
微信群里的二三事(上)
5 / 3 / 创建于 6年前 /
 MirrorTan 的个人博客
MirrorTan 的个人博客
微信基本上是使用最频繁的一款软件了,因为工作、学习、兴趣爱好等各种各样的原因,加入了很多很多群。今天,就利用 Python 对加入的微信群聊天记录进行一些简单的分析。
数据分析工作在 Jupyter 环境下开展,使用到的库主要有:
- pandas
- numpy
- matplotlib
- seaborn
- re
1 数据获取
要对微信群聊天记录进行分析,首先需要获取微信群聊天记录。微信聊天记录除保存在腾讯的服务器,也会在本地进行保存。因此,我们可以从手机端将聊天记录导出,获取我们需要的数据。
iPhone 版微信聊天记录导出可以参考 hangcom 的分享,Android 版可借鉴于 @godweiyang 的分享。
微信本地数据库保存在 EnMicroMsg.db 中,该数据库中的比较重要的表有:
- userinfo: 用户个人信息
- voiceinfo: 发送过的语音消息
- VoiceTransText: 转换为语音消息后的文本
- chatroom: 微信群信息
- message: 聊天记录
- HardDeviceRankInfo: 硬件设备信息 ~ 微信运动数据
- EmojiGroupInfo: 表情包组信息
- rcontact: 联系人信息
- friend_ext: 朋友相关信息
- SportStepItem: 个人运动步数 ~ 一天可能会存在多条数据
本次分析中主要使用到的有 chatroom, message, rcontact 三张表,使用 sqlcipher.exe 及之前获得的密码将需要用到的表导出为 csv 格式。
2 数据预处理
在获得相关数据后,我们将之导入 pandas 进行一些预处理,以便于后续数据分析工作。
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
pd.options.display.max_rows = 10
plt.rcParams['font.sans-serif']=['SimHei']
sns.set(font='SimHei')
%matplotlib inline定义一些后续会使用到变量:
my: 个人微信号
my = 'wxid_********22'2.1 数据读取
导入数据时需注意:
- 先将 csv 文件在本地转换为 ‘utf-8’ 格式(使用 pandas 以 ‘gb2312’ 导入出错);
- 导入时将 message 设定
index_col=6,以消息发送或收取时间为索引,便于后续分析。
chatroom = pd.read_csv('chatroom.csv')
message = pd.read_csv('message.csv', index_col=6)
rcontact = pd.read_csv('rcontact.csv')各 DataFrame 中要使用的数据及含义如下:
- chatroom: 微信群信息
- chatroomname: 微信群名 ~ 微信自动生成 ~ 唯一
- memberlist: 用户列表 ~ 微信号列表
- roomowner: 群主微信号
- memberCount: 群成员数量(可能存在错误)
- message: 聊天记录
- type: 消息类型
- isSend: 发送或接收消息
- createTime: 发送消息的时间 ~ 已被设定为 Index
- talker: 聊天对象
- content: 聊天内容
- rcontact: 联系人 ~ 实际上是有过联系的所有人(包括微信群中的非好友)
- username: 用户名信息 ~ 微信号 ~ 自动生成
- alias: 别名 ~ 修改过的微信号
- conRemark: 备注名
- nickname: 昵称
- type: 联系人类型
chatroom = chatroom[['chatroomname', 'memberlist', 'roomowner', 'memberCount']]
chatroom.head()| chatroomname | memberlist | roomowner | memberCount |
|---|---|---|---|
| 0 | 5604**@chatroom | wxid_****22;fj*71;wxid_82… | Gr**92 |
| 1 | 1202**@chatroom | Gr**92;lk**09;zh**75;sh… | su***e |
| 2 | 7766*****@chatroom | ww4;cha**;wxid_***22;wxid_… | dc****25 |
| 3 | 1682****@chatroom | wxid_;wxid_21;wxid_2… | wxid_****21 |
| 4 | 4346****@chatroom | wxid_*22;wxid_22;wxid_2… | wxid_*****22 |
message = message[['type', 'isSend', 'talker', 'content']]
message.head()| createTime | type | isSend | talker | content |
|---|---|---|---|---|
| 1537709186000 | 318767153 | 0.0 | weixin | \n \n … |
| 1537709314000 | 1 | 0.0 | weixin | 欢迎你再次回到微信。如果你在使用过程中有任何的问题或建议,记得给我发信反馈哦。 |
| 1534500421000 | 1 | 0.0 | 5604****@chatroom | w***i:\n又下雨了[捂脸] |
| 1534500558000 | 1 | 0.0 | 5604****@chatroom | ch***6:\n吃个饭先 |
| 1534500839000 | 1 | 0.0 | 5604****@chatroom | XL***45:\n来玩吗 |
rcontact = rcontact[['username', 'alias', 'conRemark', 'nickname', 'type']]
rcontact.head()| username | alias | conRemark | nickname | type | |
|---|---|---|---|---|---|
| 0 | filehelper | NaN | NaN | 文件传输助手 | 1 |
| 1 | qqmail | NaN | NaN | QQ邮箱提醒 | 33 |
| 2 | floatbottle | NaN | NaN | 漂流瓶 | 33 |
| 3 | shakeapp | NaN | NaN | 摇一摇 | 33 |
| 4 | lbsapp | NaN | NaN | 附近的人 | 33 |
2.2 rcontact 预处理
rcontact.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4569 entries, 0 to 4568
Data columns (total 5 columns):
username 4568 non-null object
alias 1036 non-null object
conRemark 389 non-null object
nickname 4498 non-null object
type 4569 non-null int64
dtypes: int64(1), object(4)
memory usage: 178.6+ KB对于部分联系对象(如群聊)无 alias, conRemark 是十分正常的现象,对于这两列数据直接填充为 ‘EMPTY’;而无 username 的联系人仅 1 条数据,直接删除即可。
rcontact.dropna(subset=['username'], inplace=True)
rcontact.fillna({'alias': 'EMPTY', 'conRemark': 'EMPTY'}, inplace=True)rcontact[rcontact.nickname.isnull()]| username | alias | conRemark | nickname | type | |
|---|---|---|---|---|---|
| 436 | 5479****@chatroom | EMPTY | EMPTY | NaN | 2 |
| 445 | fake_1573021893227 | EMPTY | EMPTY | NaN | 0 |
| 1261 | fake_1538661262204 | EMPTY | EMPTY | NaN | 0 |
| 1340 | fake_1541554264077 | EMPTY | EMPTY | NaN | 0 |
| 1342 | fake_1539142500399 | EMPTY | EMPTY | NaN | 0 |
| … | … | … | … | … | … |
| 4174 | fake_1576654843913 | EMPTY | EMPTY | NaN | 0 |
| 4205 | fake_1577183589467 | EMPTY | EMPTY | NaN | 0 |
| 4217 | fake_1577447590269 | EMPTY | EMPTY | NaN | 0 |
| 4328 | fake_1578041960745 | EMPTY | EMPTY | NaN | 0 |
| 4501 | fake_1580712150796 | EMPTY | EMPTY | NaN | 0 |
70 rows × 5 columns
对于 nickname 为空剩余 70 位联系人,其中 63 位以 'fake_' 开头,4 个群聊和另外 3 个用户,暂时将这部分数据先保留,填充为 'ALIEN'。
nan = rcontact.nickname.isnull()
name = rcontact.username.str
print('fake_: ', rcontact[nan & name.startswith('fake_') ]['username'].count())
print('@chatroom: ', rcontact[nan & name.endswith('@chatroom') ]['username'].count())fake_: 63
@chatroom: 4rcontact.fillna({'nickname': 'ALIEN'}, inplace=True)经个人整理推断,rcontact.type 表示含义如下:
- 0: 使用过的小程序
- 1: 添加用户的好友 ~ 含公众号
- 2: 群聊
- 3: 用户主动添加的好友 ~ 含关注的公众号
- 4: 同微信群非好友
- 7: 聊天频次高的好友
- 8, 9, 10, 11: 已删除或被删除的好友
- 33: 微信官方
- 259: 不让他看我朋友圈
- 2051: 置顶好友
- 8193: 未聊过天的好友
- 65536, 65537, 65539: 不看对方朋友圈的好友
rcontact[rcontact.username.str.endswith('@chatroom')].type.value_counts()2 92
0 2
Name: type, dtype: int64也即,在本地数据库中存在两个微信群 'type' 标注错误的情况,将之修正。
rcontact.loc[rcontact.username.str.endswith('@chatroom'), 'type'] = 2为便于后续运算将微信联系对象简化为并选取 contact_type 为 ['好友', '非好友', '群聊'] 三类。
contact_dict = {1:'好友', 2:'群聊', 3:'好友', 4:'非好友', 7:'好友', 8:'非好友', 9:'非好友', 10:'非好友',
11:'非好友', 259:'好友', 2051:'好友', 8193:'好友', 65536:'好友', 65537:'好友', 65539:'好友'}
rcontact['contact_type'] = rcontact['type'].map(contact_dict)
rcontact = rcontact[rcontact.contact_type.isin(['好友', '非好友', '群聊'])]
rcontact.contact_type.value_counts()非好友 2697
好友 552
群聊 94
Name: contact_type, dtype: int642.3 chatroom 处理
从导入的情况来看,共有 94 个群聊,为了获取关于群聊更详细的数据,我们需要将 chatroom 与 rcontact 合并。
chatroom = pd.merge(chatroom, rcontact, left_on='chatroomname', right_on='username')
chatroom.groupby(['alias', 'conRemark'])['chatroomname'].count()alias conRemark
EMPTY EMPTY 94
Name: chatroomname, dtype: int64也即,alias, conRemark 两列数据均为填充数据,实际上,微信群也没有「别名」和「备注」的概念,将这两列直接拿掉。另,chatroomname 和 username 重复,去掉其中一列。
chatroom.drop(columns=['alias', 'conRemark', 'username'], inplace=True)
chatroom.head()| chatroomname | memberlist | roomowner | memberCount | nickname | type | contact_type | |
|---|---|---|---|---|---|---|---|
| 0 | 5712****@chatroom | wxid_***… | Gr****92 | 18 | 首届吐槽大会 | 2 | 群聊 |
| 1 | 1202****@chatroom | Gr*6… | s****e | 24 | 2018?? | 2 | 群聊 |
| 2 | 7766***@chatroom | ww*_… | d**** | 166 | 建投公司 | 2 | 群聊 |
| 3 | 1682****@chatroom | wxid_… | wxid_** | 9 | 2017 | 2 | 群聊 |
| 4 | 4346****@chatroom | wxid_… | wxid_****22 | 52 | 没有烦恼的青春 | 2 | 群聊 |
chatroom['memberCount'].value_counts()-1 9
7 5
11 5
10 5
18 4
..
36 1
25 1
230 1
34 1
418 1
Name: memberCount, Length: 47, dtype: int64我们发现,memberCount 群成员数量中出现负数 ~ 明显不正常,需要进行调整;而群成员数量可通过 memberlist 计数获取。
chatroom.memberlist.str.split(';').str.len().value_counts().sort_index()2 2
3 3
4 4
5 3
6 1
..
166 1
206 1
230 1
405 1
418 1
Name: memberlist, Length: 48, dtype: int64(chatroom.memberlist.str.split(';').str.len() == chatroom.memberCount).sum()85经测算,通过对群成员计数获得的群成员数与 memberCount 相等共有 85 项,也即除 memberCount 为 -1 的情况均相等;采用对 memberlist 计数的值完善 memberCount。
chatroom['memberCount'] = chatroom.memberlist.str.split(';').str.len()2.4 message 预处理
本次计划对微信群聊天记录进行分析,也即对 talker 以 '@chatroom' 的聊天记录进行分析。
message = message[message.talker.str.endswith('@chatroom')]索引 createTime 是以毫秒为单位的累计时间,将之转换为常见格式。
message.index = pd.to_datetime(message.index, unit='ms', utc=True).tz_convert('Asia/Shanghai')
message.head()| createTime | type | isSend | talker | content |
|---|---|---|---|---|
| 2018-08-17 18:07:01+08:00 | 1 | 0.0 | 5604****@chatroom | we****:\n又下雨了[捂脸] |
| 2018-08-17 18:09:18+08:00 | 1 | 0.0 | 5604****@chatroom | ch**:\n吃个饭先 |
| 2018-08-17 18:13:59+08:00 | 1 | 0.0 | 2434****@chatroom | tc**:\n来玩吗 |
| 2018-08-17 18:14:04+08:00 | 3 | 0.0 | 5604****@chatroom | XL**:\n<img cdnbigimgurl=”null” hd… |
| 2018-08-17 18:14:13+08:00 | 1 | 0.0 | 1285**@chatroom | l***:\n加班 |
message.info()<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 155485 entries, 2018-08-17 18:07:01+08:00 to 2020-02-16 11:38:21+08:00
Data columns (total 4 columns):
type 155485 non-null int64
isSend 155477 non-null float64
talker 155485 non-null object
content 155415 non-null object
dtypes: float64(1), int64(1), object(2)
memory usage: 5.9+ MBmessage 表 isSend 缺 8 项,content 缺 70 项:
isSend为空值时表示群通话结束 ~ 与发起群语音通话对应,可直接删除;content为分析重点,缺项少,空值直接删除。
message.dropna(subset=['isSend', 'content'], inplace=True)需注意的是,isSend 有三种值:
- 1: 表示自己发出的消息;
- 0: 表示接受消息;
- 2: 其他消息,出现的包括群语音通话和我发起的拉人入群。
message.isSend.value_counts()0.0 153785
1.0 1611
2.0 11
Name: isSend, dtype: int64经推断,不同的 type 表示的消息种类如下:
- 1: 普通文字消息
- 3: 普通图片
- 34: 语音消息
- 42: 公众号名片
- 43: 普通视频
- 47: 表情包
- 48: 定位消息
- 49: 公众号或小程序分享
- 64: 群语音通话 ~ 发起群语音通话 isSend 为 2,结束 isSend 为 NaN
- 10000: 撤回消息
- 1048625: 收藏的表情
- 16777265: 网页分享
- 436207665: 微信红包
- 486539313: 转发公众号内的视频
- 520093745: 微信卡包 ~ 礼品卡
- 570425393: 邀请加入群聊信息
- 587202609: 小程序消息 ~ 游戏
- 805306417: 微信接龙
- 822083633: 引用回复消息
- -1879048186: 位置共享
为便于后续处理,对类型进行简化处理:
message_dict = {1: '文字', 3: '图片', 34: '语音', 42: '公众号', 43: '视频', 47: '表情', 48: '位置',
49: '公众号', 64: '通话', 10000: '撤回', 1048625: '表情', 16777265: '网页',
436207665: '红包', 486539313: '视频', 520093745: '公众号', 570425393: '加群',
587202609: '公众号', 805306417: '文字', 822083633: '文字', -1879048186: '位置'}
message['message_type'] = message.type.map(message_dict)此外,content 列不仅包含聊天的内容,还包括发言人员的微信号;微信号与聊天内容以 ':' 进行分割,微信号仅包含 [a-zA-Z0-9_\-] 字符。
使用 map 适合单列映射,但此处还需用到 type 信息帮助判断,因此并不适合 ~ 直接拆分后文本中含 : 的非用户发言会被当做用户发言;无 : 会被全部当成本人。此处借助于 apply 函数实现
regex = re.compile('([a-zA-Z0-9_\-]+):(.*)', flags=re.S)
username = set(rcontact.username)
def split_content(record):
content = str(record.content).strip()
if record.isSend == 0:
# 即用户接受的消息
m = regex.match(content)
# print(m.groups())
if m and (m.group(1) in username):
# 即正确匹配上并且拆分的用户名在 username 中
return (m.group(1), m.group(2).strip())
else:
# 实际上没有用户的情况
return ('None User', content)
elif record.isSend == 1:
# 用户发送的消息
return (my, content)
else:
# 其他消息 record.isSend == 2
return ('None User', content)message['username'], message['real_content'] = message.apply(split_content, axis=1).strmessage[message.username == 'None User'].type.value_counts()10000 1745
570425393 780
64 8
Name: type, dtype: int64也即,只有「撤回消息」、「拉人进群」以及「群通话」共 2533 条消息被标记为 ‘None User’。
3 初步分析
进行简单初步分析:
- 联系人 ~ 好友、非好友发言频次分析
- 发言类型 ~ 依据群聊人数多少分析发言类型之间的差异
3.1 发言频次分析
首先,统计所有联系人发言的频次信息;再将之与 rcontact 合并。
people = message.groupby('username')['real_content'].count()
people = pd.merge(people, rcontact, left_index=True, right_on='username', how='right')
people.head()| real_content | username | alias | conRemark | nickname | type | contact_type | |
|---|---|---|---|---|---|---|---|
| 0 | NaN | filehelper | EMPTY | EMPTY | 文件传输助手 | 1 | 好友 |
| 48 | 1611.0 | wxid_*****22 | **** | EMPTY | M** | 1 | 好友 |
| 49 | NaN | gh_** | z*u | EMPTY | Z*会 | 3 | 好友 |
| 51 | NaN | gh_* | ls** | EMPTY | 龙*网 | 3 | 好友 |
| 52 | NaN | wxid_** | EMPTY | 大* | 学* | 1 | 好友 |
将 'real_content' 列名改为 'counts',该列为空的实际就表示该联系人未发言,可直接填充为 0。
people.columns = ['counts', 'username', 'alias', 'conRemark', 'nickname', 'type', 'contact_type']
people.fillna(0, inplace=True)
people.sort_values(by='counts').tail(10)| counts | username | alias | conRemark | nickname | type | contact_type | |
|---|---|---|---|---|---|---|---|
| 2888 | 2432.0 | wxid_** | li**h | EMPTY | 雨眠** | 4 | 非好友 |
| 2459 | 2473.0 | wa** | EMPTY | EMPTY | 小业* | 4 | 非好友 |
| 2815 | 2677.0 | wxid_** | a5** | EMPTY | 白涛** | 4 | 非好友 |
| 2955 | 2757.0 | wxid_** | Y** | EMPTY | 花** | 4 | 非好友 |
| 3125 | 2976.0 | O* | EMPTY | EMPTY | 开心** | 4 | 非好友 |
| 3115 | 4117.0 | wxid_** | EMPTY | EMPTY | 金** | 4 | 非好友 |
| 357 | 5264.0 | wxid_** | Y** | 飞** | 大** | 3 | 好友 |
| 2869 | 5300.0 | H* | EMPTY | EMPTY | T* | 4 | 非好友 |
| 2920 | 5646.0 | wxid_** | EMPTY | EMPTY | rap** | 4 | 非好友 |
| 2790 | 10204.0 | h** | s** | EMPTY | 豆* | 4 | 非好友 |
也即,10 个发言最多的人 ~ None User 除外以及一位是自己的好友,其余均为同微信群中的非好友。
而作为加群最多的自己发言排在第 23 位,哈哈。
rank = people['counts'].rank(method='max')
rank.max() - rank[people[people.username == my].index] + 148 23.0
Name: counts, dtype: float64再来看看不同类型的好友发言量总量、平均量、方差。
people.groupby('contact_type')['counts'].agg(['sum', 'mean', 'median', 'std', 'count'])| contact_type | sum | mean | median | std | count |
|---|---|---|---|---|---|
| 好友 | 58605.0 | 106.168478 | 0.0 | 354.541844 | 552 |
| 群聊 | 0.0 | 0.000000 | 0.0 | 0.000000 | 94 |
| 非好友 | 94269.0 | 34.953281 | 0.0 | 309.216804 | 2697 |
我们可以很明显的看到好友和非好友之间发言上的差异,好友的发言均值要明显高于非好友;而两者都有的共同点就是方差大 ~ 而潜水用户占据比例高。
people[people.counts == 0].groupby('contact_type')['username'].count() / people.contact_type.value_counts()好友 0.54529
群聊 1.00000
非好友 0.62551
dtype: float64在分析聊天对象时微信群可直接去掉。
people = people[people.contact_type != '群聊']将用户按发言次数进行分组:[[0.0, 1.0) < [1.0, 10.0) < [10.0, 100.0) < [100.0, 1000.0) < [1000.0, 10205.0)],查看各组人数并绘制柱状图。
people_groups = ['深水炸弹', '潜伏者', '小气泡', '活跃分子', '资深话痨']
people_bins = [0, 1, 10, 100, 1000, people.counts.max()+1]people['cat'] = pd.cut(people['counts'], people_bins, labels=people_groups,right=False)
people['cat'].value_counts()深水炸弹 1988
潜伏者 610
小气泡 450
活跃分子 168
资深话痨 33
Name: cat, dtype: int64cat_counts = pd.crosstab(people.cat, people.contact_type)
cat_counts.plot(kind='bar')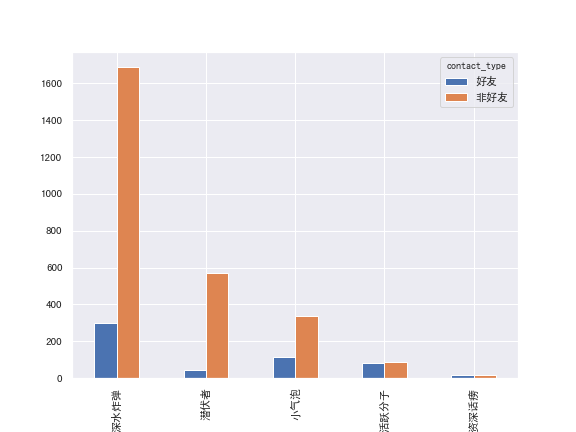
也即,无论是好友或非好友,不发言的均占据绝大多数。
3.2 发言类型分析
将群聊和发言合并,并选取需要的数据列
room = pd.merge(chatroom, message, left_on='chatroomname', right_on='talker')
room = room[['chatroomname', 'memberCount', 'message_type']]按群大小进行分组:(0, 10] < (10, 20] < (20, 50] < (50, 100] < (100, 419],查看各个大小群发言类型偏好。
room_groups = ['小小群', '小群', '中型群', '大型群', '巨型群']
room_bins = [0, 10, 20, 50, 100, chatroom.memberCount.max()+1]room['cat'] = pd.cut(room['memberCount'], room_bins, labels=room_groups)不同大小群各种类型发言总量偏好
room_total = room.groupby('cat')['chatroomname'].count()
talk_count = pd.crosstab(room.cat, room.message_type)
talk_count| message_type | 位置 | 公众号 | 加群 | 图片 | 撤回 | 文字 | 红包 | 网页 | 表情 | 视频 | 语音 | 通话 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cat | ||||||||||||
| 小小群 | 19 | 365 | 57 | 891 | 145 | 7920 | 207 | 1 | 523 | 90 | 68 | 0 |
| 小群 | 56 | 619 | 90 | 1751 | 396 | 28293 | 328 | 0 | 2650 | 205 | 235 | 2 |
| 中型群 | 27 | 405 | 235 | 733 | 264 | 10278 | 49 | 0 | 536 | 88 | 492 | 0 |
| 大型群 | 6 | 346 | 103 | 1562 | 159 | 4053 | 465 | 6 | 183 | 384 | 600 | 0 |
| 巨型群 | 32 | 1073 | 295 | 4011 | 798 | 75176 | 241 | 4 | 6999 | 500 | 387 | 6 |
talk_per = talk_count.div(room_total, axis=0) * 100
talk_per| message_type | 位置 | 公众号 | 加群 | 图片 | 撤回 | 文字 | 红包 | 网页 | 表情 | 视频 | 语音 | 通话 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cat | ||||||||||||
| 小小群 | 0.184717 | 3.548513 | 0.554151 | 8.662259 | 1.409683 | 76.997861 | 2.012444 | 0.009722 | 5.084581 | 0.874976 | 0.661093 | 0.000000 |
| 小群 | 0.161733 | 1.787726 | 0.259928 | 5.057040 | 1.143682 | 81.712635 | 0.947292 | 0.000000 | 7.653430 | 0.592058 | 0.678700 | 0.005776 |
| 中型群 | 0.205997 | 3.089952 | 1.792935 | 5.592432 | 2.014191 | 78.416114 | 0.373846 | 0.000000 | 4.089418 | 0.671397 | 3.753719 | 0.000000 |
| 大型群 | 0.076268 | 4.398119 | 1.309267 | 19.855091 | 2.021101 | 51.519003 | 5.910766 | 0.076268 | 2.326173 | 4.881149 | 7.626795 | 0.000000 |
| 巨型群 | 0.035745 | 1.198588 | 0.329528 | 4.480463 | 0.891401 | 83.974889 | 0.269208 | 0.004468 | 7.818190 | 0.558522 | 0.432296 | 0.006702 |
利用各种分组的群发消息的类别绘制热力图。
f, ax = plt.subplots(figsize=(9, 6))
sns.heatmap(np.sqrt(np.sqrt(talk_per)), annot=True, linewidths=.5, ax=ax, cmap='Set3')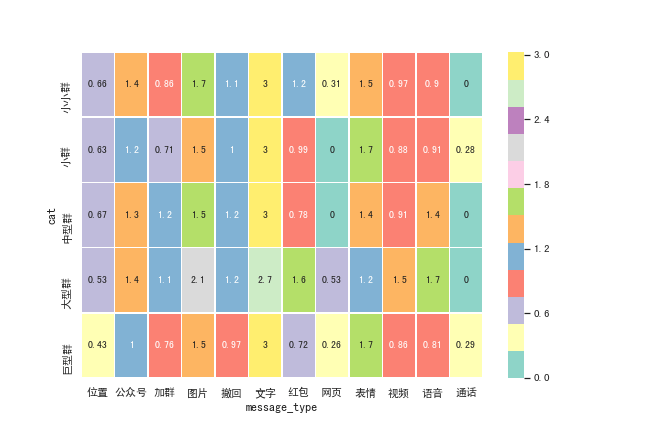
从占比上看,任何分组的「文字消息」均占据绝大多数,而且占比之间差异过大,因此在将占比两次开方后绘制。
从结果上看,除文字消息均占据最大比中外,图片、表情也是使用占比普遍较高的消息种类;小、中型群分享位置更多,中大型群撤回消息占比更多!
本次分析主要集中在数据预处理上,具体分析比较少,后续再依据发言时间、发言具体内容进行分析。
4 参考资料
- 韦阳的博客, 韦阳, 微信聊天记录导出为电脑 txt 文件教程, 2020/3/2.
- hangcom 写字的地方, hangcom, 微信聊天记录导出–发布, 2020/3/2.
- Asher117, 【Python】DataFrame 一列拆成多列以及一行拆成多行, 2020/3/2.
- 风浅安然, Matplotlib 及 Seaborn 中文显示问题, 2020/3/2.
本作品采用《CC 协议》,转载必须注明作者和本文链接













 关于 LearnKu
关于 LearnKu




推荐文章: