
LSTM 长短期记忆网络
0 / 1 / 创建于 6年前 /
 Galois 的个人博客
Galois 的个人博客
由来
人类并不是每时每刻都从一片空白的大脑开始他们的思考。在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义。我们不会将所有的东西都全部丢弃,然后用空白的大脑进行思考。我们的思想拥有持久性。
传统的神经网络并不能做到这点,看起来也像是一种巨大的弊端。例如,假设你希望对电影中的每个时间点的时间类型进行分类。传统的神经网络应该很难来处理这个问题——使用电影中先前的事件推断后续的事件。
RNN 解决了这个问题。RNN 是包含循环的网络,允许信息的持久化。
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。不幸的是,当时间间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
幸运的是,LSTM 并没有这个问题!
为什么需要 LSTM
普通 RNN 的信息不能长久传播(存在于理论上)
引入选择性机制
- 选择性输出
- 选择性输入
- 选择性遗忘
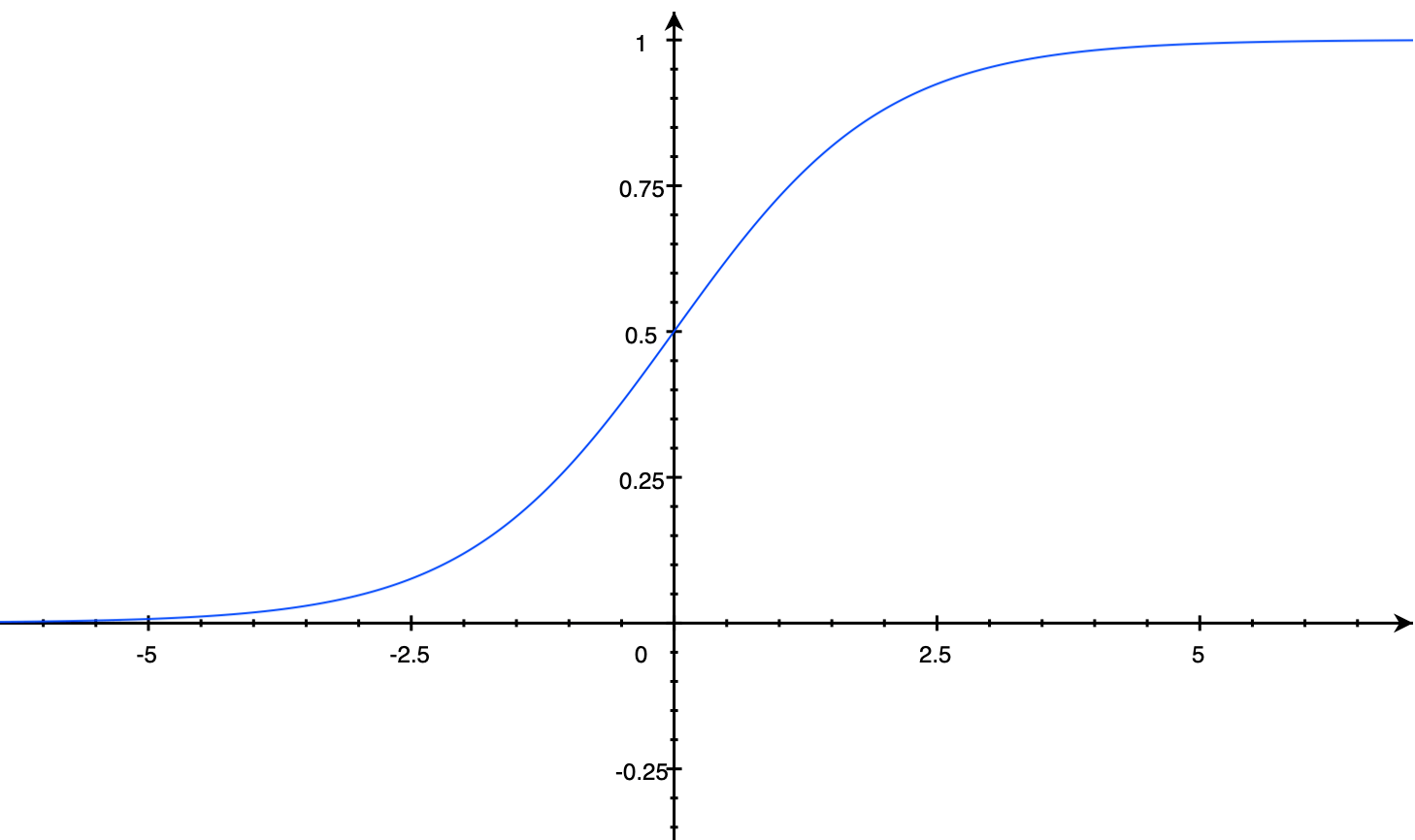
选择性 -> 门 - Sigmoid 函数:[0, 1]
\displaystyle f(x)=\frac{1}{1+e^{-x}}
门限机制
- 向量A -> sigmoid -> [0.1, 0.9, 0.4, 0, 0.6]
- 向量B -> [13.8, 14, -7, -4, 30.0]
- A为门限,B为信息
- A * B = [0.138, 12.6, -2.8, 0, 18.0]
LSTM 属于循环神经网络的一种,详细的循环神经网络参考循环神经网络。

处理层的符号解释:

网格结构 - Neural Network Layer
点积操作 - Pointwise Operation
向量传递 - Vector Transfer
向量拼接 - Concatenate
向量拷贝 - Copy
逐步解析LSTM
三门两态:
LSTM 第一步是用来决定什么信息可以通过 cell state。这个决定由“forget gate”层通过sigmoid来控制,它会根据上一时刻的输出通过或部分通过。如下:
「遗忘门」: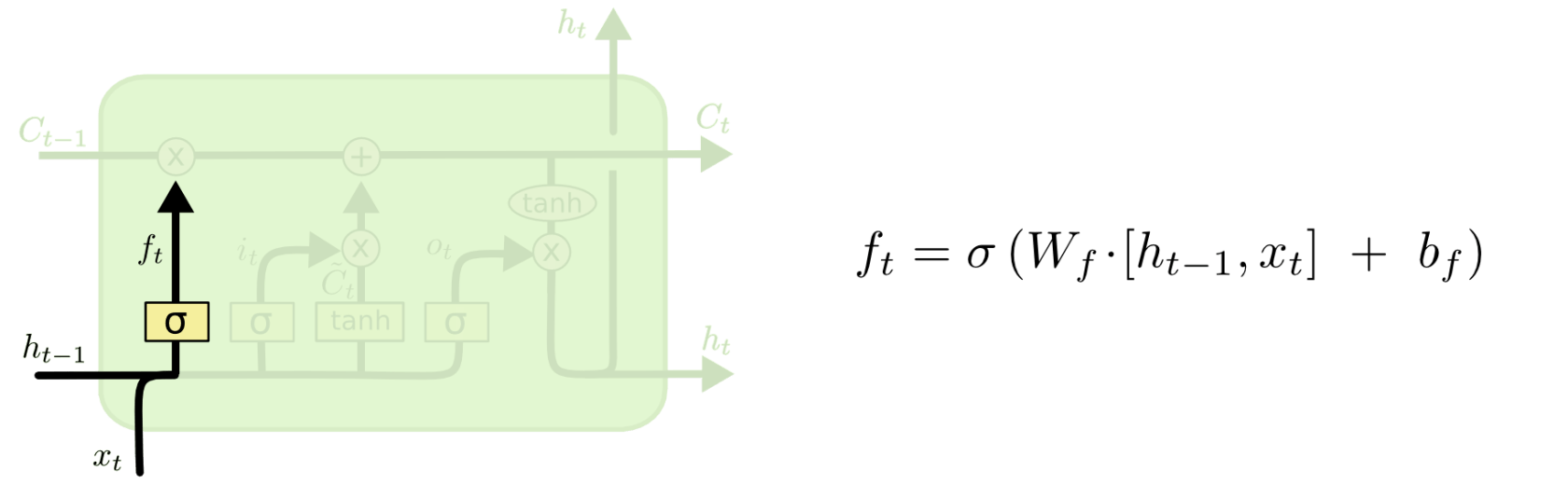
第二步是产生我们需要更新的新信息。这一步包含两部分,第一个是一个“input gate”层通过\mathrm{sigmoid}来决定哪些值用来更新,第二个是一个\tanh层用来生成新的候选值相加,得到了候选值。
一二步结合起来就是丢掉不需要的信息,添加新信息的过程:
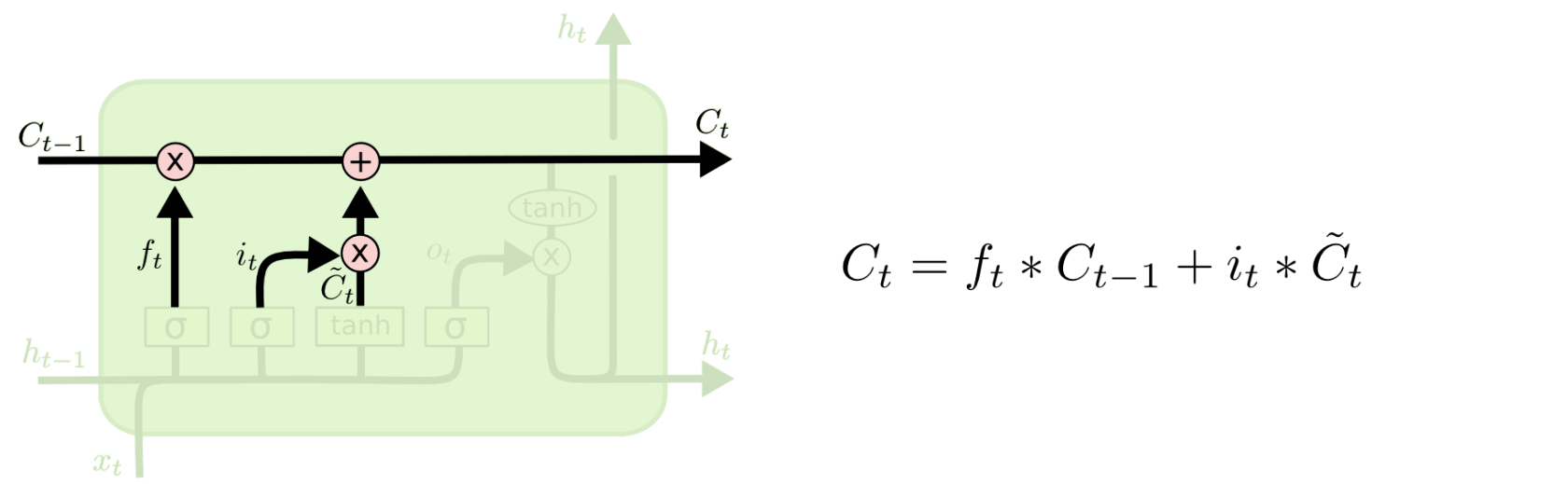
最后一步是决定模型的输出,首先是通过\mathrm{sigmoid}层来得到一个初始输出,然后使用tanh将值缩放到-1到1间,再与\mathrm{sigmoid}得到的输出逐对相乘,从而得到模型的输出。
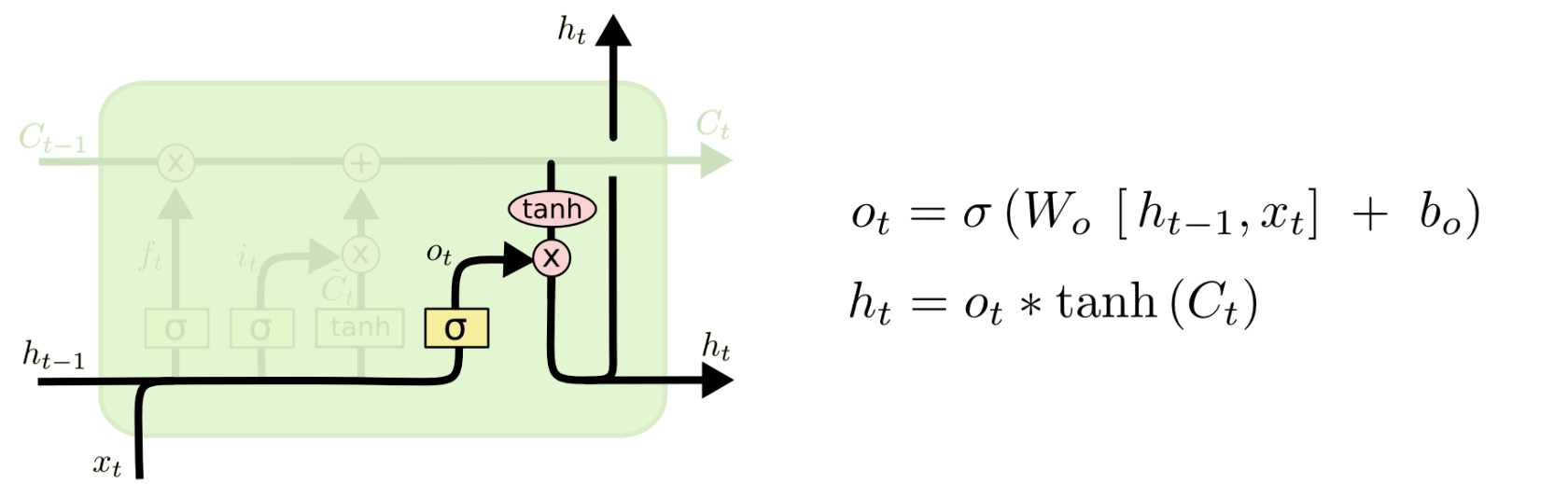
这显然可以理解,首先\mathrm{sigmoid}函数的输出是不考虑先前时刻学到的信息的输出,tanh函数是对先前学到信息的压缩处理,起到稳定数值的作用,两者的结合学习就是递归神经网络的学习思想。至于模型是如何学习的,那就是后向传播误差学习权重的一个过程了。
这是 LSTM 的一个典型结构的理解,当然,它也会有一些结构上的变形,但思想基本不变。
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




请问下 Sigmoid 函数曲线用什么软件画的?