
微信群里的二三事(下)
5 / 0 / 创建于 6年前 /
 MirrorTan 的个人博客
MirrorTan 的个人博客
前期,我们将微信聊天记录导出后,并选择微信群聊天记录作为分析对象,进行了一些预处理工作后,从发言频次和发言类型进行了简单的分析。本次,我们从微信群聊的时间偏好进行分析,并选定记录最多的群聊分析该群中最受关注的人物,最后,对文字消息进行分词并绘制词云。
与上期一样,本次数据分析工作在 Jupyter 环境下开展,使用到的库主要有:
- pandas
- numpy
- matplotlib
- seaborn
- jieba
- wordcloud
- collections
1 聊天的时间偏好
即通过对微信群中不同时间的发言频次进行统计分析。
# 后续分析需要用到的新库
from collections import Counter
import jieba
import jieba.analyse
from wordcloud import WordCloud首先导入需要使用到的库并进行简单的设置。
print('Min Time: ', message.index.min())
print('Max Time: ', message.index.max())
print('Total Message: ', message['real_content'].count())Min Time: 2018-08-11 13:52:14+08:00
Max Time: 2020-02-16 11:38:21+08:00
Total Message: 155407即本次分析的微信群聊天记录发言时间在 2018-08-11 到 2020-02-06 之间,共计 155407 条记录,下面将从三个时间进度对发言频次进行分析:
- 按 ‘%Y-%m’ 精度进行频次统计;
- 按 ‘%w’ 精度进行频次统计;
- 按 ‘%H’ 进度进行频次统计。
1.1 按年月的发言统计
month_count = message['real_content'].resample('M', kind='period').count()
month_count.head()createTime
2018-08 1064
2018-09 4092
2018-10 3214
2018-11 3116
2018-12 4376
Freq: M, Name: real_content, dtype: int64fig, ax = plt.subplots(figsize=(9, 6))
month_count.plot(kind='bar', ax = ax)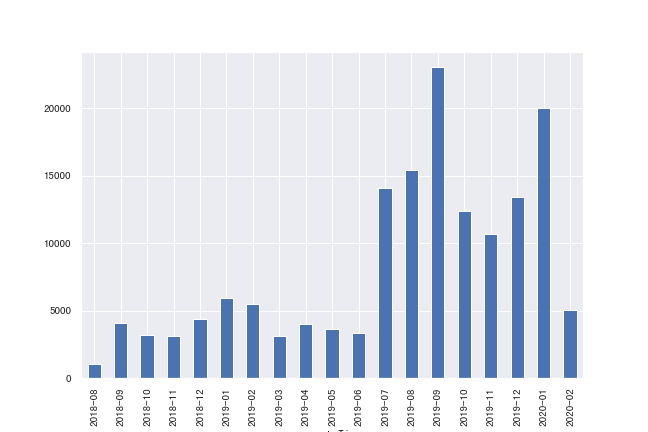
也即,我们可以明显得看出从 2019 年 7 月开始,微信群聊天的记录明显增加 ~ 实际上是自己加入了一些很活跃的聊天群的缘故。
1.2 每周发言情况
weekday_count = message.groupby(lambda x: x.weekday_name)['real_content'].count()
weekday_countFriday 27563
Monday 25577
Saturday 12692
Sunday 10291
Thursday 26028
Tuesday 27318
Wednesday 25938
Name: real_content, dtype: int64weekday_per = weekday_count / weekday_count.sum() * 100
ax = weekday_per.plot.pie(figsize=(6, 6), autopct='%.2f')
ax.set_ylabel('')
plt.title('微信群中一周发言情况')
plt.show()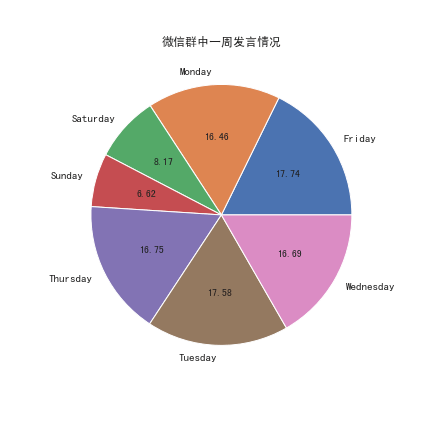
也即,整体而言,微信群中的发言活跃程度工作日明显高于周末。
1.3 一天内发言情况
hour_count = message.groupby(message.index.hour)['real_content'].count()
hour_countcreateTime
0 1994
1 169
2 155
3 15
4 18
...
19 8381
20 7666
21 5600
22 5791
23 3902
Name: real_content, Length: 24, dtype: int64fig = plt.figure(figsize=(10, 8))
plt.step(hour_count.index.values, hour_count.values, where='post')
plt.plot(hour_count.index.values, hour_count.values, 'o--')
plt.xticks(hour_count.index)
plt.xlabel('发言时间')
plt.ylabel('发言次数')
plt.title('微信群中每天发言情况')
plt.show()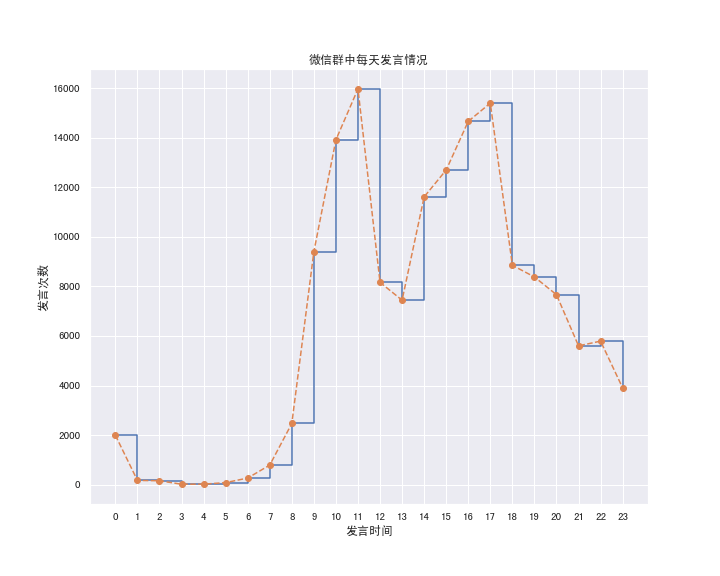
我们发现两个在微信群中发言的高峰期分别出现在 11-12 点以及 17-18 点,大致是在饭点左右,哈哈。
当然,上述三种基于时间的发言计次都是基于所有微信群的,如果要对特定的微信群的聊天时间习惯进行分析,只需将 message.talker 限定为指定的微信群即可。
2 微信群里最受关注的人物
微信群的聊天记录,我们可以依据「聊天是否连续」进行分段,当某个人参与到这段聊天后,这段聊天参与的人数明显增多、聊天记录总量明显变多。我们就认为,这个人在群里受到比较多的关注。
target_group = message.groupby('talker')['real_content'].count().idxmax()
target_message = message[message.talker == target_group]
print('聊天记录最多的微信群:', target_group)
print(' 该群聊天记录总数:', target_message['real_content'].count())聊天记录最多的微信群: 12***92@chatroom
该群聊天记录总数: 796062.1 聊天记录「分段」
选定聊天记录最多的群进行分析,将两次聊天的时间差作为 target_message 的新列 diff_second,设定为 60 秒(实际上就是不太好找拆分的时间点随便选的)。
diff_second = (target_message.index[1:] - target_message.index[0:-1]).values / 1e9
diff_second = diff_second.astype('d')
target_message['diff_second'] = np.concatenate(([0.], diff_second))
len(diff_second[diff_second <= 60]) / target_message['real_content'].count()0.8264578046880888两次聊天间隔在 60 秒以内占比达到 82.65% 左右,拆分时也具备一定的合理性。
target_message['talk_segid'] = np.where(target_message['diff_second'] <= 60, 0, 1).cumsum()
target_message = target_message[['isSend', 'message_type', 'username', 'real_content',
'diff_second', 'talk_segid']]
target_message.talk_segid.value_counts().value_counts().sort_index()1 5370
2 2722
3 1447
4 883
5 539
...
371 1
378 1
527 1
638 1
925 1
Name: talk_segid, Length: 146, dtype: int64借助于 cumsum() 实现分段标记,并选取后续要用到的数据列。也即,有 5370 次聊天与上一句聊天和下一句聊天的时间差均超过 60 秒,占聊天总记录数的 6.75% 左右。连续聊天最长在 925 句。
2.2 发言影响力计算
def impact_factor(df):
'''
计算一段发言中每个人的影响力
'''
impact_list = []
if len(df) == 1:
impact_list.append([df.username.iloc[0], 0, 0])
else:
names = df.username.unique()
for name in names:
# 第一次发言的位置
first_index = np.argmax(df.username == name) - df.index.min()
diff_people = len(df[first_index+1:].username.unique()) - len(df[:first_index+1].username.unique())
diff_talks = len(df) - first_index*2 - 1
impact_list.append([name, diff_people, diff_talks])
# print('第 {} 段对话处理完成'.format(df.talk_segid.iloc[0]))
return pd.DataFrame(impact_list, columns=['username', 'diff_people', 'diff_talks'])计算一个人在这段聊天中第一次发言前后「参与发言人数变化、发言数量变化」。
- 计算发言前后参与聊天的人数差;
- 计算发言前后聊天总量的差;
说明:此处发言前后以一个人在该段聊天中第一次发言为准;聊天密度采用聊天时间间隔平均值。
impact = target_message.reset_index().groupby('talk_segid').apply(impact_factor)
impact_people_mean = impact.groupby('username')['diff_people'].mean()
impact_talks_mean = impact.groupby('username')['diff_talks'].mean()
talks = target_message[['username', 'talk_segid']].drop_duplicates().groupby('username')['talk_segid'].count()分别计算参与聊天的每个人在所有聊天的参与次数 talks,参与每段聊天影响的人数差的均值 impact_people_mean,参与每段聊天影响的聊天记录的均值 impact_talks_mean。
talks = pd.merge(pd.merge(talks, impact_people_mean, left_index=True, right_index=True),
impact_talks_mean, left_index=True, right_index=True)
talks.columns = ['total_talks', 'diff_people_mean', 'diff_talks_mean']
talks| username | total_talks | diff_people_mean | diff_talks_mean |
|---|---|---|---|
| FJ***21 | 20 | -0.950000 | -5.900000 |
| Ha***73 | 32 | -0.093750 | 1.500000 |
| Hx***55 | 1166 | 0.845626 | 9.343911 |
| JA***37 | 76 | -0.828947 | 0.763158 |
| JJ***er | 4 | -2.500000 | -1.500000 |
| … | … | … | … |
| zj***mc | 1 | 11.000000 | 37.000000 |
| zl***69 | 186 | 0.032258 | 2.365591 |
| zs***24 | 11 | 0.727273 | 7.090909 |
| zs***41 | 43 | 0.232558 | 8.209302 |
| zw***247459 | 14 | -0.785714 | -0.214286 |
313 rows × 3 columns
2.3 最受关注人选
fig = plt.figure(figsize=(10, 8))
talks['sqrt_total_talks'] = np.sqrt(talks.total_talks)
sns.scatterplot(x='sqrt_total_talks', y='diff_people_mean', hue='diff_people_mean',
size='diff_people_mean', data=talks)
plt.annotate('target', xy=(5, 10), xytext=(10, 15),
arrowprops=dict(width=1, headwidth=5))
plt.show()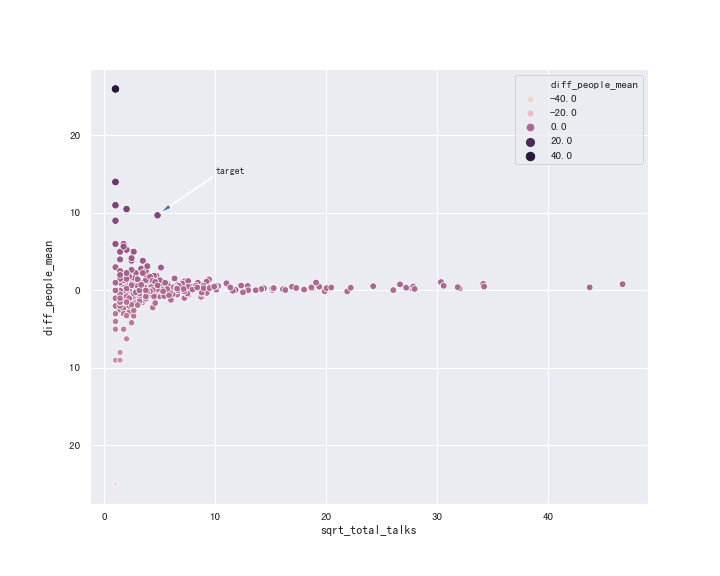
因为群中部分成员很活跃,因此将参与的「聊天段」开方后画散点图。
实际上,计算发言引起的人数差和聊天量差都有一个明显的 bug ~ 如果一个人发言次数很少,并且紧随受大家关注的人发言(或者在热点话题讨论时发言较早),那么相应的 diff_people_mean, diff_talks_mean 值就比较大。
发言次数较多后,发言人是否受到大家的关注用 diff_people_mean, diff_talks_mean 来度量就有一定的合理性了,如两图中 target 点。
fig = plt.figure(figsize=(10, 8))
sns.scatterplot(x='sqrt_total_talks', y='diff_talks_mean', hue='diff_talks_mean',
size='diff_talks_mean', data=talks)
plt.annotate('target', xy=(5, 95), xytext=(10, 150),
arrowprops=dict(width=1, headwidth=5))
plt.show()
print('发言五次及以上最受关注人:', talks[talks.total_talks >= 5]['diff_people_mean'].idxmax())
print('发言五次及以上话题引领人:', talks[talks.total_talks >= 5]['diff_talks_mean'].idxmax())发言五次及以上最受关注人: ad****47
发言五次及以上话题引领人: ad****47也即,'ad****47' 发言后发言的人和发言量都比较多 ~ 实际上这个群也是因他而建立的,与预期相符。
talks.loc['ad****47']total_talks 23.000000
diff_people_mean 9.695652
diff_talks_mean 92.565217
sqrt_total_talks 4.795832
Name: ad814156147, dtype: float64也即,'ad***47' 总共参与 23 次聊天,平均每次聊天后有 9 个多人会出来冒泡、让发言量增加 92 次左右。
最终评选出 'ad****47' 为「整个群里最靓的崽」!
3 聊天的用词偏好
最后,我们利用 target_message 中的聊天记录简单做个词云。主要使用 jieba 进行分词,使用 wordcloud 库绘制词云图。
3.1 分词
chats = target_message[target_message.message_type == '文字']['real_content']
chatscreateTime
2019-07-01 22:04:12+08:00 昨天的图片还在吗
2019-07-01 22:04:17+08:00 各位大佬们
2019-07-01 22:10:03+08:00 出现了
2019-07-01 22:10:20+08:00 ????
2019-07-01 22:10:28+08:00 谢谢
...
2020-02-16 10:30:54+08:00 ??
2020-02-16 10:38:48+08:00 嗯
2020-02-16 10:43:05+08:00 我感觉我回不去了
2020-02-16 11:33:02+08:00 健康码就能进,也不用隔离了。
2020-02-16 11:36:42+08:00 绿的健康码就可以了
Name: real_content, Length: 69171, dtype: object进行分词时仅选择 '文字' 类的聊天记录。
为添加微信表情所转化成的文字添加到字典中,如 '[捂脸], [奸笑], [笑哭]' 等,需对 jieba 库的 __init__.py 文件进行修改,具体可参见 https://github.com/fxsjy/jieba/issues/423.
jieba.load_userdict('wechat_emoji_dict.txt')
jieba.analyse.set_stop_words('stop_words.txt')Building prefix dict from the default dictionary ...
Dumping model to file cache /var/folders/bf/yt56193d35lbzfh4rn_xxct40000gn/T/jieba.cache
Loading model cost 0.966 seconds.
Prefix dict has been built successfully.在词典中添加微信表情符,并去除掉一些停用词,借助于 collections.Counter 简化词频统计。
word_counts = Counter()
for chat in chats:
word_counts.update(jieba.analyse.extract_tags(chat))
word_counts = pd.Series(word_counts)word_counts.sort_values().tail()不是 1402
这个 1787
[奸笑] 1818
可以 1825
[捂脸] 2783
dtype: int643.2 词云制作
借助于 wordcloud 绘制词频最高的两百个词的词云。
wc = WordCloud(font_path='/fontpath/simhei.ttf', background_color="white", repeat=False)
wc.fit_words(word_counts.sort_values()[-200:])
fig, ax = plt.subplots(figsize=(10, 8))
ax.axis('off')
ax.imshow(wc)
那我们微信群聊天记录分析就到这里啦。
4 参考资料
- 韦阳的博客, 韦阳, 微信聊天记录导出为电脑txt文件教程, 2020/3/2.
- hangcom写字的地方, hangcom, 微信聊天记录导出–发布, 2020/3/2.
- Asher117, 【Python】DataFrame一列拆成多列以及一行拆成多行, 2020/3/2.
- 风浅安然, Matplotlib及Seaborn中文显示问题, 2020/3/2.
- alpiny, 【分享】好多人需要的:关键词带空格和特殊字符方法~~, 2020/3/9.
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu



