
如何正确使用requests 获得所需资料?
大家好,小弟目前需要使用requests获取以下网站的资料:
forumd.hkgolden.com/view.aspx?type...
图中红色框的内容小弟目前需要获取的资料: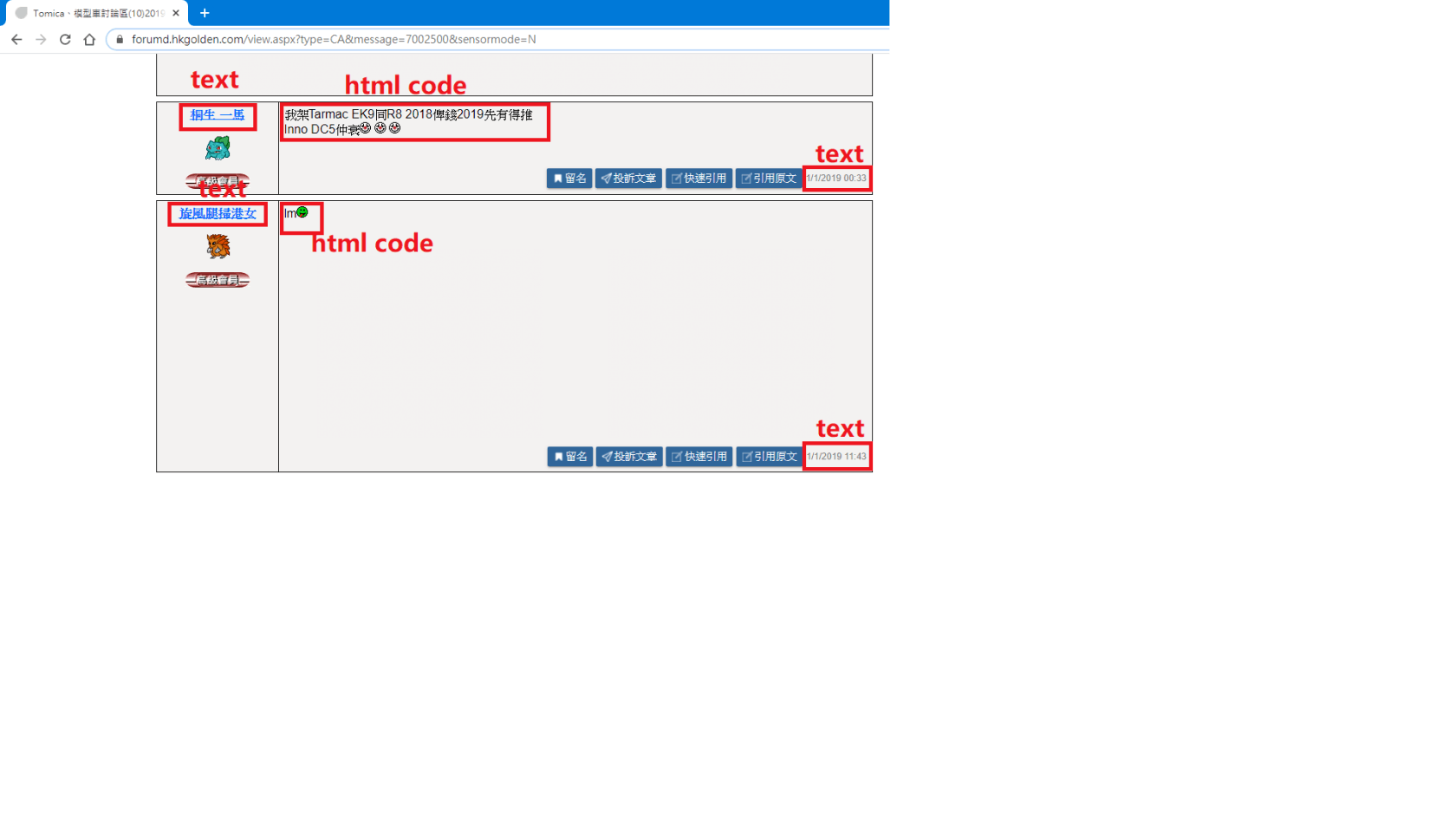
因此我需要使用以下代码获取相关的资料,目前只针对html code的部分处理:
import requests
from lxml import etree
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
URL = 'https://forumd.hkgolden.com/view.aspx?type=CA&message=7168706&sensormode=N'
res = requests.get(URL)
#content可以正常输出整个html代码
content = res.content.decode()
# 使用etree.HTML()載入html
html = etree.HTML(content)
content = html.xpath('//*[@id]/td[2]/table/tbody/tr[1]/td/div') #在图中的红色框框HTML Code 的XPATH
#/html/body/form/div[5]/div/div/div[2]/div[1]/div[5]/table/tbody/tr/td/table/tbody/tr/td[2]/table/tbody/tr[1]/td/div #在图中的红色框框HTML Code 的FULL XPATH
print(content)以上代码是参考以下网站,并根据我自己需要获取的网站查看规则,得到以上的xpath修正:
medium.com/%E9%B3%A5-crl/python%E9...
但是很不幸,目前我遇到一个难题,我在其他网站使用同一方法是可以正常得到网站的相关资料,但是不知道为何我需要获取的网站只有输出以下结果,使用XPATH 和FULL XPATH也一样:
只有显示 []
除了参考网址的方法,我也使用过其他方法,但结果还是一样只显示 []
我完全不知道问题到底发生在哪里,希望大家可以帮帮我,谢谢。





 关于 LearnKu
关于 LearnKu




推荐文章: