
 sed & awk (2nd edition)
sed & awk (2nd edition)4.11. 字符介绍——字符类——POSIX 增加的字符类
4.11 字符介绍——字符类——POSIX 增加的字符类
POSIX 标准规范了正则表达式字符和操作符的含义。这个标准定义了两类正则表达式:被 grep 和 sed 使用的基本正则表达式(BREs),被 egrep 和 awk 使用的扩展正则表达式。
为了适应非英语环境, POSIX 标准增强了字符类匹配非英文字母的能力,比如法语 è 是一个字母字符,但一个典型的字符类 [a-z] 将不会匹配它。另外,当匹配和排序(collating)字符串数据时,标准提供了应该被当做一个单独单元的字符序列。
POSIX 还改变了之前一直有的术语。我们一直叫做“字符类”的东西,在 POSIX 标准里被称作“方括号[] 表达式”。在方括号[] 表达式中,除了字面量字符,比如 a,!等等,还可以有额外的组件。它们是:
- 字符类。POSIX 字符类由被
[:和:]括起来的关键词组成。这些关键词描述了不同的字符类,如字母字符、控制类字符等等(见表 3-3) - 排序符号。一个排序符号是应该被当做一个单元的多字符序列,它由被 [. 和 .] 括起来的字符组成。
- 等效类。一个等效类,列出了应该被认为是相等的一套字符,比如 e 和 è。它由来自区域设置的一个命名元素组成,被 [= 和 =] 括起来。
所有这三个结构都必须出现在方括号[] 表达式的方括号[] 里面。比如,[[ :alpha:]!] 就匹配了任意单个字母字符或者感叹号,[[.ch.]] 就匹配排序元素 ch[^1],但是不匹配单独的字母 “c” 或 h。在法语的区域设置里面,[[=e=]] 可能匹配 e,è 或 é 中的任何一个。字符类和匹配字符见表3-3。
| 类 | 匹配字符 |
|---|---|
| [:alnum:] | 数字和字母字符(包含空格,不包括标点符号或其它符号) |
| [:alpha:] | 字母字符 |
| [:blank:] | 空格和Tab字符 |
| [:cntrl:] | 控制字符 |
| [:digit:] | 数字字符 |
| [:graph:] | 可打印且可见(非空格)字符 |
| [:lower:] | 小写字符 |
| [:print:] | 可打印字符(包含空格) |
| [:punct:] | 标点符号 |
| [:space:] | 空格字符 |
| [:upper:] | 大写字符 |
| [:xdigit:] | 16进制数字 |
测试如下:
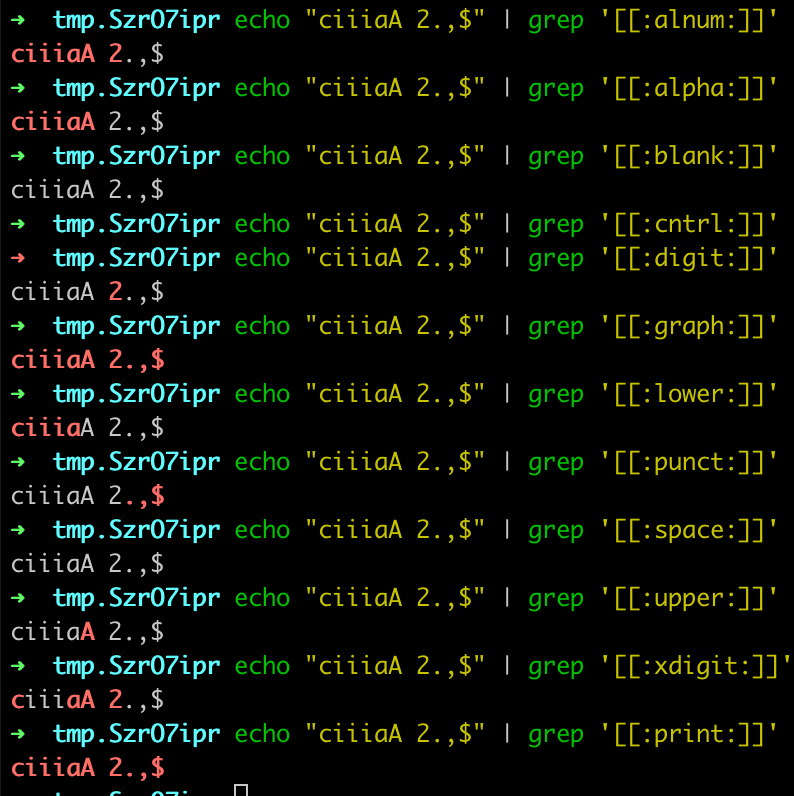
随着供应商完全地实现 POSIX 标准,这些特性都慢慢地进入商业版本的 sed 和 awk。GNU 的 awk 和 GNU 的 sed 支持字符类标记,但是不支持其它两种方括号[] 的标记。检查你本地的系统文档,看它们是否可用。
因为这些特征用得不是很广泛,所以本书中的脚本将不会依赖于它们。我们将继续使用术语“字符类”来指代方括号[] 里面的字符列表。
脚注
脚注1
注意:如果这个 ch 不是当前排序序列定义中的排序元素,或者这个排序元素没有跟它对应的字符。那么这个 ch 就会被认为是一个无效的表达式,如下:
➜ tmp.SzrO7ipr echo "ciiiaA 2.," | grep '[[.ch.]]'
grep: invalid collating elementIf the string is not a collating element in the current collating sequence definition, or if the collating element has no characters associated with it (for example, see the symbol in the example collation definition shown in Collation Order ), the symbol will be treated as an invalid expression.
关于何时才会有这样的元素,可以参考这里。



 关于 LearnKu
关于 LearnKu




推荐文章: