
服务器崩溃、远程无法访问、阿里云诊断提示IO延迟过长,导致读写受限
服务器监控情况
在晚上4点左右突然疯狂读取硬盘,一直持续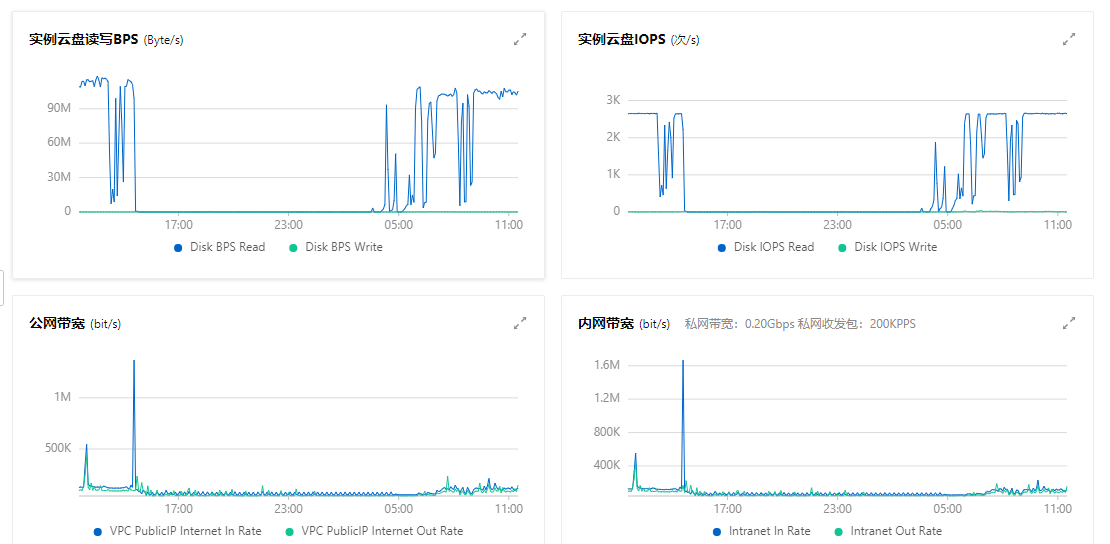
阿里云诊断提示
当前实例的云盘在2023年11月28日 11:13:00出现读写IO延迟过长,或达到了该云盘类型的IOPS上限,导致实例云盘读写受限。
请教下如何排查,急!!
补充:
查了系统的日志 /var/log/message
发现在触发读盘时候有内存oom的信息,内存不足了,估计是内存一直保持满负荷,一跑任务就触发oom,系统读取硬盘保存现场,导致读取量暴增,超出阿里云的io限制,然后就蹦了。
这种推理有没有可能?












 关于 LearnKu
关于 LearnKu




推荐文章: