
学习推荐系统 tf 相关知识提问,问题有三
1
为何embeding层的数据要扩X,2^N 的形式,有讲究吗
为何输入四个数据id,gender,age,job的embeding层id设为1,32 而其他都是1,16为何不统一
输入层输入
embeding层 为何要扩到

1,32 或1,16,为何不统一32
embeding原理知道,但是每次案例给的例子就是embeding成x,8 x,16 x,32为何是这些 有讲究吗
2
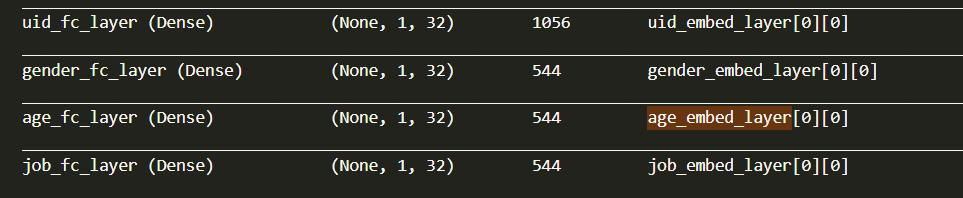
embeding后的数据经过dense层 激活函数relu 都能理解 但是为何本来的1,16的数据变成了1,32
dense层是这样写的:
uid_fc_layer = tf.keras.layers.Dense(embed_dim, name="uid_fc_layer", activation='relu')(uid_embed_layer)
gender_fc_layer = tf.keras.layers.Dense(embed_dim, name="gender_fc_layer", activation='relu')(gender_embed_layer)
age_fc_layer = tf.keras.layers.Dense(embed_dim, name="age_fc_layer", activation='relu')(age_embed_layer)
job_fc_layer = tf.keras.layers.Dense(embed_dim, name="job_fc_layer", activation='relu')(job_embed_layer)代码没问题,我理解的是 进行一层激活函数,relu 那数据的尺寸是不应该发生变化的呀
sum
归纳一下
为何embeding层的数据要扩X,2^N 的形式,有讲究吗
为何输入四个数据id,gender,age,job的embeding层id设为1,32 而其他都是1,16为何不统一
为何embeding后的dense层 (只是进行了激活函数 处理,数据的尺寸全部变了)?
研究的项目链接:https://nbviewer.jupyter.org/github/chengs...
文章!!首发于我的博客Stray_Camel(^U^)ノ~YO。







 关于 LearnKu
关于 LearnKu




推荐文章: