
一次 KubeCPUOvercommit 告警排查过程小记
2 / 1 / 创建于 6年前 /
 RightCapital 的个人博客
RightCapital 的个人博客
问题现象
在配置好 Prometheus Operator Chart 一段时间后,我们决定开启由 kubernetes-mixin 项目提供的 alert rules,并将 AlertManager 和 Opsgenie 集成。在其后的几天里,每到傍晚六点钟左右就会出现 KubeCPUOvercommit 的告警:
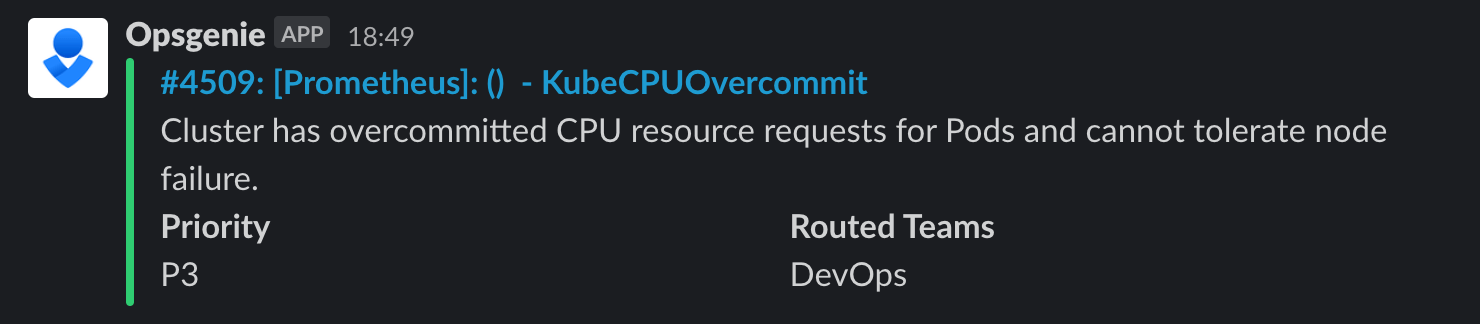
排查过程
最初的猜测
根据报警信息,我们第一反应打开了 Grafana,开始查看 Compute Resources / Cluster dashboard 的数据,其中一个 panel 为 CPU Requests Commmitment,此时的数据确实超过了 100%。
但我们集群内安装了 Cluster Autoscaler,理论上不会出现 CPU Resource Requests 超量的情况,我们也在收到报警的时刻做了确认,当时并没有发现 unscheduled Pods。
难道是误报?我们打开了 panel 详情,提取了其中的表达式:
sum(kube_pod_container_resource_requests_cpu_cores{cluster="$cluster"})
/
sum(kube_node_status_allocatable_cpu_cores{cluster="$cluster"})随后通过 Grafana Explore 面板查看 kube_pod_container_resource_requests_cpu_cores metric,发现它并不包含任何关于 Pod status 的 label,于是我们开始怀疑:是否是此 metric 包含了 failed 和 completed 的 Pod 导致的?
验证猜测
我们手动删除了一部分 failed 和 completed Pods 后 alert closed,Grafana dashboard 上的显示也降到了 100% 以下。我们以为找到了问题的原因,正当我们修复了 panel 的表达式,准备调整 alert rule 的时候,发现该报警规则的表达式(来源)是:
sum(namespace:kube_pod_container_resource_requests_cpu_cores:sum)
/
sum(kube_node_status_allocatable_cpu_cores)
>
(count(kube_node_status_allocatable_cpu_cores)-1) / count(kube_node_status_allocatable_cpu_cores)它的含义为:Pod所需要的CPU核心总数 / 可分配的核心总数 > (node数量 - 1) / node数量 则报警。
此处使用的是 namespace,并非  sum
sumkube_pod_container_resource_requests_cpu_cores,因此之前的猜想错误。
再次 debug
研究发现,namespace 是 Prometheus Operator Chart 自定义的 recording rule。sum
Recording rule 主要用于预先计算那些使用率高或是计算量较大的表达式,并将其结果保存为一组新的时间序列,这样不仅能够提高报警规则的计算速度,同时可以达到复用复杂表达式的效果。
level是官方推荐的 recording rules 命名协定。operations
经过一番查找,该 recording rule 的表达式为(来源):
sum by (namespace) (
sum by (namespace, pod) (
max by (namespace, pod, container) (
kube_pod_container_resource_requests_cpu_cores{job="kube-state-metrics"}
) * on(namespace, pod) group_left() max by (namespace, pod) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)稍微有点长,我们简化一下,先看内层。
max by (namespace, pod, container) (
kube_pod_container_resource_requests_cpu_cores{job="kube-state-metrics"}
)
* on(namespace, pod) group_left()
max by (namespace, pod) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)on(namespace, pod) group_left() 是 PromQL 的语法之一,直译为 向量匹配。本例的含义为:依次查找运算符(*)左侧样本中 namespace 和 Pod 相匹配的右侧样本,若有匹配则参与运算并形成新的时间序列,若未找到则直接丢弃样本。
另外此处的条件 kube_pod_status_phase{phase=~"Pending|Running"} == 1,表示 Pod 的状态必须是 pending 或 running,否则样本会被丢弃。
最后,在外层再进行一些聚合运算,recording rule namespace 就计算完成了:sum
sum by (namespace) (
sum by (namespace, pod) (
...
)
)经过排查,否定了我们的猜想,因为该时间序列已经排除了非 pending 或 running 状态的 Pod,它们的 resource requests 数值不会纳入到最终的样本中。
新的猜测和证实
确定 namespace 没有问题后,我们仔细阅读告警的描述:sum
Cluster has overcommitted CPU resource requests for Pods and cannot tolerate node failure.
恍然发现它表述的意思是:集群已承受超量的 Pod CPU 资源请求,无法容忍 node 失效(例如节点崩溃、drain/taint 造成的 eviction 等)。
这么说来就可以解释为何 CPU 核心数的利用率 要与 (node数量 - 1) / node数量 做比较了。可简单地理解为:目前集群中的工作负载已不容许出现 Node 数量减少 1,一旦有 node 失效,Pod 所需要的 CPU 资源就超出集群的资源总量了。
问题解释
综上所述,该 alert 属于「预警」,并非「报警」。它的出现是为了提示我们,为了保证高可用性应该扩容集群了。而不是已经出现了 unscheduled Pod。
因为有 Cluster Autoscaler 的存在,扩容操作不需要我们手动执行,因此文章开头提到的「手动删除一部分 failed Pod 后恢复正常」实际上是一个「迷惑行为」,此时刚好碰上新的 node 启动完成而已。
解决方案
为了能够保证集群的超高可用(至少可以容忍一台 node 失效),我们需要 overprovisioning。虽然 Cluster Autoscaler 并没有直接提供参数实现,但我们在 FAQ 发现了一个小技巧:How can I configure overprovisioning with Cluster Autoscaler。
大致思路如下:
- 创建较低的
PriorityClass,例如名为overprovisioning值为-1。 - 创建
Deployment作为「占位」,将spec.template.spec.priorityClassName设置为overprovisioning,同时配置 containers 的 resource requests 为预留的资源数量。 - Cluster Autoscaler 将会 overprovisioned 一部分 node 以满足占位 Pods 的 resource requests。
- 因为占位 Pods 优先级较低,在其它优先级较高的 Pods 需要资源时,占位 Pods 将会被驱逐,将预留的资源提供给其它 Pods。
- 此时占位 Pods 无法被调度,Cluster Autoscaler 将会再次 overprovision 新的 node。
最终,在 kubernetes-mixin 项目中,修改告警规则的 ignoringOverprovisionedWorkloadSelector 配置。使用 Selectors 忽略 overprovisioned 的 Pods,使其不纳入工作负载的计算,即可让 Cluster Autoscaler 始终让我们的服务器保证多出当前的需求一台,来保证高可用性。
结语
以上就是我们透过一次「误报」,排查后发现集群可用性存在的问题,并最终做出解决方案提高了可用性的经历。如果你有更好的实践,欢迎通过通过留言与我们交流。
本作品采用《CC 协议》,转载必须注明作者和本文链接








 关于 LearnKu
关于 LearnKu




推荐文章: