
大家看看这个数据表怎么设计最简单?
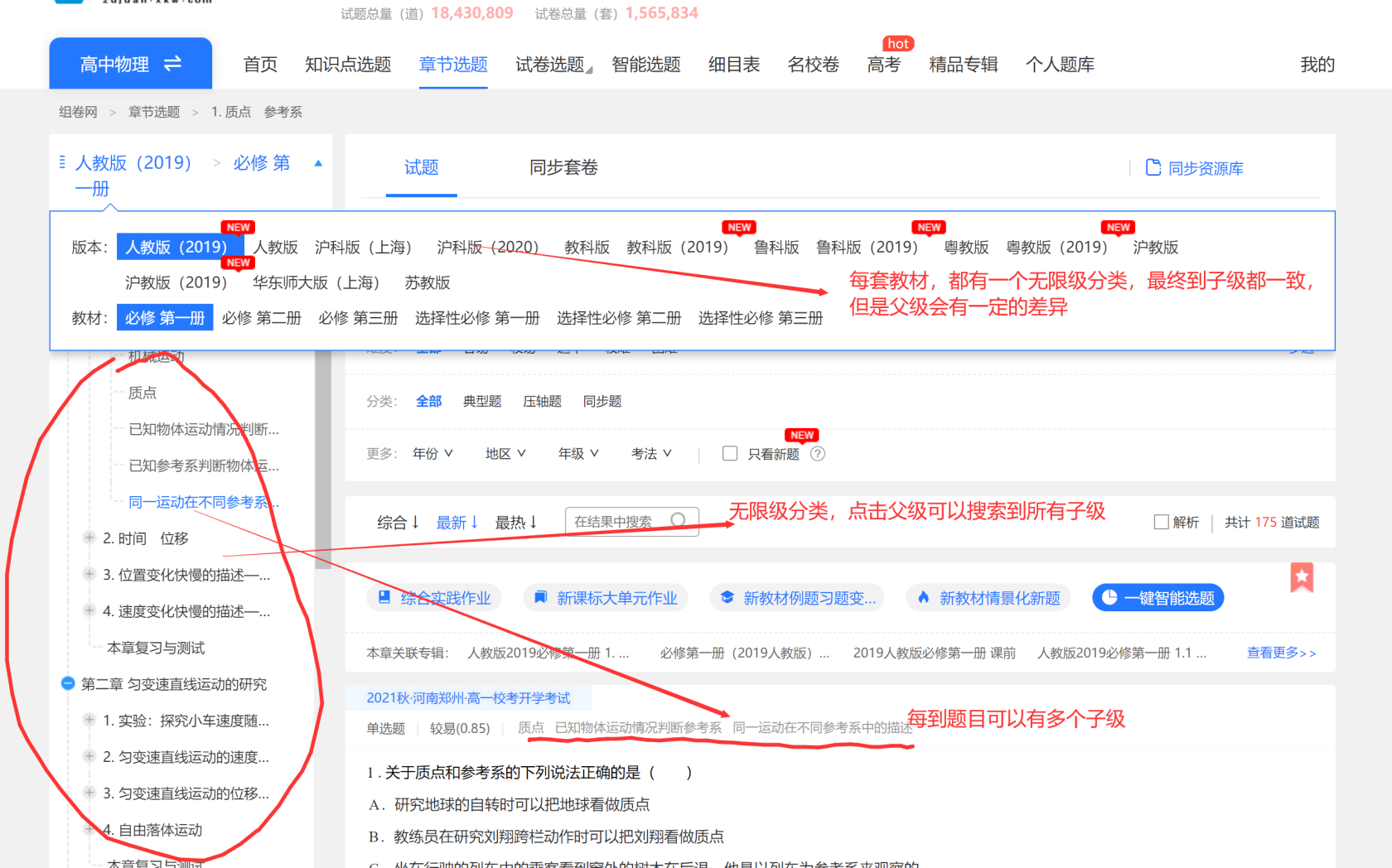
发现组卷网的这个选题有点厉害,单独的无限级分类,只要选择子级,将父ID都一起存到数据库即可,但是同样的数据,关联多个无限级分类,还真不太好设计,
比如说后台,选择一个分类下的一个子级,那么根据关联关系,我可以得到其他分类的所有关联关系,如果都提前存储,添加一个新教材怎么办呢?
如果不提前存储,那搜索的时候怎么办呢?
还真挺难搞的呀。
补充说明:
下面的所有设计均为初步想法,包括分类表,都可以推翻重来。
一般来说,无限级分类, 数据表为以下做法
教材1
| id | name | parent_id |
|---|---|---|
| 1 | 第一章 运动与描述 | 0 |
| 2 | 1 质点 参考系和坐标系 | 1 |
| 3 | 质点 | 2 |
| 4 | 新的1级 | 0 |
| 5 | 新的2级 | 4 |
| 6 | 新的3级 | 5 |
那么文章表设计如下
| id | name | cate_id | cate_ids |
|---|---|---|---|
| 1 | 文章1 | 3 | 1,2,3 |
| 2 | 文章2 | 3 | 1,2,3 |
| 3 | 文章3 | 6 | 4,5,6 |
查询时如下, 不管是查询最底层的id,或者其中的任何一个父级
SELECT * from 文章表 WHERE FIND_IN_SET(查询的ID, cate_ids)那么最上图的截图,问题是什么呢?
可以有多个新的无限级分类,无限级分类的最底层(last children)是有关联的,1对1,都可以查询到这个文章表
例如:一个新的无限级分类
教材2
| id | name | parent_id |
|---|---|---|
| 8 | 第一章 匀变速直线运动 | 0 |
| 9 | A. 质点 位移和时间 | 8 |
| 10 | 质点 | 9 |
那么我们可以人为的不管是加一个表或者怎么处理,让他们有一个对应的1对1关系
| 教材1 1id | 教材2 id | 教材3 id |
|---|---|---|
| 3 | 10 | ….. |
这样我们在文章表插入数据时,只需要以其中的一个分类为基础,就可以查找到所有相关的无限级分类,
那么最简单粗暴的方法
在文章表或者新开一个表, 增加分类字段,在入库之前
| id | name | cate_id | cate_ids | cate_id2 | cate_ids2 | cate_id3… |
|---|---|---|---|---|---|---|
| 1 | 文章1 | 3 | 1,2,3 | 10 | 8,9,10 | … |
| 2 | 文章2 | 3 | 1,2,3 | 10 | 8,9,10 | … |
| 3 | 文章3 | 6 | 4,5,6 | 15 | 3,6,15 | … |
| … |
这样查询时,我们会知道,他是从哪个分类来的
SELECT * from 文章表 WHERE FIND_IN_SET(查询的ID, 分类_ids)这样虽然可以实现功能,那如果我今天,又想增加一个新的分类表呢?不能所有文章编辑一遍吧,当然也可以跑个脚本,所有文章自动改一遍。
不知道大家有什么更好的想法没?

















 关于 LearnKu
关于 LearnKu




推荐文章: