
如何处理一亿条数据请求api, 求一个思路或者流程?
项目想实现的效果是这样的
1.)前端提交一个txt文件, 文件内有一亿条数据,一行一条数据
2.)后端接受txt文件,取出一条数据,拼接api, 生成新的url链接
3.)后端curl发起请求,获取返回数据,保存数据
4.)前端此时,可以实时显示一亿条数据跑了多少条了
项目现状
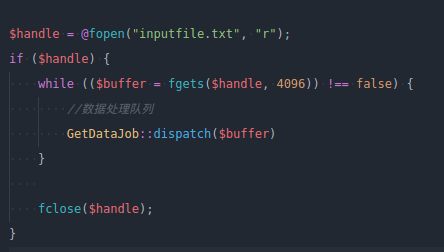
前端用js模拟多线程,不停的向后端发起请求,后端laravel不停的接收数据并返回数据
效果并不理想,速度特别慢,前端页面还会卡死不动!
求
1.)希望一亿条数据在后端循环处理,目前是前端发起一亿次请求,后端只是处理一条数据,相当于一亿条数据在前端处理
2.)前端显示实时跑到了第几条数据!
3.)希望速度快一些,最好一天跑完!提供最快的方式就行!
4.)求这个的解题思路,要用到laravel的那些插件框架或者技术名词?
5.)是否用Guzzle合适?


























 关于 LearnKu
关于 LearnKu




推荐文章: