
Tensorflow-keras 理论 & 实战
0 / 2 / 创建于 6年前 /
 Galois 的个人博客
Galois 的个人博客
理论部分
Keras:
- 基于 python 的高级神经网络 API
- Francois Chollet 与 2014-2015 年编写 Keras
- 以 Tensorflow、CNTK、Theano 为后端运行,keras 必须有后端才可以运行(现在一般多用 tensorflow)
- 极方便与快速实验,帮助用户以最少的时间验证自己的想法
Tensorflow-keras:
- Tensorflow 对 keras API 规范的实现
- 相对于以 tensorflow 为后端的 keras,Tensorflow-keras 与Tensorflow 结合更加紧密
- 实现在 tf.keras 空间下
Tf-keras 和 keras 联系:
- 基于同一套 API(keras程序可以通过改导入方式轻松转为 tf.keras 程序;反之可能不成立,因为 tf.keras 有其他特性)
- 相同的 JSON 和 HDF5 模型序列化格式和语义
Tf-keras 和 keras 区别:
- Tf.keras 全面支持 eager mode
- 只是用 keras.Sequential 和 keras.Model 时没影响
- 自定义 Model 内部运算逻辑的时候会有影响
- Tf 底层 API 可以使用 keras 的 model.fit 等抽象
- 适用于研究人员
- Tf.keras 支持基于 tf.data 的模型训练
- Tf.keras 支持 TPU 训练
- Tf.keras 支持 tf.distribution 中的分布式策略
- 其他特性
- Tf.keras 可以与 Tensorflow 中的 estimator 集成
- Tf.keras 可以保存为 SavedModel
如果想用 tf.keras 的任何一个特性,那么选 tf.keras
如果后端互换性很重要,那么选 keras,如果都不重要,随便选。
分类问题、回归问题、损失函数
分类问题
分类问题预测的是类别,模型的输出是概率分布。
三分类问题输出例子:[0.2, 0.7, 0.1]
比如
- 第 0 类是「猫」类,
- 第 1 类是「狗」类,
- 第 2 类是「狼」类。
为什么分类问题的模型输出是概率分布,这里涉及到知识点「目标函数」
回归问题
回归问题预测的是值,模型的输出是一个实数值。
比如房价预测问题,就属于回归问题,房价是一个值。
目标函数
为什么需要目标函数?
- 参数是逐步调整的(不像数学的计算问题,可以直接得到值,机器学习中需要目标函数逐步调整参数来逼近准确值)
- 分类问题举例:目标函数可以帮助衡量模型的好坏(模型A 和 模型B 的准确率没有区别,但 模型A 比 模型B 更接近正确结果)
- Model A:[0.1, 0.4, 0.5]
- Model B:[0.1, 0.2, 0.7]
分类问题需要衡量目标类别与当前预测的差距
- 三分类问题输出例子:[0.2, 0.7, 0.1]
- 三分类真实类别:2 -> one_hot -> [0, 0, 1]
One-hot 编码:把正整数变为向量表达
生成一个长度不小于正整数的向量,只有正整数的位置处为 1,其余位置都为 0。
目标函数-分类问题
「平方差损失」,x,y都是向量,对应位置相减。
\displaystyle \frac{1}{n}\sum_{x,y}\frac{1}{2}(y-Model(x))^2
「交叉熵损失」,Model(x)是预测值。
\displaystyle \frac{1}{n}\sum_{x,y}y\ln(Model(x))
分类问题的平方差损失举例:
- 预测值:[0.2, 0.7, 0.1]
- 真实值:[0, 0, 1]
- 损失函数值:[(0.2-0)^2 + (0.7-0)^2 + (0.1-1)^2]*0.5
由于预测值只有 1 个,所以 1/n = 1/1 = 1
目标函数-回归问题
- 预测值与真实值的差距
- 平方差损失
- 绝对值损失
「绝对值损失」\displaystyle \frac{1}{n}\sum_{x,y}\big|y-Model(x)\big|
模型的训练就是调整参数,使得目标函数逐渐变小的过程。
实战:Keras 搭建分类模型,Keras 搭建回调函数, Keras 搭建回归模型。
神经网络、激活函数、批归一化、Dropout
神经网络
先看下三层神经网络的案例: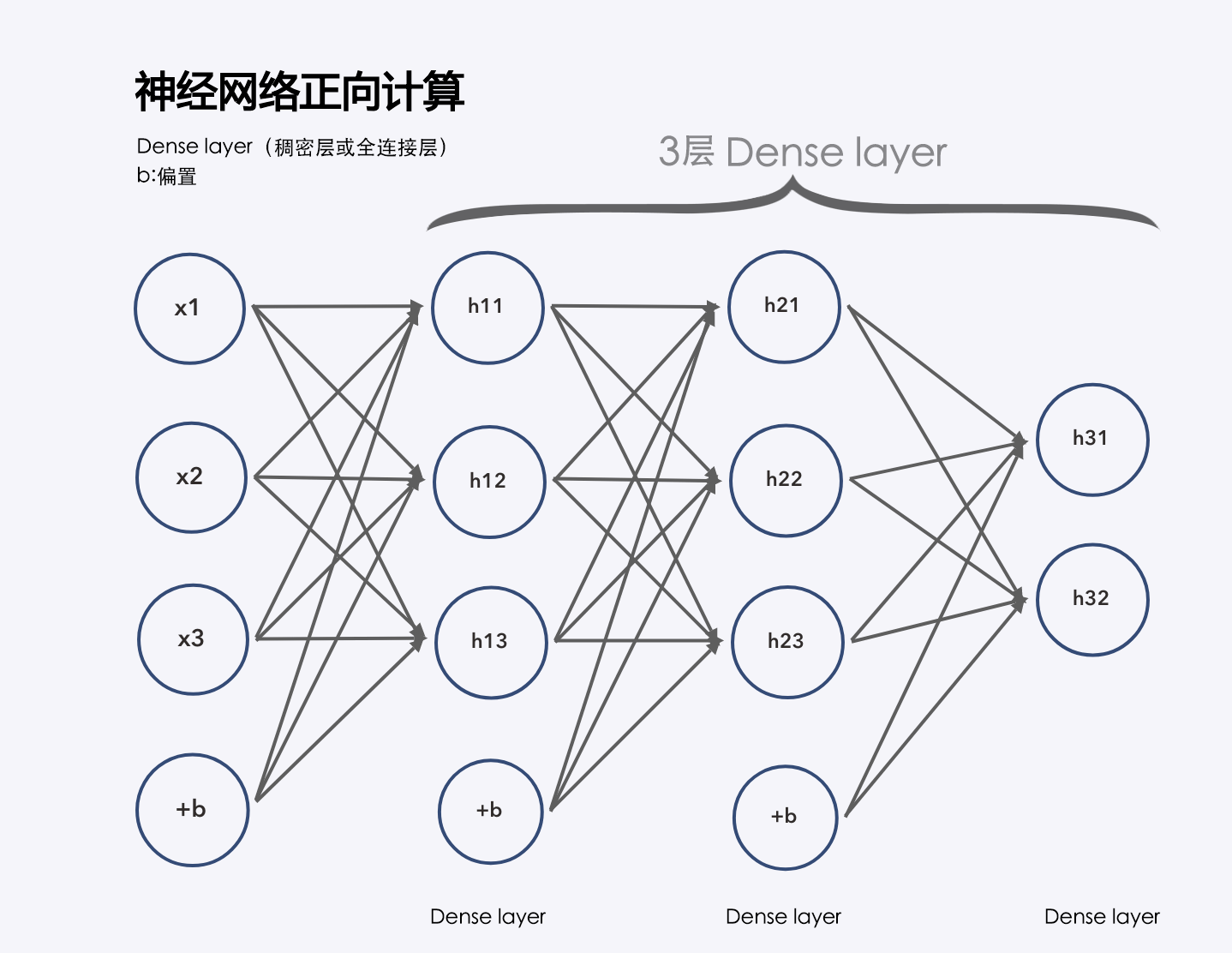
全连接层指的是层级结构中,下一层的神经单元都和上一层的神经单元相连接。
当然,每一层计算完毕之后都会用到「激活函数」:
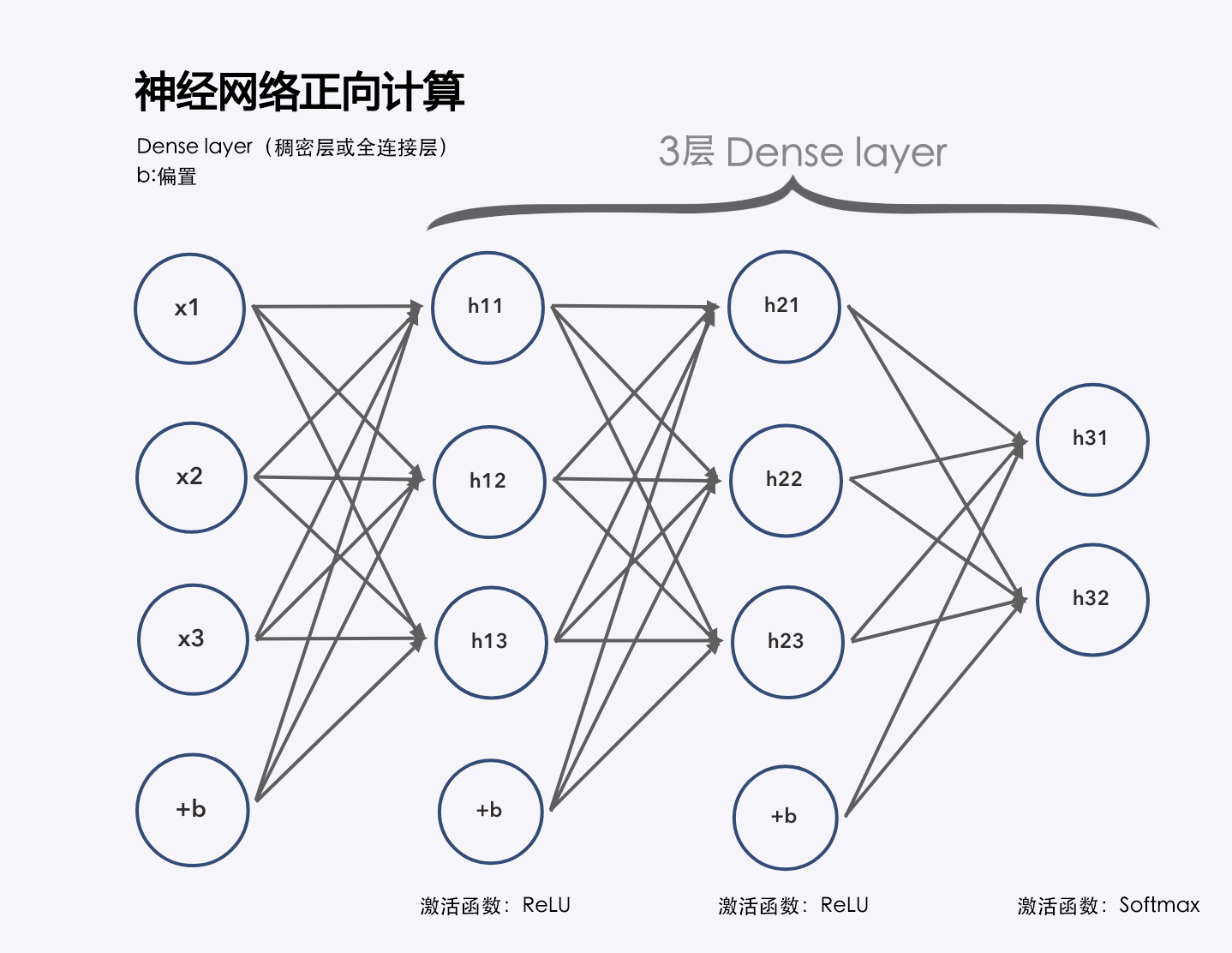
神经网络训练
神经网络训练使用「梯度下降」:
- 梯度下降
- 求导
- 更新参数
我们可以形象的想象一下“下山算法”:
- 下山算法
- 找到方向
- 走一步
深度神经网络
深度学习就是层次非常深的神经网络,以上我们看到的都是层次比较浅的神经网络,只有三层,如果有几十几百层的神经网络就叫做深度神经网络。
激活函数
我们先介绍 6 种激活函数:
Sigmoid:
\displaystyle \sigma(x)=\frac{1}{1+e^{-x}}
tanh:
\tanh(x)
ReLU
\max(0,x)
Leaky ReLU:
\max(0.1x,x)
Maxout:
\max(w_1^Tx+b_1,w_2^Tx+b_2)
ELU:
\displaystyle \left\{ \begin{aligned} x && x\geqslant0\\ \alpha(e^x-1) && x<0 \end{aligned} \right.
激活函数图:
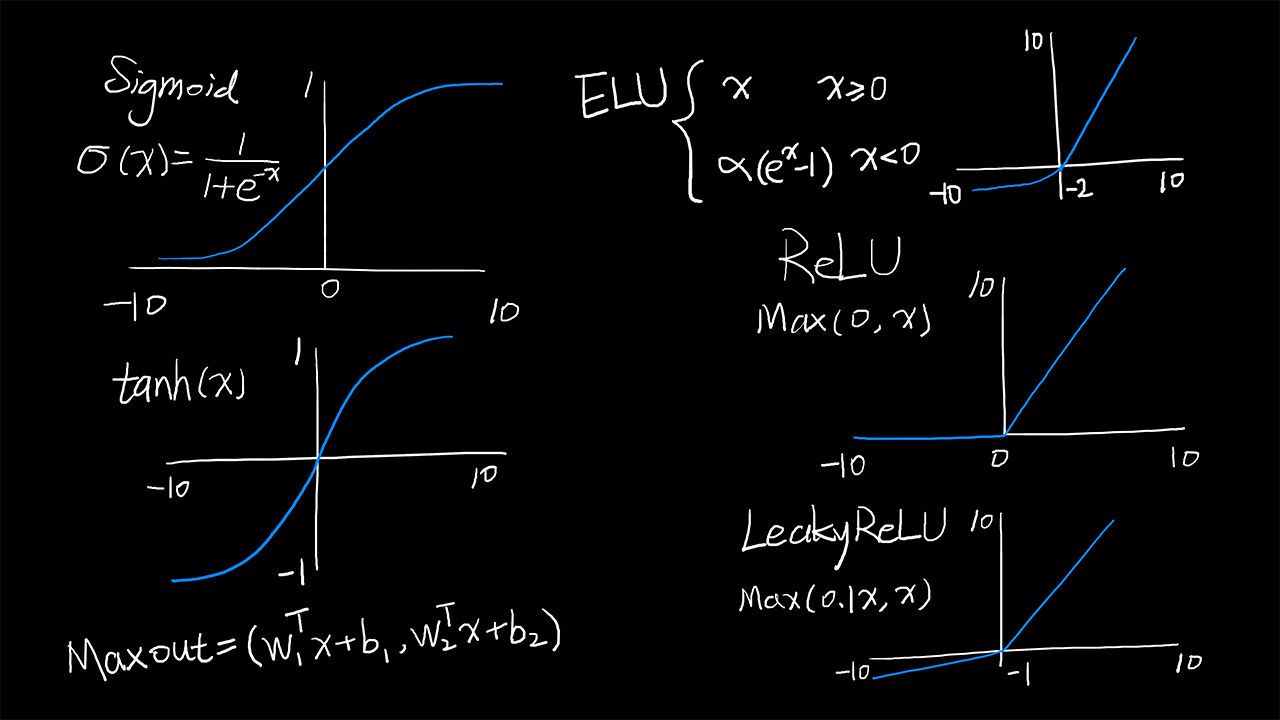
归一化
归一化是把输入数据做一个规整,使输入数据均值为 0,方差为 1。
还有一些其他归一化:
- Min-Max 归一化:
\displaystyle x^*=\frac{x-\min}{\max-\min}
- Z-score 归一化:
\displaystyle x^*=\frac{x-\mu}{\sigma}
批归一化
每层的激活值都做归一化,把归一化的范围从输入数据拓展到每层激活值。
归一化为何有效?
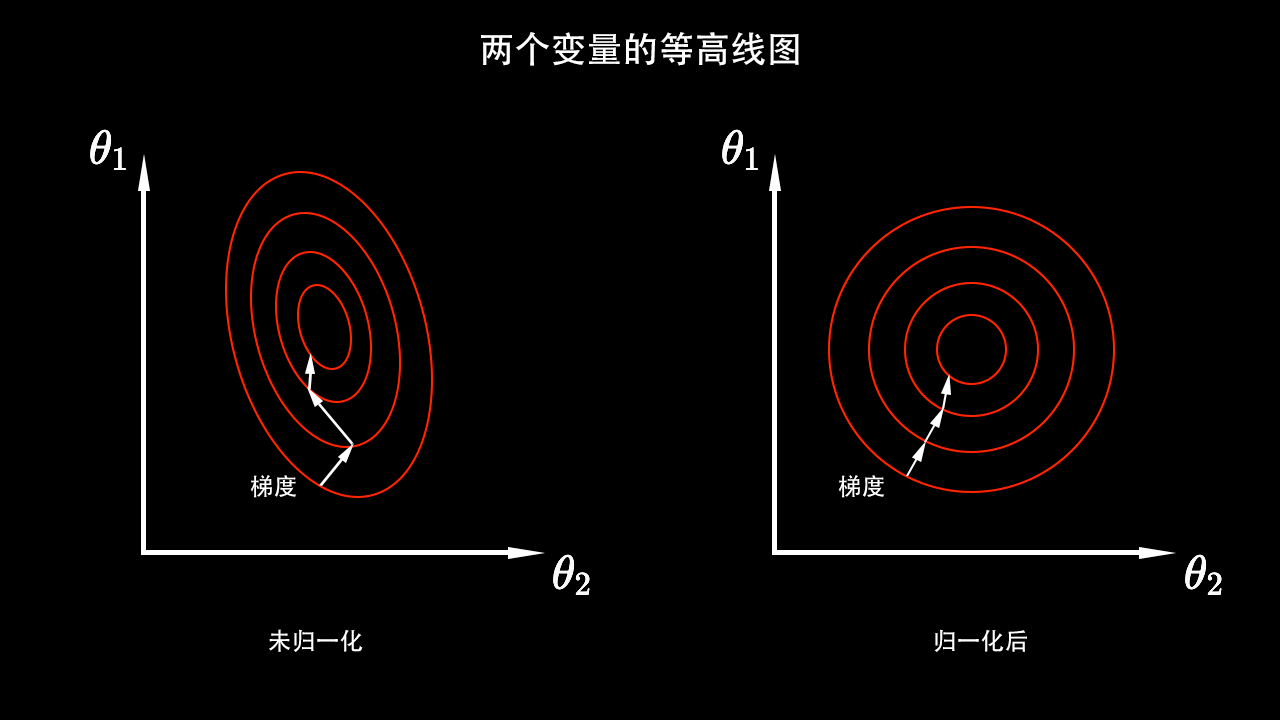
回顾梯度下降算法:在当前状态下给每一个变量都求一个导数,然后在这个导数的方向上把参数更新一点。上图的未归一化的两个变量\theta_1和\theta_2的数据范围是不一样的,所以等高线看起来像是个椭圆,因为它是个椭圆,所以当在椭圆上计算梯度「法向量」的时候,它指向的并不一定是圆心,所以会导致训练轨迹会非常曲折。经过归一化的数据等高线是一个正圆,这意味着「法向量」都是对着圆心的,所以归一化之后,它的训练速度会更快。这是归一化有效的一个原因。
Dropout
Droutout 在深度神经网络中会用到。
除了 Dropout 来降拟合,还可以用正则化 regularizer 来降低过拟合。
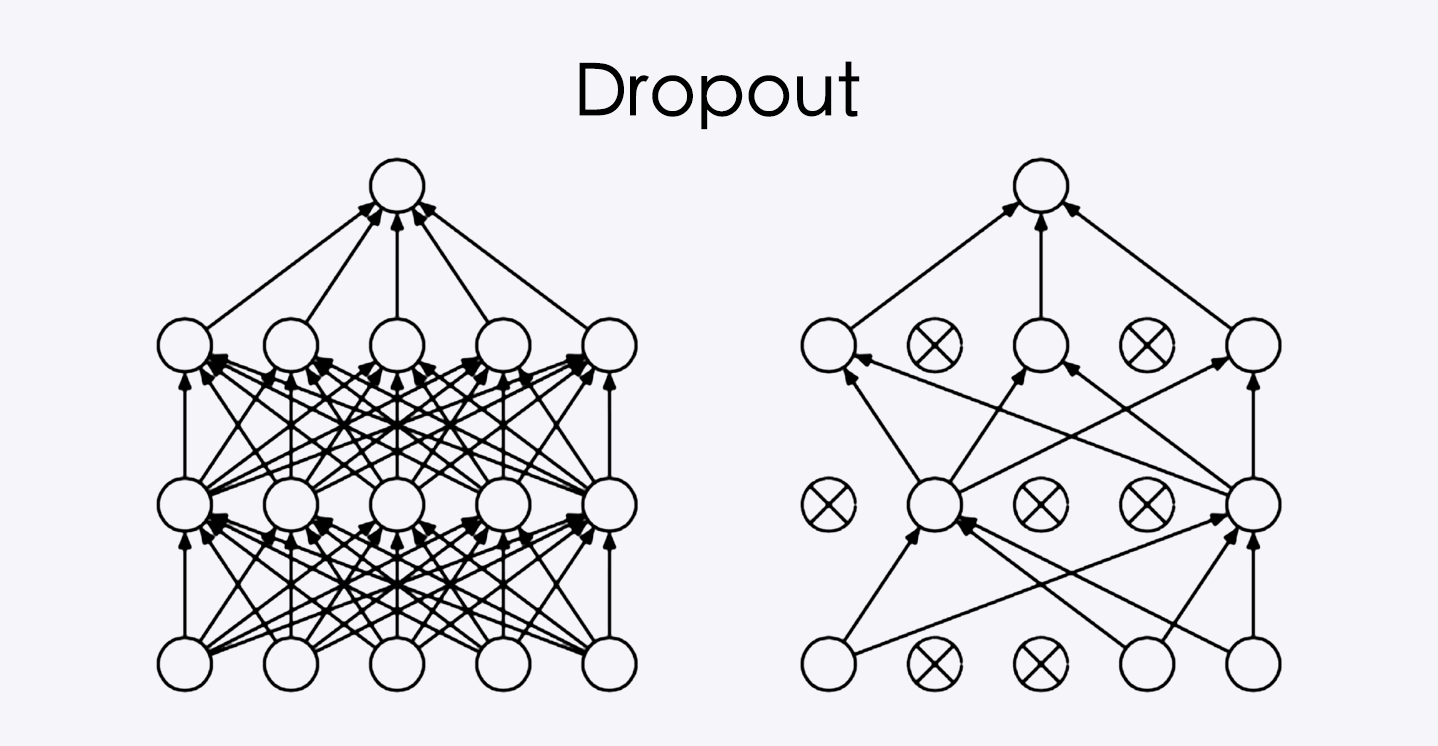 可以看到 Dropout 在全连接层随机弃用一些神经单元,而且每层的弃用都不一样的,弃用是随机性的。
Dropout 作用:
- 防止过拟合(训练集上很好,测试集上不好)
- 过拟合原因:模型参数太多,模型容易记住样本,不能泛化
当样本输入的时候,每层激活的值都非常大,就容易导致模型记住样本。
可以看到 Dropout 在全连接层随机弃用一些神经单元,而且每层的弃用都不一样的,弃用是随机性的。
Dropout 作用:
- 防止过拟合(训练集上很好,测试集上不好)
- 过拟合原因:模型参数太多,模型容易记住样本,不能泛化
当样本输入的时候,每层激活的值都非常大,就容易导致模型记住样本。
实战:Keras 实现深度神经网络,Keras 更改激活函数, Keras 实现批归一化,Keras 实现 dropout。
Wide & Deep 模型
Wide & Deep 模型在 16 年发布,用于分类和回归,应用到了 Google Play 中的应用推荐,原始论文:提取码:a8rg
稀疏特征
- 离散值特征
- One-hot 表示
- Eg:专业 = {计算机, 人文, 其他},人文 = [0, 1, 0]
- Eg:词表 = {人工智能,你,我,他,张量,…},他 = [0, 0, 0, 1, 0, …]
- 稀疏特征之间可以做「叉乘」= {(计算机, 人工智能), (计算机, 你), …}
- 稀疏特征做叉乘获取共现信息
- 实现记忆的效果
稀疏特征优点:有效,广泛用于工业界。
稀疏特征缺点:需要人工设计;可能过拟合,所有特征都叉乘,相当于记住每一个样本;泛化能力差,没出现过就不会起效果。
例:组合问题,我很高兴和我很快乐是一个意思,不能泛化。
密集特征
向量表达:
- Eg:词表 = {人工智能, 你, 他, 愣酷},他 = [0.3, 0.2, 0.6, (n维向量)]
- Word2vec 工具
- 男 - 女 = 国王 - 王后
密集特征的优点:带有语义信息,不同向量之间有相关性;兼容没有出现过的特征组合;更少人工参与。
密集特征缺点:过度泛化,推荐不怎么相关的产品。
说明完毕,来看模型:
这是 Wide&Deep 模型的通用结构。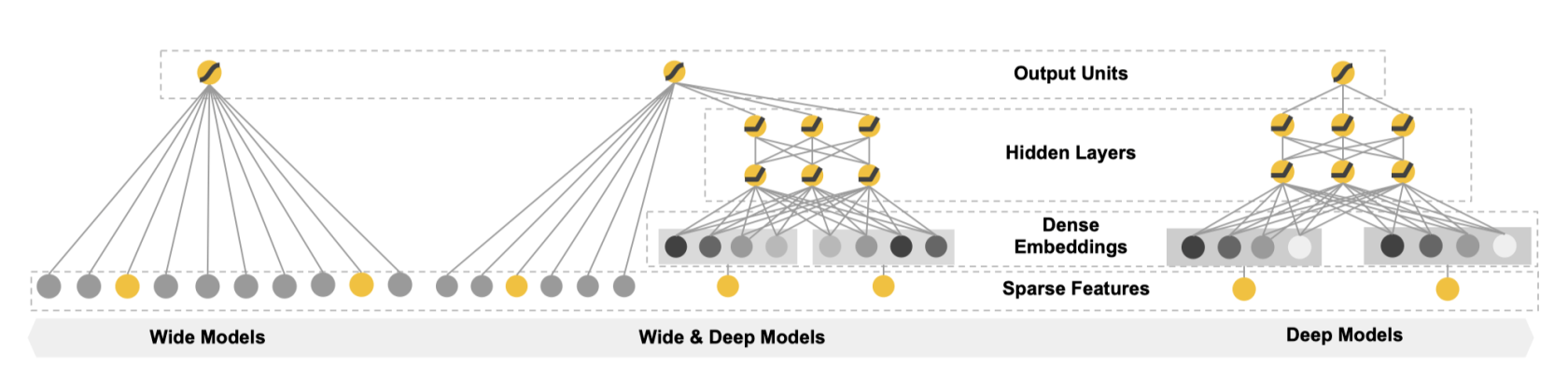
这是 Google play上的应用推荐算法的模型图。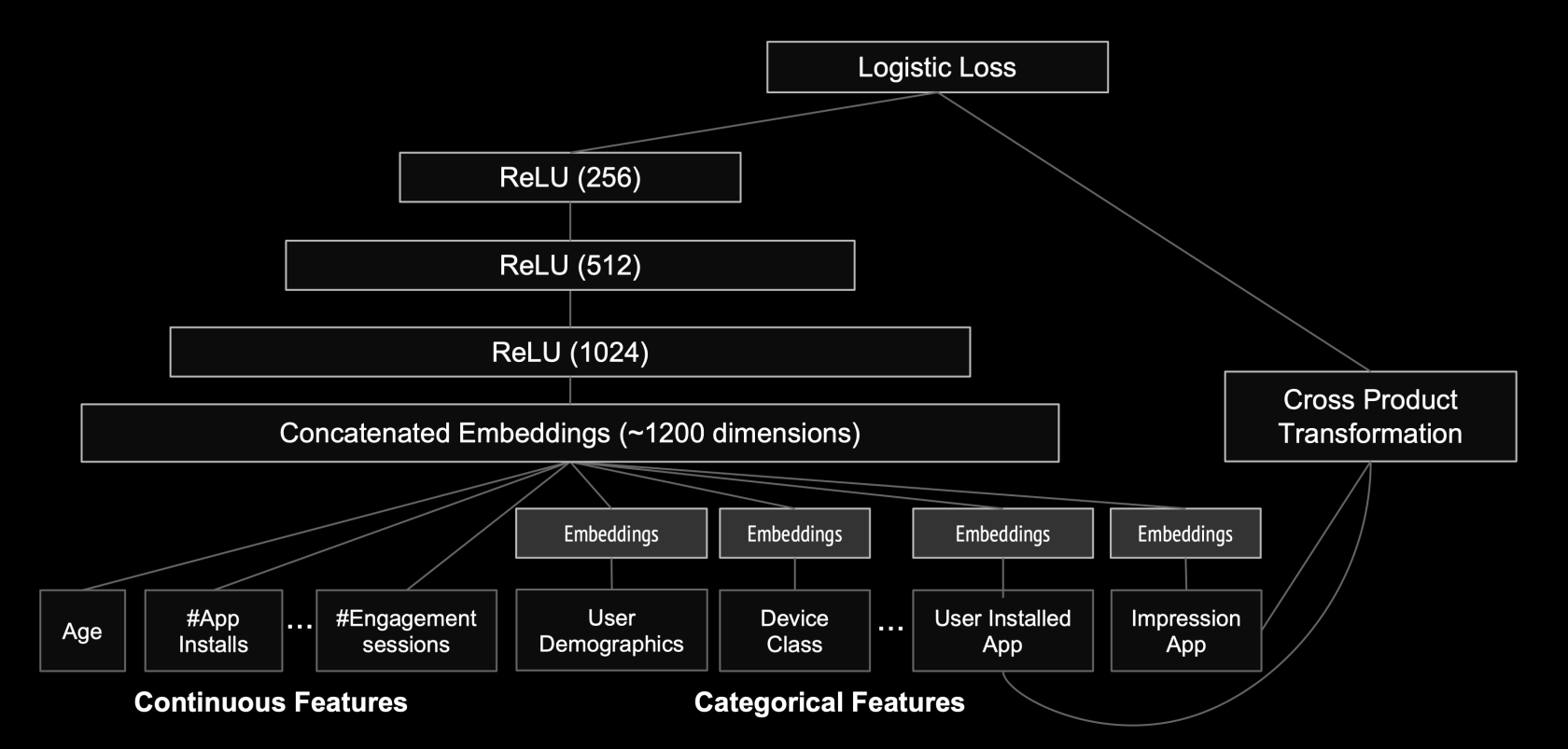
实战:子类API,功能API(函数式API),多输入与多输出。
超参数搜索
超参数用手工去试耗费人力
- 神经网络有很多训练过程中不变的参数
- 网络结构参数:层数,每层宽度,每层激活函数等
- 训练参数:batch_size,学习率,学习率衰减算法等
batch_size 指的是一次训练从训练数据中选多少数据塞到神经网络中去。
搜索策略
- 网格搜索
- 随机搜索
- 遗传算法搜索
- 启发式搜索
网格搜索
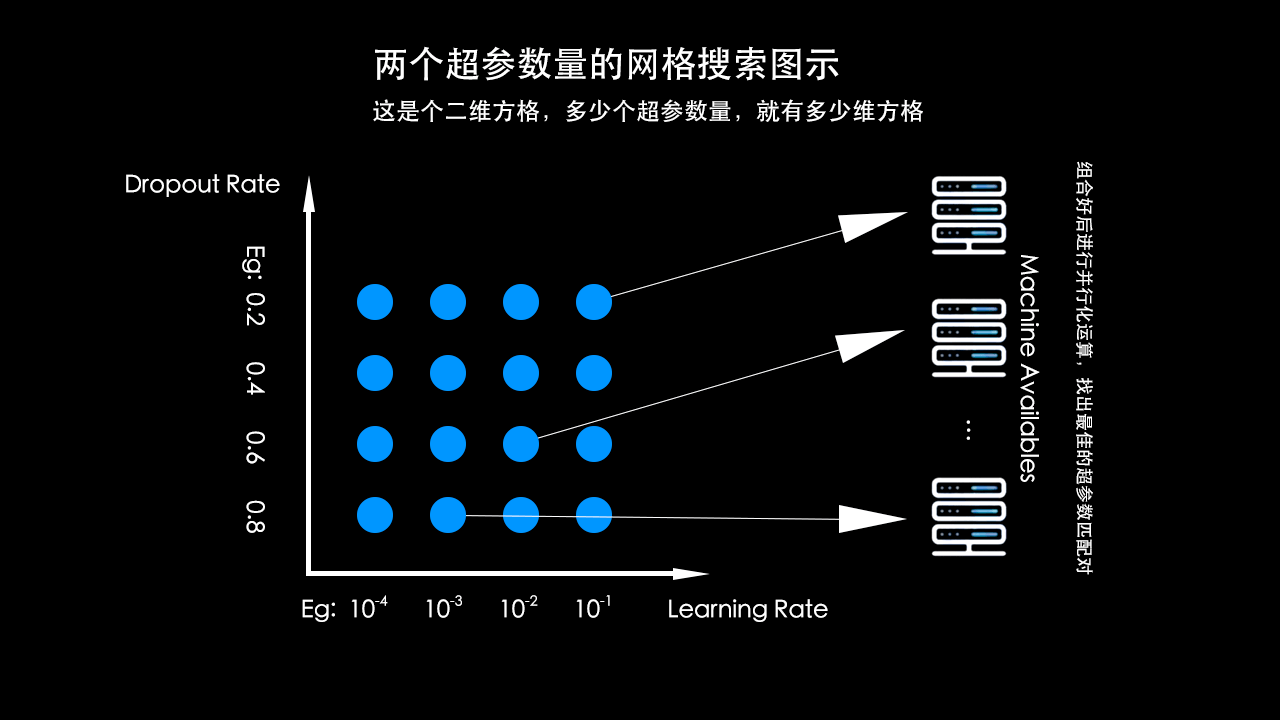
网格搜索步骤:
- 定义 n 维方格
- 每个方格对应一组超参数
- 一组一组参数尝试
随机搜索
网格搜索有个缺点,都只能取几个固定的值,比如上面的网格搜索图示中取了 DropoutRate = [0.2, 0.4, 0.6, 0.8],但如果最优值是 0.5 那么我们的网格搜索将永远不可能找到最优解。
随机搜索的两个好处:
- 参数的生成方式为随机
- 可探索的空间更大
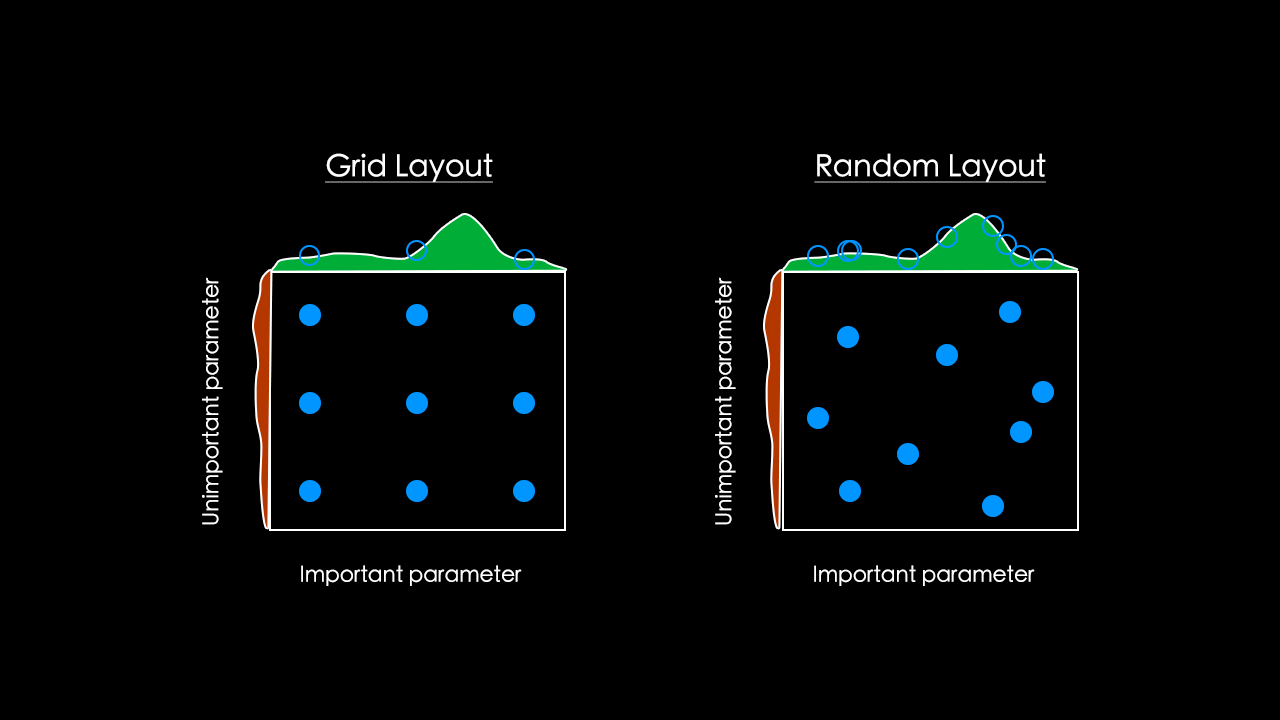
遗传算法
遗传算法是对自然界的模拟
A. 初始化候选参数集合 -> 训练 -> 得到模型指标作为生存概率
B. 选择 -> 交叉 -> 变异 -> 产生下一代集合
C. 重新到 A
启发式搜索
- 研究热点-AutoML
- 循环神经网络来生成参数
- 使用强化学习来进行反馈,使用模型来训练生成参数
实战:使用 scikit 实现超参数搜索。
实战部分
为了方便阅读代码,以下所有代码都是在 JupyterNotebook 上的,每个代码块记得执行代码。
Keras 搭建分类模型
来做个图像分类,数据集用:fashion_mnist。(以前学过深度学习的人都对 mnis 不陌生,mnis 就是个手写字体图像数据。)
数据读取与展示
导入库:
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)输出:
2.1.0
sys.version_info(major=3, minor=6, micro=4, releaselevel=’final’, serial=0)
matplotlib 2.2.3
numpy 1.18.1
pandas 0.22.0
sklearn 0.19.1
tensorflow 2.1.0
tensorflow_core.python.keras.api._v2.keras 2.2.4-tf
导入数据:
fashion_mnist = keras.datasets.fashion_mnist把训练集和测试集都拆分出来:
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()再把训练集拆分成训练集和验证集,因为这个数据集有 60000 张图片,所以我们把前 5000 张图片作为验证集,后面 55000 张作为训练集:
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
# 现在打印一下验证集, 训练集, 测试集
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# 输出
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)得到图像数据集后,需要看下图像是什么样子,这样有助于了解数据集,了解数据集是机器学习工作中很重要的一部分。
接下来定一个函数用作展示图像:
def show_single_image(img_arr):
plt.imshow(img_arr, cmap="binary")
plt.show()
# 调用函数显示第 1 张图片
show_single_image(x_train[0])我们会看到这样一张图片:

只显示一张图片可能不是那么直观,定义一个显示多图像显示的函数:
def show_imgs(n_rows, n_cols, x_data, y_data, class_name):
assert len(x_data) == len(y_data)
assert n_rows * n_cols < len(x_data)
plt.figure(figsize = (n_cols * 1.4, n_rows * 1.6))
for row in range(n_rows):
for col in range(n_cols):
index = n_cols * row + col
plt.subplot(n_rows, n_cols, index+1)
plt.imshow(x_data[index], cmap="binary", interpolation="nearest")
plt.axis('off')
plt.title(class_names[y_data[index]])
plt.show()
class_names = ['T-shirt', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# 调用函数显示 15 张图片
show_imgs(3, 5, t_train, y_train, class_names)模型构建
使用 tf.keras.models.Sequential() 来构建模型。
# 初始化训练模型
model = keras.models.Sequential()
# 模型添加层
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
"""
其实添加模型可以用另一种写法(直接在模型初始化中设置模型层):
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation='relu'),
keras.layers.Dense(100, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
"""
# 有了以上的概率分布,就可以用目标函数了
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])Flatten:展平,keras.layers.Flatten(input_shape[28, 28]) 把二维向量(28x28)展成一维向量(1x784)。keras.layers.Dense(300, activation="relu") 意思是神经元数量为 300,激活函数为 ReLU 的全连接层。
最后一层作为输出层,设置 10 个输出节点,因为这个问题是个 10 个类别的分类问题。
relu:y = max(0, x)
softmax 是将向量变成概率分布:
\displaystyle x = [x_1,x_2,x_3]\\{}\\ y = \left[\frac{e^{x_1}}{\Sigma},\frac{e^{x_2}}{\Sigma},\frac{e^{x_3}}{\Sigma}\right]\\{}\\ \sum=e^{x_1}+e^{x_2}+e^{x_3}
model.compile 中:loss 是损失函数属性,属性值 crossentropy 是交叉熵损失函数,我们的y是长度等于样本数的向量,对于每个样本来说只是「一个值」,y 是一个 index 值,所以用 sparse_categorical_crossentropy,如果 y 是通过 one_hot 输出的向量,那这里就用 categroical_crossentropy。optimizer 是模型调整方法(优化方法),我们需要调整参数使得目标函数越来越小。metrics 是把 loss、optimizer 都加入到模型图中去。
查看模型层数:
model.layers查看模型概况:
model.summary()我们看到第一层(Flatten 层)是样本数乘以 784 的矩阵,经过全连接层之后变成样本数乘以 300 的矩阵:[None, 784] -> [None, 300],这需要让 [None, 784] 乘以一个矩阵 W,在全连接层里面加一个偏置 b,W.shape=[784, 300],b 是长度为 300 的一个向量,所以第二层长度是 784x300+300 = 235500。
模型设计好了,接下来开启训练:
history = model.fit(x_train, y_train, epochs=10, validation_data=(x_valid, y_valid))其中 x_train, y_train 是训练集,epochs 是训练次数,validation_data 是每次训练的验证,验证数据用的是 x_valid, y_valid。model.fit 可以返回值,把数据结果返回给 history。
训练完毕,我们可以看下 type(history),history 是一个 tensorflow.python.keras.callbacks.History。
查看训练的准确率与误差的历史数据:
history.history我们可以打印训练的准确率与误差的统计图:
def plot_learning_curves(history):
# 把训练指标数据转成 pd.DataFrame 格式
pd.DataFrame(history.history).plot(figsize=(8, 5))
# 显示网格
plot.grid(True)
# 设置坐标轴范围
plot.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)这样就完成了一个完整的分类模型:数据处理 -> 模型构建 -> 模型训练 -> 指标图示打印。
在「图像分类」领域有一个非常有助于提升准确率的手段:归一化(对训练数据进行操作)。
归一化
接着上例的代码的数据处理后面做归一化:
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)归一化方法:
\displaystyle x=\frac{x-\mu}{\sigma^2}
\mu均值,\sigma^2方差。
可以用 print(np.max(x_train), np.min(x_train)) 查看训练集的最大值最小值,会打印出最大值 255,最小值 0。
用 sklearn.preprocessing 里面的 StandardScaler 来实现归一化:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 训练集归一化用 fit_transform
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
# 验证集测试集归一化用 transform
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)归一化涉及到除法,所以先将数据转为 float32。
现在可以 print(np.max(x_train_scaled), np.min(x_train_scaled)) 打印看看归一化后的训练集最大值最小值。
然后设置训练模型后训练归一化后的数据:
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation='relu'),
keras.layers.Dense(100, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer = "sgd",
metrics = ["accuracy"])
# 训练归一化后的数据:
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_valid, y_valid))最后打印学习曲线图:
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plot_learning_curves(history)可以与之前未归一化的训练指标对比下。
继续在测试集上进行指标的评估:
model.evaluate(x_test_scaled, y_test)Keras 回调函数
回调函数在 TensorFlow for Python API 官方文档 的 tf.keras 下的 callbacks 里,回调函数是作用在训练模型中的操作。涉及到一些 callbacks,不过常用的是 EarlyStopping、ModelCheckpoint、TensorBoard。其中 EarlyStopping 是在模型训练过程中 Loss 不再下降的时候,可以中止训练。下面就展示下这三个 callback 的用法。
因为这是作用域训练过程中的操作,所以直接把上面归一化的例子中的训练部分代码拿下来:
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_valid, y_valid))修改成:
# 定义文件夹
logdir = './callbacks'
if not os.path.exists(logdir):
os.mkdir(logdir)
# 定义输出的 Model 文件
output_model_file = os.path.join(logdir, "fashion_mnist_model.h5")
# 定义 callbacks
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(out_model_file, save_best_only=True) # save_best_only:保存最好的模型,不设置的话,默认保存最近的一个模型
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_valid, y_valid), callbacks=callbacks)对于 Tensorboard 来说,需要一个文件夹;对于 ModelCheckpoint 来说,需要一个文件名。Earlystopping 中有三个重要的属性 monitor、min_delta、patience。monitor 设置关注指标,一般关注验证集上,目标函数的值。min_delta 是一个阈值,这次的训练与上次的训练的差距,如果比这个阈值高的话,就不用 EarlyStopping,如果比这个阈值低的话,就会用上 EarlyStopping 提前停止训练。patience 表示 EarlyStopping 的耐心,设置允许低于阈值的次数,超出次数了,就会中止训练。
运行后,我们在项目目录下使用 tree 命令来打印目录结构,会发现 callbacks 文件夹内多出了一些文件:ModelCheckpoint 文件:fashion_mnist_model.h5
还有两个文件夹 train、validation 存储的是 TensorBoard 的文件。
然后在当前项目下打开 Tensorboard:
$ tensorboard --logir=callbacks然后用浏览器访问 localhost:6006 会看到 Tensorboard 的界面。
Keras 搭建回归模型
这是个房价预测问题。
数据集:
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
# 数据集
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.target.shape)
# 打印了解数据
import pprint
pprint.pprint(housing.data[0:5])
pprint.pprint(housing.target[0:5])数据集划分:
from sklearn.model_selection import train_test_split
x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data, housing.target, random_state=7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all, random_state=11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)数据归一化:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.fit_transform(x_valid)
x_test_scaled = scaler.fit_transform(x_test)模型构建:
model = keras.models.Sequential([
keras.layers.Dense(30, activation='relu', input_shape=x_train.shape[1:]),
keras.layers.Dense(1),
])
model.summary()
model.compile(loss="mean_squared_error", optimizer="sgd")
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]训练数据:
history = model.fit(x_train_scaled, y_train, validation_data=(x_valid_scaled, y_valid), epochs=100, callbacks=callbacks)学习曲线图:
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)测试集评估模型:
model.evaluate(x_test_scaled, y_test)Keras 搭建深度神经网络
把分类模型搭建的代码块改成:
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
# 搭建 20 层神经网络
for _ in range(20):
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])然后可以看下模型的 summary():
model.summary训练时,可以把这个深度神经网络的 Tensorboard 文件夹定义在 logdir = './dnn-callbacks'。
可以看到 Tensorboard 显示学习曲线图:
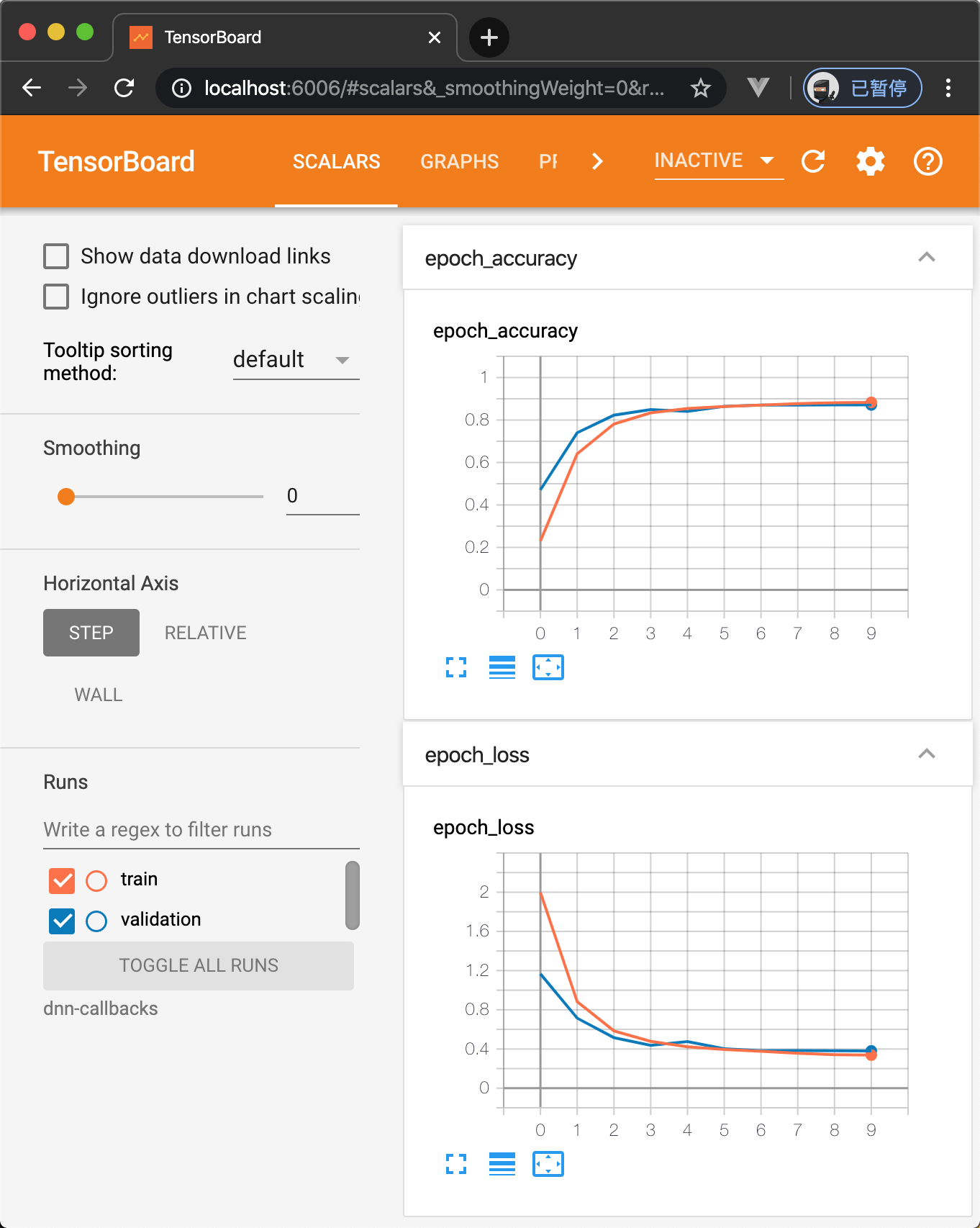
或者直接用脚本打印:
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 3)
plot_learning_curves(history)
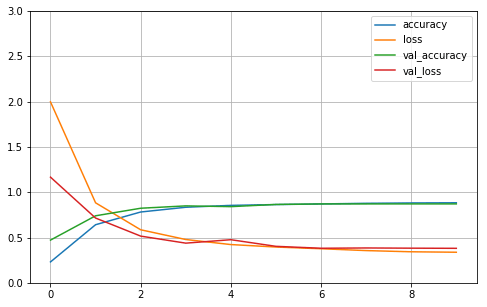 可以看到这个学习曲线图有点不一样,后面接近平滑,那是因为我们的深层神经网络(20 层 Dense layer)参数众多,导致训练不充分,以及「梯度消失」,梯度消失一般发生在深度神经网络里,导致梯度消失的原因是「链式法则」,用在复合函数求导上面。
可以看到这个学习曲线图有点不一样,后面接近平滑,那是因为我们的深层神经网络(20 层 Dense layer)参数众多,导致训练不充分,以及「梯度消失」,梯度消失一般发生在深度神经网络里,导致梯度消失的原因是「链式法则」,用在复合函数求导上面。
对于多层神经网络来说,离目标函数比较远的底层神经网络的梯度比较微小的一个现象叫做「梯度消失」。
复合函数:f(g(x))
测试集指标评估:
model.evaluate(x_test_scaled, y_test)评估结果:
10000/10000 [==============================] - 0s 43us/sample - loss: 0.4111 - accuracy: 0.8619
[0.4111427655220032, 0.8619]
批归一化
在激活后批归一化:
model = keras.models.Sequential()
model.add(keras.layes.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="relu"))
# 批归一化
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])在激活前批归一化:
model = keras.models.Sequential()
model.add(keras.layes.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100))
# 批归一化
model.add(keras.layers.BatchNormalization())
# 激活函数
model.add(keras.layers.Activation('relu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])model.summary 后可以看到批归一化的层次结构。
批归一化能缓解「梯度消失」。
自带归一化的激活函数 Selu
model = keras.models.Sequential()
model.add(keras.layes.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="selu"))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])logdir = './dnn-selu-callbacks'
学习曲线图:
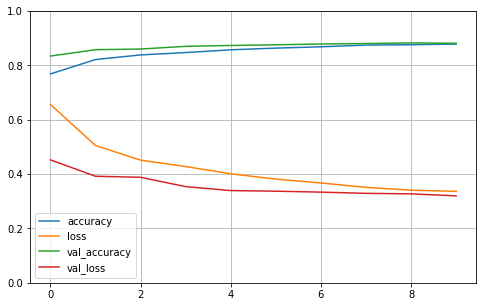
可以看到 Selu 比 Relu+归一化 训练快一些,指标也很快 进入状态了。
Dropout
一般情况下,不会给每一层都做 Dropout,而是给最后几层做 Dropout。
model = keras.models.Sequential()
model.add(keras.layes.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="selu"))
# Dropout 相当于对前面一层作 Dropout
model.add(keras.layers.AlphaDropout(rate=0.5))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])纯「Dropout」是:model.add(keras.layers.Dropout(rate=0.5))。AlphaDropout 是一个更加强大的「Dropout」:
- 均值和方差不变
- 归一化的性质也不变
如果数据过拟合比较轻,不适合作 Dropout 处理,Dropout 是针对缓解数据过拟合的。
函数式 API 实现 Wide&Deep 模型
直接看上面的房价预测回归模型的代码块:
model = keras.models.Sequential([
keras.layers.Dense(30, activation='relu', input_shape=x_train.shape[1:]),
keras.layers.Dense(1),
])
model.summary()由于 Wide&Deep 模型不是严格的层级结构,而是由两部分组成的,每一部分都是一个层级结构,所以我们不能用 Sequential 去实现模型了。所以我们用函数式 API 对模型进行实现。
# 函数式API 功能API
input = keras.layers.Input(shape=x_train.shape[1:]) # 读取数据
hidden1 = keras.layers.Dense(30, activation='relu')(input) # (input)之前的可以看作是一个函数,input 是这个函数的输入参数
hidden2 = keras.layers.Dense(20, activation='relu')(hidden1)
# 复合函数形式:f(x) = h(g(x))
# 输出之后需要合并模型,这里我们假设 Wide模型 和 Deep模型 是一样的
concat = keras.layers.concatenate([input, hidden2]) # 拼接 input 和 hedden2
output = keras.layers.Dense(1)(concat) # 把拼接好的数据赋给 output
# 函数式API 写法需要用 keras.models.Model() 固化模型
model = keras.models.Model(inputs = [input], outputs = [output])子类 API 实现 Wide&Deep 模型
# 子类API
class WideDeepModel(keras.models.Model):
def __init__(self):
super(WideDeepModel, self).__init__()
"""定义模型的层次"""
self.hidden1_layer = keras.layers.Dense(30, activation='relu')
self.hidden2_layer = keras.layers.Dense(30, activation='relu')
self.output_layer = keras.layers.Dense(1)
def call(self, input):
"""完成模型的正向计算"""
hidden1 = self.hidden1_layer(input)
hidden2 = self.hidden2_layer(hidden1)
concat = keras.layers.concatenate([input, hidden2])
output = self.output_layer(concat)
return output
model = WideDeepModel()
"""
也可以写成
model = keras.models.Sequential([
WideDeepModel(),
])
"""
model.build(input_shape=(None, 8))目前为止用的 Wide 和 Deep 模型都是一样的,下面看下多输入与多输出。
Wide&Deep 模型的多输入与多输出
多输入神经网络:
选前 5 个 ficher 当作是 Wide 模型的输入,取后 6 个 ficher 当作是 Deep 模型的输入。
# 多输入
input_wide = keras.layers.Input(shape=[5])
input_deep = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30, activation='relu')(input_deep)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
concat = keras.layers.concatenate([input_wide, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_wide, input_deep], outputs=[output])
model.summary()
model.compile(loss="mean_squared_error", optimizer="sgd")
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]训练数据也要作出改变,因为有两组数据:
x_train_scaled_wide = x_train_scaled[:, :5]
x_train_scaled_deep = x_train_scaled[:, 2:]
x_valid_scaled_wide = x_valid_scaled[:, :5]
x_valid_scaled_deep = x_valid_scaled[:, 2:]
x_test_scaled_wide = x_test_scaled[:, :5]
x_test_scaled_deep = x_test_scaled[:, 2:]
history = model.fit([x_train_scaled_wide, x_train_scaled_deep],
y_train,
validation_data=([x_valid_scaled_wide, x_valid_scaled_deep], y_valid),
epochs=100,
callbacks=callbacks)测试集评估:
model.evaluate([x_test_scaled_wide, x_test_scaled_deep], y_test)多输出神经网络主要针对多任务学习的问题,和 Wide&Deep 多输入没关系,比如房价预测问题预测的是当前的房价,不过我们还需要预测一年后的房价是多少,这样就有了两个预测任务,这个模型就需要给出两个结果。试试上面的房价预测模型在 hidden2 后再输出一个值:
# 多输入多输出
input_wide = keras.layers.Input(shape=[5])
input_deep = keras.layers.Input(shape=[6])
hidden1 = keras.layers.Dense(30, activation='relu')(input_deep)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
concat = keras.layers.concatenate([input_wide, hidden2])
output = keras.layers.Dense(1)(concat)
output2 = keras.layers.Dense(1)(hidden2)
model = keras.models.Model(inputs=[input_wide, input_deep], outputs=[output, output2])
# 这样在网络结构部分就有了两个输出的网络结构这样数据训练也需要两个输出,y也要变成两份:
history = model.fit([x_train_scaled_wide, x_train_scaled_deep],
[y_train, y_train],
validation_data=([x_valid_scaled_wide, x_valid_scaled_deep], [y_valid, y_valid]),
epochs=100,
callbacks=callbacks)学习曲线图:
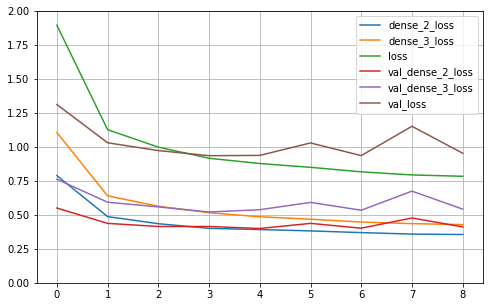
测试集模型评估:
model.evaluate([x_test_scaled_wide, x_test_scaled_deep], [y_test, y_test])评估结果:
5160/5160 [==============================] - 0s 21us/sample - loss: 0.9603 - dense_2_loss: 0.4309 - dense_3_loss: 0.5326
[0.9603453163028688, 0.43093655, 0.5325812]
Keras 与 scikit-learn 实现超参数搜索
手动实现超参数搜索
这里改变回归模型的模型搭建部分的代码,不依赖于 sklearn 的超参数搜索实现。
这里就来手动搜索下学习率这个超参数。
神经网络训练迭代公式:
\displaystyle W_n=W_{n-1}+\nabla f\cdot learningRate
# learning_rate: [1e-4, 3e-4, 1e-3, 3e-3, 1e-2, 3e-2]
# W = W + grad * learning_rate
learning_rate = [1e-4, 3e-4, 1e-3, 3e-3, 1e-2, 3e-2]
# 保存所有的 history
histories = []
for lr in learning_rates:
model = keras.models.Sequential([
keras.layers.Dense(30, activation='relu', input_shape=x_train.shape[1:]),
keras.layers.Dense(1),
])
# 定义 optimizer
optimizer = keras.optimizers.SGD(lr)
model.compile(loss="mean_squared_error", optimizer=optimizer)
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]之前的模型 optimizer="sgd" 中 sgd 是随机梯度下降,现在用自己的 lr 去初始化 optimizer。
然后我们保存所有的 history:
history = model.fit(x_train_scaled, y_train, validation_data=(x_valid_scaled, y_valid), epochs=100, callbacks=callbacks)
histories.append(history)打印所有的 history 学习曲线图:
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
for lr, history in zip(learning_rates, histories):
print("learning rate: ", lr)
plot_learning_curves(history)由于是在筛选学习速率超参数,所以不用测试集评估模型。
一般情况下梯度系数也就是学习率是衰减的,这里是从小到大递增,所以会看到到后面会发生「数据爆炸」。
在现实情况中一般会定义很多超参数,这里一个学习率超参数就用了一个 for,如果有很多个超参数,就需要很多个 for,这样就无法「并行化」计算,因为每个超参数计算都需要把上一个超参数计算完,这就加大了超参数搜索的编程难度,这个算法无法并行化计算,这样做超参数搜索也不太现实,所以最好借助 sklearn 库的超参数搜索策略来实现超参数搜索。
sklearn 封装 keras 模型
RandomizedSearchCV 是 sklearn 里面的一个函数,首先要把 tf.keras 的 Model 转化成 sklearn 形式的 Model。先定义一个 tf.keras 的 Model,然后调用一个函数把这个 Model 封装成 sklearn 的 Model。去 官方文档 中查找 tf.keras -> wrappers -> scikit_learn。如果是回归模型用 KerasRegressor,如果是分类模型用 KerasClassifier。
# RandomizedSearchCV
# 1. 转化为sklearn的model
# 2. 定义参数集合
# 3. 搜索参数
def build_model(hidden_layers=1, layer_size=30, learning_rate=3e-3):
model = keras.models.Sequential()
model.add(keras.layers.Dense(layer_size, activation='relu', input_shape=x_train.shape[1:]))
for _ in range(hidden_layers - 1):
model.add(keras.layers.Dense(layer_size, activation='relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate)
model.compile(loss='mse', optimizer=optimizer)
return model
sklearn_model = keras.wrappers.scikit_learn.KerasRegressor(build_model)
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]
history = sklearn_model.fit(x_train_scaled, y_train, epochs=100,validation_data=(x_valid_scaled, y_valid),callbacks=callbacks)sklearn 的 Model 没有
evaluate。
查看学习曲线:
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)sklearn 超参数搜索
keras 模型被转成 sklearn 模型后,就可以用 RandomizedSearchCV。
现在需要定义需要搜索的超参数的范围,至于是哪些参数,在定义 build_model 的时候已经指定了哪些参数:def build_model(hidden_layers=1,layer_size=30,learning_rate=3e-3):。
# reciprocal 是一个分布
from scipy.stats import reciprocal
# f(x) = 1/(x*log(b/a)) a <= x <= b
param_distribution = {
"hidden_layers":[1, 2, 3, 4],
"layer_size": np.arange(1, 100),
# learning_rate 取连续的值,调用 reciprocal 函数
"learning_rate": reciprocal(1e-4, 1e-2),
}reciprocal分布解析:
\displaystyle f(x)=\frac{1}{x\log(\frac{b}{a})}\\{}\\ a\leqslant x\leqslant b
可以生成十个数测试下这个分布:
from scipy.stats import reciprocal
reciprocal.rvs(1e-4, 1e-2, size=10)然后调用 RandomizedSearchCV:
输入值:
- sklearn_model
- 参数分布
- 生成参数集合的个数
- cross_validation 机制中的 n 值
- 并行处理的任务个数(默认不能大于 1,可通过别的方式修改)
from sklearn.model_selection import RandomizedSearchCV
random_search_cv = RandomizedSearchCV(sklearn_model,
param_distribution,
n_iter=10,
'''
默认 cv=3,可以设置别的值
cv=3
'''
n_jobs=1)开启超参数搜索:
random_search_cv.fit(x_train_scaled,
y_train,
epochs=100,
validation_data=(x_valid_scaled, y_valid),
callbacks=callbacks)搜索结束之后,可以打印下最佳参数组:
# 最佳参数组
print(random_search_cv.best_params_)
# 最佳分值
print(random_search_cv.best_score_)
# 最佳模型
print(random_search_cv.best_estimator_)输出:
{‘hidden_layers’: 4, ‘layer_size’: 58, ‘learning_rate’: 0.005740738090802875}
-0.34587740203258194
<tensorflow.python.keras.wrappers.scikit_learn.KerasRegressor object at 0x1400cb828>
测试集评估:
model = random_search_cv.best_estimator_.model
model.evaluate(x_test_scaled, y_test)输出:
5160/5160 [==============================] - 0s 21us/sample - loss: 0.3982
0.398169884478399
在搜索参数的过程中,会看到 Train on 7740 samples, validate on 3870 samples,而不是之前训练模型的 Train on 11610 samples, validate on 3870 samples。每个搜索遍历 7740 个样本,这是因为搜索参数遵循 cross_validation 机制,这个机制说的是:
训练集分成n份,n-1份训练,最后1份验证,可以看到最后一次训练,遍历数据仍然变成了 11610 个。默认情况下 n=3,可以通过修改 RandomizedSearchCV 里的属性 CV 值来改变n。
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




你这™写的太详细了
持续关注