
线程并行使用线程池并发操作 2800 多条线程,时间反而用时比不用线程池更大?原因是什么?
参考文章:
11.4. threading — 管理单个进程里的并行操作
我们地excel数据集:
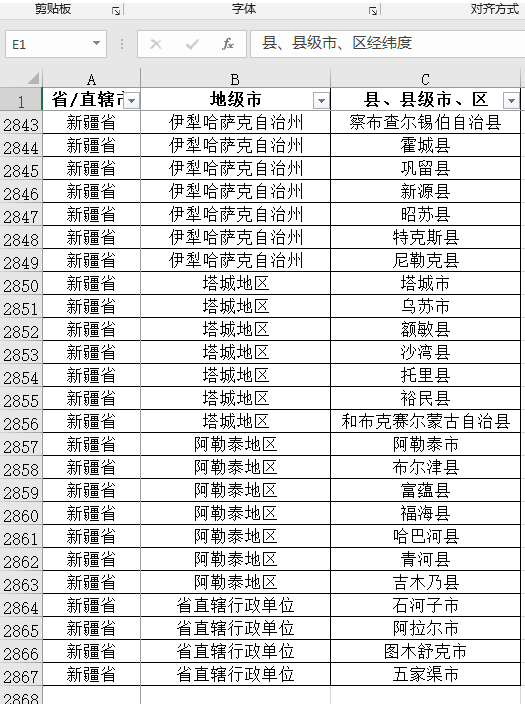
使用threading,单进程多线程操作
threading — 管理单个进程里的并行操作
管理几个线程执行。
使用线程允许一个程序在同一个进程空间中并发运行多个操作。单进程多线程操作。
主要在excel2sql.py文件中进行修改:
多线程操作主要部分代码:
def insert_coordinates(
self,
) -> "result={'code':'xx','message':'xx','data':xx}":
geo_app = Geo_mapInterface(config.geo_key)
all_data = [self.sh_data.row_values(i) for i in range(self.rows)]
test_data = [i for i in all_data ]
print(test_data)
new_excel = copy(self.excel)
ws = new_excel.get_sheet(self.sheet)
def test(i):
cur_coordinates = 12345
ws.write(i,3,cur_coordinates)
time.sleep(0.01)
# print(i,l[2],'经纬度为',cur_coordinates,"已存入exlcel文档")
for i,l in enumerate(test_data[:]):
if l[3] and i!=0:
print(test[0][3],"已经存在",i[3])
elif l[3]!=" ":
# cur_coordinates = geo_app.get_coordinatesViaaddress(i[1])
test(i)
# t = threading.Thread(target=test, args=(i,))
# t.start()
new_excel.save(config.src_path+'\\data\\new_fileName.xls')我们使用threading来并行运行多个线程:
# cur_coordinates = geo_app.get_coordinatesViaaddress(i[1])
# test(i)
t = threading.Thread(target=test, args=(i,))
t.start()两者时间分别是30.804279s和00.643780s
我丢你吗,这尼玛是真的离谱!( ఠൠఠ )ノ
尝试使用线程池--concurrent.futures模块来开发线程并行:
# 线程池
from concurrent.futures import ThreadPoolExecutorimport好我们要的线程池
我们来试一下将2800多个线程装在线程池中运行:
def test(i):
cur_coordinates = 12345
ws.write(i,3,cur_coordinates)
time.sleep(0.01)
if i ==2865:
print('最后一条数据我运行完了',i,datetime.datetime.now())
# print(i,l[2],'经纬度为',cur
executor = ThreadPoolExecutor(max_workers=3)
for i,l in enumerate(test_data):
if l[3] and i!=0:
print(test[0][3],"已经存在",i[3])
elif l[3]!=" ":
# cur_coordinates = geo_app.get_coordinatesViaaddress(i[1])
# print(os.cpu_count())
# 单进程单线程30.804279stest
# test(i)
# 利用线程池--concurrent.futures模块来管理多线程:
future = executor.submit(test,i)
# 单进程,8核CPU,线程并行00.743780s,
# t = threading.Thread(target=test, args=(i,))
# t.start()
# print(t.getName())
#
new_excel.save(config.src_path+'\\data\\new_fileName.xls')当整个当前线程(当前文件运行完毕后)
if __name__ == "__main__":
test = OpExcel(config.src_path+"\\data\\2019最新全国城市省市县区行政级别对照表(194).xls","全国城市省市县区域列表")
# print(test.init_SampleViaProvince_name("北京市"))
start = datetime.datetime.now()
print("开始运行",start)
test.insert_coordinates()
print(datetime.datetime.now() - start)
print(datetime.datetime.now())我们是会打印当前时间的,但是当当前线程运行完成,似乎装在线程池的代码还没运行完毕,我们看看运行后的结果:
(env) PS F:\workspace> & f:/workspace/env/Scripts/python.exe f:/workspace/城市距离爬取/process_data/excel2sql.py
开始运行 2019-12-29 16:29:06.819023
0:00:00.166542
2019-12-29 16:29:06.985565
最后一条数据我运行完了 2865 2019-12-29 16:29:17.244969以上代码实际运行完毕的时间应该是 17.244969 - 06.819023,大约为10s
而我们利用同样的代码来运行之前的简单的单进程多线程并行,运行结果:
(env) PS F:\workspace> & f:/workspace/env/Scripts/python.exe f:/workspace/城市距离爬取/process_data/excel2sql.py
开始运行 2019-12-29 16:30:16.586423
最后一条数据我运行完了 2865 2019-12-29 16:30:17.172863
0:00:00.632285
2019-12-29 16:30:17.218708全部运行完毕的时间大概是16:30:17.218708 - 16:30:16.586423,也就是0.6s左右。
是因为线程池的大小缘故吗?
我们试着将线程池大小增大一倍:
executor = ThreadPoolExecutor(max_workers=6)运行结果:
(env) PS F:\workspace> & f:/workspace/env/Scripts/python.exe f:/workspace/城市距离爬取/process_data/excel2sql.py
开始运行 2019-12-29 16:32:09.525962
0:00:00.176528
2019-12-29 16:32:09.702490
最后一条数据我运行完了 2865 2019-12-29 16:32:14.756947确实有影响,那是不是可以判定影响运行速度的原因就是线程池的大小呢?
照这样说,反而将2800多个线程不放在池里不会就更快,更方便吗。
线程池的作用本来就是,方便上下文管理。。是不是这样的操作就是相当于用更多的时间来换取更安全的操作(上下文,资源管理)?
文章!!首发于我的博客Stray_Camel(^U^)ノ~YO。









 关于 LearnKu
关于 LearnKu




推荐文章: