
通一个sql执行效率不一样,是为啥
Mysql 8.0.24 下数据库大概160w条数据
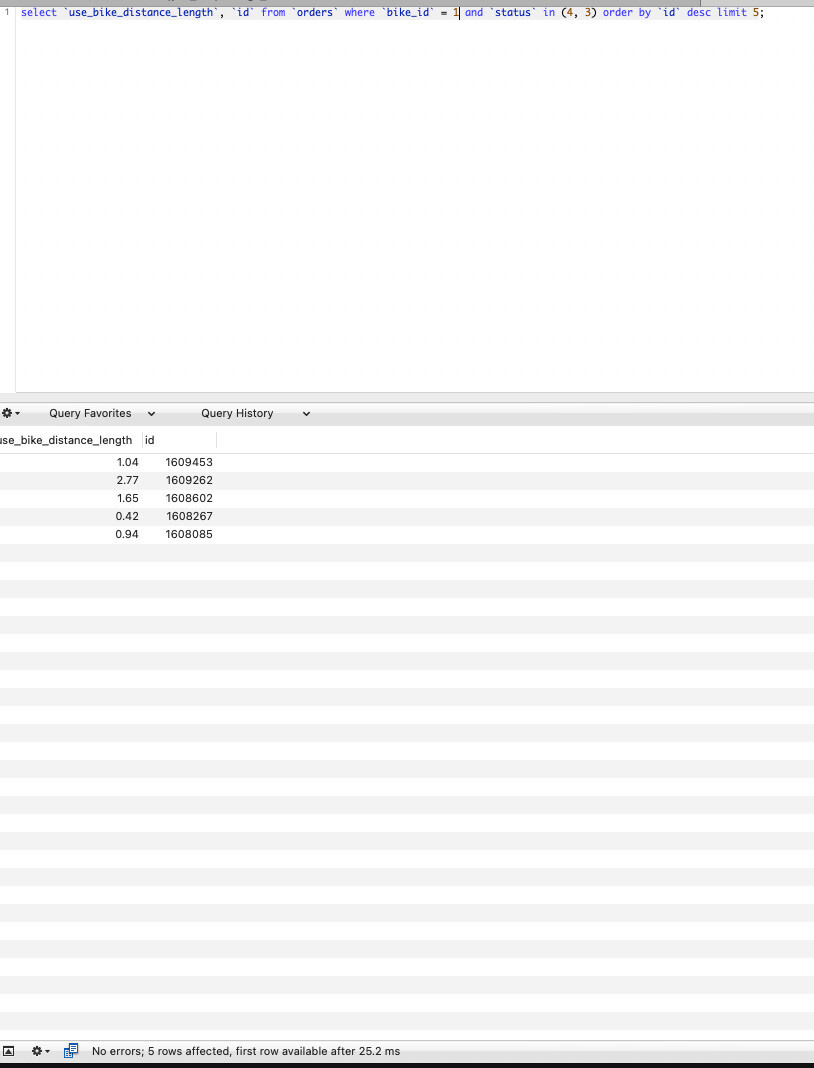
1、select `use_bike_distance_length`, `id` from `orders` where `bike_id` = 1 and `status` in (4, 3) order by `id` desc limit 5;#数据库里面有很多符合这个条件的数据【很快】
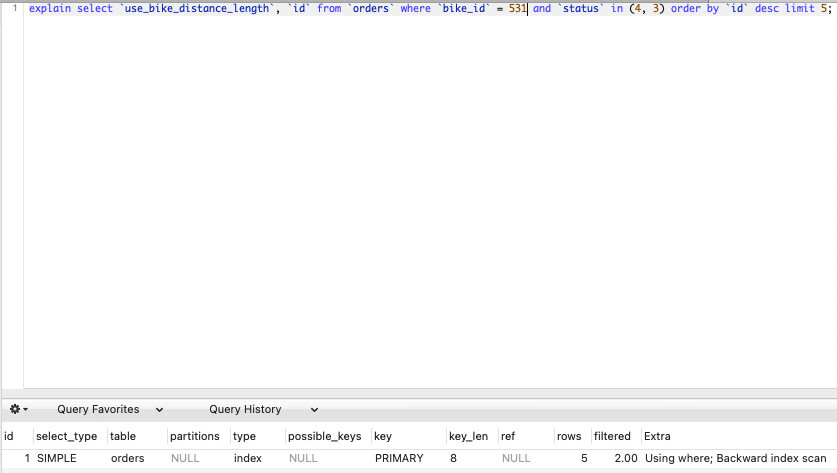
2、select `use_bike_distance_length`, `id` from `orders` where `bike_id` = 531 and `status` in (4, 3) order by `id` desc limit 5;#数据库中没有符合这个条件的数据【很慢】不知道从哪下手分析导致这样问题的原因。
执行计划

运行效果

我的分析
- 应该和索引和执行计划没有关系【要是有关我感觉应该是:没有数据也就没有索引,是不是全表查了;但是如果查询的时候如果没有索引咋会有数据,我感觉不用全表扫描查吧。】
1、select `use_bike_distance_length`, `id` from `orders` where `bike_id` = 1 order by `id` desc limit 5;#【快】 2、select `use_bike_distance_length`, `id` from `orders` where `bike_id` = 531 order by `id` desc limit 5;【慢】

















 关于 LearnKu
关于 LearnKu




推荐文章: