
数据量大的情况下 Laravel 获取分页查询时很慢,有什么优化方案?

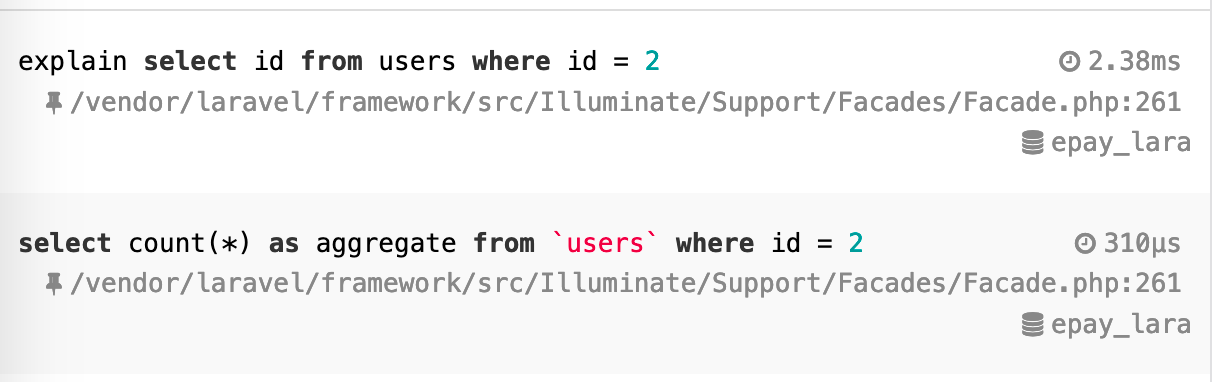
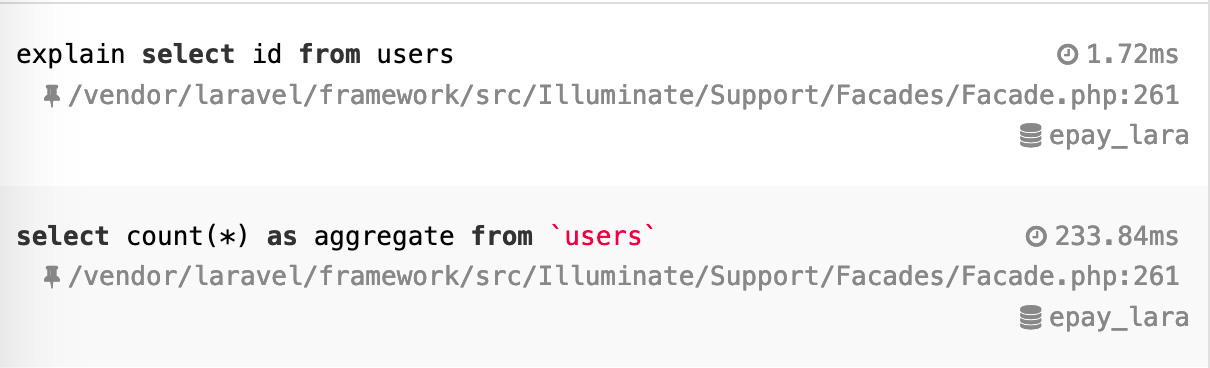
上面第一条 SQL 是 laravel 分页时用来获取数据总数的,第二条是获取当前页数据的。
第一条竟然要三百多毫秒,第二条1毫秒都不用。users 数据表有200万行数据,这种情况有什么解决方案没,大家是如何优化的


































 关于 LearnKu
关于 LearnKu




推荐文章: