
 sed & awk (2nd edition)
sed & awk (2nd edition)4.18. 字符介绍——是什么单词?第二部分
4.18 字符介绍——是什么单词?第二部分
让我们根据已经讨论的新的元字符来重新评估查找一个单词的正则表达式。
首先我们尝试为 grep 写一个正则表达式来搜索以下面表达式结尾的单词:
□book.*□这个表达式相当简单,它匹配一个空格,接着字符串 “book” 再接着是任意数量的字符,再跟一个空格。然而它不能匹配所有可能的情况,并且它确实匹配了一些讨厌的单词。
下面这个测试文件包含了多次出现的 “book”。我们添加了一个标记,它不是这个文件的一部分,只是为了显示是否这个输入行应该是一次 “命中”(>)并且包括在输出中,或者是一次 “错失”(<)。我们已经努力包括了尽可能多的不同的例子。
$ cat bookwords结果(文件内容+标记):
> This file tests for book in various places, such as
> book at the beginning of a line or
> at the end of a line book
> as well as the plural books and
< handbooks. Here are some
< phrases that use the word in different ways:
> "book of the year award"
> to look for a line with the word "book"
> A GREAT book!
> A great book? No.
> told them about (the books) until it
> Here are the books that you requested
> Yes, it is a good book for children
> amazing that it was called a "harmful book" when
> once you get to the end of the book, you can’t believe
< A well-written regular expression should
< avoid matching unrelated words,
< such as booky (is that a word?)
< and bookish and
< bookworm and so on.当我们搜索单词 “book” 的出现时,应该有 13 行被匹配,有 7 行不应该被匹配。首先让我们对样本文件运行之前的那个正则表达式。然后检查结果:
➜ ch03 git:(daily) ✗ grep ' book.* ' bookwords
This file tests for book in various places, such as
as well as the plural books and
A great book? No.
told them about (the books) until it
Here are the books that you requested
Yes, it is a good book for children
amazing that it was called a "harmful book" when
once you get to the end of the book, you can't believe
such as booky (is that a word?)
and bookish and它只打印了我们要匹配的 13 行中的 8 行,并且它打印了我们不想匹配的行中的两行。
这个表达式匹配了包含单词 “booky” 和 “bookish” 的行。它忽略了 “book” 在行首或行尾的情况。当涉及特定的标点符号时,它也忽略了 “book”。
为了将这个搜索限制得更严一点,我们必须使用字符类。通常单词末尾的字符列表都是标点符号,如:
? . , ! ; : ’另外,引号,小括号() 、大括号{} ,方括号[] 可能围绕一个单词或以一个单词开头或结尾。
" () {} []你还得适应单词的复数和所有格形式。
因此你将有两个不同的字符类:在单词之前的和之后的。记住,所有我们需要做的是在方括号[] 里面列出类的成员。在单词前面,我们现在有:
["[{(]然后在单词后面:
[]})"?!.,;:’s]注意把结尾的方括号[] 作为类中的第一个字符,使得它是类的一个成员而不是关闭这个集合。把两个类放一起,我们得到了这个表达式:
□["[{(]*book[]})"?!.,;:’s]*□把这个给外行看,它们会举手投降。但是既然你知道了设计的原理,你就不仅能理解这个表达式,还能轻松地重构它。让我们看一下它是怎样作用于样本文件的(我们使用双引号来包裹单引号字符,然后在嵌套的双引号前面加一个反斜杠):
➜ ch03 git:(daily) ✗ grep " [\"[{(]*book[]})\"?\!.,;:'s]* " bookwords
This file tests for book in various places, such as
as well as the plural books and
A great book? No.
told them about (the books) until it
Here are the books that you requested
Yes, it is a good book for children
amazing that it was called a "harmful book" when
once you get to the end of the book, you can't believe注意:
!要进行转义。
我们消除了不想匹配的那些行,但是有四行我们没有得到。让我们看一下这四行:
book at the beginning of a line or
at the end of a line book
"book of the year award"
A GREAT book!所有这些问题都是由出现在行首和行尾的字符串引起的。因为在行首和行尾没有空格,这个模式就不会被匹配。我们可以使用定位元字符—— ^ 和 $。因为我们想匹配行首和行尾的一个空格。我们可以使用 egrep 并且指定 “或” 这个元字符和小括号() 来分组。比如要匹配行首或一个空格,你可以写这个表达式:
(^| )因为竖线(|) 和小括号() 是扩展元字符集的一部分,如果你在使用 sed 你将必须写不同的表达式来处理每一种情况。)
这里是修改后的正则表达式:
(ˆ| )["[{(]*book[]})"?\!.,;:’s]*( |$)让我们看一下它是如何工作的:
➜ ch03 git:(daily) ✗ egrep "(^| )[\"[{(]*book[]})\"?\!.,;:'s]*( |$)" bookwords
This file tests for book in various places, such as
book at the beginning of a line or
at the end of a line book
as well as the plural books and
"book of the year award"
to look for a line with the word "book"
A GREAT book!
A great book? No.
told them about (the books) until it
Here are the books that you requested
Yes, it is a good book for children
amazing that it was called a "harmful book" when
once you get to the end of the book, you can't believe这肯定是一个复杂的正则表达式,然而它可以被分解成几部分。这个正则表达式可能不会匹配每一种情况,但是它可以很容易的被改动去处理你可能遇到的其它情况。
你还可以创建一个简单的 shell 脚本,来用一个命令行参数替代 “book”。唯一的问题可能是有些单词的复数不是简单的 “s”。你可以巧妙地通过添加 “e” 到单词后的字符类中来处理 “es” 复数;它将在很多情况下都可用。
进一步说明,ex 和 vi 文本编辑器有用于匹配单词开头的字符串的特殊元字符 \<,也有用于匹配单词结尾的字符串的特殊元字符 \>。成对使用,它们就可以匹配一个仅当它是一个完整单词时的字符串。(对这些操作符,一个单词是一个没有空格的字符串,两边有空格,或者在行首或行尾。)匹配一个单词是很常见的,以至于如果这些元字符在所有的正则表达式中都可用,那么它们将肯定会被广泛地使用。
GNU 程序,比如 GNU 版本的 awk sed grep 都支持
\<和\>。
在 vi 中 按 / 进入搜索模式,输入:
\<["[{(]*book[]})"?\!.,;:’s]*\>这样是一次匹配一个,按 n 移动到下一个匹配。如果要一次性显示所有匹配,输入:
:g/\<["[{(]*book[]})"?\!.,;:’s]*\>/p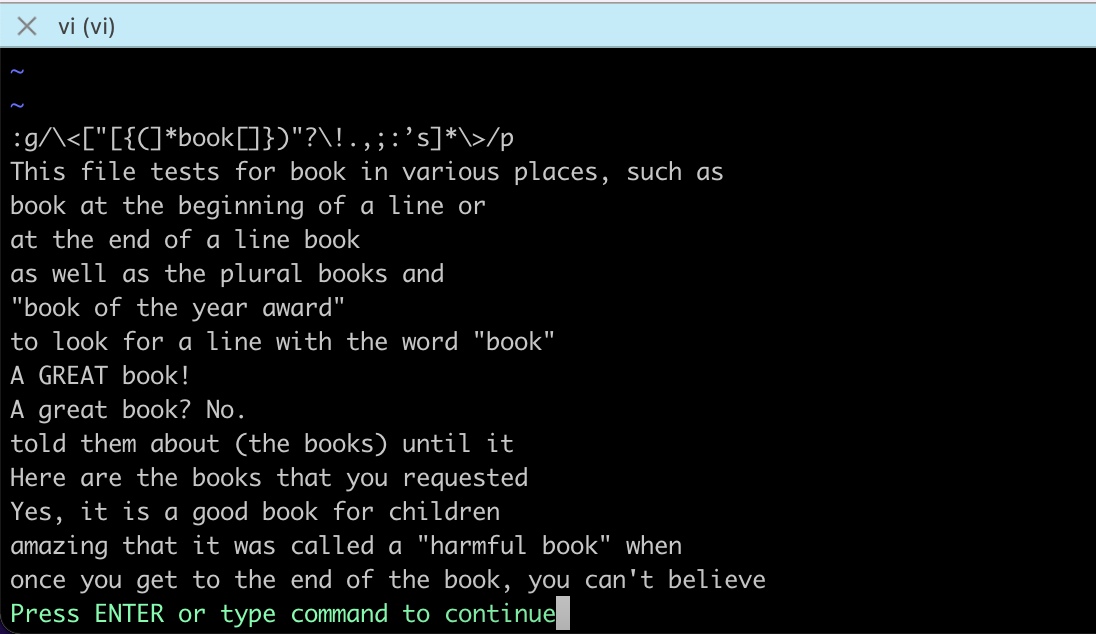
更详细的搜索匹配,可以参考我的博文 在 vi 中一次性显示出所有搜索的匹配 | 开发者工具论坛
另外,在使用 gsed 时, \< 和 \> 还可以用 \b 来代替,书写更方便。
\b["[{(]*book[]})"?\!.,;:’s]*\b



 关于 LearnKu
关于 LearnKu



