





讨论数量:

给个参考:
User::whereRaw('left(`created_at`, 10)>="2017-10-13"')->get()
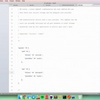
有更好的方法,我看了作者的视频的,但是忘了怎么写的,我晚点告诉你。

如果数据量大,实时统计是很难的,通常是每天凌晨去跑一下数据存起来,然后查的时候就直接查结果就行了

2017-11-16 14:24:37 是 datetime 类型,2017-11-16 是 date 类型,这两个类型指的是 MySQL 数据类型。这两个类型中,均可以使用 > 和 < 进行筛选,即:Article::where('created_at', '>', '2017-11-16 14:26:33')->get() 甚至直接拿 date 类型的数据去 datetime 字段筛选,都是支持的。
@johnlui 恩 了解,现在问题是,数据量大,用这种where('created_at', '>', '2017-11-16 14:26:33')这种查询的效率就会很低,所以有没有 可以统计这种没有规律的时间段内数据的 方法。
这种非确定时间的统计只能实时来做,建议从优化数据库性能方向着手。
查询最近7天,设置要查询的天数就行了
$days = Input::get('days', 7);
$range = \Carbon\Carbon::now()->subDays($days);
$stats = User::where('created_at', '>=', $range)
->groupBy('date')
->orderBy('date', 'DESC')
->remember(1440)
->get([
DB::raw('Date(created_at) as date'),
DB::raw('COUNT(*) as value')
])
->toJSON();@Wanzj 看我的答案,直接用mysql的date函数,结合Carbon,爽爆了。
$days = Input::get('days', 7);
$range = \Carbon\Carbon::now()->subDays($days);
$stats = User::where('created_at', '>=', $range)
->groupBy('date')
->orderBy('date', 'DESC')
->remember(1440)
->get([
DB::raw('Date(created_at) as date'),
DB::raw('COUNT(*) as value')
])
->toJSON();return $this->where('category_id',$category)
->whereBetween('sort_time',[$st,$et])
->where('device_type',1)
->select(\DB::raw('sum(amount) as y,device as x'))
->groupby('x')
->get();我现在是所有的数据都是用的区间查的,暂时没有做统计表


进行表分区,如果表数据字段非常多,已经非常大了,可以建个新表,新表分区,就保存需要统计的字段。进行任务定时,往新表,新增数据





 关于 LearnKu
关于 LearnKu




推荐文章: