
猫眼票房大屏投影及常规版数据爬取
0 / 1 / 创建于 6年前 /
 MirrorTan 的个人博客
MirrorTan 的个人博客
猫眼票房 是查看国内影院上线电影票房的一个站点,包括 大屏投影 和 常规版 两个版面。本文尝试对这两个版面的数据进行爬取。
1 大屏投影
大屏投影是猫眼票房目前默认的首页,其中票房数据近乎实时更新,该版面展示的数据中相较于常规版多了一项「场均人次」。
1.1 页面分析
使用浏览器打开 大屏投影 版后,通过 检查 调出分析工具,选择 Network 选项卡,页面中会不断更新 https://box.maoyan.com/promovie/api/box/se... 文件 ~ 已实现更新票房数据。
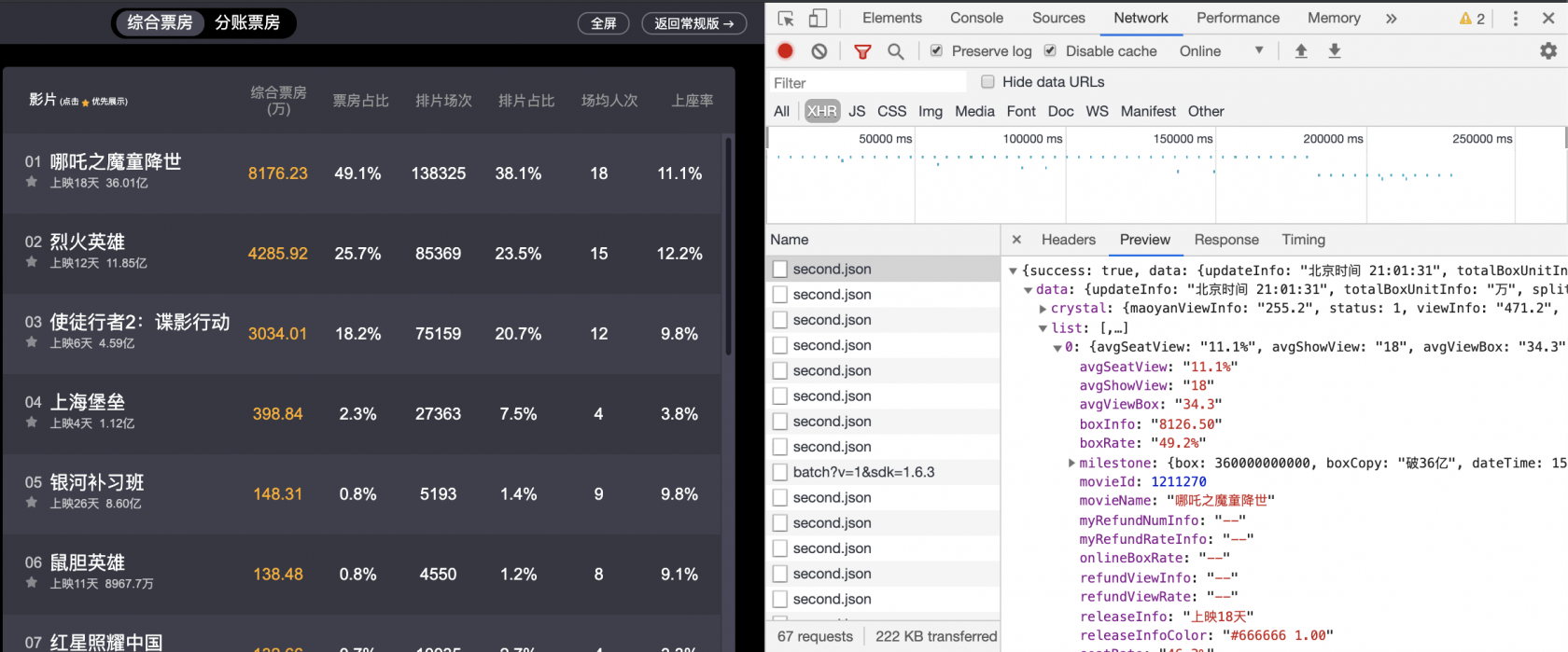
也即,该 Ajax 相应的 json 数据即为我们所需的数据。同时,当我们跳转到不同的日期,发现请求的 API 相应改变,如 2019/8/11 的票房数据请求 API 为 https://box.maoyan.com/promovie/api/box/se...。
所以,我们可以模仿浏览器的 Ajax 请求来实现数据的获取。
1.2 代码实现
import time
import datetime
import requests
from requests.exceptions import RequestException
def get_one_page(date):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
url = 'https://box.maoyan.com/promovie/api/box/second.json?beginDate=' + date
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except RequestException as e:
print("Requests {}, Error {}.".format(date, e.args))
def parse_one_page(json):
if json:
today = json.get('data').get('queryDate')
items = json.get('data').get('list')
for item in items:
yield {
'date': today,
'movieName': item['movieName'],
'releaseInfo': item['releaseInfo'],
'sumBoxInfo': item['sumBoxInfo'],
'splitSumBoxInfo': item['splitSumBoxInfo'],
'boxInfo': item['boxInfo'],
'boxRate': item['boxRate'],
'showInfo': item['showInfo'],
'showRate': item['showRate'],
'avgShowView': item['avgShowView'],
'avgSeatView': item['avgSeatView']
}
def main():
start_date = datetime.date.today()
for i in range(0, 31):
date = start_date - datetime.timedelta(days=i)
json = get_one_page(date.strftime(r'%Y%m%d'))
for item in parse_one_page(json):
print(item)
time.sleep(1)
if __name__ == '__main__':
main()借助于 requests 库,通过 get_one_page(date) 函数获得指定日期的票房数据;通过 parse_one_page(json) 实现对 json 格式数据的解析;在 main() 函数中,借助于 datetime 函数,一次请求过去一个月以来数据。
2 常规版
普通版的数据 30 分钟更新一次,直接请求 https://piaofang.maoyan.com/?ver=normal 页面时,所需数据已经存在,但返回的数字加密过 ~ 而且每次请求后获得的数据中数字加密方式不一致。
2.1 页面分析
通过 检查 常规版 页面,选择 Network 选项卡,查看 https://piaofang.maoyan.com/?ver=normal 对应的 Response 数据:
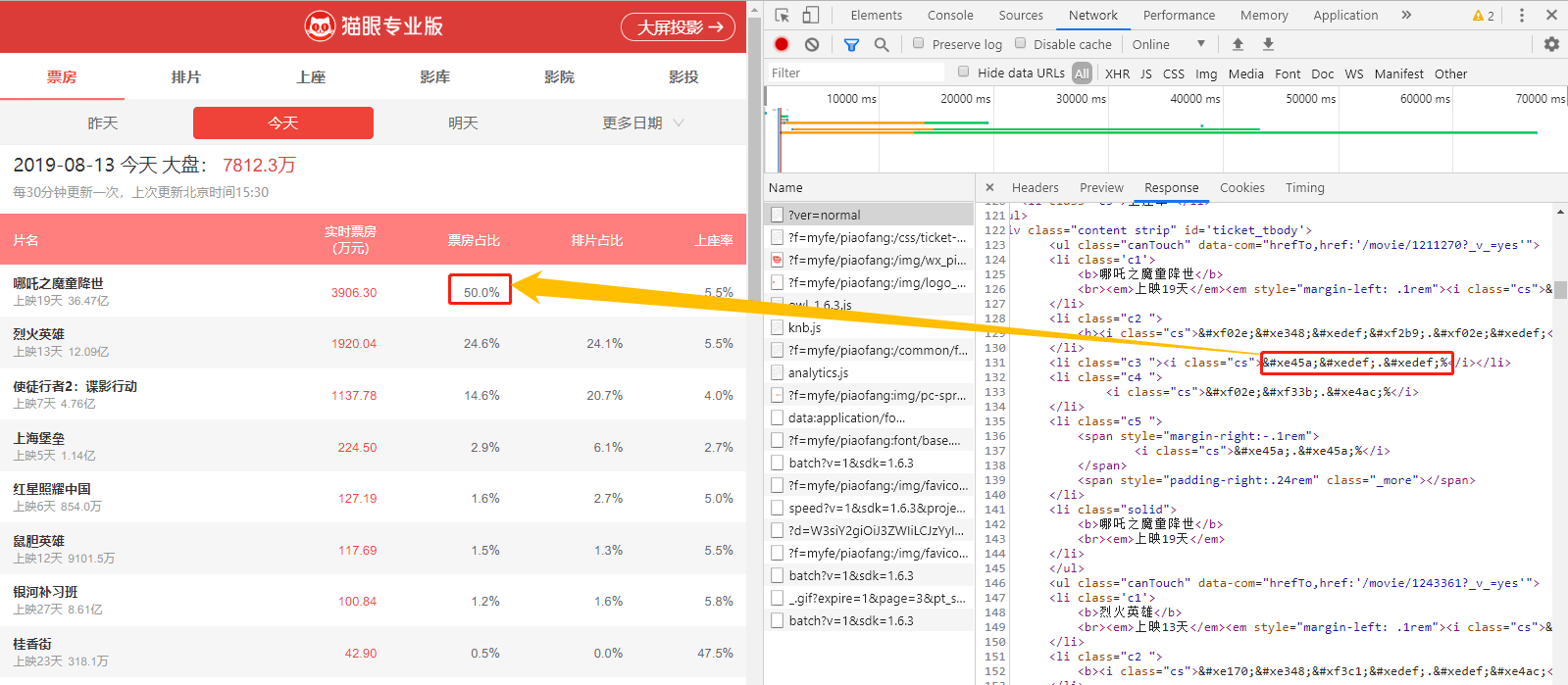
我们发现,此页面的数字进行过加密,对应的样式为 class="cs",通过在该页面中搜索 cs 发现其对应的样式为:
<style id="js-nuwa">
@font-face{font-family:"cs";src:url(data:application/font-woff;charset=utf-8;base64,d09G...yxfp) format("woff");}
.cs{font-family:cs}
</style>也即,字体通过 base64 进行加密。
2.2 字体加密
我们将加密后的字符串 (d09G...yxfp) 使用 base64 解码后,借助于 fontTools 库存储为字体文件:
import os
import re
import base64
import requests
from fontTools.ttLib import TTFont
def font_face(url, name):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
response = requests.get(url, headers=headers)
fonts = re.search(r'base64,(.*?)\)', response.text, re.S)
fonts = base64.b64decode(fonts)
with open(name+'.woff', 'wb') as fp:
fp.write(fonts)
TTFont(name+'.woff').saveXML(name+'.xml')
if __name__ == '__main__':
url1 = 'https://piaofang.maoyan.com/?ver=normal&date=2019-07-29'
url2 = 'https://piaofang.maoyan.com/?ver=normal&date=2019-07-28'
font_face(url1, 'font1')
font_face(url2, 'font2')借助于 百度字体编辑器 打开保存好的字体:


此时,我们即可找到加密后的字符串与数字之间的对应关系。不过这里有一点麻烦的地方在于不同时间加载加密方式不一样,也即字符串和数字对应的关系会发生变化。
不过,当我们将字体文件使用 fontTools 库保存为 .xml 格式后发现:

各个数字对应的字符串位于 <GlyphOrder>...</GlyphOrder> 中(id 与数值并没有直接关系);如请求的 font1 中 8 对应于 uniE577,而 font2 中的 1 对应于 uniE5F9,但二者的字形 <glyf>... 中的内容完全一致:
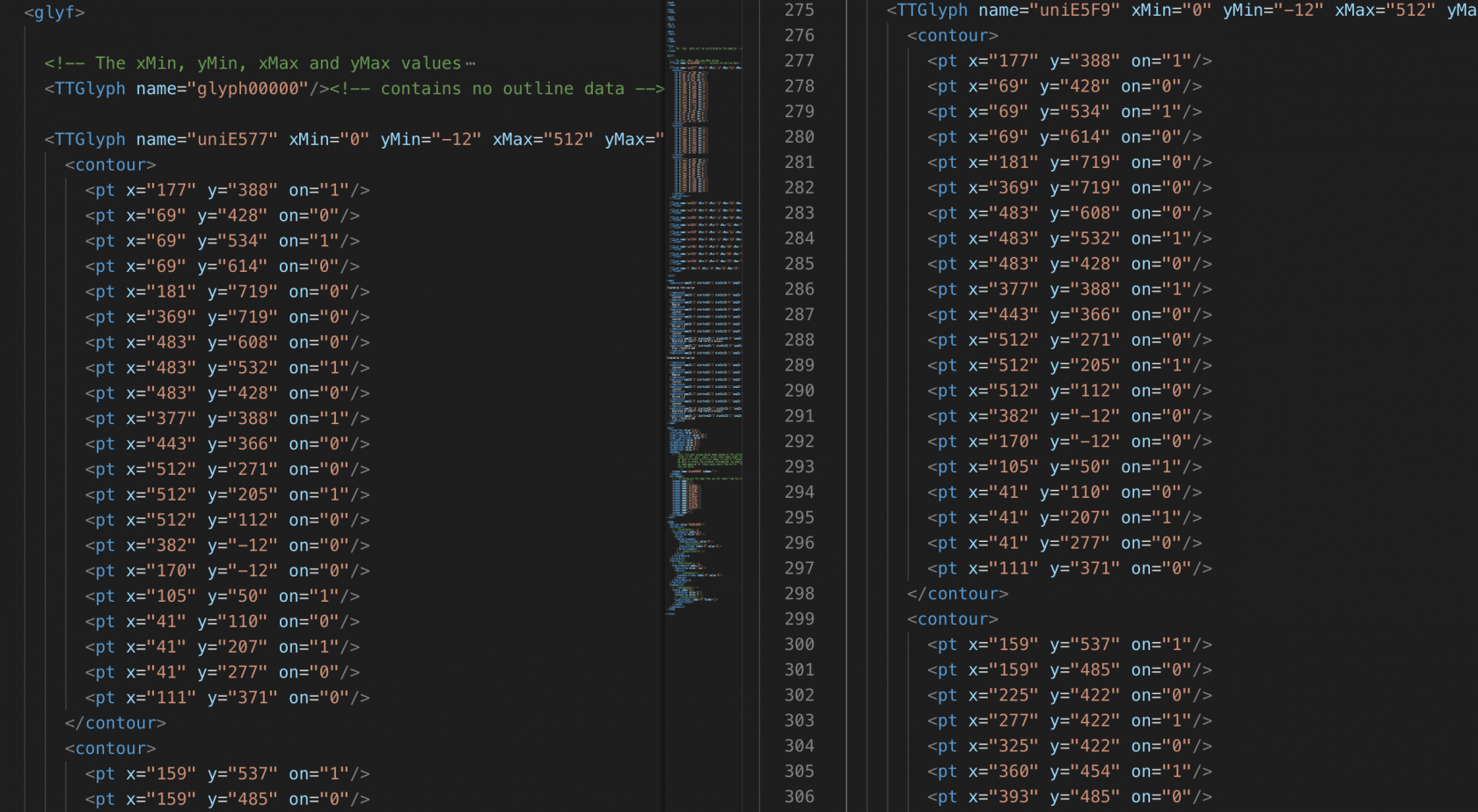
因此,我们找到了所需的不变量,即数字与字体文件中 <glyf> 的对应关系不会发生变化,而前端呈现的字符串与数字之间的对应关系会发生变化。
因此,我们只要找到第一次的加密字符串与数字之间的对应关系,利用 <glyf> 中的元素去匹配后续新文件,即可实现加密字符还原。
2.3 代码实现
import re
import time
import datetime
import base64
import requests
from requests.exceptions import RequestException
from pyquery import PyQuery as pq
from fontTools.ttLib import TTFont
font = TTFont('font1.woff')
uni_list = font.getGlyphOrder()[2:]
first_match = {
'uniE893': '0',
'uniF690': '1',
'uniF55C': '2',
'uniF28F': '3',
'uniF4B1': '4',
'uniE623': '5',
'uniF294': '6',
'uniEEC4': '7',
'uniE577': '8',
'uniE77B': '9'
}
def get_one_page(date):
headers = {
'User-Agent': os.getenv('User_Agent')
}
url = 'https://piaofang.maoyan.com/?ver=normal&date=' + date
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException as e:
print("Requests {}, Error {}.".format(date, e.args))
return None
def parse_font(html):
fonts = re.findall(r'base64,(.*?)\)', html, re.S)[0]
# fonts = re.search(r'base64,(.*?)\)', html, re.S)
fonts = base64.b64decode(fonts)
with open('tmp.woff', 'wb') as fp:
fp.write(fonts)
font1 = TTFont('tmp.woff')
# obj_list1 = font1.getGlyphNames()[1:-1]
uni_list1 = font1.getGlyphOrder()[2:]
tmp_match = {}
for uni1 in uni_list1:
obj1 = font1['glyf'][uni1] #获取编码 uni1 在 tmp.ttf 中对应的对象
for uni in uni_list:
obj = font['glyf'][uni]
if obj==obj1:
tmp_match[uni1] = first_match[uni]
return tmp_match
def rebuild_number(number, tmp_match):
'''还需要对数字进行改写'''
result = ''
for num in number:
s = str(hex(ord(num)))
s = s.upper().replace('0X', 'uni')
if s in tmp_match.keys():
result += tmp_match[s]
else:
result += num
return result
def parse_one_page(html):
tmp_match = parse_font(html)
doc = pq(html)
today = doc('.today').text()[:10]
movies = doc('#ticket_tbody ul').items()
for movie in movies:
result = {}
result['date'] = today
result['movieName'] = movie.find('.c1 b').text()
result['releaseInfo'] = movie.find('.c1 em').text().split()[0]
result['sumBoxInfo'] = rebuild_number(movie.find('.c1 em i').text(), tmp_match)
result['boxInfo'] = rebuild_number(movie.find('.c2').text(), tmp_match)
result['boxRate'] = rebuild_number(movie.find('.c3').text(), tmp_match)
result['showRate'] = rebuild_number(movie.find('.c4').text(), tmp_match)
result['avgSeatView'] = rebuild_number(movie.find('.c5').text(), tmp_match)
yield result
def main():
start_date = datetime.date.today()
for i in range(0, 31):
date = start_date - datetime.timedelta(days=i)
html = get_one_page(date.isoformat())
for result in parse_one_page(html):
print(result)
time.sleep(1)
if __name__ == '__main__':
main()使用 requests 库,通过 get_one_page(date) 实现指定日期网页请求;再利用 parse_one_page(html) 数据的提取,其中,首先调用 parse_font(html) 构建当前数字与加密字符串的对应关系,再利用 rebuild_number(number, tmp_match) 实现加密字符串的到数字的转换过程。
3 参考资料
- 大龄码农的Python之路, 丹枫无迹, Python爬虫实例:爬取猫眼电影——破解字体反爬, 2019/8/13.
- 《Python3网络爬虫开发实战》, 崔庆才,2019/8/13.
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: