
我们是如何将 22TB 的 MySQL 集群从 5.6 升级到 5.7 的?(费时 9 个月)

昨天, Synthesio Coffee 团队完成了一个 22TB 的MySQL集群从 Percona 5.6 升级到 Percona 5.7 。 我们已经升级了我们大部分集群,知道这次升级会需要时间,但是我们没有想到整整会花上 9个月的时间。 这就是我们在不停机的情况下迁移巨型数据库集群的经验。
最初的设置
我们的数据库集群是在 Haproxy 后面运行的经典高可用性 3+1 节点拓扑。它运行在没有 Systemd 的 Debian Jessie 上,内核为 4.9.1 (最开始是 4.4.36)。 服务器搭配 20 核心的 Dual Xeon E5-2660 v3 , 256GB内存 和 设置为 RAID10 的 36*4 TB 硬盘 。 吞吐量约为每天1亿次写入,插入和更新混合。
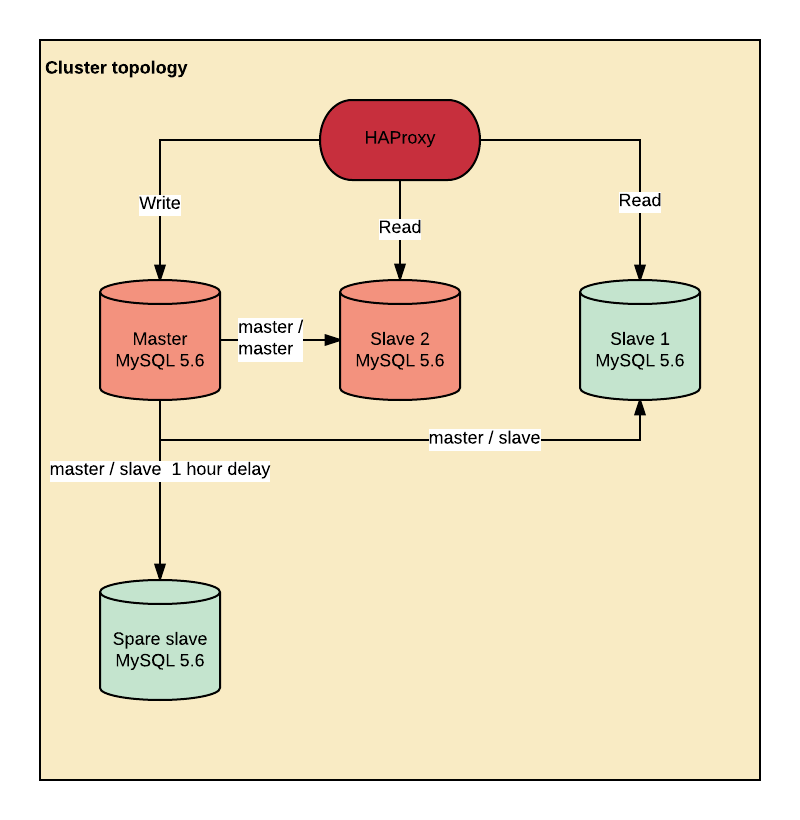
集群设计
集群设计本身没有什么特别之处:
- 2 台服务器被配置为主/主, 但是只能在主要的主机上执行写操作。
- 通过一个 Haproxy 在 Master 主服务器和 Slave1 、Slave2 两台从服务器上进行读取,配置为在复制延迟时移除一台从机。
- 一个备用的 Spare Salve 从机在异地运行, MASTER_DELAY 设置为1小时,以防止 The little Bobby Tables 来玩弄我们的服务器。
第一步: 在 mysql_upgrade 的地狱里
我们使用 Percona Debian 软件包将 Spare Salve 备用主机升级到 MySQL5.7 。
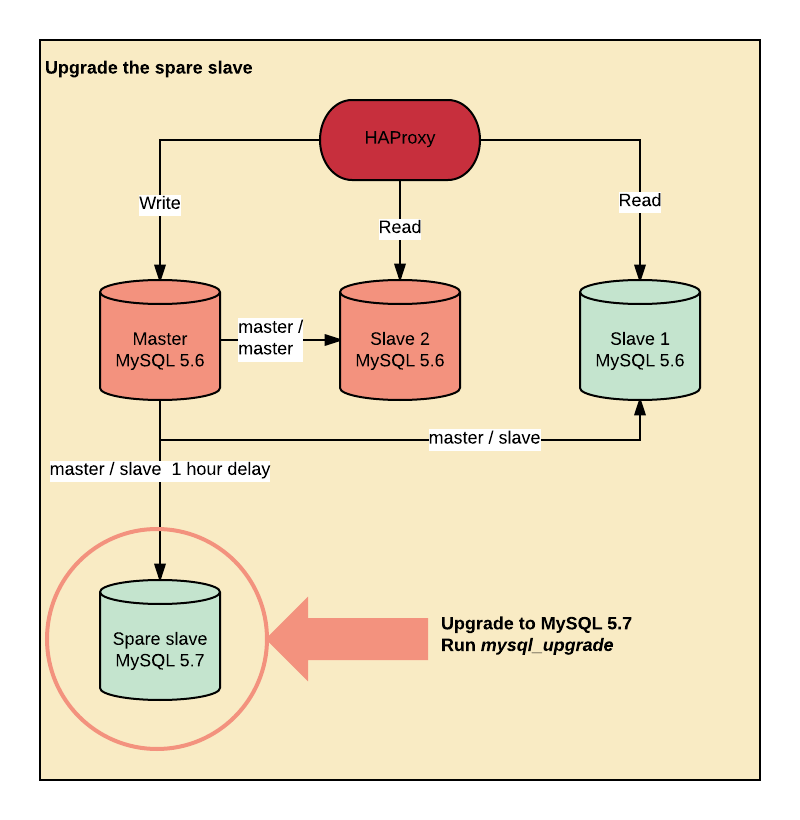
Spare Slave 备用从机的升级
从 MySQL5.6 升级到 MySQL5.7 需要升级每个包含 TIME 、 DATETIME ,以及 TIMESTAMP 的列, 以增加对小数秒精度的支持。 mysql_upgrade 需要处理这一部分以及系统表的升级。
升级带有时间列的表意味着在每一个需要升级的表中运行 ALTER TABLE ... FORACE 。 这意味着复制 22TB 的数据表作为临时表,然后把数据加载回来。在旋转的磁盘上。
5个月后,我们完成啦 20% 。
我们杀死了 mysql_upgrade 并编写了一个脚本,在两个表上并行运行着 ALTER 。
2个月后,升级完成了 50% , 复制延迟约 900万秒。 大规模复制延迟并不再计划之中,并且在该过程中引入了重大的意外延迟。
我们决定稍微升级一下硬件。
我们安装了一个新的主机,配备了 12 3.8TB SSD 磁盘 在 RAID0 中 (不要在home中这样做), rsynced* 了备用主机的数据,并且恢复了这个过程。8天后,升级结束了。又花了3个星期才赶上复制的进度。
第二步:添加2个新的 MySQL5.7 从库
在执行此操作之前,请确保你的集群已经激活 GTID 。 GTID 为我们节省了大量时间和麻烦,因为我们多次重新配置了复制。不确定的友情提示,但 MASTER_AUTO_POSITION=1 太魔幻了。
我们新增了2个运行 MySQL5.7 新的从库。在安装一个新的服务器时, Percona postinst.sh 脚本有一个错误, MySQL 的数据不在 /var/lib/mysql 。数据库的路径被硬编码在 shell 脚本中,这导致安装永远挂起。通过安装 percona-server-server-5.6,然后安装 percona-server-server-5.7 可以绕过。
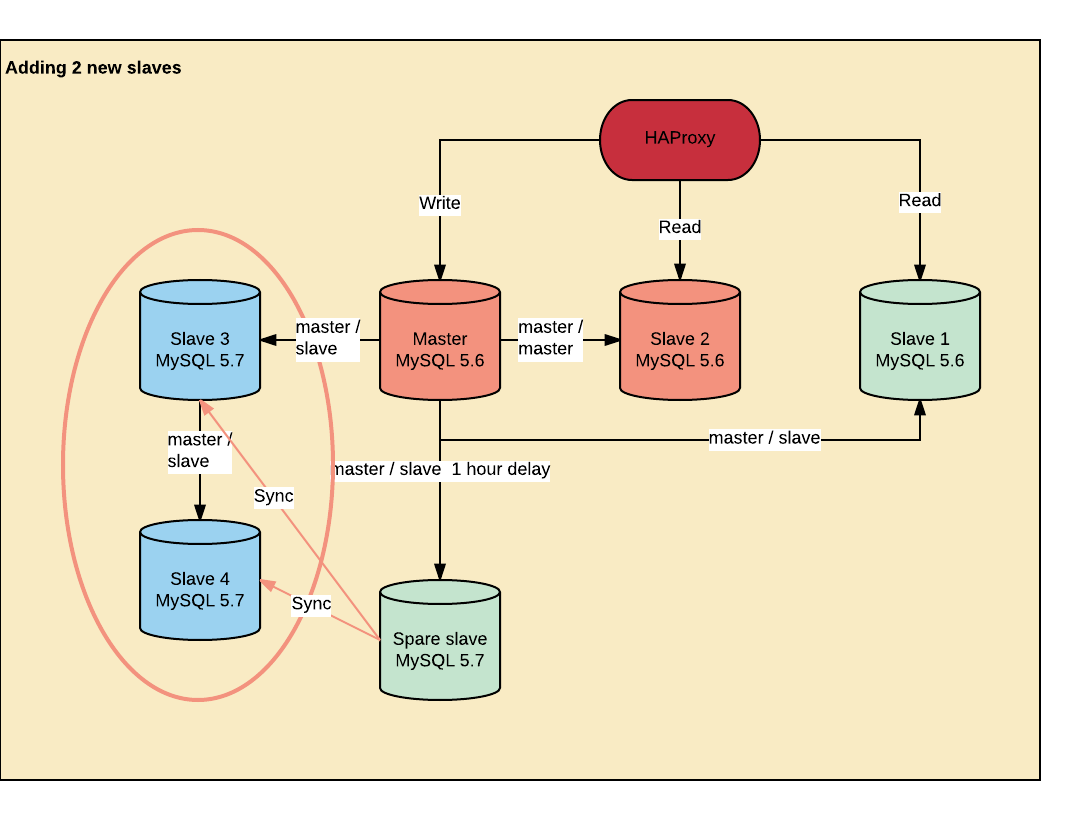
添加2个新从机
完成后,我们将数据从 MySQL5.7 备用主机上同步运行 innobackupex 的新从机
。
接收方:
mysql -e "SET GLOBAL expire_logs_days=7;"
nc -l -p 9999 | xbstream -x发送方:
innobackupex --stream=xbstream -- parallel=8 ./ | nc slave[3,4] 999930个小时后:
innobackupex --use-memory=200G --apply-log .Slave 3 上:
CHANGE MASTER TO
MASTER_HOST="master",
MASTER_USER="user",
MASTER_PASSWORD="password",
MASTER_AUTO_POSITION=1;Slave 4 上:
CHANGE MASTER TO
MASTER_HOST="slave 3",
MASTER_USER="user",
MASTER_PASSWORD="password",
MASTER_AUTO_POSITION=1;第三步:赶上复制(再次)
再次,我们在复制上滞后了。我已经写过 修复滞后的 MySQL 复制 。在你应用下面配置之前,请仔细阅读利弊。
STOP SLAVE;
SET GLOBAL sync_binlog=0;
SET GLOBAL innodb_flush_log_at_trx_commit=2;
SET GLOBAL innodb_flush_log_at_timeout=1800;
SET GLOBAL slave_parallel_workers=40;
START SLAVE;赶上两台主机完成复制需要2到3周的时间,主要是因为我们的写入比平时多得多。
第四步:完成工作
迁移基本完成。还有几件事情需要做。
我们重新配置了 Haproxy ,切换写操作到 Slave3 上 ,事实上 Slave3 已经成为新的主机,切换读操作到 Slave4 上 。然后我们重启了平台上所有写入进程,以杀死剩余的连接。
5分钟后,Slave3 已经赶上了 Master 主机的所有内容,我们停止了复制。我们保存主服务器上最后一个事务ID,以防止我们不得不回滚。
然后,我们重新配置了 Slave3 的配置,使其成为 Salve4的从属,因此我们将再次在 master/master 中运行。
我们在 MySQL5.7中升级了 Master,再次运行 innobackupex,并使其成为 Salve3的从库。复制花了几天时间才赶上,然后,昨天我们又将 master 重新添加到集群中。
一周后,我们丢弃 Slave1 和 Slave2 这两个不要的机器。
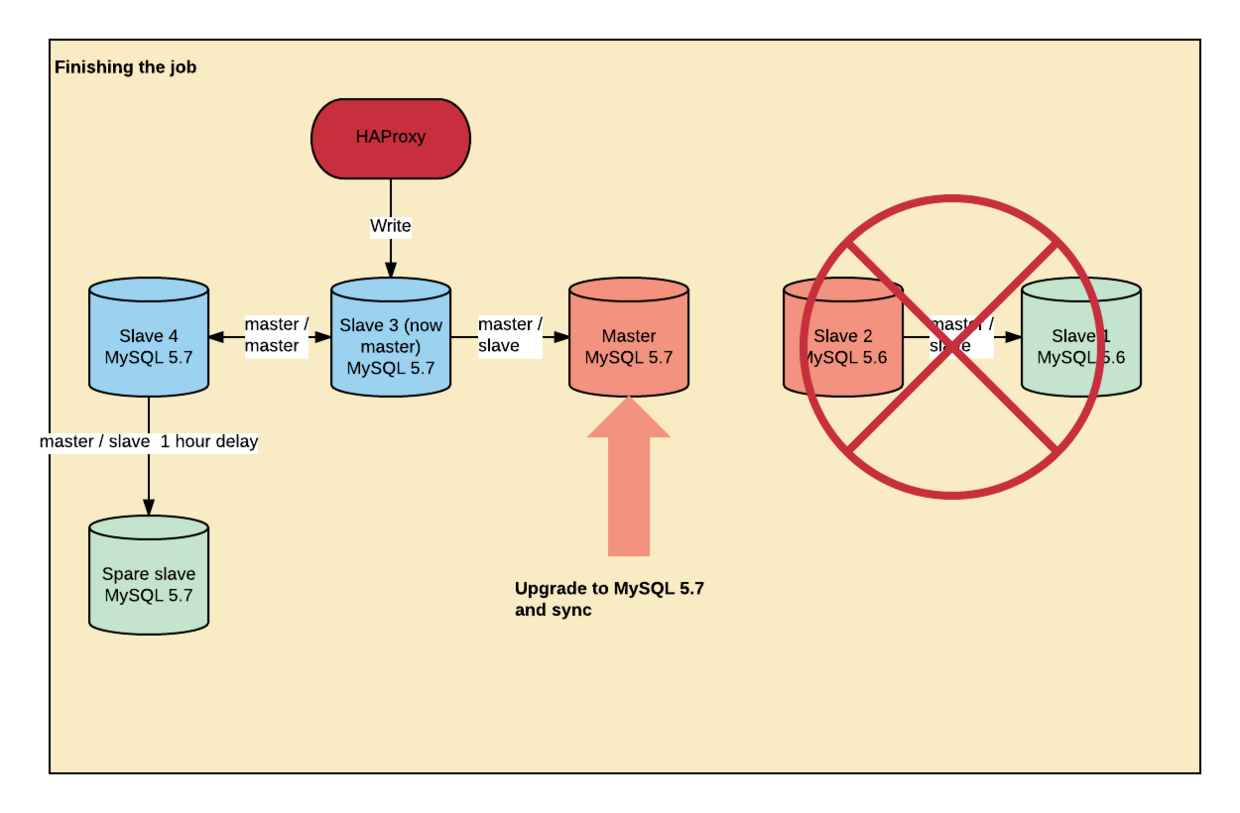
把事情做好
回滚,有人说“回滚”吗?
中国有句古话对于每一次迁移:
一个好的迁移是顺利的,但一个伟大的迁移是需要有回滚的措施。
如果出了问题,我们有一个 B 计划。
在迁移的时候,我们保留了最后一个 Master 上运行的事务,Master 仍然连接到 Slave1 和 Slave2 。如果出现问题,我们将会停止一切,导出丢失的事务,加载数据并且切换 源 Master + Slave1 + Slave2 。谢天谢地,这不是我们必须要做的事情,下一次,我将告诉你如果迁移 6GB 的 Galera 集群,从 MySQL5.6 到 MySQL5.7 。稍微晚些时候。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。







 关于 LearnKu
关于 LearnKu




推荐文章: