
symbol := roman[i]
// 如果可以,请向前看下一个符号,当前符号以 10 为基数(仅有效的减法器)
if couldBeSubtractive(i, symbol, roman) {
nextSymbol := roman[i+1]
// 构建两个字符串
potentialNumber := string([]byte{symbol, nextSymbol})
if value := romanNumerals.ValueOf(potentialNumber); value != 0 {
total += value
i++ // 在下一个循环中也跳过这个字符
} else {
total++ // 这是可疑的...
}
} else {
total+=romanNumerals.ValueOf(string([]byte{symbol}))
}
}
return total
}重构
当你在 Go 中索引字符串时,你会得到一个 byte。这就是为什么当我们再次建立字符串时,我们必须做像 string([]byte{symbol}) 这样的事情。它重复了几次,让我们移动一下这个功能,以此让 ValueOf 占用一些字节。
func (r RomanNumerals) ValueOf(symbols ...byte) int {
symbol := string(symbols)
for _, s := range r {
if s.Symbol == symbol {
return s.Value
}
}
return 0
}然后我们可以直接将字节传递给我们的函数
func ConvertToArabic(roman string) int {
total := 0
for i := 0; i < len(roman); i++ {
symbol := roman[i]
if couldBeSubtractive(i, symbol, roman) {
if value := romanNumerals.ValueOf(symbol, roman[i+1]); value != 0 {
total += value
i++ // 在下一个循环中也跳过这个字符
} else {
total++ // this is fishy...
}
} else {
total+=romanNumerals.ValueOf(symbol)
}
}
return total
}情况仍然很糟糕,但情况正在恶化。
如果你开始移动我们的 cases[:xx] 数字,你会发现现在有很多在传递。完全删除切片操作符并查看哪些操作符失败,下面是我的套件中的一些示例
=== RUN TestConvertingToArabic/'XL'_gets_converted_to_40
--- FAIL: TestConvertingToArabic/'XL'_gets_converted_to_40 (0.00s)
numeral_test.go:62: got 60, want 40
=== RUN TestConvertingToArabic/'XLVII'_gets_converted_to_47
--- FAIL: TestConvertingToArabic/'XLVII'_gets_converted_to_47 (0.00s)
numeral_test.go:62: got 67, want 47
=== RUN TestConvertingToArabic/'XLIX'_gets_converted_to_49
--- FAIL: TestConvertingToArabic/'XLIX'_gets_converted_to_49 (0.00s)
numeral_test.go:62: got 69, want 49我认为我们所缺少的是 couldBeSubtractive 的更新,这样它就可以解释其他类型的减法符号了。
func couldBeSubtractive(index int, currentSymbol uint8, roman string) bool {
isSubtractiveSymbol := currentSymbol == 'I' || currentSymbol == 'X' || currentSymbol =='C'
return index+1 < len(roman) && isSubtractiveSymbol
}再试一次,上面的测试还是失败了。但是我们之前留下了注释…
total++ // 这是可疑的...我们不应该只是增加 total,因为这意味着每个符号都是 I。替换为:
total += romanNumerals.ValueOf(symbol)所有的测试都通过了!现在我们已经有了可以工作的软件,我们可以满怀信心地进行一些重构。
重构
这是我完成的所有代码。我有过几次失败的尝试,但正如我一直强调的那样,这没有问题,测试会帮助我们自由地处理代码。
import "strings"
func ConvertToArabic(roman string) (total int) {
for _, symbols := range windowedRoman(roman).Symbols() {
total += allRomanNumerals.ValueOf(symbols...)
}
return
}
func ConvertToRoman(arabic int) string {
var result strings.Builder
for _, numeral := range allRomanNumerals {
for arabic >= numeral.Value {
result.WriteString(numeral.Symbol)
arabic -= numeral.Value
}
}
return result.String()
}
type romanNumeral struct {
Value int
Symbol string
}
type romanNumerals []romanNumeral
func (r romanNumerals) ValueOf(symbols ...byte) int {
symbol := string(symbols)
for _, s := range r {
if s.Symbol == symbol {
return s.Value
}
}
return 0
}
func (r romanNumerals) Exists(symbols ...byte) bool {
symbol := string(symbols)
for _, s := range r {
if s.Symbol == symbol {
return true
}
}
return false
}
var allRomanNumerals = romanNumerals{
{1000, "M"},
{900, "CM"},
{500, "D"},
{400, "CD"},
{100, "C"},
{90, "XC"},
{50, "L"},
{40, "XL"},
{10, "X"},
{9, "IX"},
{5, "V"},
{4, "IV"},
{1, "I"},
}
type windowedRoman string
func (w windowedRoman) Symbols() (symbols [][]byte) {
for i := 0; i < len(w); i++ {
symbol := w[i]
notAtEnd := i+1 < len(w)
if notAtEnd && isSubtractive(symbol) && allRomanNumerals.Exists(symbol, w[i+1]) {
symbols = append(symbols, []byte{byte(symbol), byte(w[i+1])})
i++
} else {
symbols = append(symbols, []byte{byte(symbol)})
}
}
return
}
func isSubtractive(symbol uint8) bool {
return symbol == 'I' || symbol == 'X' || symbol == 'C'
}前面代码的主要问题与我们前面重构的问题相似。我们有太多的代码耦合在一起。我们写了一个算法,试图从字符串中提取罗马数字,并 找到它们的值。
因此,我创建了一个新的类型 windowedRoman,它负责提取数字,并提供一个 Symbols 方法来将它们作为一个切片检索。这意味着我们的 ConvertToArabic 函数可以简单地遍历这些符号并将它们加起来。
我通过提取一些函数来对代码进行细分,特别是围绕着不靠谱的 if 语句来确定我们当前处理的符号是否是两个字符的减法符号。
可能有一种更优雅的方法,但我不打算花大力气。代码就在那里,它可以工作,并且经过测试。如果我(或其他任何人)找到一个更好的方法,他们可以安全地改变它——艰苦的工作已经完成了。
介绍基于属性的测试
在罗马数字的领域里有一些规则,我们在这一章已经学过了
-
不能有超过 3 个连续的符号
-
只有 I (1), X (10) 和 C (100) 是 「减法器」
-
将
ConvertToRoman(N)的结果传递给ConvertToArabic,应该返回N。
到目前为止,我们编写的测试可以被描述为基于「示例」的测试,在这些测试中,我们围绕我们的代码提供了一些用于验证的工具示例。
如果我们可以使用我们了解的有关领域的规则,并以某种方式对我们的代码进行运用,结果会怎样呢?
基于属性的测试通过向代码中抛出随机数据并验证所描述的规则始终为真来帮助您做到这一点。很多人认为基于属性的测试主要是关于随机数据的,但他们是错误的。 基于属性的测试面临的真正挑战是你对你的领域有「很好的」理解,这样您就可以编写这些属性。
话不多说了,让我们看代码
func TestPropertiesOfConversion(t *testing.T) {
assertion := func(arabic int) bool {
roman := ConvertToRoman(arabic)
fromRoman := ConvertToArabic(roman)
return fromRoman == arabic
}
if err := quick.Check(assertion, nil); err != nil {
t.Error("failed checks", err)
}
}属性的基本原理
我们的第一个测试将检查是否将数字转换为罗马数字,然后使用其他函数将其转换回我们最初拥有的数字。
-
给定随机数 (例如
4)。 -
用随机数调用
ConvertToRoman(如果是4,则应返回IV)。 -
将上面的结果传递给
ConvertToArabic。 -
以上是我们的原始输入 (
4)。
这似乎是建立我们信心的良好测试,因为如果其中任何一个存在错误,它都将被破坏。唯一可以通过的方法是它们有相同的 bug;这种情况不是不可能存在,但基本上不太可能。
技术解释
我们正在使用标准库中的 testing/quick 包
从底部读取,我们为 quick.Check 提供了一个函数,它将运行一些随机的输入,如果函数返回 false,它将被视为检查失败。
上面的 assertion 函数接受随机数并运行函数来测试属性。
运行测试
尝试运行它;你的电脑可能会挂一段时间,所以当你无聊的时候就杀了它 :)
这是怎么回事?尝试在断言代码中添加以下内容。
assertion := func(arabic int) bool {
if arabic <0 || arabic > 3999 {
log.Println(arabic)
return true
}
roman := ConvertToRoman(arabic)
fromRoman := ConvertToArabic(roman)
return fromRoman == arabic
}你应该会看到这些:
=== RUN TestPropertiesOfConversion
2019/07/09 14:41:27 6849766357708982977
2019/07/09 14:41:27 -7028152357875163913
2019/07/09 14:41:27 -6752532134903680693
2019/07/09 14:41:27 4051793897228170080
2019/07/09 14:41:27 -1111868396280600429
2019/07/09 14:41:27 8851967058300421387
2019/07/09 14:41:27 562755830018219185仅仅运行这个非常简单的属性就暴露了我们实现中的一个缺陷。我们使用 int 作为输入,但是:
-
你不能用罗马数字表示负数
-
根据我们最多 3 个连续符号的规则,我们不能表示大于 3999 的值(罗马数字的最大值),而
int的最大值比 3999 大得多。
这很棒!我们被迫更深入地思考我们的领域,这是基于属性测试的真正优势。
显然 int 不是一个很好的类型。如果我们尝试一些更合适的方法呢?
uint16
Go 具有 无符号整数 的类型,这意味着它们不能为负数;这样就可以立即排除我们代码中的一类错误。通过添加 16,这意味着它是一个 16 位的整数,它可以存储最大 65535,这仍然太大了,但使我们更接近我们的需要。
尝试更新代码,使用 uint16 而不是 int。我在测试中更新了 assertion 以提供更多的可见性。
assertion := func(arabic uint16) bool {
if arabic > 3999 {
return true
}
t.Log("testing", arabic)
roman := ConvertToRoman(arabic)
fromRoman := ConvertToArabic(roman)
return fromRoman == arabic
}如果你运行测试,现在他可以运行了,你可以看到正在测试的内容。你可以运行多次,来查看我们的代码是否可以处理任何值!这可以是我们对代码的稳定性充满信心。
默认运行 quick.Check 的次数是100,但是你可以通过配置更改它。
if err := quick.Check(assertion, &quick.Config{
MaxCount:1000,
}); err != nil {
t.Error("failed checks", err)
}更进一步的工作
-
你能编写属性测试来检查我们描述的其他属性吗?
-
你能想出一个办法让别人不可能用大于3999的数字来调用我们的代码吗?
-
你可以返回一个 error
-
或者创建一个无法表达 大于 3999 的数字的类型
- 你觉得你的写法好在哪里。
-
总结
更多的 TDD 实践与迭代开发
一开始,你是不是觉通过代码把 1984 年转换成 MCMLXXXIV 有点吓人?对于从事软件开发很长时间的我也是一样的。
与往常一样,诀窍就是从简单的事情开始,一步一步来。
在这个过程中,我们从来没有做过大的飞跃,也没有做过大的重构,或者陷入混乱。
我能听到有人冷嘲热讽地说:「这只是一个 kata。」我不能否认这一点,但我仍然对我参与的每个项目采取相同的方法。在我的第一步中,我从未发布过一个大型的分布式系统,我发现团队可以发布的最简单的东西(通常是一个「Hello world」网站),然后在可管理的块中迭代小的功能,就像我们在这里所做的一样。
技巧就是知道 如何 划分工作,这需要不断的练习和 TDD 来帮助你。
基于属性的测试
-
内置于标准库中
-
如果您能想出用代码描述领域规则的方法,它们将是增强您信心的极好工具
-
强迫您深入考虑自己的领域
-
是你测试套件不错的补充
附言
这本书依赖于来自社区的宝贵反馈。Dave 几乎每一章都提供了巨大的帮助。但他对我在这一章中使用「阿拉伯数字」表示了不满,所以,为了全面披露,他是这么说的。
只是要写为什么类型
int的值不是真正的「阿拉伯数字」。这可能是我太精确了,所以如果你叫我滚蛋,我完全能理解。digit 是用来表示数字的字符,在拉丁语中是「手指」的意思,因为我们通常有十个手指。在阿拉伯语(也称为印度教-阿拉伯语)数字系统中,有 10 个。这些阿拉伯数字是:
0 1 2 3 4 5 6 7 8 9数字 是使用一组数字表示的集合。阿拉伯数字是在基数为 10 的位置数字系统中由阿拉伯数字表示的数字。我们说的「位置」是因为每个数字在数字中的位置不同,其值也不同。所以
1337
1的值是 1000,因为它是四位数字中的第一个数字。罗马字是用较少的数字(
I,V等…)作为产生数字的值。有一些位置的东西,但I始终代表 「1」。那么,鉴于此,
int是「阿拉伯数字」吗?一个数的概念与它的表示完全没有关系——如果我们问自己这个数的正确表示是什么,我们就能明白这一点:255 11111111 two-hundred and fifty-five FF 377是的,这是一个很难解释的问题。他们都是正确的。它们分别在十进制、二进制、英语、十六进制和八进制中表示相同的数字。
数字作为数字的表示是 独立于 其作为数字的属性的——当我们在 Go 中查看整数时可以看到:
0xFF == 255 // true以及如何在格式字符串中打印整数:
n := 255 fmt.Printf("%b %c %d %o %q %x %X %U", n, n, n, n, n, n, n, n) // 11111111 ÿ 255 377 'ÿ' ff FF U+00FF我们可以把同一个整数写成十六进制和阿拉伯(十进制)数字。
因此,当函数签名看起来像
ConvertToRoman(arabic int) string时,它就对其调用方式做了一些假设。因为有时arabic被写为十进制整数。ConvertToRoman(255)但它也可以写成
ConvertToRoman(0xFF)实际上,我们根本不是在「转换」阿拉伯数字,我们是在「打印」——表示——一个
int作为一个罗马数字——而int不是数字,阿拉伯语或其他;他们只是数字。ConvertToRoman函数更像strconv.Itoa,因为它将int转换为string。但其他版本的 kata 不在乎这种区别
原文地址 Learn Go with Tests
本译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。










 关于 LearnKu
关于 LearnKu




推荐文章: