
 sed & awk (2nd edition)
sed & awk (2nd edition)5.3. 在脚本中应用命令——模式空间
5.3 在脚本中应用命令——模式空间
Sed 维护了一个模式空间(一个工作空间或临时暂存区),当应用编辑命令时,输入的一行被保存在那里。
一次一行的设计的优点是 sed 可以毫无问题的读取非常大的文件,不得不将整个文件或非常大的部分读入内存的屏幕编辑器会耗尽内存耗尽,或者处理大文件时非常缓慢。
通过两行脚本对模式空间进行转换如图 4-1 所示。
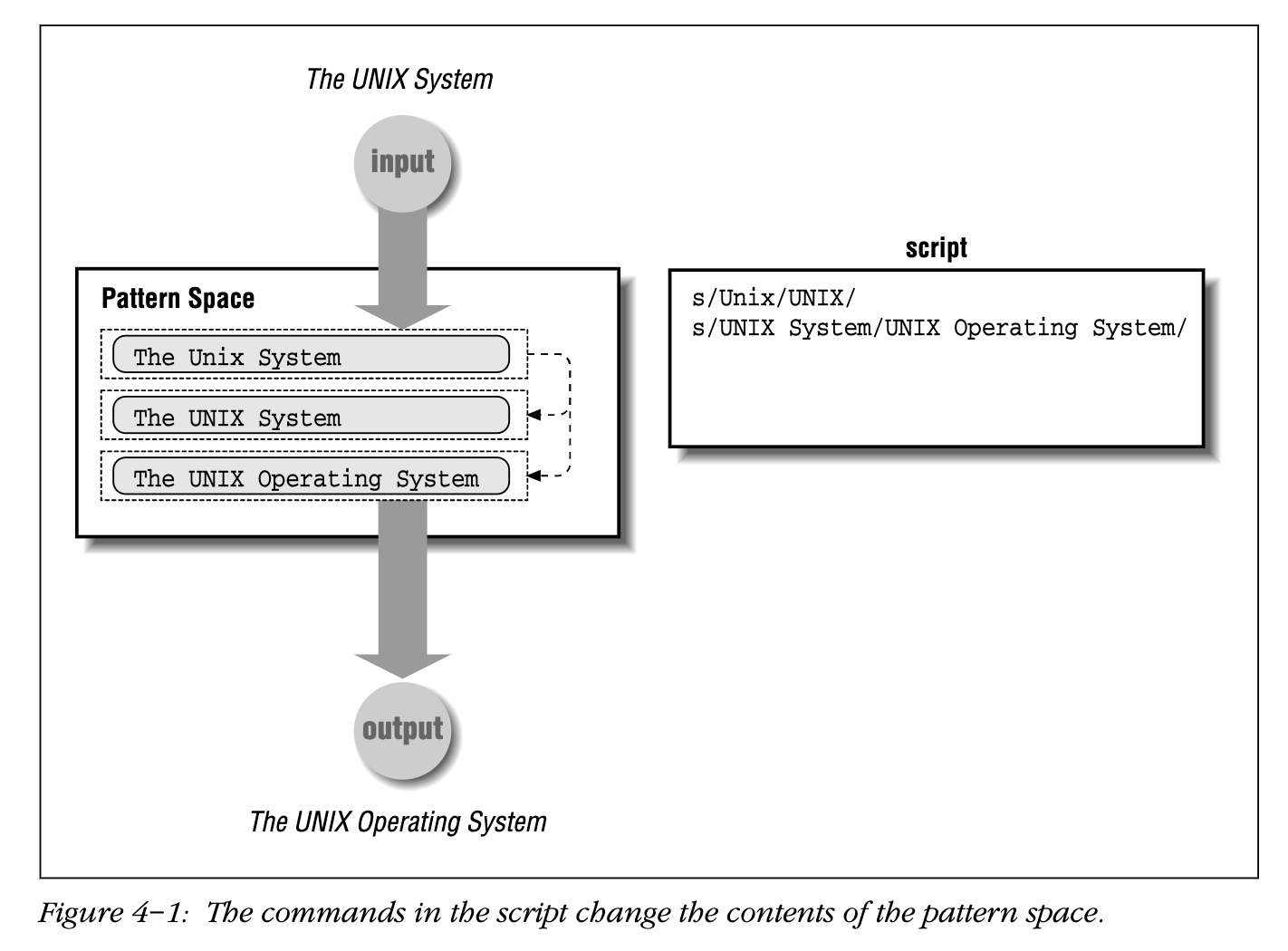
它将 “The Unix System” 改为 “The UNIX Operating System”。
一开始,这个模式空间包括了一个输入行的拷贝。在图 4-1 里面,这一行是 “The Unix System” 。脚本的正常流程是对那一行执行每一个命令,直到脚本的末尾。脚本的第一个命令被应用在那一行上,将 “Unix” 改变为大写的 “UNIX”。接着应用第二个命令将 “UNIX System” 改变为 “UNIX Operating System”。注意,第二个替换命令的模式不匹配原始输入行,它匹配的是在模式空间中已经改变的当前行。
是的,我们可以将 “UNIX System” 直接一步改为 “UNIX Operating System”。然而输入文件里面可能会有大写的 “UNIX System” 和小写的 “Unix system”,所以通过改变小写的 “UNIX” 到大写的 “UNIX” 我们在将它们改变成 “UNIX Operating System” 之前,使得两种情况一致。
当所有的指令都被应用后,当前行被输出,然后输入的下一行被读入模式空间,然后在脚本中的所有命令都应用在那一行上。
因此,任何 sed 命令都可能改变下一个命令的模式空间的内容。模式空间的内容是动态的,并且并不总是匹配原来的输入行,这就是本章开始那个简单脚本的问题所在。第一个命令将按照我们想要的 “pig” 改为 “cow” 然而当第二个命令将在同一行上的 “cow” 再改为 “horse”(它将原来是 “pig” 的 “cow” 改为 “horse”)。所以在一个包含 “pig” 和 “cow” 的输入文件中,最后的输出文件只有 “horse”!
这个错误仅仅是脚本中命令次序的一个问题。将命令的顺序调换一下(在改变 “pig” 为 “cow” 之前,将 “cow” 改为 “horse” 就可以了。
s/cow/horse/g
s/pig/cow/g我们在随后的章节中将看到有些 sed 命令会改变脚本的流程。
比如大写的 n 命令,在不移除当前行的情况下,从模式空间中读取另一行,所以你可以在多行上测试模式。其它的命令在到达一个脚本的底部之前就告诉 sed 退出或到一个标记好的命令。 sed 还维护一个名为 hold space 的第二临时缓冲区。你可以将模式空间的内容拷贝到 hold space 并随后提取它们。使用 hold space 的命令将在第六章中被讨论。






 关于 LearnKu
关于 LearnKu




推荐文章: